前言
PyTorch 2.0 算是正式官宣了,预计在明年 3 月和大家见面。官方的 blog 宣发了非常多的内容,但是阅读下来不难发现,几乎所有的性能提升、体验优化都源自于 PyTorch 新设计的即时编译工具:Dynamo。
PyTorch eager 模式极佳的编程体验让他在深度学习学术圈内几乎有了“一统天下”之势。但是相比于 trace 模式,eager 模式的缺点同样明显,即没有办法简单地通过代码获取模型的图结构,导致模型导出、算子融合优化、模型量化等工作变得异常困难。
当然 PyTorch 1.0 对追踪模型图结构(graph capture)这件事也付出了很多的努力,例如 torch.jit.trace/script,torch.fx 等,但是无一例外,上述各种 graph capture 方法其使用手感只能用一言难尽来形容(部署、量化的同学赶快举起你们的双手!)。
因此 PyTorch 痛定思痛,终于在年底搞了个大新闻,在 2.0 里推出了他们新一代的 trace 工具 Dynamo。作为 PyTorch 1.0 graph capture 的受害者,我迫不及待的想看一看 Dynamo 到底做了什么,以至于让 PyTorch 对其如此自信,甚至以此为基础做了那么多的工作,发布 PyTorch 2.0。
OpenMMLab 于今年九月发布了新一代的训练框架 MMEngine,各个下游仓库也分别基于 MMEngine 发布了全新版本。自 PyTorch 2.0 发布以来,我们也紧锣密鼓地进行着兼容、适配工作。目前 MMEngine 新开了一个 experimental/compile 分支,各个算法可以基于该分支验证性地适配 Dynamo 加速优化。
当然啦,理想很美好,现实很骨感,不出意外地,Dynamo 适配各个下游算法库出了意外。目前来看,尽管 Dynamo 能够 trace 绝大部分的 Python 语法,但是如果遇到某些不符合它预期的语法,仍然会报错。对于那些尚未支持的语法,它有可能是现在不支持,将来支持,也有可能是从原理上就无法支持。因此对于那些可以支持但是尚未支持的语法,我们会向 Dynamo 提 issue,希望能够尽快修复他们尚未考虑到的 corner case;对于原则上就无法支持的语法,OpenMMLab 系列的算法库也会相应调整,以符合 PyTorch 2.0 的开发规范。
我们强烈呼吁更多同学参与到这个活动中来,基于 MMEngine 的 dynamo 分支跑一下自己使用的算法库,“体验”一下 PyTorch 2.0 带来的性能优化。如果报错了,我们也会第一时间反馈优化,我们的目标是:PyTorch 2.0 发布时,所有模型都能够搭上性能优化的快车!
感兴趣的同学可以加 群 上车,与我们一起和 Dynamo 大战三百回合!
安装预发布版本的 PyTorch
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
如果 tqdm 版本过低,可能会出现一些奇怪的报错:
TypeError: __init__() got an unexpected keyword argument 'desc'
牛刀小试
先看一个简单的例子(摘自官方文档,感觉官方文档的示例和后文的展开有冲突,因此做了一些修改),如果能正常运行,就代表你的预发布版本的 PyTorch 初步安装成功。
import torch
from torch._dynamo import optimize
import torch._inductor.config
torch._inductor.config.debug = True
def fn(x):
a = torch.sin(x).cuda()
b = torch.sin(a).cuda()
return b
new_fn = optimize("inductor")(fn)
input_tensor = torch.randn(10000).to(device="cuda:0")
a = new_fn(input_tensor)
在上例中,我们用 torch.compile 依次运行了两个 pointwise 算子(逐元素计算),PyTorch 2.0 将会从以下两个角度对其进行优化。
图优化之算子融合
在 Eager 模式下,pointwise 算子通常不是最优的,因为他经常涉及从一块内存(Tensor)上读数据,然后计算完之后再写回去。例如上面的例子,他会涉及 2 次额外的内存读取和 2 次内存写入:
- 从 x 中读取数据
- 计算 sin(x) 的结果写入到 a
- 从 a 中读取数据
- 计算 sin(a) 的结果写入到 b
然而事实上,上述过程是可以被优化成 1 次内存读取和 1 次内存写入的。即把临时变量暂存到寄存器或告诉缓存上。
图优化之降低 kernel 启动的开销
PyTorch 2.0 会基于很多 backend 对 CUDA graph 进行优化,inductor 会基于 Triton 对 CUDA graph 进行重构。
Triton 为没有 CUDA 编程经验的人提供了一套更加简单地基于 Python GPU 编程接口,让大家可以更加简单地开发 CUDA 算子。inductor backend 下,Dynamo 会将用户写的代码解析成 Triton kernel 进行优化
优化结果
假设刚才的代码文件夹名是 trig.py
执行 python compile.py
PyTorch 预发布版本更新频率极高,debug 的启动方式,优化后代码的存放路径会有所不同,想要看到下面这段代码可能需要大家各凭本事 (狗头保命 x1)

打开红框文件,就能够发现 Triton 的等效代码实现:
@pointwise(size_hints=[16384], filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32'}, 'device': 0, 'constants': {}, 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2), equal_to_1=())]})
@triton.jit
def kernel(in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 10000
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.reshape(tl.arange(0, XBLOCK), [XBLOCK])
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask) # 只读一次
tmp1 = tl.sin(tmp0) # 临时变量放在寄存器,不计入读写次数
tmp2 = tl.sin(tmp1) # 临时变量放在寄存器,不计入读写次数
tl.store(out_ptr0 + (x0 + tl.zeros([XBLOCK], tl.int32)), tmp2, xmask) # return 时才真正触发写
正如注释所述,优化后的代码避免了非必要的内存读写,做到了只读一次,只写一次。
PyTorch 的这个官方示例总感觉有点看的不过瘾,毕竟只是 demo 级别的示例,没法真正体现他的加速效果。为了进一步验证 optimize("inductor") 带来的性能优化,我们尝试用它来加速 MMEngine 中训练 ResNet50 的例子:
@optimize('inductor')
def forward(self, imgs, labels, mode):
x = self.resnet(imgs)
if mode == 'loss':
return {'loss': F.cross_entropy(x, labels)}
elif mode == 'predict':
return x, labels
优化之前的日志片段:
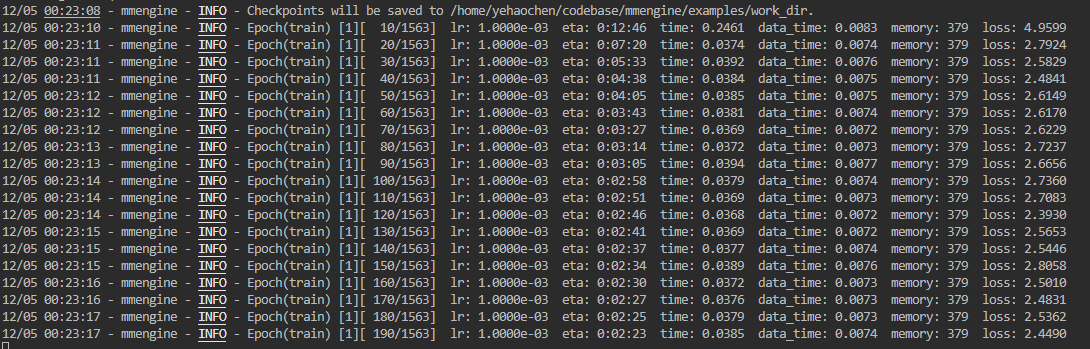
优化之后的日志片段:

嘶!PyTorch 2.0 诚不欺我,ResNet50 在 CIFAR10 上的训练加速比达到了惊人的 40%。
在惊叹于 PyTorch 2.0 加速的同时,我也发现了两个非常有趣的现象:
- 在给
forward加上@optimize('inductor')装饰器之后,训练启动时间明显变长了很多。从上文得知,这大概率是图优化的过程,那图优化的过程具体是怎么进行的呢? - 训练完一个 epoch 之后,第一个验证过程的启动也明显变慢,这又是为什么呢?
这两个问题我们会在后续的内容中进行解释。
Dynamo 初探
什么是 Dynamo?这里给出一段官方介绍的翻译,以及相应的流程图:
TorchDynamo is a Python-level JIT compiler designed to make unmodified PyTorch programs faster. TorchDynamo hooks into the frame evaluation API in CPython (PEP 523) to dynamically modify Python bytecode right before it is executed. It rewrites Python bytecode in order to extract sequences of PyTorch operations into an FX Graph which is then just-in-time compiled with a customizable backend. It creates this FX Graph through bytecode analysis and is designed to mix Python execution with compiled backends to get the best of both worlds — usability and performance.
TorchDynamo 是一个 Python 级别的即时编译器,可以在不修改 PyTorch 程序的情况下对其进行加速。TorchDynamo 在 Python 调用帧评估函数 (frame evaluation) 时,插入了钩子 (Hook) 。钩子会在执行具体的 Python 字节码(bytecode)之前对其进行解析,从中提炼出 PyTorch 运算符并将其转化成 torch.fx 的图结构,最后用自定义的后端对图进行编译优化,并导出、返回优化后的字节码…
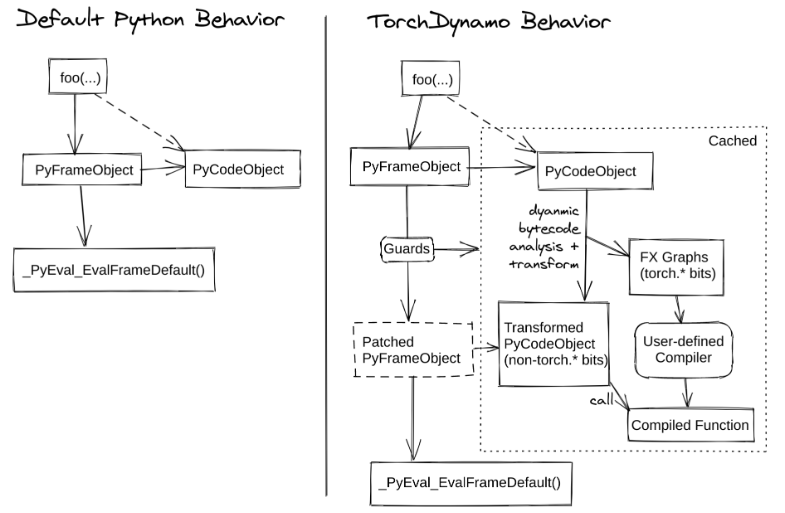
不了解 Python 虚拟机执行步骤的同学可能会觉得一头雾水,并且也很难理解 Dynamo 附赠的这张优化流程图。没关系,我们可以从一些基本概念入手,隐去具体实现的细节,从概念上理解 Dynamo 的优化原理。
Dynamo 的 “与众不同”
这里真的忍不住要贴一下 PyTorch 官方的吐槽:
In the past 5 years, we built
torch.jit.trace, TorchScript, FX tracing, Lazy Tensors. But none of them felt like they gave us everything we wanted. Some were flexible but not fast, some were fast but not flexible and some were neither fast nor flexible. Some had bad user-experience (like being silently wrong). While TorchScript was promising, it needed substantial changes to your code and the code that your code depended on. This need for substantial change in code made it a non-starter for a lot of PyTorch users.
总而言之,言而总之,无论是 torch.jit.trace,TorchScript ,torch.fx 还是 Lazy Tensor,都不好用!有的不灵活,有的不够高效,有的既不灵活也不高效(大声告诉我,是谁!),甚至有时候还会偷偷犯错把你坑懵。这些自嘲式的描述不禁让我们这些长期受虐的用户会心一笑,好家伙,你也知道难用啊。
但是看到这我们也不经会好奇,为什么 PyTorch 会觉得 Dynamo 比以前的那些方式更加好用,以至于基于 Dynamo 投入了那么多资源进行开发,并发布了 2.0。
个人以为,核心原因就是 Dynamo 解决 trace 问题的视角,和之前所有那些设计存在本质上的不同:打个不恰当的比方,如果把 graph capture 的过程当做走迷宫,torch.jit.trace 这些在遇到迷宫的路口时,他只能“走一步看一步”,不知道未来通向何方,只能随着 Python 的调用栈随波逐流;而 Dynamo 则视角更高,他能够“看到”前方每个分支会通向何方,并将其记录下来。尽管说 Dynamo 一次性还是只能 trace 一个分支,但是得益于他“记录现场”的能力,当再一次走到这一个路口时,Dynamo 会还原现场,根据当前状态选择正确的分支。
Dynamo 优化原理
回顾一下 PyTorch 官方的定义:
TorchDynamo 是一个 Python 级别的即时编译器,用于在不修改 PyTorch 程序的情况下对其进行加速。TorchDynamo 在 Python 调用帧评估函数 (frame evaluation) 时,插入了钩子 (Hook) 。钩子会在执行具体的 Python 字节码(bytecode)之前对其进行解析,从中提炼出 PyTorch 运算符并将其转化成 torch.fx 的图结构,最后用自定义的后端对图进行编译优化,并导出、返回优化后的字节码…
这边圈出几个关键字:
- Frame evaluation
- Hooks
- bytecode
帧(frame)评估
首先,什么是 frame?如果你听说过函数栈,相信你一下子就能理解 frame 的概念。如果对这方面的理论知识不是很熟悉,没关系,我们用一张图来表示 Python 中的函数和 frame 之间的关系:
This content is only supported in a Feishu Docs
正如上图所示,函数的调用栈,实际上就是递归地创建 frame(Python 内置的数据结构),执行frame 的过程。
当然我们也可以在 Python 层面感知到这层调用关系,比较典型的就是 MMEngine 中也利用函数的 frame 信息,去获取注册器所在的 scope。当然我们这里给出一个更加简单的例子,方便大家理解:
import inspect
def func_a():
frame = inspect.currentframe()
co_name = frame.f_code.co_name # 当前帧执行函数的名字
print(f'code name of current frame is {co_name}')
pri_frame = frame.f_back # 通过 f_back 访问前一帧执行函数的名字
print(f'current code name of previous frame is {pri_frame.f_code.co_name}')
def func_b(a=1):
func_a()
if __name__ == '__main__':
func_b()
Python 层面代码的执行,是在 frame 中进行的。CPython 非常贴心地允许我们在执行 Python 代码(字节码)时,访问当前的帧信息。上述代码我们在 func_b 中执行 func_a,并且在 func_a 中解析当前帧和前一帧的信息,得到的打印结果是:
code name of current frame is func_a
current code name of previous frame is func_b
函数是运行在 frame 中的,因此我们可以轻松地从 frame 中获取任何函数需要的信息,例如我们可以通过上例在 frame 中获取到当前函数的名字 func_a。由于 Python 的 frame 是栈式存储的,因此很简单就能访问到上一个 frame,进而获取上一帧所运行的函数名 func_b。
更夸张一点,我们甚至能够在 func_a 中获取 func_b 定义的的局部变量 a:
def func_a():
frame = inspect.currentframe()
co_name = frame.f_code.co_name
print(f'code name of current frame is {co_name}')
pri_frame = frame.f_back
print(f'current code name of previous frame is {pri_frame.f_code.co_name}')
print(f'a={pri_frame.f_locals["a"]}')
由此我们可以得出两个结论:
- frame 包含了函数执行所需要的所有信息
- 我们可以在函数中访问 frame
这其实是一个很重要的启示,frame 包含了函数的所有信息,那就意味着 frame 包含了代码信息。 那么理论上,如果我们在执行函数之前就能通过 frame 获取到函数的代码信息,并且能够解析这个信息,那是不是从某种意义上我们就完成了这个函数的 trace 了呢?
没错,这就是 Dynamo 官方流程图的第一步,解析 frame :
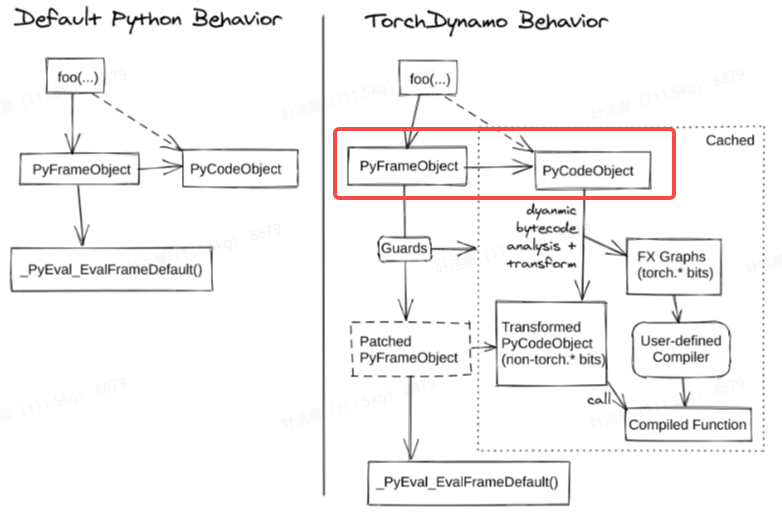
上述代码示例都是针对单帧函数而言的,即我们特定地在 func_a 里去获取帧信息。然而模型实际运行时,其调用栈非常复杂,我们如何自动化地为每个函数额外加上解析 frame 的行为呢?答案是:PEP 523
事实上,我们很难在 Python 层面想到一种方法,将某一个修改(例如刚才提到的函数入栈时解析 frame)递归地作用在所有的函数栈上(函数入口及其内部调用的所有接口)。这件事看上去很简单,但是做起来却非常的困难,甚至早期的 CPython 都没有开放这样功能。因此 PEP 523 应运而生,再此之前,我们再回顾一下这张图:
This content is only supported in a Feishu Docs
划重点:所有的 frame 的评估,都是依赖于 CPython 解释器的。 因此 PEP 523 认为,CPython 解释器的帧评估方式(Frame Evaluation)应该是可扩展的,这样用户就可以用自定义的方式进行 frame evaluation。
这恰好和 Dynamo 的需求相符合:我们希望 model 内部所有的函数调用(同 frame evaluation),都能够附加一个解析 frame 的过程,以此来解析提炼 PyTorch 程序运行时的图结构。因此 Dynamo 扩展了 CPython 解释器 frame evaluation,在执行默认的帧评估函数之前,实现一些额外的 frame 解析优化的工作。
为了方便大家理解 Dynamo 是如何扩展 Frame evaluation 的,这里先给出 CPython 默认 Frame evaluation 的调用栈(以下代码片段摘自 Python 3.10,Python 3.11 对函数执行做了非常大的优化,以至于调用栈变得非常难懂):
- _PyEval_EvalFrameDefault
- call_function
- _PyFunction_Vectorcall
- _PyEval_Vector
- PyEval_EvalFrame
- _PyEval_EvalFrame
This content is only supported in a Feishu Docs
上述六个步骤,即为 CPython 解释器执行一个函数时默认的调用栈,这边截取了 _PyEval_EvalFrame 中的代码片段:
_PyEval_EvalFrame(PyThreadState *tstate, PyFrameObject *f, int throwflag)
{
return tstate->interp->eval_frame(tstate, f, throwflag);
}
Python 会从线程状态(tstate)中获取解释器的 eval_frame 函数指针,默认情况下, CPython 解释器的 eval_frame 的函数指针就是 _PyEval_EvalFrameDefault ,具体见解释器的创建过程。
Dynamo 想用自定义的流程去执行 frame(解析 Python 代码,编译优化等),那么最容易想到的就是更改 eval_frame 的指向,让解释器的 eval_frame 指向 Dynamo 自己实现的 custom frame evaluation function。
This content is only supported in a Feishu Docs
正如上图所示,Dynamo 就是这样做的,他在 set_eval_frame 中将默认的 _PyEval_EvalFrameDefault 替换成 Dynamo 自定义的帧评估函数。
事实上,Dynamo 在 Python 层面完成了字节码(Python 代码)的解析,重构以及 PyTorch 图结构的追踪,并将上述过程打包成一个回调函数,传给自定义的帧评估函数。在此我们先不深究具体实现的过程。
巧妙的回调函数
上一节我们概念性地介绍了 PyTorch Dynamo 如何借助 PEP 523,以自定义的帧评估函数去执行帧(调用函数),但是具体他是怎么做的呢?难道要在 C 层面完成全套的字节码(Python 代码)解析,图追踪?
如果你刚才点开这个 _PyEval_EvalFrameDefault 的实现,就会发现其代码行数到了惊人的 6500 行,如果 Dynamo 想在 C 层面自己实现一套字节码解析、重构的逻辑,那怕是 PyTorch 2.0 明年都发不了版。因此,Dynamo 非常聪明得选择在 Python 层做字节码解析,以回调函数的形式传给自定义的帧评估函数。
当我们调用 optimizer('inductor')(fn) 时,Dynamo 会将 fn 的帧评估函数替换成 Dynamo 自定义的,并且传入回调函数。
def __call__(self, fn):
fn = innermost_fn(fn)
# Optimize the forward method of torch.nn.Module object
if isinstance(fn, torch.nn.Module):
mod = fn
new_mod = OptimizedModule(mod, self)
# Save the function pointer to find the original callable while nesting
# of decorators.
new_mod._torchdynamo_orig_callable = mod.forward
return new_mod
assert callable(fn)
callback = self.callback
on_enter = self.on_enter
backend_ctx_ctor = self.extra_ctx_ctor
@functools.wraps(fn)
def _fn(*args, **kwargs):
if (
not isinstance(self, DisableContext)
and torch.fx._symbolic_trace.is_fx_tracing()
):
if config.error_on_nested_fx_trace:
raise RuntimeError(
"Detected that you are using FX to symbolically trace "
"a dynamo-optimized function. This is not supported at the moment."
)
else:
return fn(*args, **kwargs)
on_enter()
# 执行之前更改帧评估函数,并传入回调函数
prior = set_eval_frame(callback)
backend_ctx = backend_ctx_ctor()
backend_ctx.__enter__()
dynamic_ctx = enable_dynamic(self.dynamic)
dynamic_ctx.__enter__()
try:
return fn(*args, **kwargs)
finally:
# 执行之后还原成原来的帧评估函数
set_eval_frame(prior)
dynamic_ctx.__exit__(None, None, None)
backend_ctx.__exit__(None, None, None)
传入的回调函数会被自定义的帧评估函数调用。回调函数会解析重构 frame 中原有的字节码,并在过程中追踪模型执行图结构。当然了,帧评估时也不是每次都会调用回调函数,例如某个 frame 已经被解析重构过了(cached),此时就会直接执行缓存里已经重构好的代码。
看到这,相信我们已经可以笼统地回答开头提到的两个问题:
Q: 为什么 Dynamo 优化后的模型第训练启动耗时那么长?
A:执行传入的 callback 函数会额外消耗时间。模型越复杂,调用栈越深,耗时越多
Q: 为什么验证阶段也会需要额外的启动时间?
A:验证阶段尽管和训练阶段有着很多重复的调用栈,但是仍然需要编译之前尚未遇到过的栈帧。因此也需要额外的启动时间在这些帧内执行 callback。
字节码解析/重构
上两节我们介绍了 Dynamo 如何通过实现自定义的帧评估函数,如何在帧评估函数中调用回调函数,进而实现 Python 字节码的重构,以达到运行时优化的效果。字节码重构部分,作为 Dynamo 最核心、最复杂的部分(实现充满了 hardcode,很多字节码解析的工作也是试错试出来的),如果大家很感兴趣,我们会单独出一期进行介绍。
总结
总得来说,相比于 torch.jit.trace、 torch.fx 等 trace 方案, Dynamo 更加本质地解决了 graph capture 的痛点。之所以说它更加本质,是因为之前的种种方案,仍然停留在 python 代码执行到哪,就 trace 到哪的程度。Dynamo 则完全不同,通过自定义帧评估函数的方式,它会在正式执行函数之前,以回调函数的方式执行 Python 层面定义的字节码“解析”(事实上除了解析,还会重构)函数。
这就意味着尽管这次函数调用不会经过某个代码分支(if else),但是 Dynamo 能够将该分支的代码信息记录下来,进而保留这一帧函数的动态特性。不谈其他方面的优化,光是 Dynamo 能够让用户在不改一行代码的前提下,自动判断哪个函数存在动态分支,那也是其他 graph capture 所方案望尘莫及的。
讲了 Dynamo 的万般好,你可能已经迫不及待地想去体验一把预发布版的 PyTorch 了,有这样想法的童鞋还是要做好心理准备。上文提到: CPython 解析器花了 6500 多行代码去解析各种各样类型的字节码,因此尽管 Dynamo 是在 Python 层面完成了字节码的解析,其复杂度仍然是相当之高,更别提他还需要在将字节码映射到模型的图表示上。
字节码解析越复杂,这就意味着解析部分的代码越容易写出 BUG。因此如果在体验过程中,发现 Dynamo 无法 trace 你的模型,那很有可能你的代码里藏着一些 Dynamo 不认识的“骚操作”,它只能报错。这部分骚操作有可能是从原理上就没法支持的,有可能是暂时还没有支持,也有可能真的是一个 Dynamo 没有考虑过的 corner case,总而言之,尽管 Dynamo 提供了一个非常优秀的 graph capture 解决方案,但是仍然有很长的路要走。
啥?字节码解析重构部分啥时候开坑?要是各位同学很感兴趣,马上安排。对 Dynamo 感兴趣的同学可以加入:PyTorch 2.0 交流群
实践是检验真知的唯一标准!下载预发布版本的 PyTorch,切换到 experimental/compile 分支,我们自己动手丰衣足食!超前体验 Dynamo 的加速效果!

![[FTP] ftp通信协议抓包分析](https://img-blog.csdnimg.cn/3de2a9884402491396152d5d5baddfc3.png)






![[附源码]计算机毕业设计Python的文成考研培训管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/2c28fc4c28ed4bd39be2a19c742888a1.png)