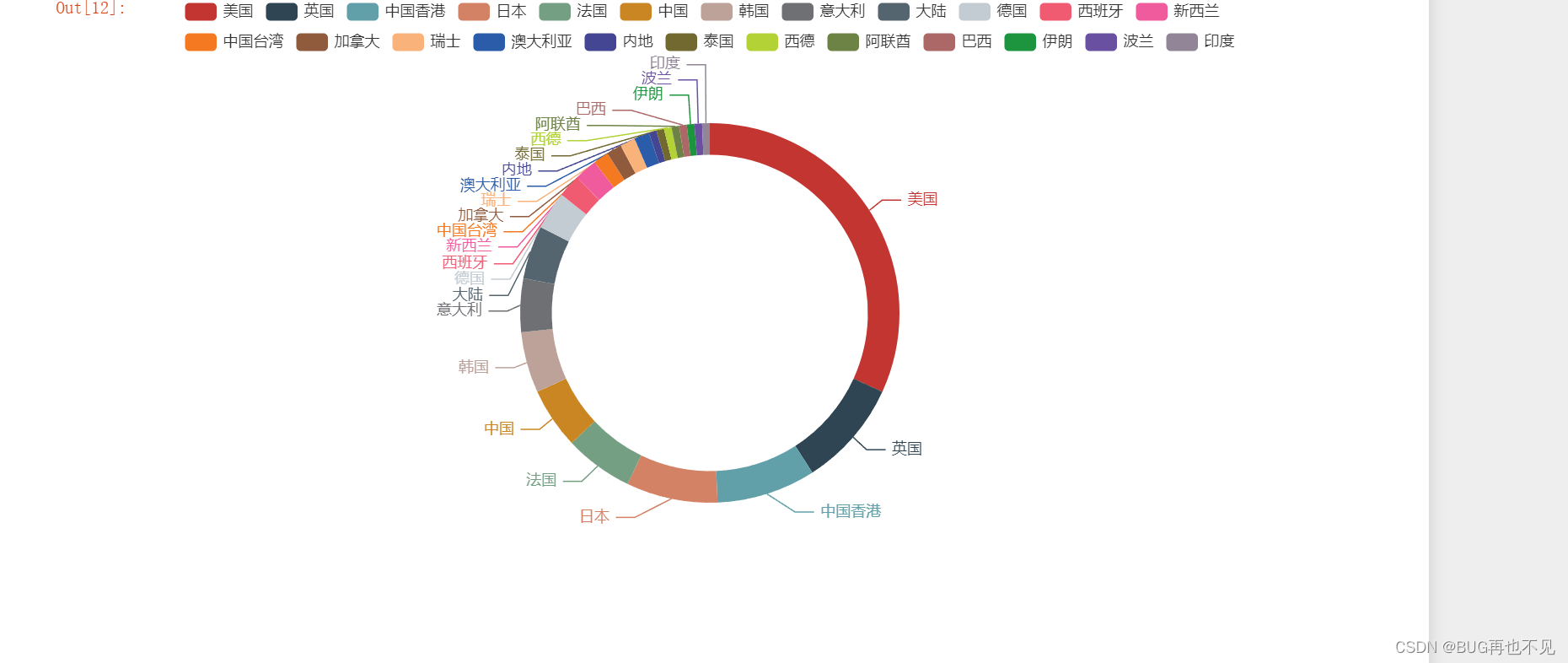
本文会在x64dbg中分析vector,list,map的内存存储特点
目录
分析vector在内存中的存储形式
x32dbg分析vector数组
总结一下vector的内存布局
分析 list 在内存中的存储形式
x32dbg分析 list 数组
总结一下 list 的内存布局
分析map在内存中的存储形式
x32dbg分析map
总结一下map的内存布局
vector list map的对比
分析vector在内存中的存储形式
vector:C++里面的动态数组,通过一个连续的数组存放元素,如果集合已经满了,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,再插入新的元素。
测试代码
#include <windows.h>
#include <vector>
using namespace std;
int main()
{
vector<int> myVec;;
myVec.push_back(1);
myVec.push_back(2);
myVec.push_back(3);
myVec.push_back(4);
myVec.push_back(5);
myVec.push_back(6);
myVec.push_back(7);
return 0;
}使用IDA加载符号文件,并导出map文件,map文件里面保存的是地址对应的函数或者变量名,然后将map文件导入到x64dbg
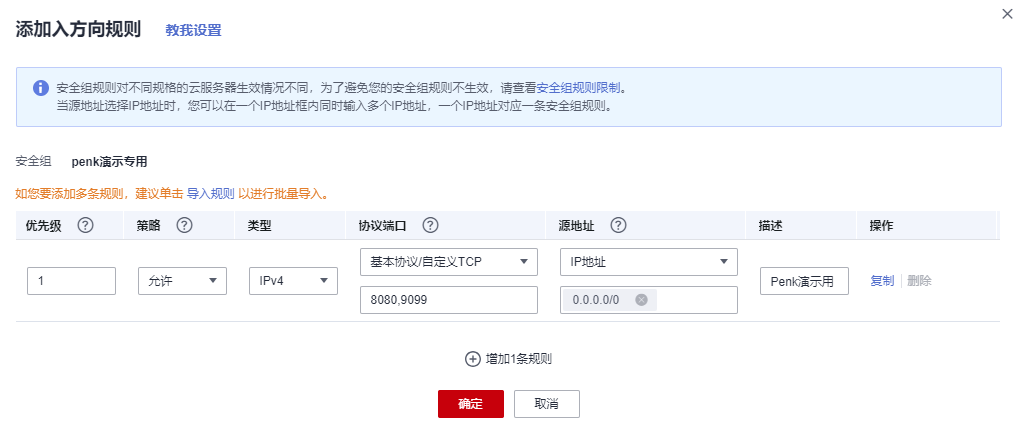
File--Produce File--Create map file 全部勾选
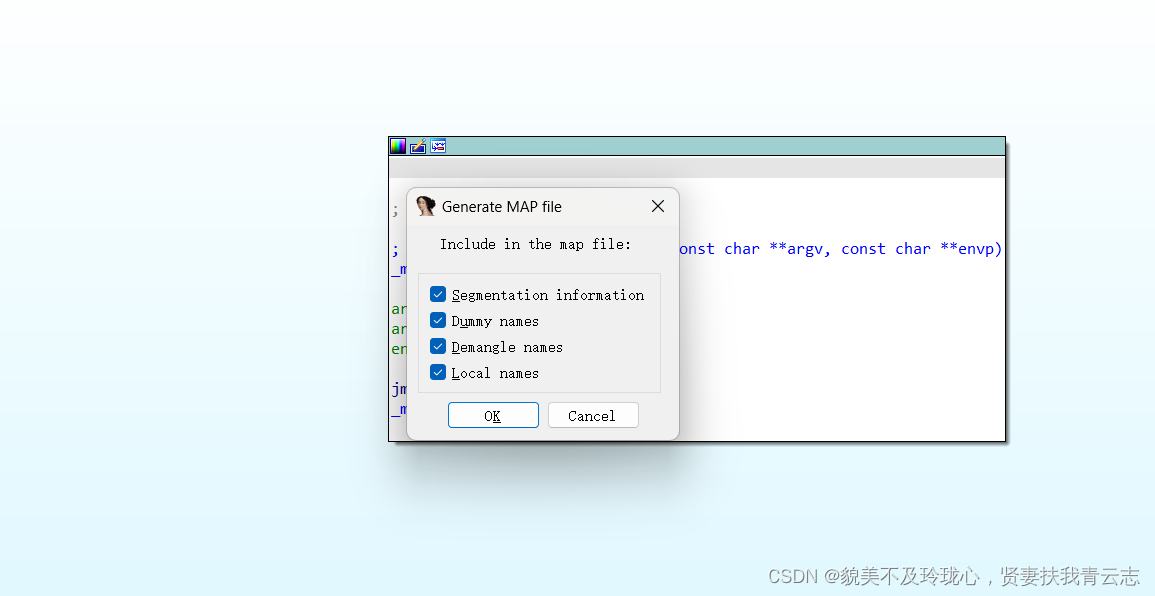
在x64dbg中导入map文件,使用插件SwissArmyKnife加载map文件
x32dbg分析vector数组
00EFF95C这个地址是vector的首地址
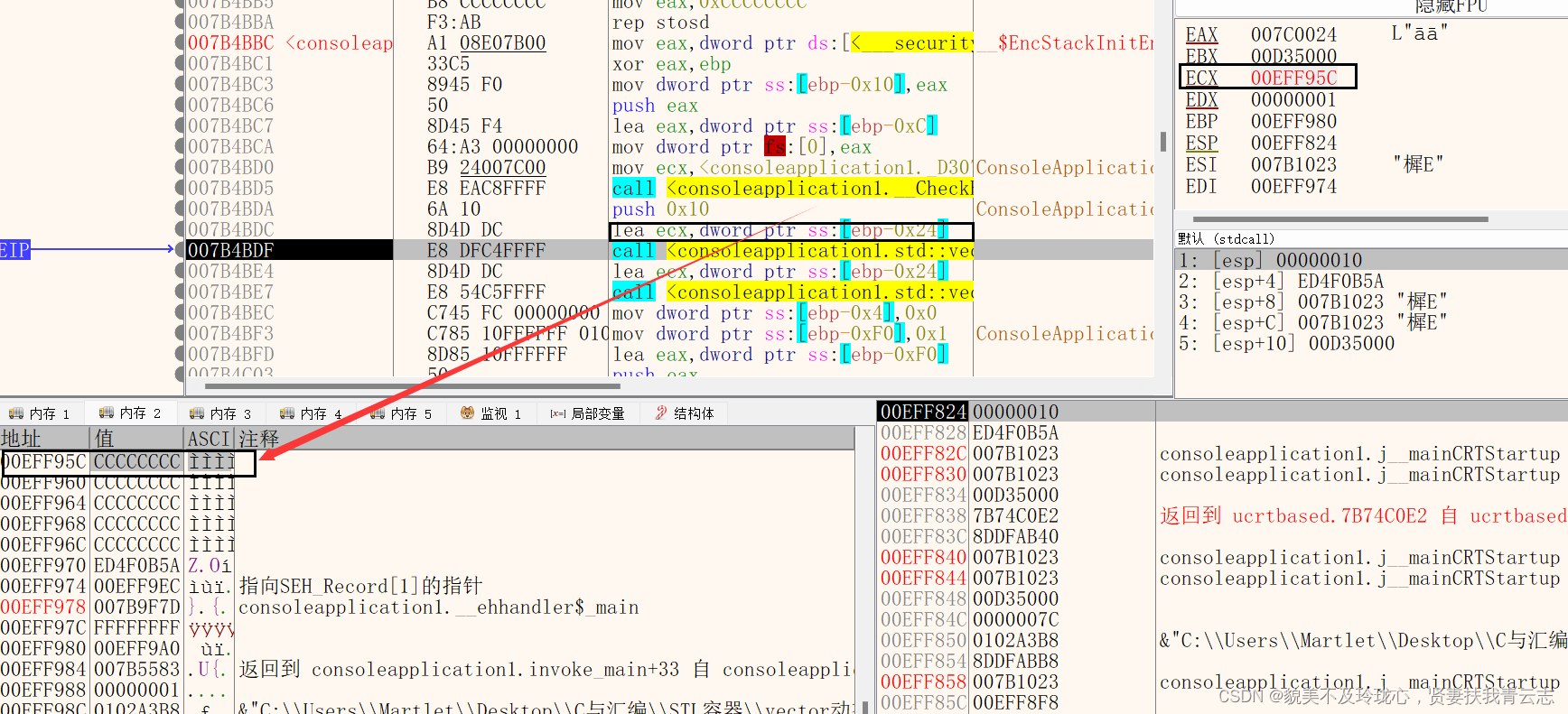
第一个函数是给是给vector分配内存空间并初始化,这里其实就标识了vector数组使用的内存空间是0x10个字节。
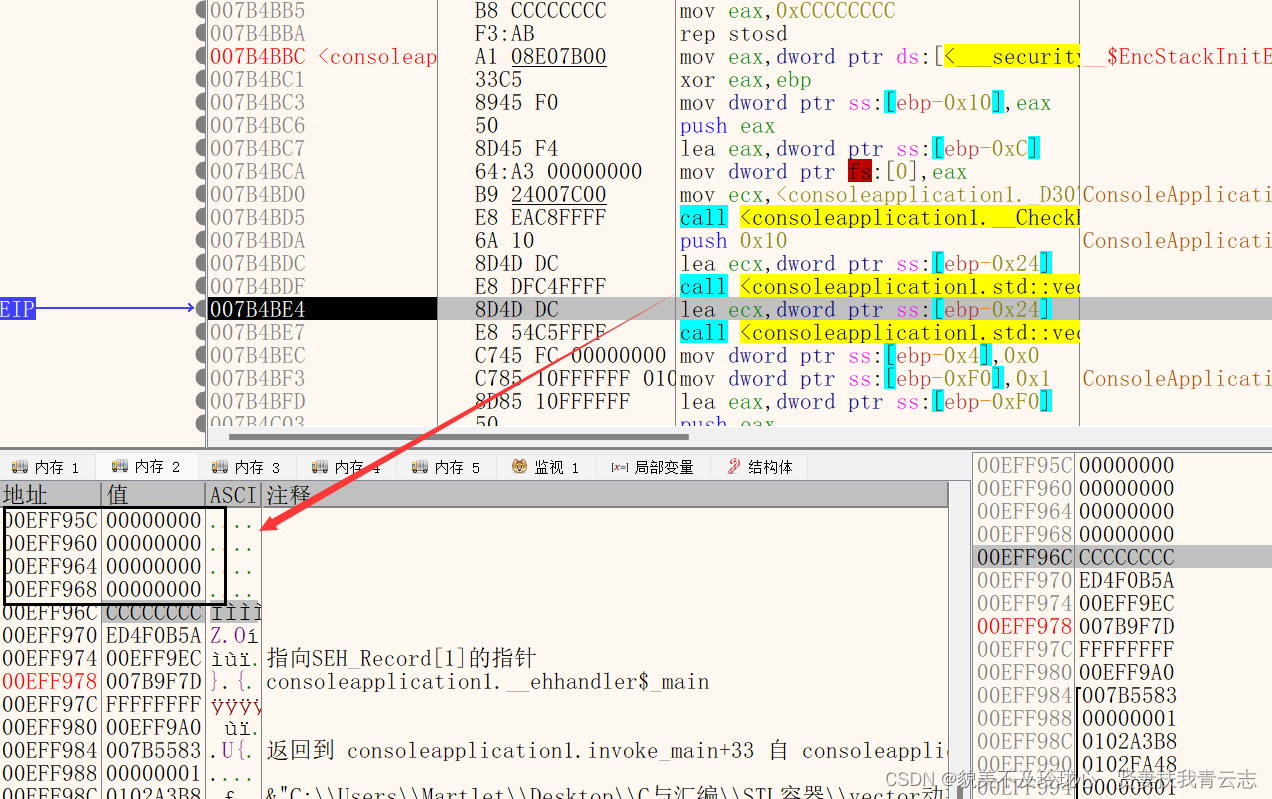
第二个函数就对应源码的vector数组初始化。这里将+0偏移的内存写入了一个地址,跟随地址里的内容就能发现实际上这个字段是一个指向自己的指针,有点类似string的结构,两个都是STL结构,那么有一个相同的字段也就说的通了。
对应的是 vector<int> myVec;
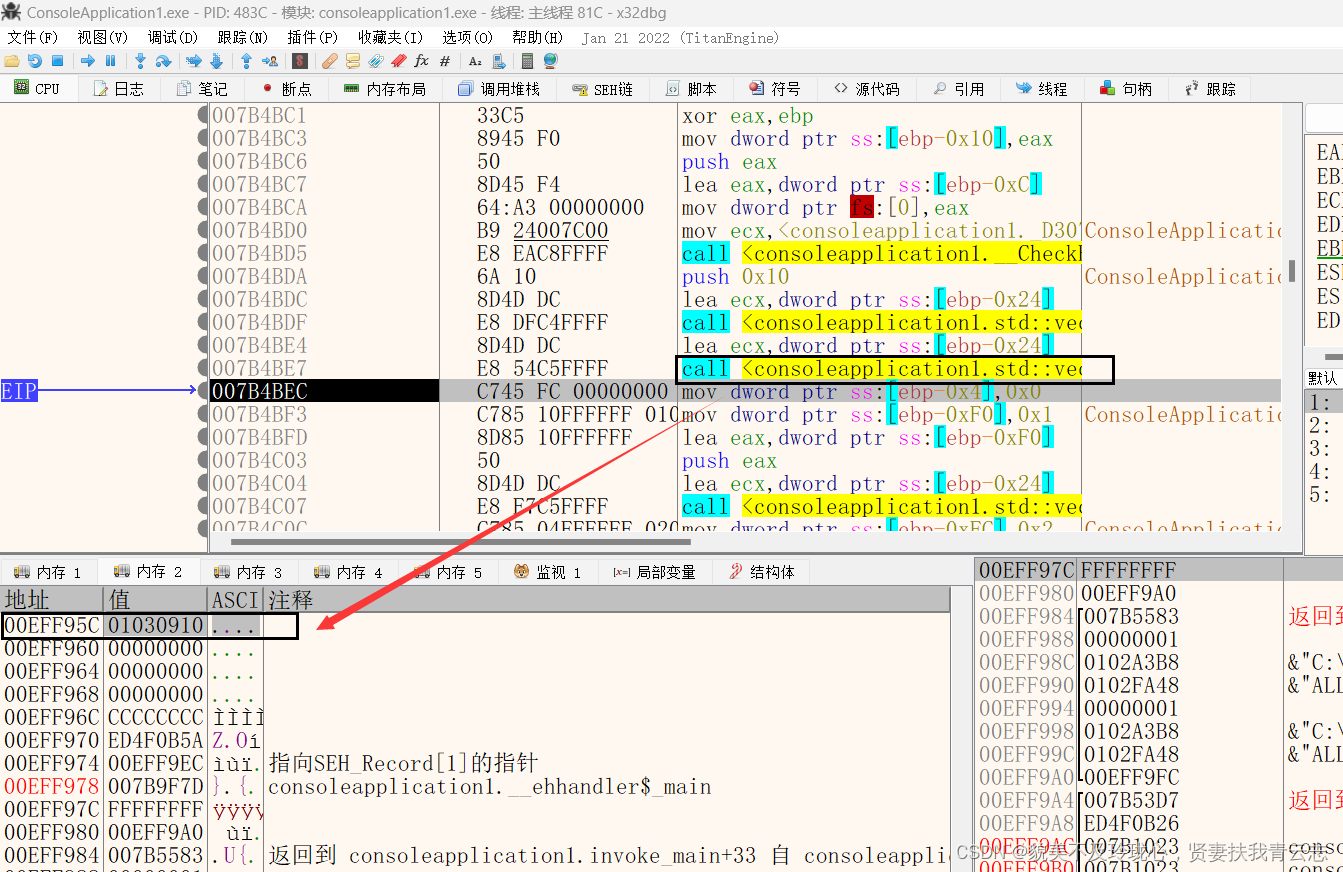
压入七个元素后,查看vector的内存:
第一个地址存储一个地址,这个地址存储的值是00EFF95C,这是个指针
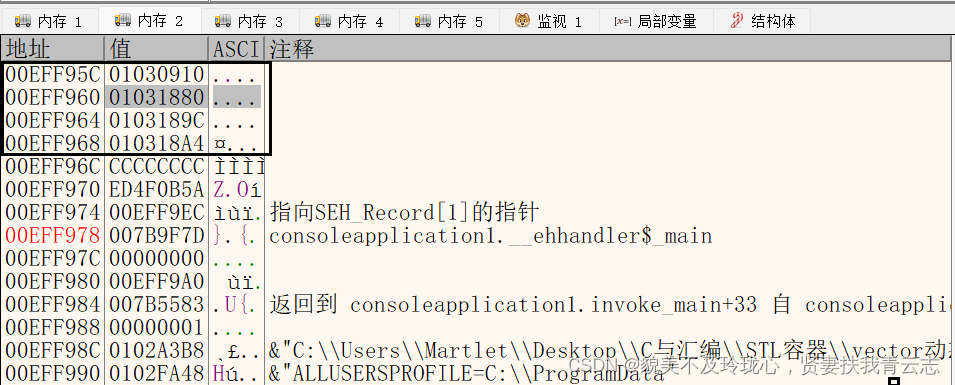
第二个地址存储一个地址,指向vector数组的首个元素地址
第三个地址存储一个地址,执行vector数组最后一个元素的下一个地址
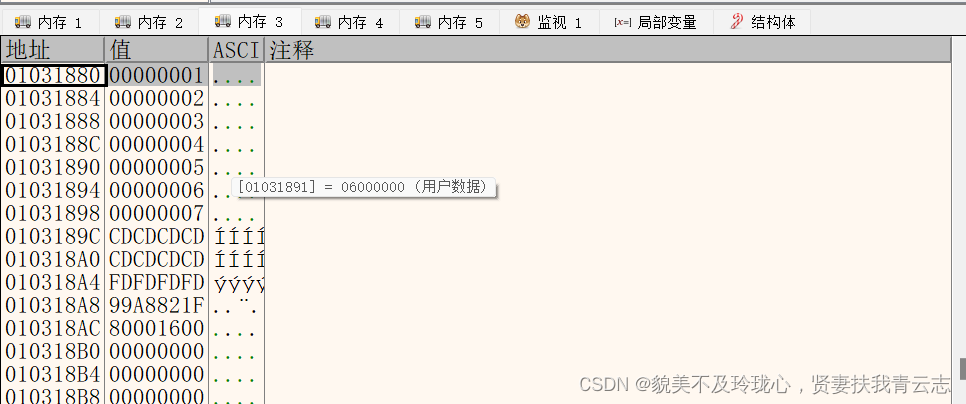
最后一个地址存储一个地址,指向的是整个vector缓冲区的结束地址
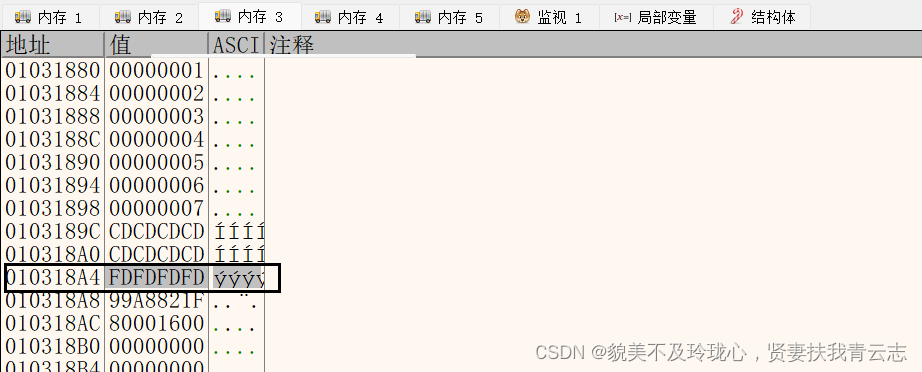
观察存储数据的空间
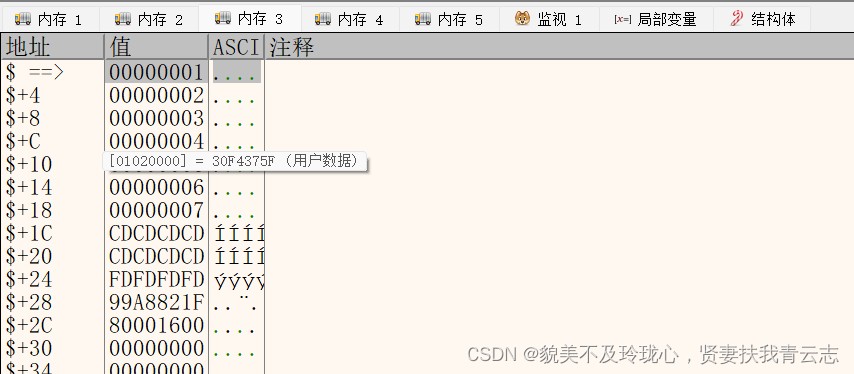
在复制的过程中,vector会根据需要的空间大小去动态的申请内存,把原来的数据拷贝一份,释放掉之前的内存。
总结一下vector的内存布局
template<class T>
struct my_vector
{
my_vector* self; // 指向自己的指针
T* fisrt; // 指向数据的首地址
T* last; // 最后一个元素的下一个位置(数据结束地址)
T* end; // 指向缓冲区的结尾
};分析 list 在内存中的存储形式
#include <windows.h>
#include <list>
using namespace std;
int main()
{
printf("hello guishou");
list<int> myList;
myList.push_back(1);
myList.push_back(2);
myList.push_back(3);
myList.push_back(4);
myList.push_back(5);
myList.push_back(6);
myList.push_back(7);
return 0;
}x32dbg分析 list 数组
第一个是初始化函数,给List数据结构分配内存空间,并初始化。这里我们可以看出list这个数据结构实 际上是占了0xC个字节
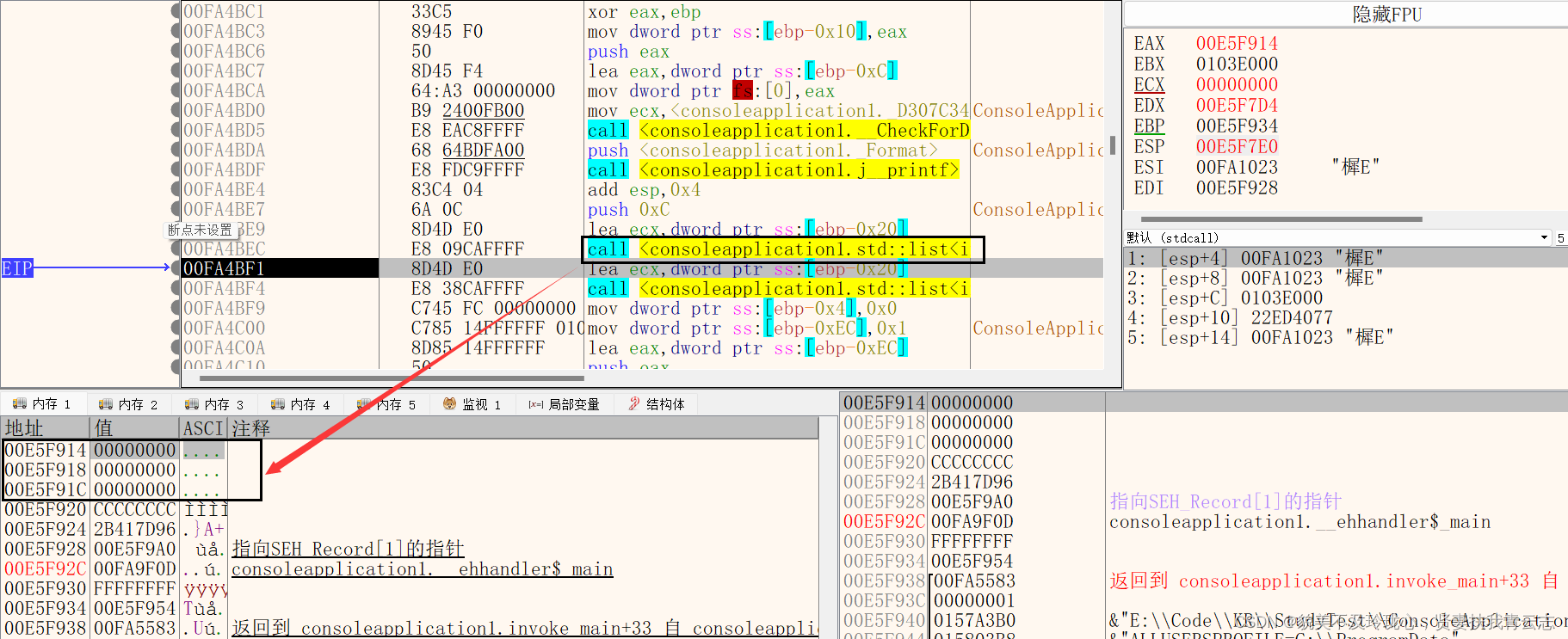
第二个构造函数执行完成之后,前两个地址就已经被赋值了
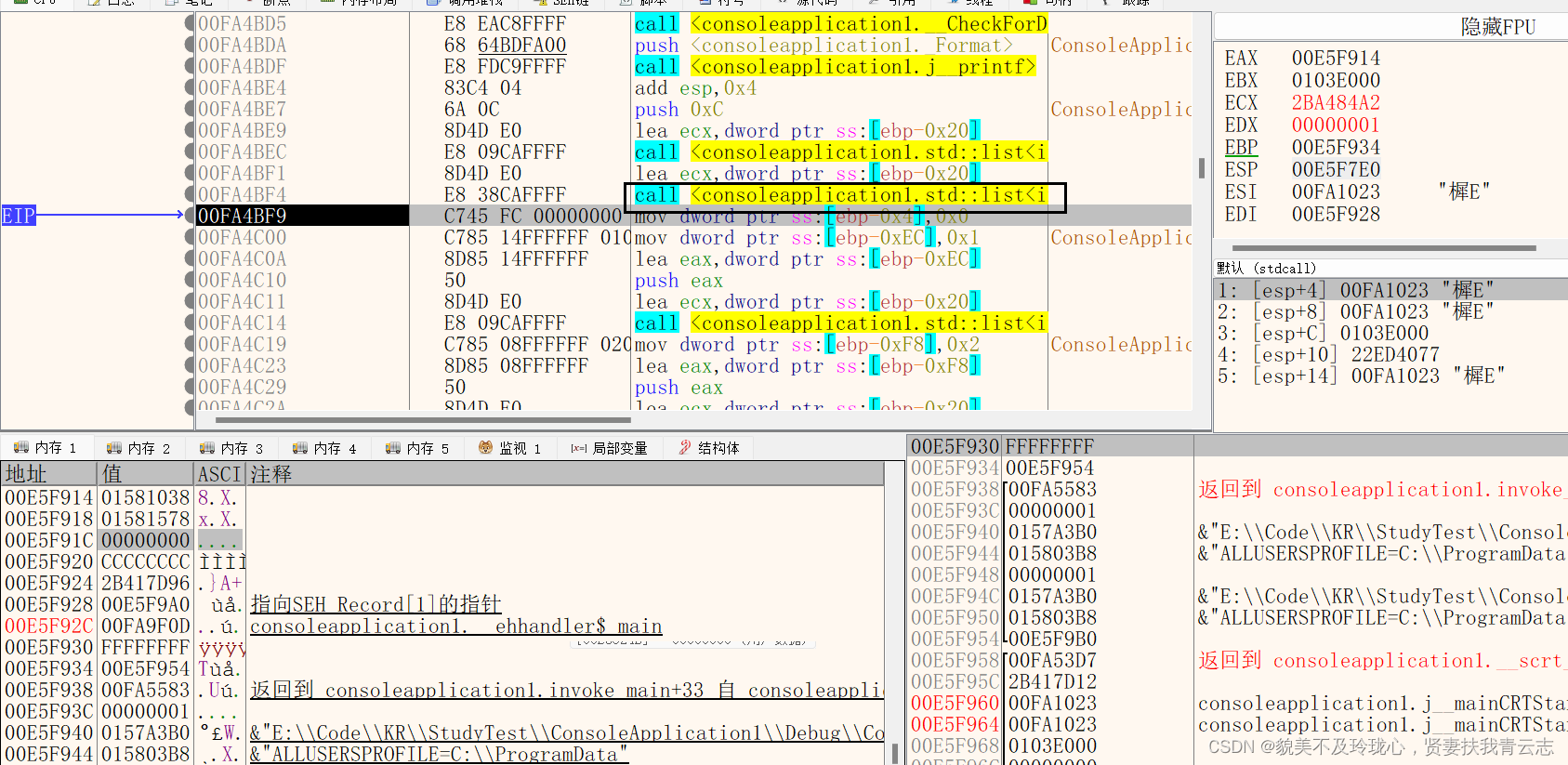
存入所有数据
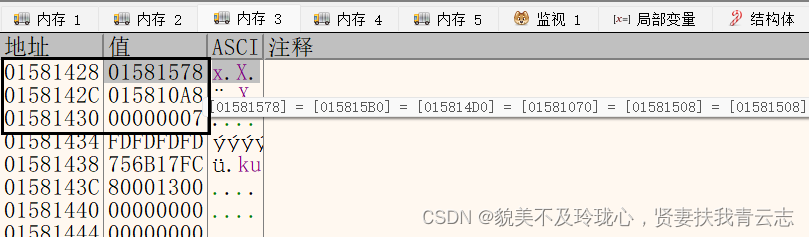
Listd对象
- 第一个地址存储一个指针指向自己
- 第二地址指向链表头
- 第三个地址存储链表由几个节点
链表头
第一个头节点,第二个尾节点
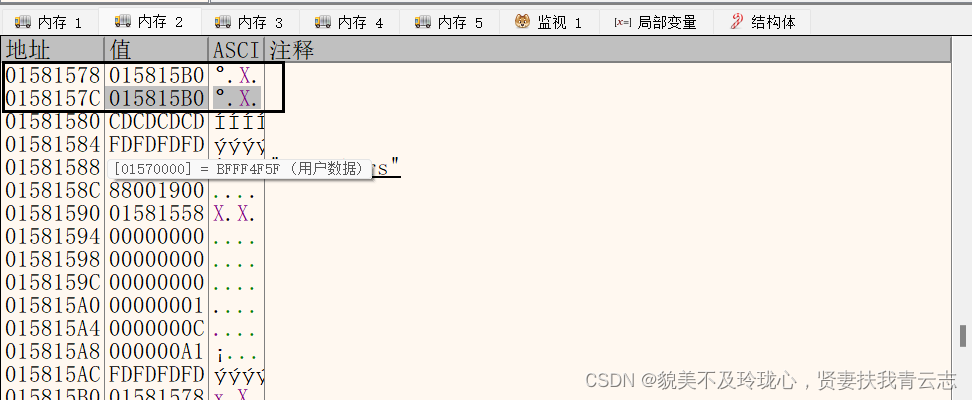
压入所有元素
List对象
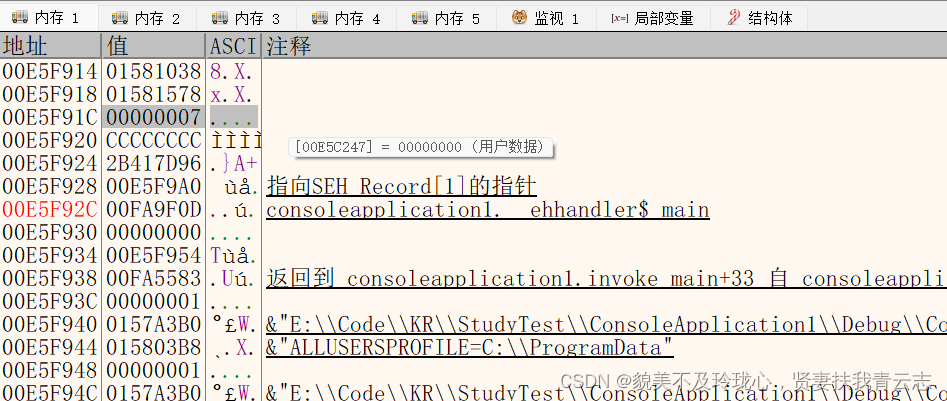
链表头
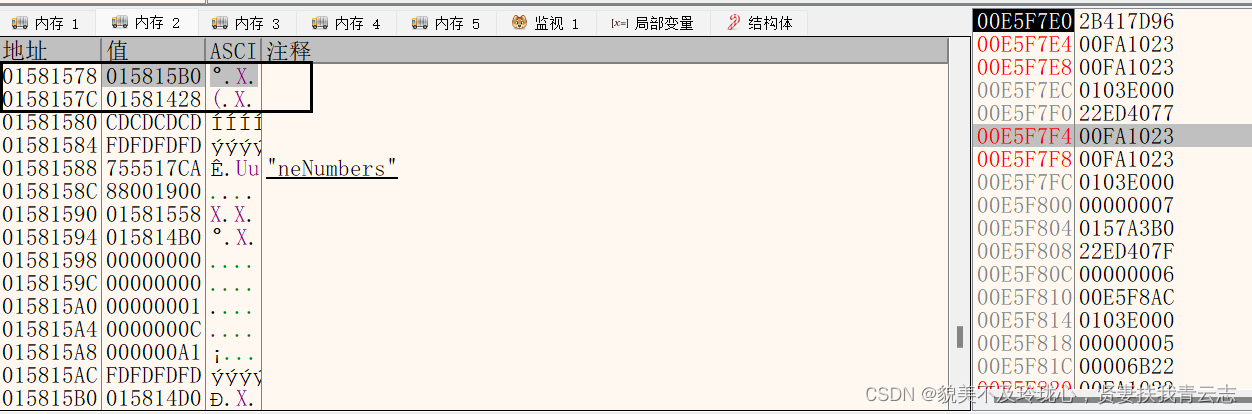
节点一
第一个地址指向下一个地址
第二个地址指向上一个地址
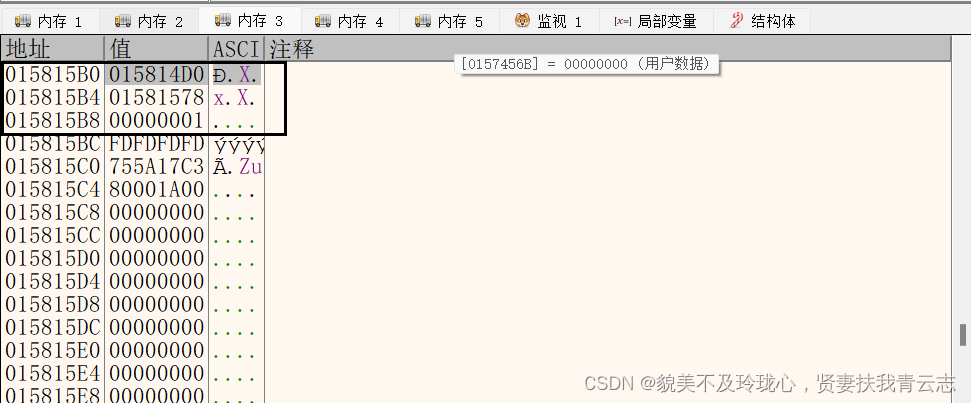
顺着链表头第一个地址走下去会重新返回来
总结一下 list 的内存布局
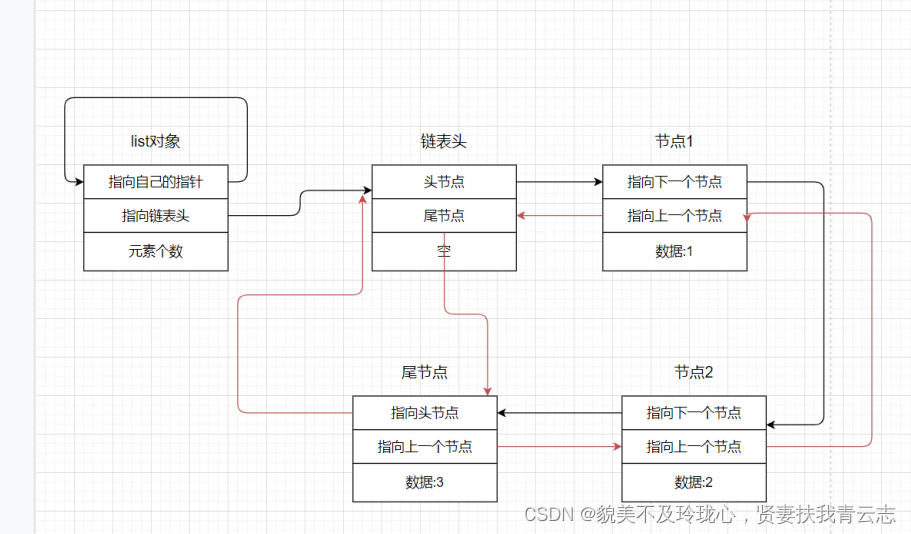
template <class T>
struct my_list
{
my_list* self; // 指向自己的指针
my_list_node<T>* header; // 指向头节点,头节点不存储数据
int size; // 元素个数
};
template <class T>
struct my_list_node
{
my_list_node* next; // 下一个节点
my_list_node* prev; // 上一个节点
T data; // 数据域
};分析map在内存中的存储形式
#include <windows.h>
#include <map>
using namespace std;
int main()
{
printf("hello guishou");
map<int, int> myMap;
myMap.insert(make_pair(1, 0x11));
myMap.insert(make_pair(2, 0x22));
myMap.insert(make_pair(3, 0x33));
myMap.insert(make_pair(4, 0x44));
return 0;
}x32dbg分析map
第一个函数初始化,这里可以确定map这个数据结构是0xC个字节
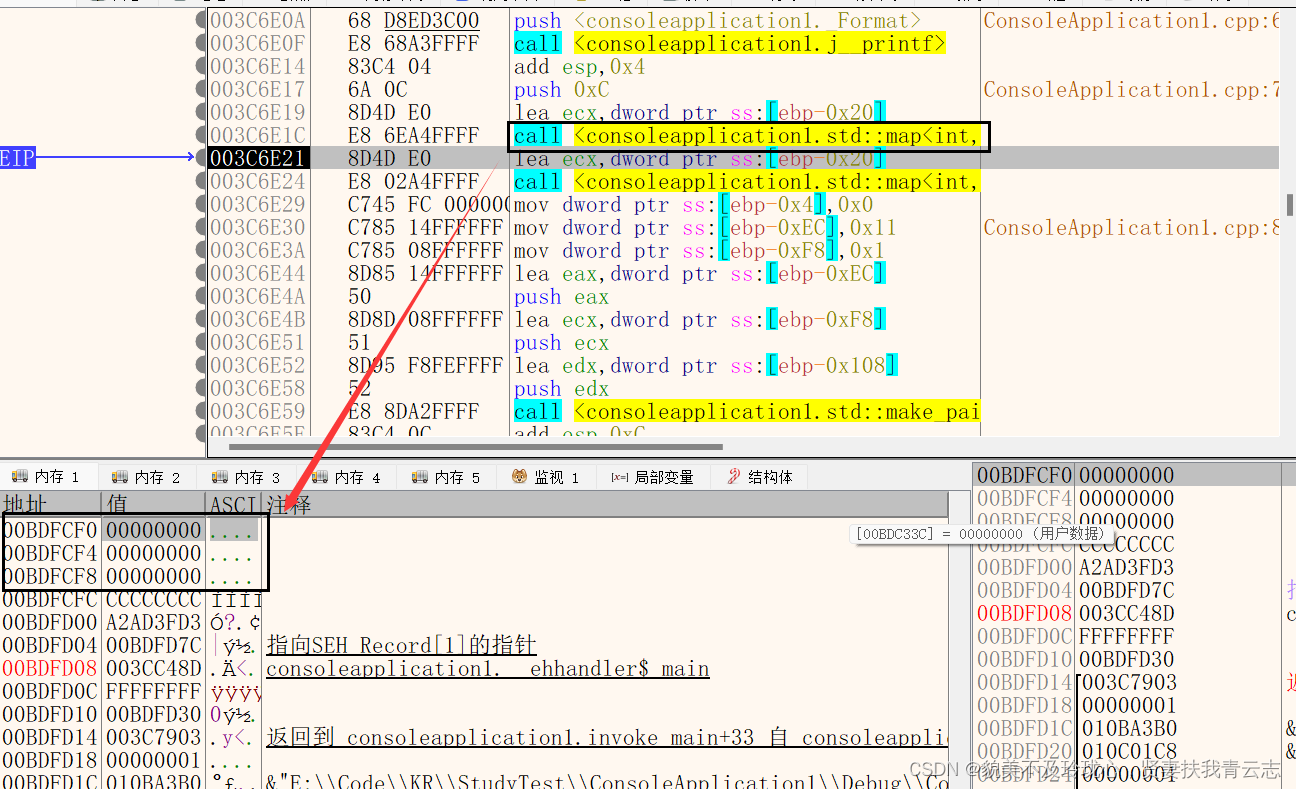
第二个函数
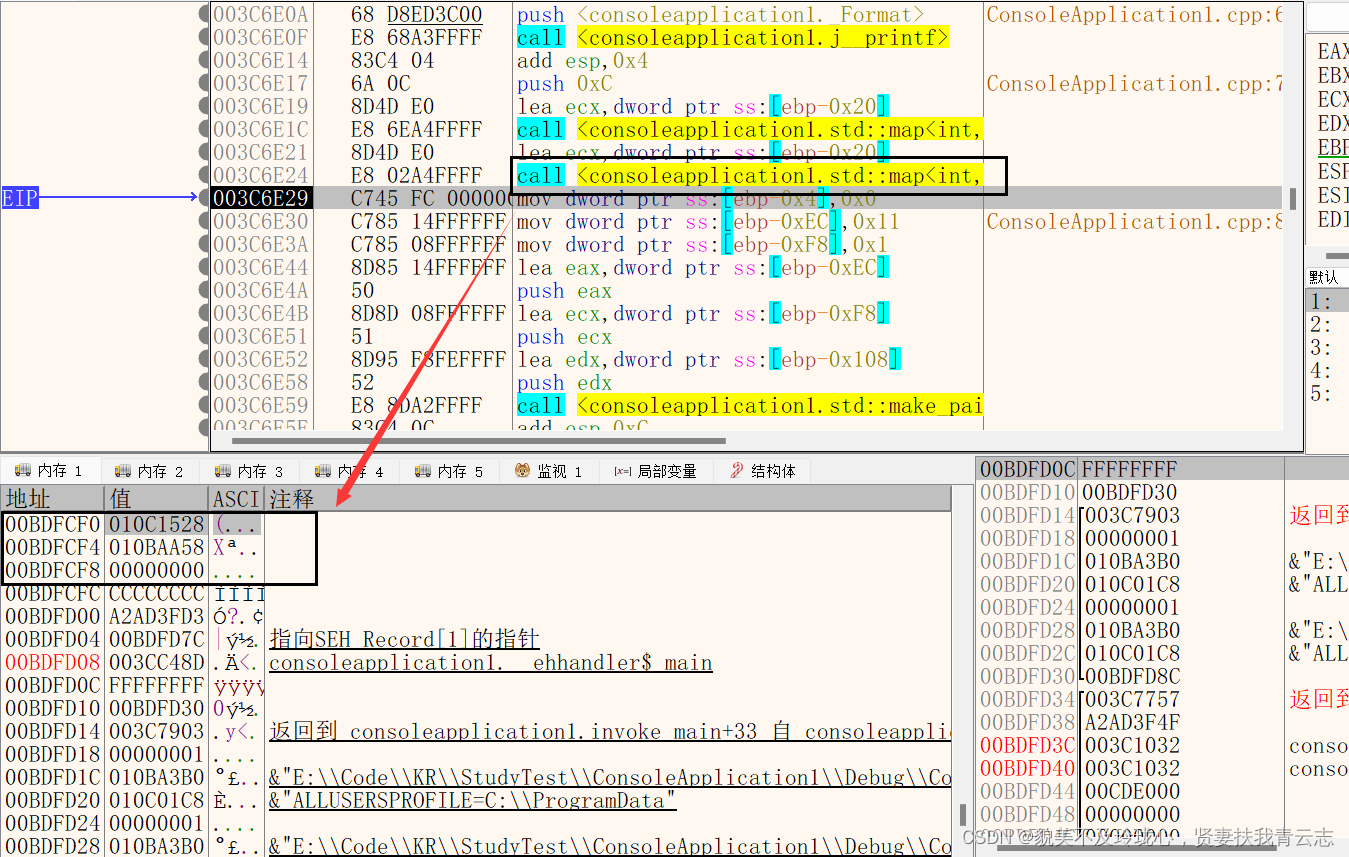
map对象,第一个地址是指针,指向自己;第二个地址指向头节点;第三个存储元素个数;
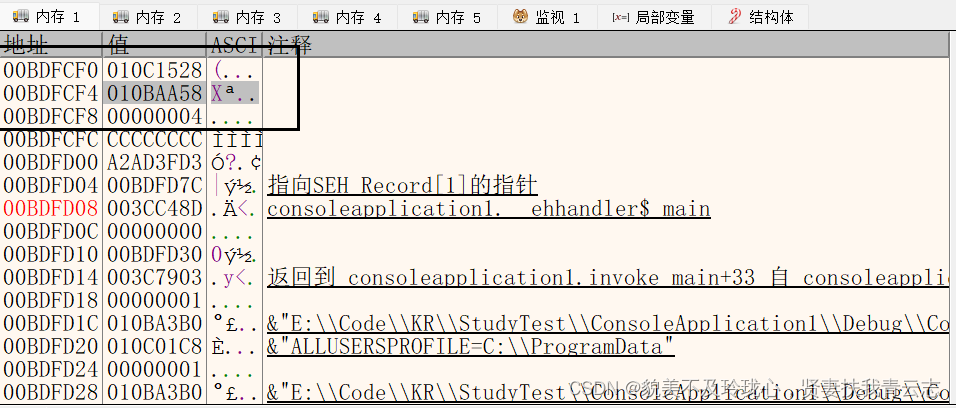
头节点
010BEFA8是1号左子节点,010BA0E0是父节点,010C2C88是右子节点
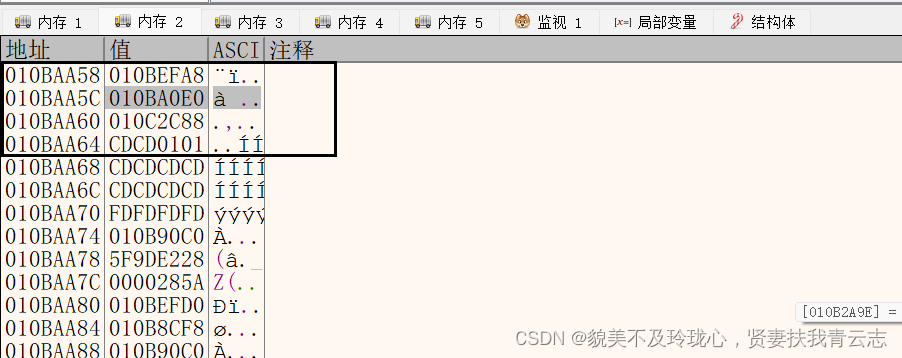
节点
+00 左节点
+04 父节点
+08 右节点
+0xC 标志->是否是叶子节点 是否是头节点
+0x10 key
+0x14 value
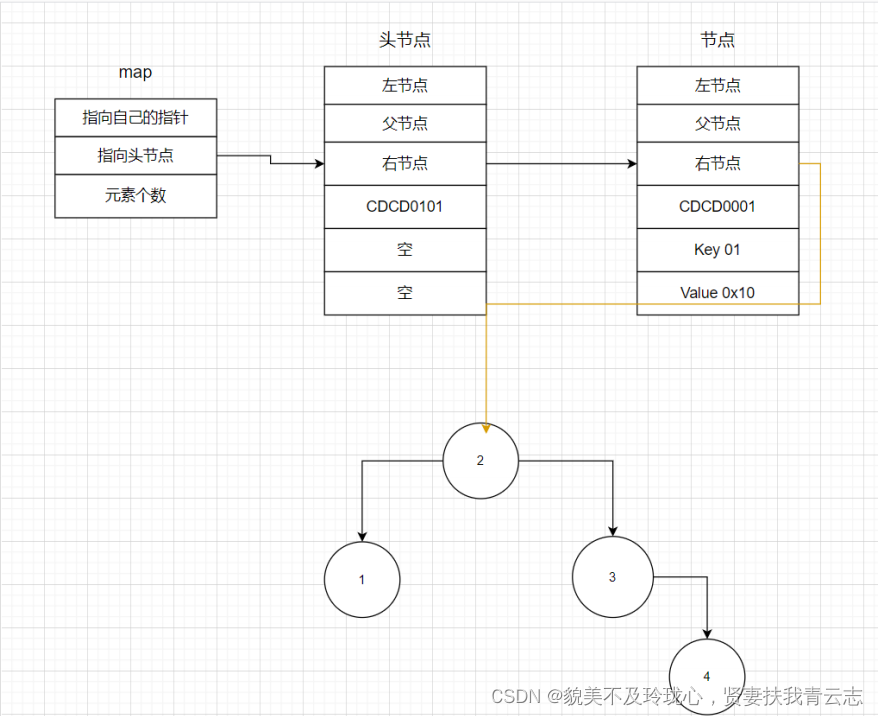
总结一下map的内存布局
map对象:
+00 指针,指向自己
+04 头节点
+08 元素个数
头节点:
+00 左节点
+04 父节点
+08 右节点
+0C CDCD0101表示头节点 CDCD0001 表示子节点
+10 key
+14 value
节点:
+00 左节点
+04 父节点
+08 右节点
+0xC 标志->是否是叶子节点 是否是头节点
+0x10 key
+0x14 value
vector list map的对比
vector对于随机访问的速度很快,但是对于插入元素的速度很慢,他需要拷贝和移动整个数据。vector适合高效存取,如果你不在乎插入和删除的效率的话可以使用。
list 对于随机访问速度很慢,因为他需要遍历整个链表,但是对于插入和删除速度快,只需要改变指针的指向就可以了。list适合频繁插入和删除,很少查找的场景
map查找速度最快,即使数据量到了百万级也是毫秒级别的,但是他的查找性能是以插入数据时维护底层红黑树作为代价的——即插入数据比较耗时。大量数据插入的场景是不适合map的,性能非常低,比vector和list慢几倍甚至十几倍。map适合偶尔插入一条数据并且很少clear,又频繁查找的场景。比如说大量数据去重 用vector和list都要遍历,而map则不需要