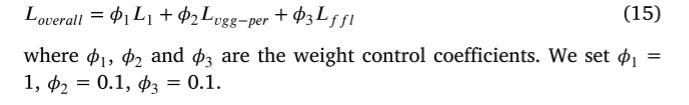毫无疑问,Milvus 已经成为全球诸多用户构建生产环境时必不可少的向量数据库。
近期,Milvus 发布了全新升级的 Milvus 2.3 版本,内核引擎加速的同时也加入了诸如支持 GPU 这样实用且强大的特性。可以说,以 Milvus 2.3 为代表的 Milvus 2.x 版本无论在功能还是性能上都远超 Milvus 1.x 版本。因此,有很多新老用户反馈,想要将存量向量数据从其他数据源迁移到 Milvus2.x 中,为了解决这一需求,Milvus-migration 项目应运而生。
读完本文,用户可以快速掌握 Milvus-migration 的功能特点和使用方法。(小声打个广告:Zilliz 云平台提供了更方便的一键迁移功能)
01.功能概述
目前迁移支持的数据源有:
-
Milvus 1.x 到 Milvus 2.x 迁移
-
Elasticsearch 到 Milvus 2.x 数据迁移
-
Faiss 到 Milvus 2.x 数据迁移 (Beta版本)
-
支持包括命令行和 Restful API 的多种交互方式
-
支持多种文件形式的迁移 (本地文件、S3、OSS、GCP)
-
支持 Elasticsearch 7.x 以上版本、自定义迁移字段构造表结构
02.设计思路
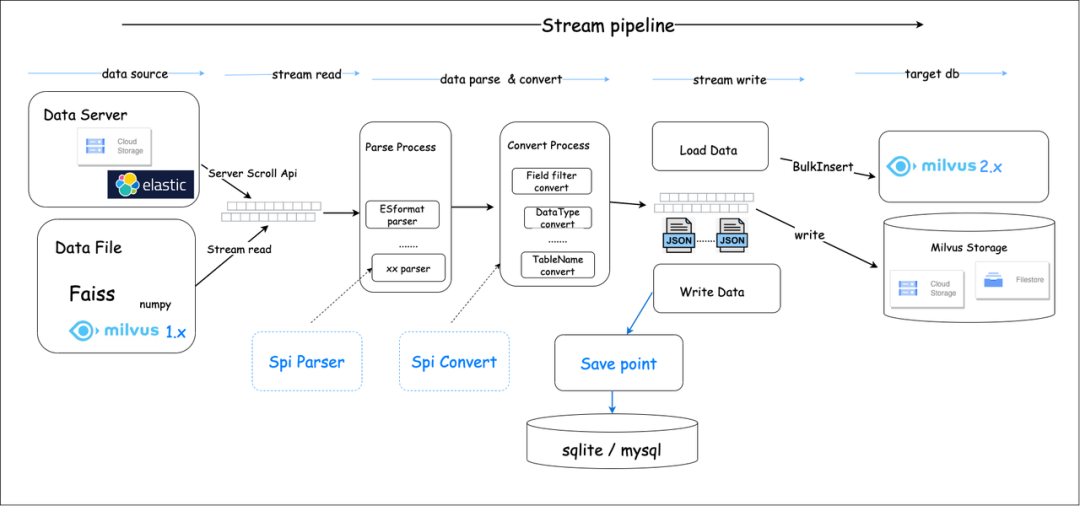
总体架构
编程语言
Milvus-migration 使用 go 语言实现.
交互方式
命令行
命令行是最简便直接的使用方式,Milvus-migration 基于 cobra 框架实现了命令行。
Restful Api
Milvus-Migration 还提供 Restful API,便于工具服务化,并提供 Swagger UI。
Go module
Milvus-Migration 还可以作为 go module,集成到其他工具之中。
实现原理
对于迁移 Milvus 1.x 和 Faiss 数据,主要会对原始数据文件内容进行解析,编辑转换成 Milvus 2.x 对应的数据存储格式,然后通过调用 Milvus sdk 的 bulkInsert 将数据写入,整个数据解析转换过程为流式处理,处理的数据文件大小理论上只受磁盘空间大小限制。数据文件支持存放在 Local File、S3、OSS、GCP 和 Minio。
对于迁移 Elasticsearch 数据,不同之处数据获取不是从文件,而是通过 ES 提供的 scroll api 能力 将 ES 数据依次遍历获取,从而解析转成 Milvus 2.x 存储格式文件,同样是调用 bulkInsert 将数据写入。除了对存储在 ES dense_vector 类型的向量进行迁移,也支持 ES 其他字段的迁移,目前支持的其他字段类型有:long、integer、short、boolean、keyword、text、double。
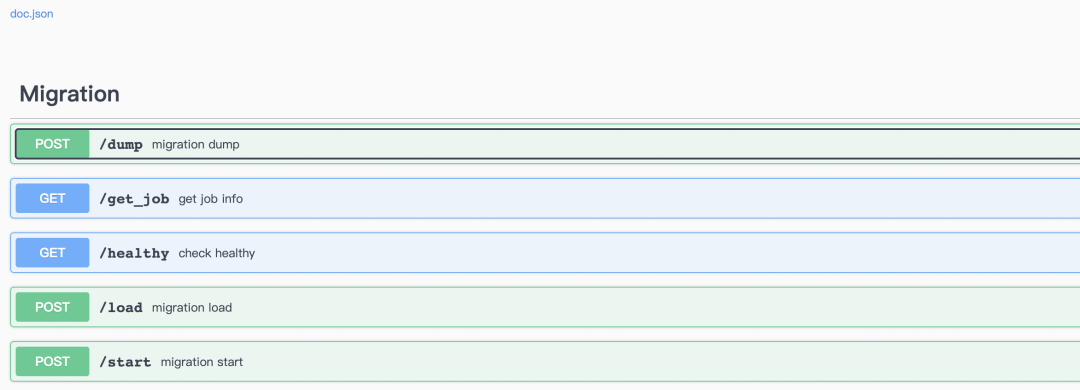
接口定义
/start - 开启一个迁移 job(相当于 dump 和 load 的结合,目前只支持 ES 迁移)
/dump - 开启一个迁移 dump job (将source数据 写入到 target 所在的存储介质中)
/load - 开启一个迁移 load job(将写入 target 存储介质的数据 写入到 Milvus 2.x)
/get_job - 查看 job 运行结果
详情可参考 https://github.com/zilliztech/milvus-migration/blob/main/server/server.go。
03.功能演示
下面使用项目中的例子来讲解 Milvus-migration 的使用方法。示例可在项目 README.md 中找到。
Elasticsearch -> Milvus 2.x
1. 准备 ES 数据
要迁移 ES 数据,前提假设您已经拥有属于自己的 es Server(自建、ElasticCloud、阿里云 ES 等),向量数据存储在 dense_vector,以及其他字段在 index 中,index mapping 形式如:

2. 编译打包
首先下载迁移项目源码:https://github.com/zilliztech/milvus-migration
执行: go get & go build,编译完成会在当前路径下产生可执行文件: milvus-migration。
3. 配置 migration.ymal config
开始迁移之前, 还需要准备迁移配置文件:包含数据的 source、target 数据等信息,内容示例如下:
dumper:
worker:
workMode: elasticsearch ------ 工作模式:elasticsearch
reader:
bufferSize: 2500 --------- 从es每次批量获取的数量
meta:
mode: config -------- 固定写法,其他数据源迁移会有其他不同值
index: test_index -------- es index
fields: -------- 需要同步的es字段有哪些:
- name: id -------- es 字段名
pk: true -------- pk=true,表示这个字段作为milvus的主键, 没设置情况下默认会采用es document _id作为主键
type: long
- name: other_field
maxLen: 60 ------- 对应milvus VarChar字段类型的maxLen, 对于varchar类型不设置maxLen则默认最大值:65535
type: keyword
- name: data
type: dense_vector ------- 向量字段,对应milvus的 field_vector类型, 必须迁移有dense_vector的字段
dims: 512
milvus: ------- 这部分配置非必填,设置生成的milvus表的属性,为空则按默认值
collection: "rename_index_test" --- 表名,为空则 esIndex作为表名
closeDynamicField: false --- 为空默认为false(开启动态列功能)
consistencyLevel: Eventually --- 一致性,为空按 milvus的默认级别
shardNum: 1 --- 分片数量,为空默认为2
source: ------- es server连接配置信息,支持 serviceToken,fingerprint,cloudId/apiKey,user/pwd,ca.crt 等方式连接/认证
es:
urls:
- http://localhost:9200
username: xxx
password: xxx
target: ------ 迁移到目标mivlus的bucket信息
mode: remote
remote:
outputDir: outputPath/migration/test1
cloud: aws
region: us-west-2
bucket: xxx
useIAM: true
checkBucket: false
milvus2x:
endpoint: {yourMilvusAddress}:{port}
username: ******
password: ******
关于配置文件更加详细的介绍,请参考项目 README.md。
4. 执行迁移 job
将配置文件放入任意文件目录下,通过执行命令方式开启迁移任务:
./milvus-migration start --config=/{YourConfigFilePath}/migration.yaml
观察日志输出,当出现类似如下日志表示迁移成功:
[task/load_base_task.go:94] ["[LoadTasker] Dec Task Processing-------------->"] [Count=0] [fileName=testfiles/output/zwh/migration/test_mul_field4/data_1_1.json] [taskId=442665677354739304]
[task/load_base_task.go:76] ["[LoadTasker] Progress Task --------------->"] [fileName=testfiles/output/zwh/migration/test_mul_field4/data_1_1.json] [taskId=442665677354739304]
[dbclient/cus_field_milvus2x.go:86] ["[Milvus2x] begin to ShowCollectionRows"]
[loader/cus_milvus2x_loader.go:66] ["[Loader] Static: "] [collection=test_mul_field4_rename1] [beforeCount=50000] [afterCount=100000] [increase=50000]
[loader/cus_milvus2x_loader.go:66] ["[Loader] Static Total"] ["Total Collections"=1] [beforeTotalCount=50000] [afterTotalCount=100000] [totalIncrease=50000]
[migration/es_starter.go:25] ["[Starter] migration ES to Milvus finish!!!"] [Cost=80.009174459]
[starter/starter.go:106] ["[Starter] Migration Success!"] [Cost=80.00928425]
[cleaner/remote_cleaner.go:27] ["[Remote Cleaner] Begin to clean files"] [bucket=a-bucket] [rootPath=testfiles/output/zwh/migration]
[cmd/start.go:32] ["[Cleaner] clean file success!"]
除了使用命令方式,项目也支持 Restful api 来执行迁移。首先执行如下命令来启动 Restful api server:
./milvus-migration server run -p 8080
看到以下日志表示服务启动成功:

将 migration.yaml 配置放在当前项目的 configs/migration.yaml, 然后调用api 来启动迁移:
curl -XPOST http://localhost:8080/api/v1/start
当迁移结束后,我们也可以通过 Attu 来查看迁移成功的总行数,也可以在 Attu 进行 load collection操作;而 collection 主键和 vector 字段建立 autoIndex 索引在迁移过程会自动创建好。
访问 swagger 来查看服务提供的 api:http://localhost:8080/docs/index.html
ES 到 Milvus 2.x 迁移就介绍到这里,下面我们来看下 milvus1.x -> 2.x 迁移过程。
Milvus 1.x -> Milvus 2.x
1. Milvus 1.x 数据准备 - (可跳过,Zilliz Cloud上的 Milvus 用户迁移会用到)
为了让用户快速体验,在项目源码的 testfiles目录下放置了1w 条 Milvus 1.x 测试数据在test1/目录下,目录结构:包含 tables 和 meta.json 两部分。快速体验可用该测试数据:

正常情况用户需要导出自己的 Milvus 1.x 的 meta.json文件,导出方式可通过命令:
./milvus-migration export -m "user:password@tcp(adderss)/milvus?charset=utf8mb4&parseTime=True&loc=Local" -o outputDir
其中 user/password/address 为 Milvus1.x 使用的 mysql;会导出到 outputDir,导出前 Milvus1.x server 需要停机或者停止写入数据。随后将 Milvus 的 tables文件夹进行copy和meta.json放到同一个目录下面。(Milvus 的 tables文件夹一般在 /${user}/milvus/db/tables )
目录结构如下:
filesdir
--- meta.json
--- tables
当准备好数据后,如果使用的 Milvus 2.x 在 Zilliz Cloud云,则可直接在 cloud console 页面进行迁移操作。
2. 编译打包
项目源码编译同上,最终生成可执行文件: milvus-migration (在上面的 export 命令中也是使用该文件命令)
3.配置 migration.ymal config
dumper:
worker:
limit: 2
workMode: milvus1x ------ 工作模式:milvus1x
reader:
bufferSize: 1024 ----- file reader/writer buffer size
writer:
bufferSize: 1024
loader:
worker:
limit: 16 ------- 支持同时并发迁移的表数量
meta:
mode: local ------ meta.json文件存放方式,有:local, remote, mysql, sqlite,
localFile: /outputDir/test/meta.json
-- mode: mysql # milvus的元数据mysql地址
-- mysqlUrl: "user:password@tcp(localhost:3306)/milvus?charset=utf8mb4&parseTime=True&loc=Local"
source: ----- milvus1.x talbes目录文件存储源,可以在local, s3,minio,oss,gcp
mode: local
local:
tablesDir: /db/tables/ --数据文件tables目录
target: ------ 数据通过bulkInsert写入的目标存储位置,
mode: remote --- 写入的存储的方式可以可以是:remote 和 local(仅验证dump功能使用)
remote:
outputDir: "migration/test/xx" --写入的路径
ak: xxxx
sk: xxxx
cloud: aws ------ 写入的cloud, 可以是aws, gcp, ali, (如果是minio也填写aws)
region: us-west-2
bucket: xxxxx
useIAM: true
checkBucket: false
milvus2x:
endpoint: "{yourMilvus2_xServerAddress}:{port}"
username: xxxx
password: xxxx
关于 migration.yaml 配置文件更加详细的介绍,请查看项目 README.md。
4.执行迁移 Job
不同于 ES 的迁移使用一个命令即可完成迁移,目前 Milvus 1.x 和 Faiss 迁移需要执行 dump 和 load 两个命令(后期规划会改造成一个指令即可)。
-
dump 命令
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml
它将 Milvus 1.x 文件数据转为 numpy 文件通过 bulkInsert 写入 target bucket.
-
load 命令
执行 load 命令,将转换好的数据文件导入到 Milvus 2x 里面:
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
最终在 Milvus 2.x中,生成的 collection 中会有两个字段:id 和 data, 可通过 Attu 查看 collection。
Faiss -> Milvus 2.x
1. Faiss 数据准备
前提条件是用户已经准备好了自己的 faiss 数据文件。(为了能快速体验,在项目源码的 testfiles 目录下放置了 faiss 测试数据方便用户体验: faiss_ivf_flat.index.

2. 编译打包
这部分同上,不再展开介绍。
3. 配置 migration.ymal config
dumper:
worker:
limit: 2
workMode: faiss ------ 工作模式:faiss
reader:
bufferSize: 1024
writer:
bufferSize: 1024
loader:
worker:
limit: 2
source:
mode: local ---- 数据源可以为 local和 remote
local:
faissFile: ./testfiles/faiss/faiss_ivf_flat.index
target:
create: ----- 指定生成的collection属性
collection:
name: test1w
shardsNums: 2
dim: 256
metricType: L2
mode: remote
remote: ------- 下面配置是将数据写入到本地搭建的minio中,milvus2x也是本地
outputDir: testfiles/output/
cloud: aws ---- 同样支持 aws, gcp, ali
endpoint: 0.0.0.0:9000
region: ap-southeast-1
bucket: a-bucket
ak: minioadmin
sk: minioadmin
useIAM: false
useSSL: false
checkBucket: true
milvus2x:
endpoint: localhost:19530
username: xxxxx
password: xxxxx
关于Faiss 的 migration.yaml 配置文件更加详细的介绍,请查看项目 README.md
4. 执行迁移 Job
-
dump 命令
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml
它将 Faiss 文件数据转为numpy 格式文件通过 bulkInsert 写入 target bucket.
-
load 命令
执行 load 命令,将转换好的数据文件导入到 Milvus 2x 里面:
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
完成后可通过 Attu 查看生成的 collection 信息进行验证。
04.未来规划
-
支持 Redis 迁移到 Milvus
-
支持 Mongodb 迁移到 Milvus
-
支持迁移过程断点续传
-
简化迁移命令:合并 dump 和 load 过程
-
支持其他数据源迁移到 Milvus
参考资料
-
Milvus-migration: https://github.com/zilliztech/milvus-migration
-
Attu: https://milvus.io/docs/attu.md
-
bulkinsert: https://milvus.io/docs/bulk_insert.md
-
官方文档: https://milvus.io/docs
-
ES scroll api: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/paginate-search-results.html#scroll-search-results
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。
-
欢迎关注微信公众号“Zilliz”,了解最新资讯。
本文由 mdnice 多平台发布