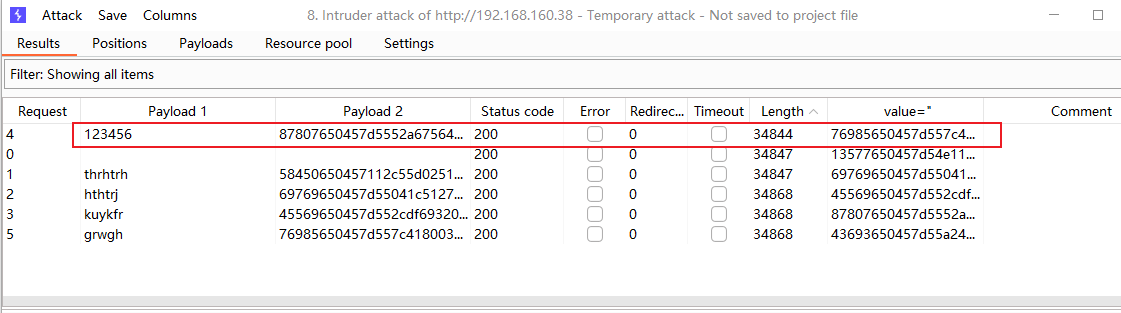
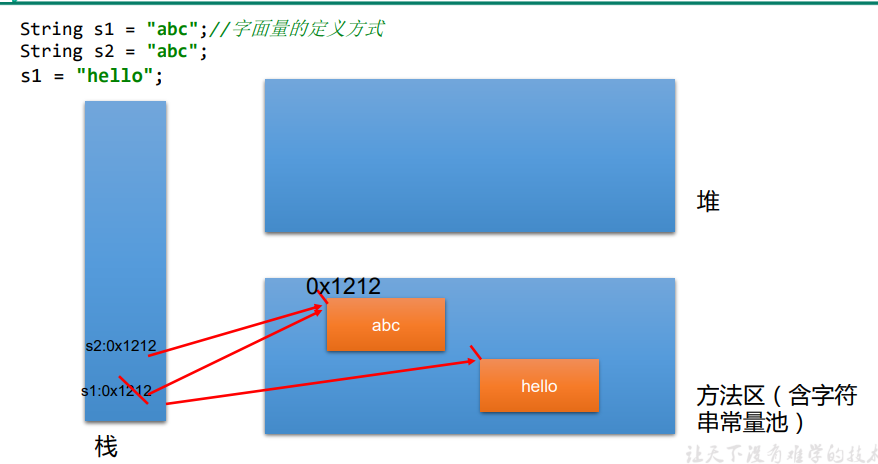
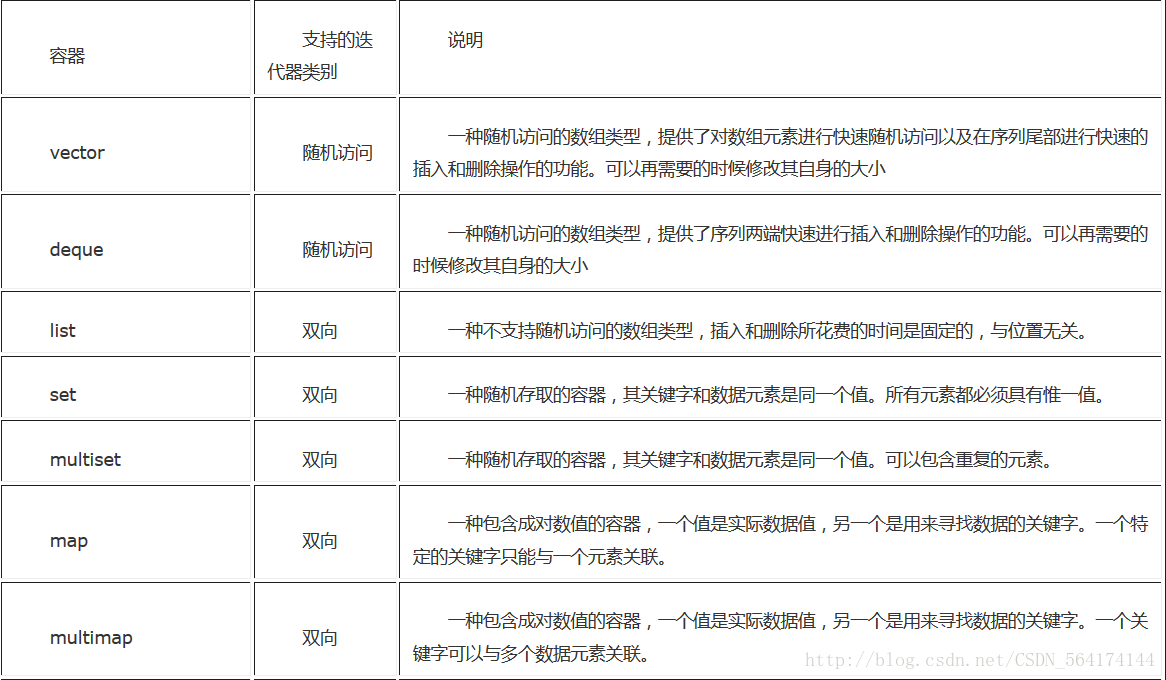
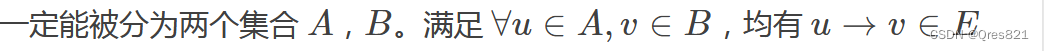一、在 Ubuntu 20.04 上安装 GCC
默认的 Ubuntu 软件源包含了一个软件包组,名称为 “build-essential”,它包含了 GNU 编辑器集合,GNU 调试器,和其他编译软件所必需的开发库和工具。
想要安装开发工具软件包,以 拥有 sudo 权限用户身份或者 root 身份运行下面的命令:
sudo apt update sudo apt install build-essential
这个命令将会安装一系列软件包,包括gcc,g++,和make。
你可能还想安装关于如何使用 GNU/Linux开发的手册。
sudo apt-get install manpages-dev
通过运行下面的命令,打印 GCC 版本,来验证 GCC 编译器是否被成功地安装。
gcc --version
在 Ubuntu 20.04 软件源中 GCC 的默认可用版本号为9.3.0:
gcc (Ubuntu 9.3.0-10ubuntu2) 9.3.0 Copyright (C) 2019 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
就这些。GCC 已经在你的 Ubuntu 系统上安装好了,你可以开始使用它了。
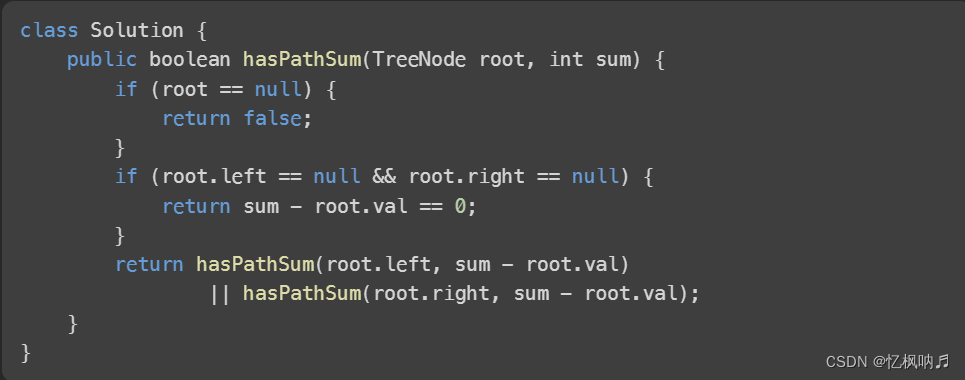
二、编译一个 Hello World 实例
使用 GCC 编译一个基本的 C 或者 C++ 程序非常简单。打开你的文本编辑器,并且创建下面的文件:
nano hello.c
#include <stdio.h>
int main()
{
printf ("Hello World!\n");
return 0;
}
保存文件,并且将它编译成可执行文件,运行:
gcc hello.c -o hello
这将在你运行命令的同一个目录下创建一个二进制文件,名称为"hello”。
运行这个hell0程序:
./hello
程序应该打印:
Hello World!
三、安装多个 GCC 版本
这一节提供一些指令,关于如何在 Ubuntu 20.04 上安装和使用多个版本的 GCC。更新的 GCC 编译器包含一些新函数以及优化改进。
在写作本文的时候,Ubuntu 源仓库包含几个 GCC 版本,从7.x.x到10.x.x。在写作的同时,最新的版本是10.1.0。
在下面的例子中,我们将会安装最新的三个版本 GCC 和 G++:
输入下面的命令,安装想要的 GCC 和 G++ :
sudo apt install gcc-8 g++-8 gcc-9 g++-9 gcc-10 g++-10
下面的命令配置每一个版本,并且设置了优先级。默认的版本是拥有最高优先级的那个,在我们的场景中是gcc-10。
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 100 --slave /usr/bin/g++ g++ /usr/bin/g++-10 --slave /usr/bin/gcov gcov /usr/bin/gcov-10 sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-9 sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 80 --slave /usr/bin/g++ g++ /usr/bin/g++-8 --slave /usr/bin/gcov gcov /usr/bin/gcov-8
以后,如果你想修改默认的版本,使用update-alternatives命令:
sudo update-alternatives --config gcc
输出:
There are 3 choices for the alternative gcc (providing /usr/bin/gcc). Selection Path Priority Status ------------------------------------------------------------ * 0 /usr/bin/gcc-10 100 auto mode 1 /usr/bin/gcc-10 100 manual mode 2 /usr/bin/gcc-8 80 manual mode 3 /usr/bin/gcc-9 90 manual mode Press <enter> to keep the current choice[*], or type selection number:
你将会被展示一系列已经安装在你的 Ubuntu 系统上的 GCC 版本。输入你想设置为默认的 GCC 版本,并且按回车Enter。
这个命令将会创建符号链接到指定版本的 GCC 和 G++。
![]()
gdb:
要使用GDB(GNU调试器)调试C程序,你需要按照以下步骤进行操作:
-
首先,确保你的系统上已经安装了GDB。GDB是GNU Binutils套件的一部分,你可以通过包管理器安装它。例如,在Ubuntu上,你可以使用以下命令安装GDB:
arduino复制代码 sudo apt-get install gdb
-
编译你的程序时,使用
-g选项启用调试信息。这将告诉编译器在生成的可执行文件中包含额外的调试信息,以便GDB使用。例如,你可以使用以下命令编译你的程序:
复制代码 gcc -g -o myprogram myprogram.c
-
运行GDB并加载你的程序。你可以使用以下命令启动GDB并加载你的程序:
复制代码 gdb myprogram
-
在GDB中,你可以使用各种命令来设置断点、运行代码、查看变量值等。以下是一些常用的GDB命令:
-
break(或简写为b):设置断点。例如,break main将在main函数处设置断点。 -
run(或简写为r):开始运行程序,直到遇到断点或程序结束。 -
step(或简写为s):逐行执行代码,进入函数调用。 -
next(或简写为n):逐行执行代码,但不进入函数调用。 -
continue(或简写为c):继续执行程序,直到遇到下一个断点或程序结束。 -
print(或简写为p):打印变量的值。例如,print x将显示变量x的值。
-
-
使用上述命令进行调试。你可以设置断点,使用
step、next和continue命令执行代码,并使用print命令查看变量的值。 -
当你完成调试时,可以使用
quit命令退出GDB。
makefile make cmake
编写Makefile并执行make
# Makefile main : main.c gcc main.c -o main
通配符:
# Makefile main : $(wildcard *.c) gcc $(wildcard *.c) -o main
变量:
# Makefile SRCS := $(wildcard *.c) main : $(SRCS) gcc $(SRCS) -o main
![]()
gcc 命令时通过 -I 选项指定头文件所在路径
# Makefile INCS := -I./func SRCS := $(wildcard *.c) main : $(SRCS) gcc $(INCS) $(SRCS) -o main
指针
在C语言中,变量名不是地址。变量名是用来标识内存地址的符号,它表示变量在计算机内存中的位置。当定义一个变量时,系统会为该变量分配一个内存地址,并且可以使用变量名来访问该变量的值。
在C语言中,指针是一种特殊的变量,它存储的是其他变量的内存地址,而不是值本身。通过指针,我们可以间接地访问和修改其指向的内存区域的值。
指针的声明和定义如下:
数据类型 *指针变量名;
其中,数据类型可以是任何有效的C语言数据类型,如int、char、float等。指针变量名是你为指针变量选择的名称。
下面是一个完整的例子,演示了如何声明、定义和使用指针变量:
#include <stdio.h>
int main() {
int num = 10;
int *ptr; // 声明指针变量ptr
ptr = # // 将num的地址赋值给ptr
printf("num的值为:%d\n", num);
printf("num的地址为:%p\n", &num);
printf("ptr指向的值为:%d\n", *ptr);
printf("ptr的地址为:%p\n", ptr);
return 0;
}
在上面的例子中,我们声明了一个整型变量num并初始化为10。然后声明了一个指向整型的指针变量ptr。通过将&num赋值给ptr,我们将num的地址存储在了ptr中。使用*ptr可以访问ptr所指向的内存区域的值,即num的值。通过&num可以得到num的地址。程序输出了num的值、num的地址、ptr指向的值以及ptr的地址。
数据交互:
可以使用指针来交换两个变量的值,这是一个非常常见的使用指针的例子。以下是一个使用 C 语言实现的示例:
首先,定义一个交换函数,它接收两个整数的指针:
#include <stdio.h>
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
然后,你可以在主函数中这样使用这个函数:
int main() {
int x = 5;
int y = 10;
printf("Before swap: x = %d, y = %d\n", x, y);
swap(&x, &y);
printf("After swap: x = %d, y = %d\n", x, y);
return 0;
}
在这个例子中,swap函数通过接收两个指针来交换两个整数的值。当我们调用swap(&x, &y)时,我们传递的是x和y的地址,所以函数能够直接影响到这两个变量的值。
ps:
在C语言中,函数的参数传递是值传递。这意味着当你传递一个变量到函数中时,函数会创建一个新的副本,而不是直接引用原始变量。因此,在函数内部对参数的任何修改都不会影响原始变量的值。
下面是一个简单的示例来说明这个概念:
c复制代码
#include <stdio.h>
void addOne(int num) {
num = num + 1;
printf("num inside the function: %d\n", num);
}
int main() {
int num = 0;
addOne(num);
printf("num in main: %d\n", num);
return 0;
}
在这个例子中,addOne函数接收一个整数参数num,然后对它加一。然而,这种修改不会影响到main函数中的num变量。输出将是:
makefile复制代码 num inside the function: 1 num in main: 0
这表明尽管在函数内部num的值被改变了,但这种改变并没有影响到函数外部的原始变量。这就是因为在C语言中,函数参数是通过值传递的。
如果你希望在函数中修改一个变量的值,并影响到原始变量,你需要使用指针。通过指针,你可以直接引用和修改内存中的原始值,而不是传递一个副本。
数组与指针
在C语言中,数组和指针之间有一个非常紧密的关系。数组的名称可以被看作是一个指向数组第一个元素的指针。同样,一个指向某个特定类型的指针也可以被看作是一个指向该类型的数组。这种关系可以在下面的示例代码中看到:
#include <stdio.h>
int main() {
// 定义一个包含5个整数的数组
int array[5] = {1, 2, 3, 4, 5};
// 定义一个指向整数的指针
int *ptr;
// 将ptr指向array的第一个元素
ptr = array;
// 使用指针访问数组元素
for(int i = 0; i < 5; i++) {
printf("array[%d] = %d\n", i, *(ptr + i));
}
// 修改数组中的元素值通过指针
*(ptr + 2) = 20;
// 打印修改后的数组
printf("Modified array: ");
for(int i = 0; i < 5; i++) {
printf("%d ", array[i]);
}
printf("\n");
return 0;
}
在这个例子中,我们首先定义了一个包含5个整数的数组array,然后定义了一个指向整数的指针ptr。我们将ptr指向array的第一个元素,然后使用一个循环通过指针访问数组的每个元素。我们也可以使用指针修改数组中的元素值,如示例中我们将第三个元素值修改为20。
二位数组的指针:
include <stdio.h>
int main(void)
{
int zippo[4][2] = { {2,4}, {6,8}, {1,3}, {5, 7} };
int (*pz)[2];
pz = zippo;
printf(" pz = %p, pz + 1 = %p\n",
pz, pz + 1);
printf("pz[0] = %p, pz[0] + 1 = %p\n",
pz[0], pz[0] + 1);
printf(" *pz = %p, *pz + 1 = %p\n",
*pz, *pz + 1);
printf("pz[0][0] = %d\n", pz[0][0]);
printf(" *pz[0] = %d\n", *pz[0]);
printf(" **pz = %d\n", **pz);
printf(" pz[2][1] = %d\n", pz[2][1]);
printf("*(*(pz+2) + 1) = %d\n", *(*(pz+2) + 1));
return 0;
}
/* zippo1.c -- zippo info */
include <stdio.h>
int main(void)
{
int zippo[4][2] = { {2,4}, {6,8}, {1,3}, {5, 7} };
printf(" zippo = %p, zippo + 1 = %p\n",
zippo, zippo + 1);
printf("zippo[0] = %p, zippo[0] + 1 = %p\n",
zippo[0], zippo[0] + 1);
printf(" *zippo = %p, *zippo + 1 = %p\n",
*zippo, *zippo + 1);
printf("zippo[0][0] = %d\n", zippo[0][0]);
printf(" *zippo[0] = %d\n", *zippo[0]);
printf(" **zippo = %d\n", **zippo);
printf(" zippo[2][1] = %d\n", zippo[2][1]);
printf("*(*(zippo+2) + 1) = %d\n", *(*(zippo+2) + 1));
return 0;
}
函数与指针
函数指针是指向函数的指针变量。它可以用来存储函数的地址,并在需要时调用该函数。下面是一个简单的例子,演示了如何定义和使用函数指针。
#include <stdio.h>
// 定义一个函数,用于计算两个整数的和
int add(int x, int y) {
return x + y;
}
int main() {
// 定义一个函数指针,指向add函数
int (*fp)(int, int) = add;
// 定义一个整数数组
int arr[] = {1, 2, 3, 4, 5};
// 使用函数指针调用add函数,计算数组元素的和
int sum = 0;
for (int i = 0; i < 5; i++) {
sum = fp(sum, arr[i]);
}
// 输出计算结果
printf("Sum of array elements: %d\n", sum);
return 0;
}
在这个例子中,我们定义了一个函数add,用于计算两个整数的和。然后,我们定义了一个函数指针fp,指向add函数。在main函数中,我们使用fp来调用add函数,计算一个整数数组的元素之和,并输出结果。
在C语言中,函数指针是指向函数的指针变量。它通常用于回调函数、函数参数传递和函数表等场景。分别给出这三个场景下应用的例子
当然,以下是函数指针在C语言中的三种常见应用场景的例子:
-
回调函数(Callback Functions)
在C语言中,函数指针最常见的用途是实现回调函数。以下是一个简单的例子:
c复制代码
#include <stdio.h>
// 定义一个函数指针类型
typedef void (*callback_t)(int);
// 定义一个函数,这个函数接受一个整数和一个回调函数
void demo_function(int x, callback_t callback) {
printf("The value of x is: %d\n", x);
// 调用回调函数
callback(x);
}
// 定义一个回调函数,用于输出一个整数的平方
void square(int x) {
printf("The square of %d is: %d\n", x, x * x);
}
int main() {
// 调用demo_function函数,并传入回调函数square
demo_function(5, square);
return 0;
}
-
函数参数传递(Function Parameters Passing)
函数指针也可以作为参数传递给其他函数,以实现更灵活的功能。以下是一个例子:
#include <stdio.h>
// 定义一个函数,这个函数接受一个整数和一个函数指针
void apply_func(int x, void (*func)(int)) {
func(x);
}
// 定义一个函数,用于输出一个整数的平方
void square(int x) {
printf("The square of %d is: %d\n", x, x * x);
}
int main() {
// 调用apply_func函数,并传入函数square作为参数
apply_func(5, square);
return 0;
}
-
函数表(Function Tables)
函数指针还可以用于实现函数表,以便根据运行时的决策来调用不同的函数。以下是一个例子:
#include <stdio.h>
// 定义一个函数指针类型,用于指向处理函数的指针数组的函数指针类型
typedef void (*operation_t)(int);
// 定义几个处理函数
void print_square(int x) { printf("%d\n", x * x); }
void print_cube(int x) { printf("%d\n", x * x * x); }
void print_quartic(int x) { printf("%d\n", x * x * x * x); }
// 定义一个包含这三个函数的函数指针数组(即函数表)
operation_t operations[] = { print_square, print_cube, print_quartic };
int main() {
// 通过函数表调用不同的函数
for (int i = 0; i < 3; i++) {
operations[i](i + 1); // 分别计算并打印1的平方、立方和四次方,2的平方、立方和四次方,以及3的平方、立方和四次方。
}
return 0;
}
在C语言中,函数的可变参数(Variable Arguments)是一种特殊的函数参数类型,它允许函数接受可变数量的参数。这种参数类型被表示为...(三个点),通常作为函数参数列表的最后一个参数。
可变参数的应用场景是在函数需要处理可变数量或类型的参数时,例如函数需要接受任意数量的整数、字符串或其他数据类型,或者需要接受不同数量的参数进行不同的操作。
下面是一个简单的示例,演示了如何使用可变参数实现一个函数,该函数接受任意数量的整数并计算它们的和:
#include <stdio.h>
#include <stdarg.h>
int sum(int count, ...) {
va_list args; // 定义一个va_list类型的变量,用于存储可变参数的列表
int sum = 0; // 初始化一个sum变量用于计算总和
va_start(args, count); // 初始化args变量,将其指向第一个可变参数
// 遍历可变参数列表,计算它们的总和
for (int i = 0; i < count; i++) {
int num = va_arg(args, int); // 依次获取每个整数参数的值
sum += num;
}
va_end(args); // 清理va_list变量
return sum;
}
int main() {
int a = 1, b = 2, c = 3;
printf("Sum: %d\n", sum(3, a, b, c)); // 输出:Sum: 6
return 0;
}
在上面的示例中,sum函数接受一个整数count表示可变参数的数量,然后使用一个va_list类型的变量args来存储可变参数的列表。通过调用va_start宏初始化args变量,然后使用va_arg宏依次获取每个整数参数的值,并计算它们的总和。最后,调用va_end宏清理args变量。
在C语言中,fopen函数用于打开文件,并返回一个文件指针。如果打开文件成功,它会返回一个指向文件的指针,该指针随后可用于进行其他的输入和输出操作。如果打开文件失败,fopen则会返回NULL。
文件
fopen函数的原型如下:
FILE *fopen(const char *path, const char *mode);
-
path:这是一个字符串,表示要打开的文件的路径或文件名。 -
mode
:这也是一个字符串,表示打开文件的模式。下面是一些常见的模式:
-
r:以只读方式打开文件。文件必须存在。 -
w:以只写方式打开文件。如果文件存在,内容会被清空。如果文件不存在,会尝试创建一个新文件。 -
a:以追加方式打开文件。如果文件存在,写操作将在文件的末尾进行。如果文件不存在,会尝试创建一个新文件。 -
r+:以读/写方式打开文件。文件必须存在。 -
w+:以读/写方式打开文件。如果文件存在,内容会被清空。如果文件不存在,会尝试创建一个新文件。 -
a+:以读/追加方式打开文件。如果文件存在,写操作将在文件的末尾进行。如果文件不存在,会尝试创建一个新文件。
-
在C语言中,fread()函数用于从文件中读取数据。它是一个非常强大的工具,因为它可以读取任意类型的数据,无论是字符、整数、浮点数,还是自定义的数据结构。
fread()
fread()函数的原型如下:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
参数说明:
-
ptr:指向用于存储数据的内存块的指针。 -
size:要读取的每个元素的大小,以字节为单位。 -
nmemb:要读取的元素的数量。 -
stream:指向FILE对象的指针,该对象指定了一个输入流。
fread()函数会从stream指向的文件中读取nmemb个元素,每个元素的大小为size字节,并将这些数据存储在由ptr指向的内存块中。函数返回成功读取的元素数量。如果返回值小于nmemb,则可能表示发生了错误或者到达了文件的末尾。
例如,以下代码将从文件中读取一个整数数组:
c复制代码
#include <stdio.h>
int main() {
FILE *file;
int numbers[10];
size_t i, n;
file = fopen("numbers.txt", "r");
if (file == NULL) {
printf("Cannot open file\n");
return 1;
}
n = fread(numbers, sizeof(int), 10, file);
for (i = 0; i < n; i++) {
printf("%d ", numbers[i]);
}
printf("\n");
fclose(file);
return 0;
}
在这个例子中,我们打开名为"numbers.txt"的文件,并使用fread()函数从文件中读取10个整数。然后,我们遍历这些整数并打印出来。注意,我们使用了sizeof(int)作为fread()的第二个参数,这是因为我们要读取的是整数,所以我们需要知道每个整数在内存中占用的字节数。
数据结构
线性表是一种常见的数据结构,它可以使用数组或者链表来实现。以下是使用数组来实现线性表的示例代码:
c复制代码
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 100 // 线性表的最大长度
typedef struct {
int data[MAXSIZE]; // 存储数据元素的数组
int length; // 线性表的当前长度
} SqList;
// 初始化线性表
void InitList(SqList *L) {
L->length = 0;
}
// 插入元素
int ListInsert(SqList *L, int i, int e) {
if (i < 1 || i > L->length + 1 || L->length >= MAXSIZE) {
return 0;
}
for (int j = L->length; j >= i; j--) {
L->data[j] = L->data[j - 1];
}
L->data[i - 1] = e;
L->length++;
return 1;
}
// 删除元素
int ListDelete(SqList *L, int i) {
if (i < 1 || i > L->length) {
return 0;
}
for (int j = i; j < L->length; j++) {
L->data[j - 1] = L->data[j];
}
L->length--;
return 1;
}
// 查找元素
int GetElem(SqList L, int i) {
if (i < 1 || i > L.length) {
return -1;
}
return L.data[i - 1];
}
// 输出线性表中的元素
void PrintList(SqList L) {
for (int i = 0; i < L.length; i++) {
printf("%d ", L.data[i]);
}
printf("\n");
}
int main() {
SqList L;
InitList(&L); // 初始化线性表
ListInsert(&L, 1, 10); // 在第1个位置插入元素10
ListInsert(&L, 2, 20); // 在第2个位置插入元素20
ListInsert(&L, 3, 30); // 在第3个位置插入元素30
PrintList(L); // 输出线性表中的元素
ListDelete(&L, 2); // 删除第2个位置的元素
PrintList(L); // 输出线性表中的元素
printf("%d\n", GetElem(L, 2)); // 查找第2个位置的元素并输出
return 0;
}
以上代码实现了线性表的基本操作,包括初始化、插入、删除、查找和输出等。在使用时,可以根据具体的需求来调用这些函数。
**用链式存储实现线性表,并实现了插入、删除、查找和遍历操作。
以下是一个简单的C语言程序,它使用链式存储实现线性表,并实现了插入、删除、查找和遍历操作。
#include <stdio.h>
#include <stdlib.h>
// 定义线性表结点的结构体
typedef struct node {
int data;
struct node *next;
} Node;
// 创建新结点
Node* create_node(int data) {
Node *new_node = (Node*)malloc(sizeof(Node));
new_node->data = data;
new_node->next = NULL;
return new_node;
}
// 初始化线性表
void init_list(Node **head) {
*head = NULL;
}
// 插入元素
void insert_element(Node **head, int data, int position) {
Node *new_node = create_node(data);
if (*head == NULL || position == 1) {
new_node->next = *head;
*head = new_node;
} else {
Node *current_node = *head;
int i;
for (i = 1; i < position - 1; i++) {
if (current_node == NULL) {
printf("线性表长度不足,不能插入元素!\n");
return;
}
current_node = current_node->next;
}
if (current_node == NULL) {
printf("线性表长度不足,不能插入元素!\n");
return;
}
new_node->next = current_node->next;
current_node->next = new_node;
}
}
// 删除元素
void delete_element(Node **head, int position) {
if (*head == NULL) {
printf("线性表为空,不能删除元素!\n");
return;
}
if (position == 1) {
Node *temp = *head;
*head = (*head)->next;
free(temp);
} else {
Node *current_node = *head;
int i;
for (i = 1; i < position - 1; i++) {
if (current_node == NULL) {
printf("线性表长度不足,不能删除元素!\n");
return;
}
current_node = current_node->next;
}
if (current_node == NULL || current_node->next == NULL) {
printf("线性表长度不足,不能删除元素!\n");
return;
}
Node *temp = current_node->next;
current_node->next = current_node->next->next;
free(temp);
}
}
// 查找元素
int find_element(Node *head, int data) {
Node *current_node = head;
int i = 1;
while (current_node != NULL) {
if (current_node->data == data) {
return i;
}
current_node = current_node->next;
i++;
}
return -1; // 没有找到元素返回-1
}
// 遍历线性表
void traverse_list(Node *head) {
Node *current_node = head;
while (current_node != NULL) {
printf("%d ", current_node->data);
current_node = current_node->next;
}
printf("\n"); // 输出换行符以保持格式整齐
}`
这段代码是用C语言定义的一个链表节点。链表是一种常见的数据结构,由一系列的节点组成,每个节点包含两部分:数据和指向下一个节点的指针。
具体地,这段代码定义了一个名为'Node'的结构体,用于表示链表的节点。每个'Node'对象都有一个名为'data'的整型字段,用于存储数据,和一个名为'next'的指向下一个'Node'对象的指针。
这里是一个使用这种链表节点的简单例子:
c复制代码
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点
typedef struct node {
int data;
struct node *next;
} Node;
// 创建新节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if(newNode == NULL) {
printf("Error creating a new node.\n");
exit(0);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 在链表末尾添加新节点
void appendNode(Node** head, int data) {
Node* newNode = createNode(data);
if(*head == NULL) {
*head = newNode;
return;
}
Node* lastNode = *head;
while(lastNode->next != NULL) {
lastNode = lastNode->next;
}
lastNode->next = newNode;
}
// 打印链表内容
void printList(Node* head) {
while(head != NULL) {
printf("%d ", head->data);
head = head->next;
}
printf("\n");
}
int main() {
Node* head = NULL; // 初始化空链表
appendNode(&head, 1); // 添加节点1
appendNode(&head, 2); // 添加节点2
appendNode(&head, 3); // 添加节点3
printList(head); // 打印链表:1 2 3
return 0;
}
这个例子中,我们首先定义了一个链表节点类型'Node',然后创建了一个名为'createNode'的函数,用于创建新的链表节点。我们还定义了一个名为'appendNode'的函数,用于在链表的末尾添加新的节点。最后,我们定义了一个名为'printList'的函数,用于打印链表的所有元素。在'main'函数中,我们创建了一个空链表,然后添加了三个节点,并打印了链表的所有元素。
队列:
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int front;
int rear;
} Queue;
void initialize(Queue* queue) {
queue->front = -1;
queue->rear = -1;
}
int isEmpty(Queue* queue) {
return queue->front == -1;
}
int isFull(Queue* queue) {
return (queue->rear + 1) % MAX_SIZE == queue->front;
}
void enqueue(Queue* queue, int item) {
if (isFull(queue)) {
printf("Queue is full. Cannot enqueue element.\n");
return;
}
if (isEmpty(queue)) {
queue->front = 0;
queue->rear = 0;
} else {
queue->rear = (queue->rear + 1) % MAX_SIZE;
}
queue->data[queue->rear] = item;
}
int dequeue(Queue* queue) {
if (isEmpty(queue)) {
printf("Queue is empty. Cannot dequeue element.\n");
return -1;
}
int item = queue->data[queue->front];
if (queue->front == queue->rear) {
queue->front = -1;
queue->rear = -1;
} else {
queue->front = (queue->front + 1) % MAX_SIZE;
}
return item;
}
int getFront(Queue* queue) {
if (isEmpty(queue)) {
printf("Queue is empty.\n");
return -1;
}
return queue->data[queue->front];
}
int main() {
// 创建并初始化队列
Queue queue;
initialize(&queue);
// 将元素入队列
enqueue(&queue, 10);
enqueue(&queue, 20);
enqueue(&queue, 30);
// 获取并输出队首元素
printf("Front element: %d\n", getFront(&queue));
// 出队列并输出
while (!isEmpty(&queue)) {
int item = dequeue(&queue);
printf("Dequeued element: %d\n", item);
}
return 0;
}
堆栈
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int top;
} Stack;
void initialize(Stack* stack) {
stack->top = -1;
}
int isEmpty(Stack* stack) {
return stack->top == -1;
}
int isFull(Stack* stack) {
return stack->top == MAX_SIZE - 1;
}
void push(Stack* stack, int item) {
if (isFull(stack)) {
printf("Stack is full. Cannot push element.\n");
return;
}
stack->data[++stack->top] = item;
}
int pop(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot pop element.\n");
return -1;
}
return stack->data[stack->top--];
}
int getTop(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return -1;
}
return stack->data[stack->top];
}
int main() {
// 创建并初始化堆栈
Stack stack;
initialize(&stack);
// 将元素压入堆栈
push(&stack, 10);
push(&stack, 20);
push(&stack, 30);
// 获取并输出堆栈顶部元素
printf("Top element: %d\n", getTop(&stack));
// 弹出堆栈顶部元素并输出
while (!isEmpty(&stack)) {
int item = pop(&stack);
printf("Popped element: %d\n", item);
}
return 0;
}
树
#include<iostream>
using namespace std;
#define MAXSIZE 100
#include<string>
typedef struct BiTnode{
string data;
struct BiTnode *lchild,*rchild;
}BiTnode,*BiTree;
//创建二叉树
void creatbitree(BiTree &T){
char ch;
cin>>ch;
if(ch=='#') T=NULL;
else{
T=new BiTnode;
T->data=ch;
creatbitree(T->lchild);
creatbitree(T->rchild);
}
}
//复制树
void Copy(BiTree T,BiTree &newT){
if(T==NULL){
newT=NULL;
return;
}
else{
newT=new BiTnode;
newT->data=T->data;
Copy(T->lchild,newT->lchild);
Copy(T->rchild,newT->rchild);
}
}
//中序遍历树
void inordertraverse(BiTree T){
if(T){
inordertraverse(T->lchild);
cout<<T->data<<endl;
inordertraverse(T->rchild);
}
}
//preortrave
void pretrave(BiTree T){
if(T){
cout<<T->data<<" ";
pretrave(T->lchild);
pretrave(T->rchild);
}
}
//latrave
void latrave(BiTree T){
if(T){
latrave(T->lchild);
latrave(T->rchild);
cout<<T->data<<" ";
}
}
//深度计算 前序遍历
int Depth(BiTree T){
int m,n;
if(T==NULL)return 0;
else{
m=Depth(T->lchild);
n=Depth(T->rchild);
return (m>n?m:n);
}
}
//结点计算
int NodeCount(BiTree T){
if(T==NULL)return 0;
else{
return NodeCount(T->lchild)+NodeCount(T->rchild)+1;
}
}
int main(){
BiTree T;
creatbitree(T);
cout<<"计算深度: "<<Depth(T)<<endl;
BiTree T1;
cout<<"复制树T1:"<<endl;
Copy(T,T1);
cout<<"前序遍历"<<endl;
pretrave(T);
cout<<"中序遍历树"<<endl;
inordertraverse(T);
cout<<"后序遍历"<<endl;
latrave(T);
cout<<"结点计算:"<<NodeCount(T)<<endl;
system("pause");
return 0;
}

![[MAUI]实现动态拖拽排序网格](https://img-blog.csdnimg.cn/03ff870c203b4b96ac9d1cfadbb3ce41.gif)