文章目录
- 概述
- 形式
- 原理理解
- 源代码实现
- 1.BatchNorm2d
- 2.LayerNorm
- 3.InstanceNorm
- 4.GroupNorm
概述
本文记录总结pytorch中四种归一化方式的原理以及实现方式。方便后续理解和使用。
本文原理理解参考自
https://zhuanlan.zhihu.com/p/395855181
形式
四种归一化的公式都是相同的,即
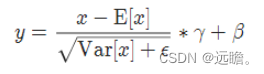
其实就是普通的归一化公式,
((x-均值)/标准差)*γ +β
γ和β是可学习参数,代表着对整体归一化值的缩放(scale) γ和偏移(shift) β。
四种不同形式的归一化归根结底还是归一化维度的不同。
| 形式 | 原始维度 | 均值/方差的维度 |
|---|---|---|
| BatchNorm2d | NCHW | 1C11 |
| LayerNorm | NCHW | N111 |
| InstanceNorm | NCHW | NC11 |
| GroupNorm | NCHW | NG11 (G=1,LN,G=C,IN) |
原理理解
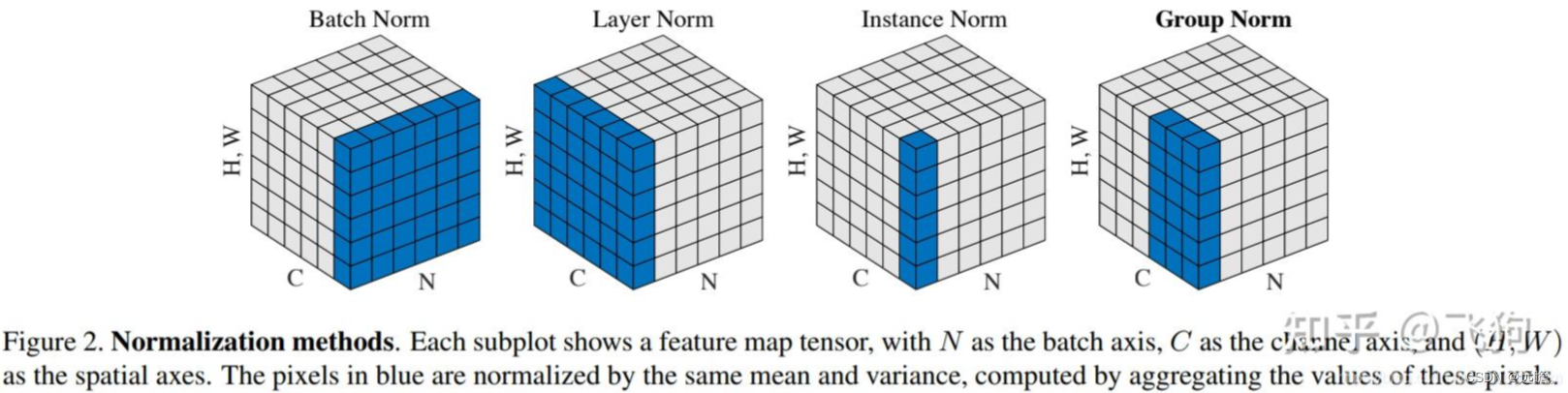
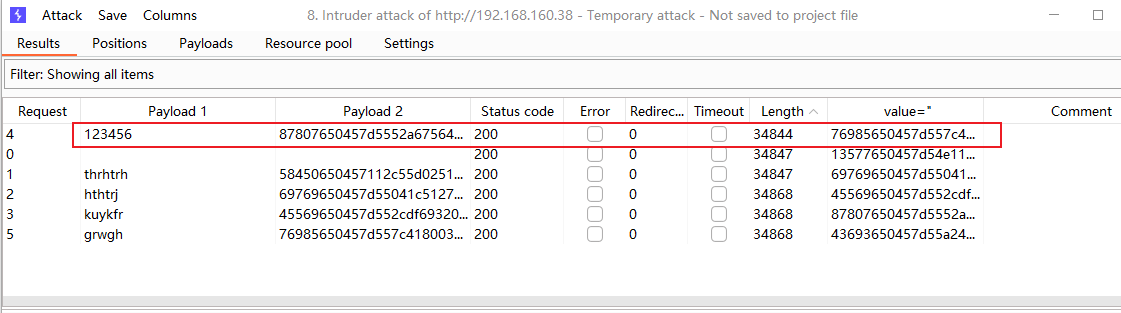
- BatchNorm2d 从维度上分析,就是在NHW维度上分别进行归一化,保留特征图的通道尺寸大小进行的归一化。
由上图理解,蓝色位置代表一个归一化的值,BN层的目的就是将每个batch的hw都归一化,而保持通道数不变。抽象的理解就是结合不同batch的通道特征。因此这种方式比较适合用于分类,检测等模型,因为他需要对多个不同的图像有着相同的理解。 - LayerNorm 从维度上分析,就是在CHW上对对象的归一化,该归一化的目的可以保留每个batch的自有特征。抽象上来理解,就是通过layernorm让每个batch都有不同的值,有不同的特征,因此适用于图像生成或RNN之类的工作
- InstanceNorm从维度上来分析,就是将HW归一化为一个值,保留在通道上C和batch上的特征N。相当于对每个batch每个通道做了归一化。可以保留原始图像的信号而不混杂,因此常用于风格迁移等工作。
- GroupNorm从维度上来分析,近似于IN和LN,但是就是在通道上可以分成若干组(G),当G代表权重通道时就变成了LN,当G代表单通道就变成了IN,我也不清楚为什么用这个,但是G通常好像设置为32.
源代码实现
结合以上理解,就可以从原理上实现pytorch中封装的四个归一化函数。如下所示。
1.BatchNorm2d
import torch
import torch.nn as nn
class CustomBatchNorm2d(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1,scale=1,shift=0):
super(CustomBatchNorm2d, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# 可训练参数
self.scale = scale
self.shift = shift
# 不可训练的运行时统计信息
self.running_mean = torch.zeros(num_features)
self.running_var = torch.ones(num_features)
def forward(self, x):
# 计算输入张量的均值和方差
mean = x.mean(dim=(0, 2, 3), keepdim=True)
print("mean.shape",mean.shape)
var = x.var(dim=(0, 2, 3), unbiased=False, keepdim=True)
print("var.shape",var.shape)
# 更新运行时统计信息 (Batch Normalization在训练和推理模式下的行为不同)
if self.training:
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.squeeze()
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * var.squeeze()
# 归一化输入张量
x_normalized = (x - mean) / torch.sqrt(var + self.eps)
# 应用 scale 和 shift 参数
scaled_x = self.scale.view(1, -1, 1, 1) * x_normalized + self.shift.view(1, -1, 1, 1)
return scaled_x
if __name__ =="__main__":
# 创建示例输入张量
x = torch.randn(16, 3, 32, 32) # 示例输入数据
scale = nn.Parameter(torch.randn(x.size(1)))
shift = nn.Parameter(torch.randn(x.size(1)))
# 创建自定义批量归一化层
custom_batchnorm = CustomBatchNorm2d(num_features=3,scale=scale,shift=shift)
# 调用自定义批量归一化层
normalized_x_custom = custom_batchnorm(x)
# 创建官方的批量归一化层
official_batchnorm = nn.BatchNorm2d(num_features=3)
official_batchnorm.weight=scale
official_batchnorm.bias=shift
# 调用官方批量归一化层
normalized_x_official = official_batchnorm(x)
# 检查自定义层和官方层的输出是否一致
are_equal = torch.allclose(normalized_x_custom, normalized_x_official, atol=1e-5)
print("自定义批量归一化和官方批量归一化是否一致:", are_equal)
2.LayerNorm
import torch
import torch.nn as nn
class CustomLayerNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-5,scale=1,shift=0):
super(CustomLayerNorm, self).__init__()
self.normalized_shape = normalized_shape
self.eps = eps
# 可训练参数
# self.scale = nn.Parameter(torch.ones(normalized_shape))
# self.shift = nn.Parameter(torch.zeros(normalized_shape))
self.scale = scale
self.shift = shift
def forward(self, x):
# 计算输入张量 x 的均值和方差
mean = x.mean(dim=(1,2,3), keepdim=True)
variance = x.var(dim=(1,2,3), unbiased=False, keepdim=True)
# 归一化输入张量
x_normalized = (x - mean) / torch.sqrt(variance + self.eps)
# # 应用 scale 和 shift 参数
scaled_x = self.scale * x_normalized + self.shift
# 应用 scale 和 shift 参数
#scaled_x = self.scale.view(-1, 1, 1, 1) * x_normalized + self.shift.view(-1, 1, 1, 1)
return scaled_x
# 创建示例输入张量
x = torch.randn(16, 3, 32, 32) # 示例输入数据
scale = nn.Parameter(torch.randn(3,32,32))
shift = nn.Parameter(torch.randn(3,32,32))
# 创建自定义 Layer Normalization 层
#custom_layernorm = CustomLayerNorm(normalized_shape=16)
custom_layernorm = CustomLayerNorm(normalized_shape=(3,32,32),scale=scale,shift=shift)
# 调用自定义 Layer Normalization 层
normalized_x_custom = custom_layernorm(x)
# 创建官方的 Layer Normalization 层
#official_layernorm = nn.LayerNorm(normalized_shape=3)
official_layernorm = nn.LayerNorm(normalized_shape=(3,32,32))
official_layernorm.weight=scale
official_layernorm.bias=shift
#official_layernorm = nn.LayerNorm(normalized_shape=(0,2,3))
# 调用官方 Layer Normalization 层
normalized_x_official = official_layernorm(x)
#print(normalized_x_official.shape)
# # 检查自定义层和官方层的输出是否一致
are_equal = torch.allclose(normalized_x_custom, normalized_x_official, atol=1e-5)
print("自定义 Layer Normalization 和官方 Layer Normalization 是否一致:", are_equal)
3.InstanceNorm
import torch
import torch.nn as nn
class CustomInstanceNorm(nn.Module):
def __init__(self, num_features, eps=1e-5,scale=1,shift=0):
super(CustomInstanceNorm, self).__init__()
self.num_features = num_features
self.eps = eps
# 不可训练参数
# self.scale = nn.Parameter(torch.ones(num_features))
# self.shift = nn.Parameter(torch.zeros(num_features))
self.scale = scale
self.shift = shift
def forward(self, x):
# 计算输入张量 x 的均值和方差
mean = x.mean(dim=(2, 3), keepdim=True)
variance = x.var(dim=(2, 3), unbiased=False, keepdim=True)
# 归一化输入张量
x_normalized = (x - mean) / torch.sqrt(variance + self.eps)
# 应用 scale 和 shift 参数
scaled_x = self.scale.view(1, -1, 1, 1) * x_normalized + self.shift.view(1, -1, 1, 1)
return scaled_x
# 创建示例输入张量
x = torch.randn(16, 3, 32, 32) # 示例输入数据
# 创建自定义 Instance Normalization 层
scale = nn.Parameter(torch.randn(3))
shift = nn.Parameter(torch.randn(3))
custom_instancenorm = CustomInstanceNorm(num_features=3,scale=scale,shift=shift)
# 调用自定义 Instance Normalization 层
normalized_x_custom = custom_instancenorm(x)
# 创建官方的 Instance Normalization 层
official_instancenorm = nn.InstanceNorm2d(num_features=3)
official_instancenorm.weight=scale
official_instancenorm.bias=shift
# 调用官方 Instance Normalization 层
normalized_x_official = official_instancenorm(x)
# # 检查自定义层和官方层的输出是否一致
are_equal = torch.allclose(normalized_x_custom, normalized_x_official, atol=1e-5)
print("自定义 Layer Normalization 和官方 Layer Normalization 是否一致:", are_equal)
4.GroupNorm
import torch
import torch.nn as nn
class CustomGroupNorm(nn.Module):
def __init__(self, num_groups, num_channels, eps=1e-5,scale=1,shift=0):
super(CustomGroupNorm, self).__init__()
self.num_groups = num_groups
self.num_channels = num_channels
self.eps = eps
# 不可训练参数
self.scale = scale
self.shift = shift
def forward(self, x):
# 将输入张量 x 分成 num_groups 个组
# 注意:这里假定 num_channels 可以被 num_groups 整除
group_size = self.num_channels // self.num_groups
x = x.view(-1, self.num_groups, group_size, x.size(2), x.size(3))
# 计算每个组的均值和方差
mean = x.mean(dim=(2, 3, 4), keepdim=True)
variance = x.var(dim=(2, 3, 4), unbiased=False, keepdim=True)
# 归一化输入张量
x_normalized = (x - mean) / torch.sqrt(variance + self.eps)
# 将组合并并应用 scale 和 shift 参数
x_normalized = x_normalized.view(-1, self.num_channels, x.size(3), x.size(4))
scaled_x = self.scale.view(1, -1, 1, 1) * x_normalized + self.shift.view(1, -1, 1, 1)
return scaled_x
# 创建示例输入张量
x = torch.randn(16, 6, 32, 32) # 示例输入数据,有6个通道
# 创建自定义 Group Normalization 层
scale = nn.Parameter(torch.randn(6))
shift = nn.Parameter(torch.randn(6))
custom_groupnorm = CustomGroupNorm(num_groups=3, num_channels=6,scale=scale,shift=shift)
# 调用自定义 Group Normalization 层
normalized_x_custom = custom_groupnorm(x)
# 创建官方的 Group Normalization 层
official_groupnorm = nn.GroupNorm(num_groups=3, num_channels=6)
official_groupnorm.weight = scale
official_groupnorm.bias = shift
# 调用官方 Group Normalization 层
normalized_x_official = official_groupnorm(x)
# # 检查自定义层和官方层的输出是否一致
are_equal = torch.allclose(normalized_x_custom, normalized_x_official, atol=1e-5)
print("自定义 Layer Normalization 和官方 Layer Normalization 是否一致:", are_equal)
如果有用帮忙点个赞哦


![[MAUI]实现动态拖拽排序网格](https://img-blog.csdnimg.cn/03ff870c203b4b96ac9d1cfadbb3ce41.gif)