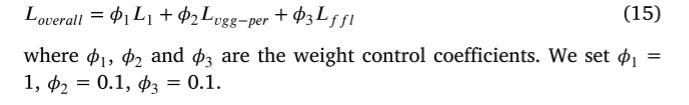DBCT-Net:A dual branch hybrid CNN-transformer network for remote sensing image fusion
(DBCT-Net:一种用于遥感图像融合的双分支混合CNN-transformer网络)
遥感图像融合是指将高空间分辨率的单波段全色图像与光谱信息丰富的多光谱图像进行融合,生成具有高分辨率和颜色信息的全色锐化图像,也称为全色锐化。大多数提出的单卷积神经网络(CNN)或基于变换的泛锐化方法都存在一些问题,例如无法获取长距离特征或难以训练,从而导致空间细节和颜色的损失。此外,Transformer的计算复杂度也不容忽视。在这项工作中,我们提出了一个双分支混合CNN-Transformer网络(DBCT-Net),该网络利用CNN的局部特异性,并通过transformer对全局依赖关系进行建模。首先,多分支密集连接块(MDCB-4)网络的设计,以分别获得光谱和纹理信息的MS和PAN图像。接下来,基于自注意和共同注意模块的编码器-解码器Transformer能够注入缺失的局部和全局信息,这可以进一步增强结果。值得注意的是,一个倒置的多头转置注意力(IMTA) 在这里被应用到从特征维度构建注意力地图,这大大减少了计算时间。最后,图像重建模块,以有效地融合所获得的纹理和光谱特征。此外,为了生成视觉上更好的泛锐化图像,我们提出了一个组合的损失函数,其中包括一个焦点频率损失。在WorldView II(WV 2)、GF-2和QuickBird(QB)数据集上的大量实验表明,DBCT-Net在空间保持和光谱特征恢复方面表现更好。
Introduction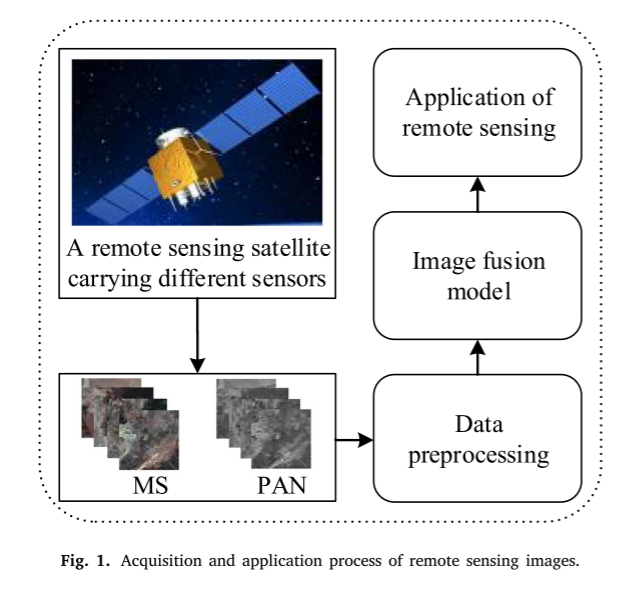
遥感图像为地理系统提供了重要的数据,在一些常见的领域有着广泛的应用。多光谱(MS)和全色(PAN)图像可以由地球观测卫星提供,如高分二号,WorldView和QuickBird。多光谱和全色成像是两种众所周知的遥感技术,它们在空间和光谱分辨率上各不相同(图1)。PAN图像的空间细节特征比MS图像丰富得多,能记录物体表面更多的纹理和细节信息;而MS图像的光谱信息比PAN图像丰富得多,是保存地物光谱信息的重要载体。由于现有传感器技术和物理条件的限制,获取包含丰富空间细节和光谱信息的综合遥感图像是当前遥感卫星面临的挑战。然而,在一些实际应用中,如气象观测,环境监测,语义分割和植被分类,往往需要高质量的遥感图像(图2)。为了解决上述问题,融合两种图像的全色锐化技术应运而生。随后,全色锐化技术被许多研究者应用于图像处理和遥感领域。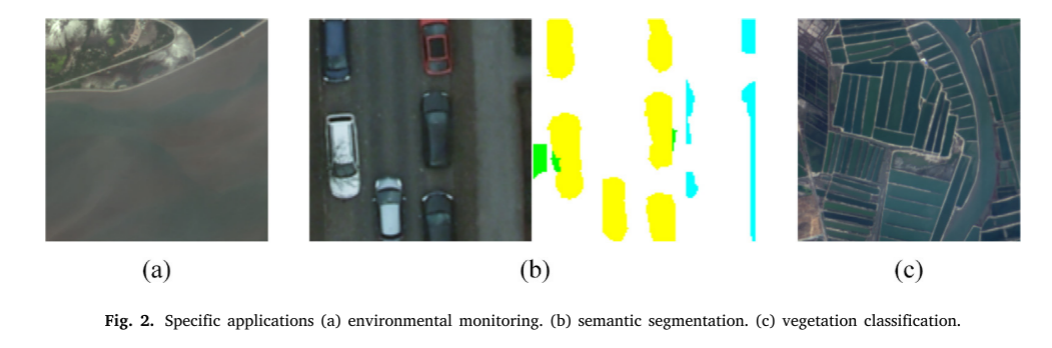
泛锐化是一种经典的图像融合方法,与图像恢复和超分辨率任务有关。到目前为止,泛锐化方法已经提出了几十年。经典的泛锐化方法包括分量替换(CS)、多分辨率分析(MRA)和深度学习(DL)方法。不同方法的优点和缺点如图3所示。基于CS的方法的主要思想是通过谱变换将MS波段的特征映射到另一个空间。接下来,用PAN图像替换MS图像的空间特征。最后,变换后的分量被转移到MS图像域,这是通过逆变换操作来实现的。代表性的方法包括主成分分析(PCA)、强度-色调-饱和度(IHS)和Gram-Schmidt(GS)光谱锐化方法。基于压缩感知的方法计算量小,能够恢复出与原始图像相似的主要空间特征。然而,基于该方法的模型通常导致光谱信息的损失。
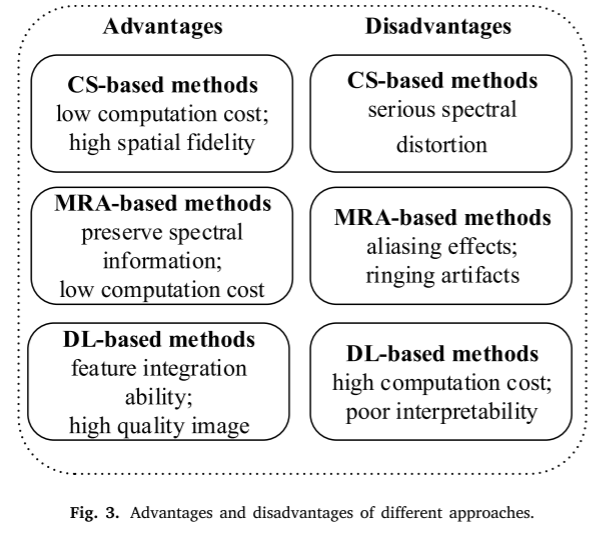
基于MRA的方法被广泛用于全色锐化,因为它们可以有效地保留光谱信息。在基于MRA的方法中,两种类型的图像通过一个专门设计的转换函数转换到尺度水平。接下来,选择子层的全色图像的空间特征并将其添加到相同级别的MS分解图像。最后,我们可以通过逆分解过程获得所需的融合图像。典型的基于MRA的方法包括高通滤波器(HPF),Indusion和à trous小波变换(ATWT)。在基于MRA的方法中,图像和滤波器的特征水平与全色锐化的结果密切相关。因此,使用不成熟的模型进行图像融合会丢失大量的空间信息。
近年来,基于深度学习的模型在图像处理方面取得了巨大的进步,这极大地启发了泛锐化领域的研究人员。Hong等人开发了一种通用的多模态深度学习(MDL)框架,该框架在细粒度分类任务中表现出色。然后,他们提出了一种新的minibatch GCN,以减少计算量。Wu,Hong和Chanussot提出了一种由跨通道重建模块构建的CCR-Net,可以更有效地相互交换信息。Tang,Deng,Ma,Huang和Ma提出了一种图像配准和融合模型,以实现自适应特征融合和语义要求。Adam Glowacz提出了一种新的特征提取方法PNID,显著提高了热成像故障诊断和识别的效率。Wu,Hong和Chanussot提出了用于检测小对象的UIU-Net,它可以从不同层次和尺度学习特征信息。卷积神经网络(称为PNN)的泛锐化受到图像处理模型结构的启发。Masi等人设计了一个3层CNN,通过引入非线性辐射指数来增加输入。这项工作极大地启发了后来的研究者,涌现出许多优秀的作品。然而,许多传统的模型简单地处理泛锐化作为一个通用的图像处理问题,不知道光谱和空间保存。考虑到两幅遥感图像所承载的信息不同,一些研究人员使用不同的模型分别获得不同图像的边缘和光谱特征。基于CNN的模型具有很强的局部特征整合能力,倾向于关注小图像块的特征信息。
基于自我注意机制的Transformer,在许多自然语言处理(NLP)任务中发挥着不可或缺的作用,其特征提取和构建能力在更长的距离。Vaswani等人。这使得它不仅能够获得本地信息,而且能够专注于完整的上下文。随后,Transformer以其令人印象深刻的效果在CV领域占据了突出的位置,例如图像分类、对象检测和图像超分辨率。同样,Transformer也适用于全色锐化。研究发现,提取PAN图像和MS图像之间的互补信息是非常重要的,而将两者紧密结合是减少光谱失真的关键。现有研究表明,视觉Transformer(ViT)在图像超分辨率和图像融合任务中具有与基于CNN的方法竞争的性能。然而,由于自注意机制的计算方法的特点,基于变换器的模型通常具有大量的参数,推理速度受到严重限制。
总体而言,基于CNN或Transformer泛锐化方法已经出现了一些优秀的作品,但仍有改进的空间。为了缓解这些问题,并联合收割机CNN和Transformer网络的优点,我们提出了一种双分支混合CNNTransformer网络(DBCT-Net)。流程图如图4所示。在三个流行数据集上的实验验证了该模型具有最好的融合效果。本文的主要贡献如下。
1.我们提出了一种新的双分支混合CNN-Transformer网络(称为DBCT-Net)用于泛锐化,它使用MDCB-4块和编码器-解码器变换器来学习局部-全局信息。
2.我们提出了一种新的多分支稠密连接块(MDCB 4)网络来捕获不同尺度的图像特征,我们还添加了局部稠密连接来提取丰富的层次特征。建议的MDCB-4是计算友好的,最大限度地减少空间和频谱失真。
3.为了降低计算复杂度并整合同一通道内和跨通道的远程依赖关系,我们的编码器-解码器Transformer采用倒置的多头转置注意(称为IMTA)分别构建自注意和共注意模块。我们还发现,在Transformer块之后添加DW-bottleneck block(DWBN)可以进一步提高模型性能。
4.为了生成视觉上更好的泛锐化图像,我们提出了一个组合损失函数来生成高质量的泛锐化图像。该损失函数由𝐿1损失、VGG感知损失和焦点频率损失组成。三个常见的数据集上的实验证实,我们的DBCT-Net具有优势的SOTA方法。
Related work
Depthwise separable convolution
卷积神经网络在图像处理中有着广泛的应用。它可以通过简单的卷积运算提取源图像的关键特征。但由于硬件设备的限制,减少模型的计算量仍然是模型结构优化的重点。深度可分离卷积旨在解决上述问题。它类似于传统的卷积运算,但与传统版本相比,参数的数量和计算开销显著减少。其主要设计思想是将传统的卷积运算分为两步,即深度卷积(DWConv)和逐点卷积(PWConv)。深度卷积在每个通道上执行卷积操作,以获得质量更好的特征图。然而,DWConv不能有效地利用其他通道的特征。因此,PWConv是集成特征信息的非常重要的操作。通常,PW卷积的卷积核大小设置为1 × 1 × h,其中h是相邻卷积层的数量。使用深度可分离卷积的优点在于,通过逐步操作可以显著降低计算复杂度,这使得网络设计更加灵活。
Vision transformer
与卷积运算的本地属性不同,Transformer架构使用多线程全局注意力机制来在不同有序输入特征之间进行远程建模。Vaswani等人在Transformer在NLP任务中取得成功之后,更多的研究人员开始将其应用于计算机视觉任务。Zhang等人提出了一种基于金字塔的双向融合网络来整合不同尺度的细节,并取得了良好的效果。在此基础上,为了从不同的图像中提取和保留更多的特征信息,提出了一些新的多级Transformer方法来实现全色锐化任务。在HyperTransformer中,光谱特征提取模块用于分别获得高光谱图像和PAN的有效特征,这有助于学习长程依赖性,并提高融合图像的光谱和空间特征质量。Liu等人引入了一种局部移动窗口机制,可以灵活地对不同的图像尺度进行建模。以这种方式,计算复杂度映射到线性范围内的图像大小。Zamir等人设计了一种新的注意力,将自我注意力应用于通道维度而不是空间维度。这种设计提高了模型的整体效率,并保留了局部-全局表示学习能力。由于计算特性的限制,传统的Transformer很难处理高分辨率的图像。此外,Transformer特别擅长对远程依赖项进行建模。然而,局部特征信息也应该被保持用于视觉感知。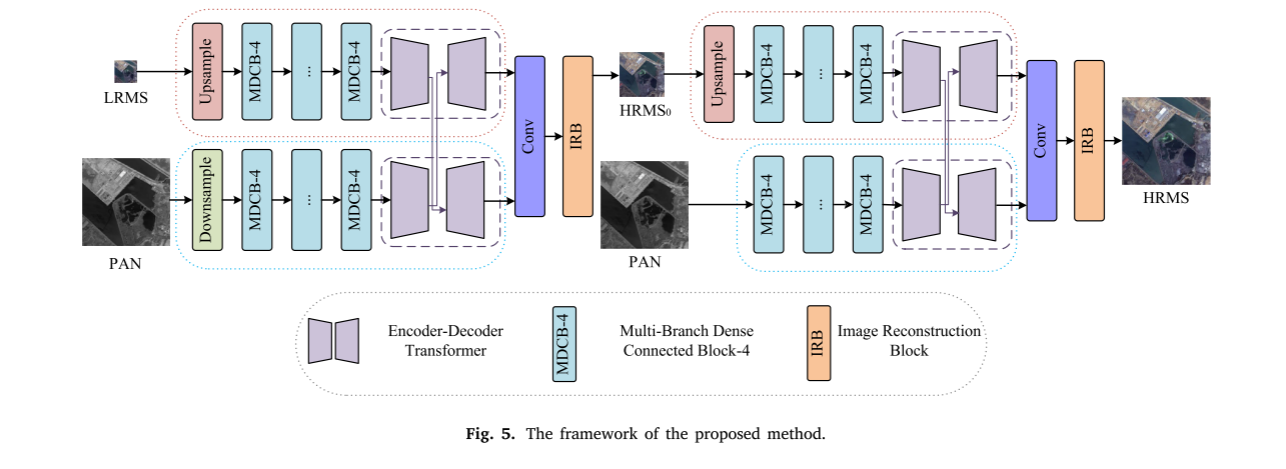
Hybrid models
一些研究人员尝试减少计算量并取得了良好的效果(,但是难以保留局部特征信息。Srinivas等人提出了BoTNet。该网络将注意力模块集成到ResNet 50的原始瓶颈结构中。它不仅结合了CNN的局部特征和Transformer的整体图像聚焦特征,而且大大降低了计算量。也为Transformer提供了一种新的关于混合网络的思考方式,随后提出了一批优秀的作品。Xia等人通过阶段到块的分层路线设计了ViT的架构,并给出了高效混合模型设计中的实用原则。Chen等人提出了一种MobileNet-Transformer的并行结构,它利用了两种模型的优点,提高了计算效率。然而,我们发现用于全色锐化的混合模型是极其罕见的。因此,在这项工作中,我们引入了一个双分支混合网络的pansharpening。
Proposed method
Overall network structure
我们的目标是利用CNN和Transformer的优势来开发一个高效的混合网络,该网络可用于pansharpening。一些优秀的作品已经证明在后期使用Transformer块可以最大限度地提高效率和性能; CNN-Transformer混合架构比单个Transformer或CNN模型更有效。我们的网络设计遵循相同的原则,图5显示了我们提出的DBCT-Net。将MS图像作为一个分支的输入,并且将对应的PAN图像用作另一分支的输入。综合两幅图像的细节特征和光谱信息,生成具有丰富特征信息的HRMS图像。我们将PAN图像表示为尺寸为W×H×1的𝐼𝑃𝐴𝑁,将相应的LRMS图像表示为尺寸为W/4×H/4×N的𝐼𝐿𝑅𝑀𝑆,将地面实况图像HRMS表示为尺寸为W×H×N的𝐼𝐺𝑇。这里W和H分别表示LRMS图像的宽度和高度,N是卫星图像的通道数。我们将整个全色锐化过程定义如下
其中𝐻𝑁𝑒𝑡(.)表示所提出的DBCT-Net方法。
具体而言,输入LRMS 𝐼𝐿𝑅𝑀𝑆然后利用编解码Transformer的共同注意机制来学习和整合非局部信息。该过程可以描述如下
与前面的操作类似,PAN图像的处理可以描述如下
最后,通过3 × 3卷积运算和图像重建模块,得到了全色锐化的MS图像。流程如下
MDCB-4 module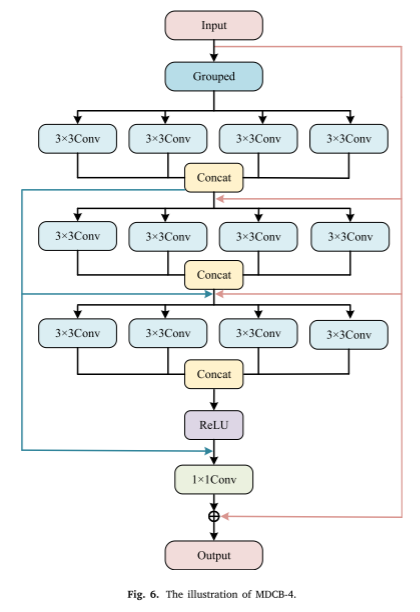
图像融合需要精确而密集的像素处理操作。为了提取高维特征,卷积网络一般进行更深的卷积,但这带来了网络扩大和信息丢失的问题。受Xception(Chollet,2017)的启发,我们可以设计一个更广泛的网络来提取高维特征。这样的设计不仅保证了网络的质量,还扩大了接收域,保留了更多的信息。MDCB 4网络由多个MDCB-4块堆叠而成,用于提取不同层次的光谱和细节特征。MDCB-4模块的结构如图6所示。首先,我们将特征图划分为一个小组,这是通过1 × 1 PW卷积运算实现的。然后,通过3 × 3卷积运算将该特征图分成四个相等大小的组。四个分支被单独处理,并且不同的路径彼此不完全连接,这减少了计算工作量和存储负担。我们在卷积层之间添加局部密集连接,以提取不同层的丰富局部特征信息。这种方法允许上层直接连接到所有后续层,从而实现功能集成和重用。最后通过卷积运算自适应融合各层特征,卷积核大小为1 × 1。保留低频信息也很重要,因此我们使用逐元素加法操作来连接输入特征。MDCB-4的输出可以定义如下
Encoder-decoder transformer
在本节中,我们描述了一种基于反向多头转置注意力(IMTA)的Transformer结构,以增强高维特征的表示,如图7(a)所示。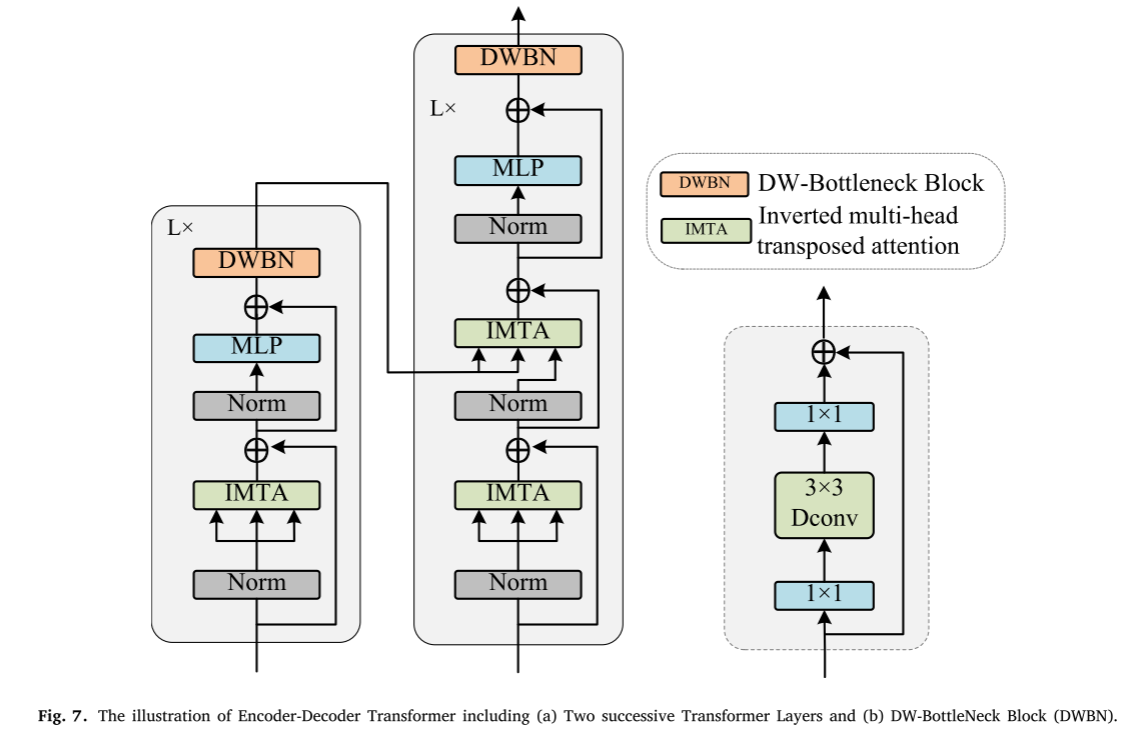
Inverted multi-head transposed attention (IMTA)
注意机制是Transformer的组成部分,并且是编码器和解码器的组成部分。同时,自关注的运行机制大大增加了Transformer网络的计算量。在传统的注意力机制中,关键字查询点积需要大量的运算开销,使得高分辨率图像处理任务变得困难。为了缓解这个问题,Zamir等人提出了一种称为多dconv头转置注意(MDTA)的注意。它在一定程度上降低了运行成本,但也存在一些问题。例如,单独的深度卷积不能有效地利用相同空间位置处的其他通道的特征信息,这是由深度卷积的独特的每通道卷积方法引起的不利影响。我们提出IMTA以减少计算时间并利用不同特征图的空间信息,具体设计如图8所示。IMTA通过基于反转残差结构的深度卷积来计算跨通道的交叉协方差,以生成关注全局上下文的注意力图。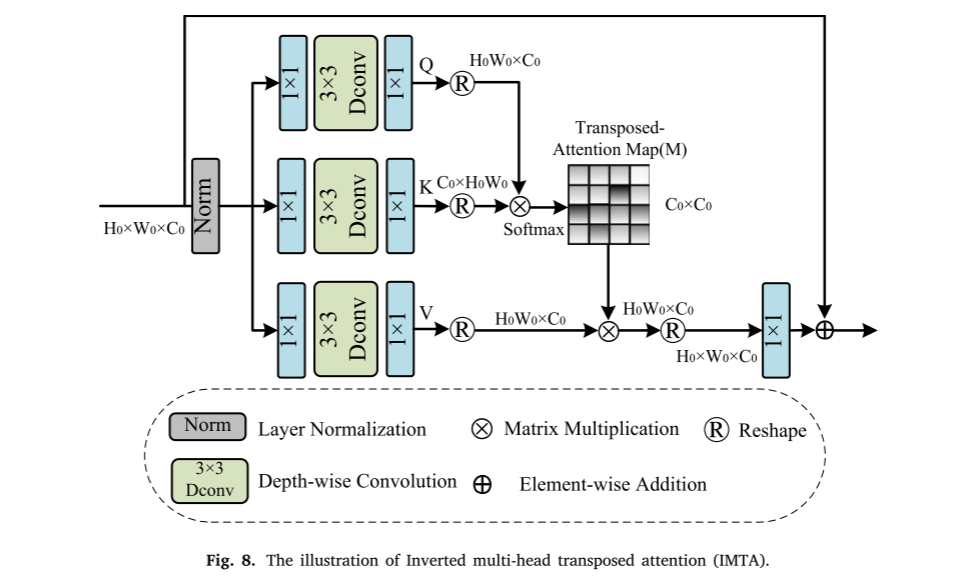
具体过程如下。在层归一化张量X∈
R
H
0
W
0
C
0
R^{H0W0C0}
RH0W0C0之后,我们的IMTA首先通过应用1 × 1卷积扩展层来聚合像素级信息,然后使用3 × 3深度卷积操作来编码通道级特征空间信息,然后使用1 × 1卷积投影层来聚合像素级跨通道信息以生成查询(Q),键(K)和值(V)。𝑊我们可以灵活地控制通道的数量,并通过扩散因子t进一步减少计算开销。
然后,我们重新塑造Q和V,使它们的点积投影生成大小为C0×C0的转置注意力图。通常,顶TA注意机制可以被定义为
Transformer encoder
我们的编码器的整体结构类似于ViT的构造(Vaswani等人,2017),但它包含一个反向多头转置注意(IMTA)模块和一个多层感知器(MLP)网络。此外,使用GELU非线性函数来构造多层感知器网络(MLP)。层归一化(LN)可以提高信息处理的效率,添加局部残差可以进一步整合不同层次的特征信息。当第一次进入编码层时,F0在归一化操作之后进入IMTA模块,并且输出随后与F0相加,表示为F’0。类似地,F’0被添加到MLP网络的输出。因此,编码器中的上层的输出用作下一层的输入,并且该过程在等式(7)和(8)中示出。
通过编码器对不同阶段的特征进行编码,可以得到更多的高维特征。
Transformer decoder
与Transformer编码器的整体设计类似,Transformer解码器也具有IMTA模块和MLP网络,但增加了共同关注IMTA模块。共同关注模块可以有效地处理解码器的输入表示信息和连接的编码器的输出表示信息。接下来,这些表示被融合以增强更高维的特征。整个计算过程可以表示为
其中S是编码器和解码器的层数,为了效率和性能,我们将其设置为4。值得注意的是,我们在编解码端都增加了DWBottleneck块,它是在Bottleneck块的基础上,将3 × 3常规卷积替换为3 × 3 DP卷积,具体结构如图7(b)所示。这种先全局后局部的处理方式可以进一步提高网络的融合效果,这一点也在后面的实验中得到了验证。
图像重建模块被用作我们的DBCTNet的结束。该模块使用常规卷积来重建最终图像,我们将卷积大小设置为3 × 3。我们还添加了Relu激活函数,以提高网络的整体表现力。
Loss function
我们使用三个损失函数的组合来约束我们的网络。考虑到L1损失的广泛应用,我们采用L1损失作为重建损失函数。此外,为了捕获感知差异,例如纹理和边缘,我们使用VGG感知损失。除了空间损失外,频率信息对图像处理的重要性也不容忽视。受图像重建的启发,我们将焦频损失引入到全色锐化领域,取得了较好的效果。
VGG perceptual loss. Alahi和Fei-Fei提出了一种新的感知损失,用于生成高质量图像。感知损失可以捕获细节并使预测图像更接近地面实况图像。该损失函数可以被描述为Eq.(13)。
Focal frequency loss.
通常,地面实况和预测图像在频带中显著不同。为了缩小这种差异,Jiang等人在一些实施例中,图像处理器使用标准傅里叶变换将图像变换成其频率表示,这优化了频域中的生成模型。焦频损失的计算过程如下。
我们的损失函数在等式(15)中示出