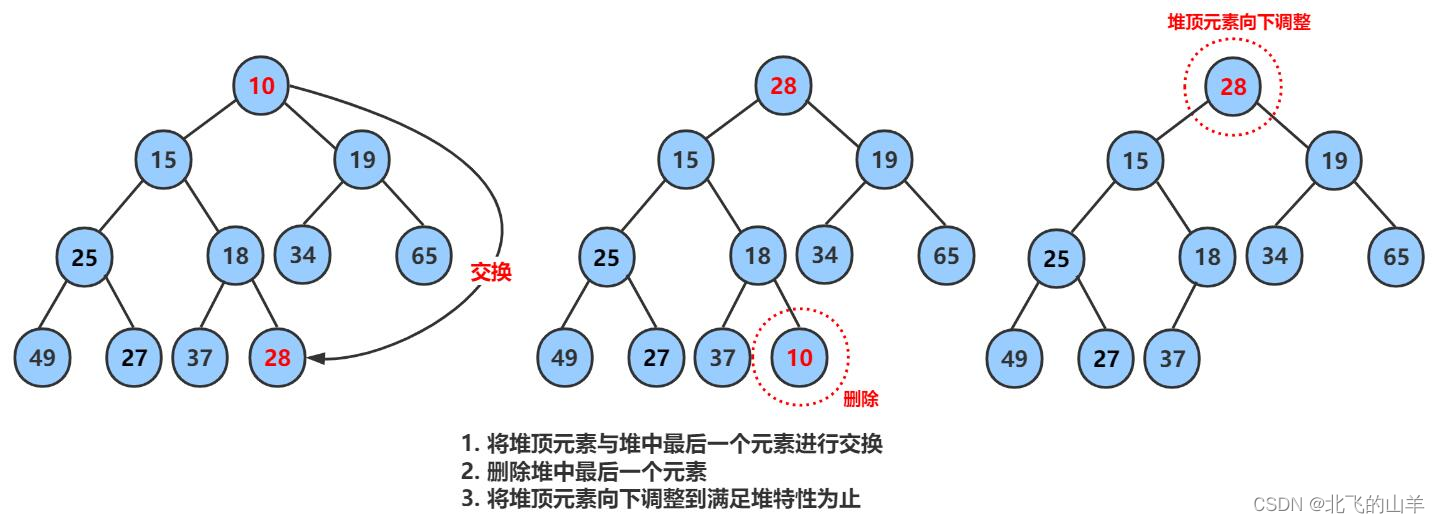
思路:
1、发送请求,解析html里面的数据
2、保存到csv文件
3、数据处理
4、数据可视化
需要用到的库:
import requests,csv #请求库和保存库
import pandas as pd #读取csv文件以及操作数据
from lxml import etree #解析html库
from pyecharts.charts import * #可视化库注意:后续用到分词库jieba以及词频统计库nltk
环境:
python 3.10.5版本
编辑器:vscode -jupyter
使用ipynb文件的扩展名 vscode会提示安装jupyter插件
一、发送请求、获取html
#请求的网址
url='https://ssr1.scrape.center/page/1'
#请求头
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
#发起请求,获取文本数据
reponse=requests.get(url,url,headers=headers)
print(reponse)
二、使用xpath提取html里面的数据并存到csv
#创建csv文件
with open('电影数据.csv',mode='w',encoding='utf-8',newline='') as f:
#创建csv对象
csv_save=csv.writer(f)
#创建标题
csv_save.writerow(['电影名','电影上映地','电影时长','上映时间','电影评分'])
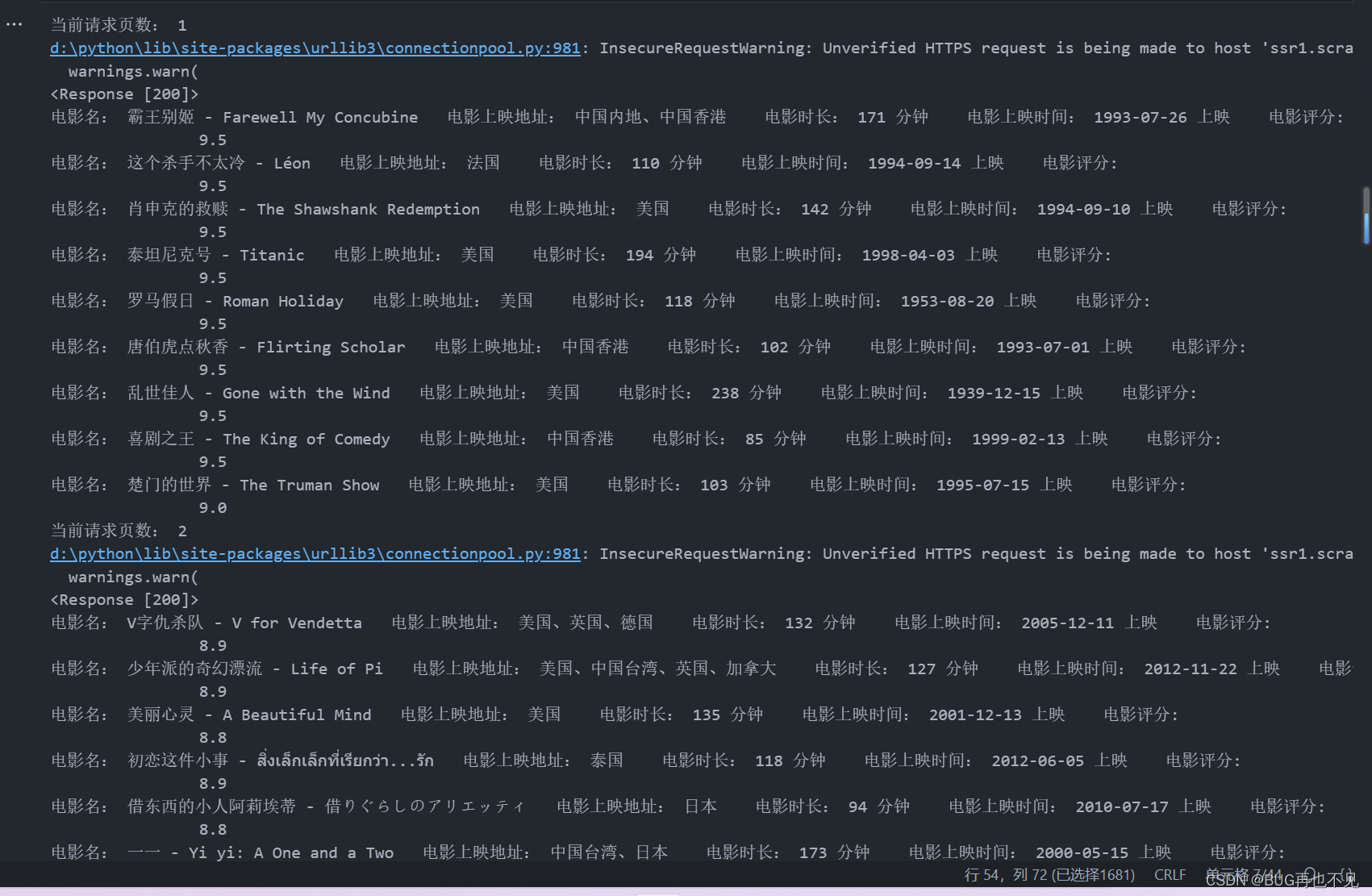
for page in range(1,11): #传播关键1到10页的页数
#请求的网址
url='https://ssr1.scrape.center/page/{}'.format(page)
print('当前请求页数:',page)
#请求头
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
response=requests.get(url,url,headers=headers,verify=False)
print(response)
html_data=etree.HTML(response.text)
#获取电影名
title=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/a/h2/text()')
#获取电影制作地
gbs=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/div[2]/span[1]/text()')
#获取电影时长
time=html_data.xpath('//div[@class="m-v-sm info"]/span[3]/text()')
#获取电影上映时间
move_time=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/div[3]/span/text()')
#电影评分
numder=html_data.xpath('//p[@class="score m-t-md m-b-n-sm"]/text()')
for name,move_gbs,times,move_times,numders in zip(title,gbs,time,move_time,numder):
print('电影名:',name,' 电影上映地址:',move_gbs,' 电影时长:',times,' 电影上映时间:',move_times,' 电影评分:',numders)
#name,move_gbs,times,move_times,numders
#写入csv文件
csv_save.writerow([name,move_gbs,times,move_times,numders])效果:
三、使用pandas打开爬取的csv文件
data=pd.read_csv('电影数据.csv',encoding='utf-8')
print(data)四、对电影名进行分词以及词频统计
注意:使用jieba分词,nltk分词
这里的停用此表可以自己创建一个 里面放无意义的字,比如:的、不是、不然这些
每个字独占一行即可
import jieba
title_list=[]
for name in data['电影名']:
#进行精准分词
lcut=jieba.lcut(name,cut_all=False)
# print(lcut)
for i in lcut :
# print(i)
#去除无意义的词
#打开停用词表文件
file_path=open('停用词表.txt',encoding='utf-8')
#将读取的数据赋值给stop_words变量
stop_words=file_path.read()
#遍历后的值 如果没有在停用词表里面 则添加到net_data列表里面
if i not in stop_words:
title_list.append(i)
# print(title_list)
#计算词语出现的频率
from nltk import FreqDist #该模块提供了计算频率分布的功能
#FreqDist对象将计算net_data中每个单词的出现频率,,并将结果存储在freq_list中
freq_list=FreqDist(title_list)
print(freq_list) #结果:FreqDist 有1321个样本和5767个结果
#该方法返回一个包含最常出现单词及其出现频率的列表。将该列表赋值给most_common_words变量。
most_common_words=freq_list.most_common()
print(most_common_words) #结果:('The这个词',出现185次)效果:
五、词云可视化
# 创建一个 WordCloud类(词云) 实例
word_cloud = WordCloud()
# 添加数据和词云大小范围 add('标题', 数据, word_size_range=将出现频率最高的单词添加到词云图中,并设置单词的大小范围为 20 到 100。)
word_cloud.add('词云图', most_common_words, word_size_range=[20, 100])
# 设置全局选项,包括标题
word_cloud.set_global_opts(title_opts=opts.TitleOpts(title='电影数据词云图'))
# 在 Jupyter Notebook 中渲染词云图
word_cloud.render_notebook()
#也可以生成html文件观看
word_cloud.render('result.html')运行效果:
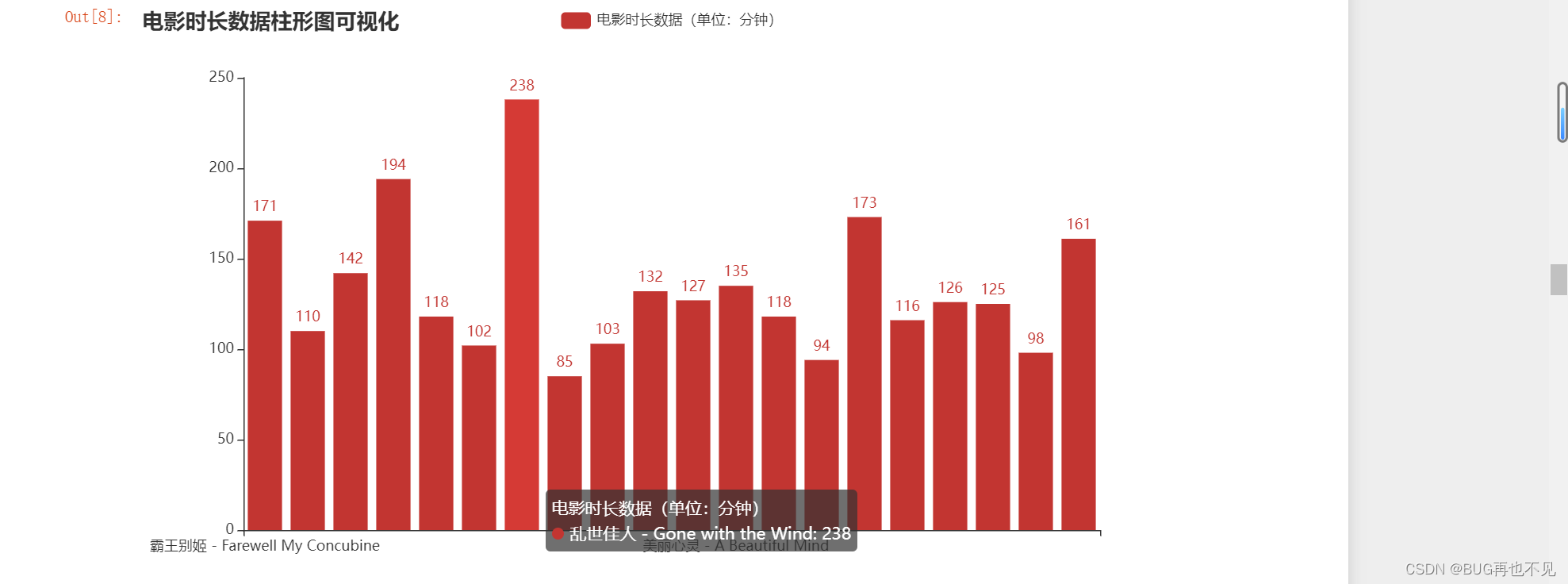
六、对电影时长进行统计并做柱形图可视化
#电影时长 去除分钟和,号这个 转为int 然后再转为列表 只提取20条数据,总共100条
move_time=data['电影时长'].apply(lambda x: x.replace('分钟', '').replace(',', '')).astype('int').tolist()[0:20]
# print(move_time)
#电影名 只提取20条数据
move_name=data['电影名'].tolist()[0:20]
# print(move_name)
#创建Bar实例
Bar_obj=Bar()
#添加x轴数据标题
Bar_obj.add_xaxis(move_name)
#添加y轴数据
Bar_obj.add_yaxis('电影时长数据(单位:分钟)',move_time)
#设置标题
Bar_obj.set_global_opts(title_opts={'text': '电影时长数据柱形图可视化'})
# 显示图表
Bar_obj.render_notebook()
效果:
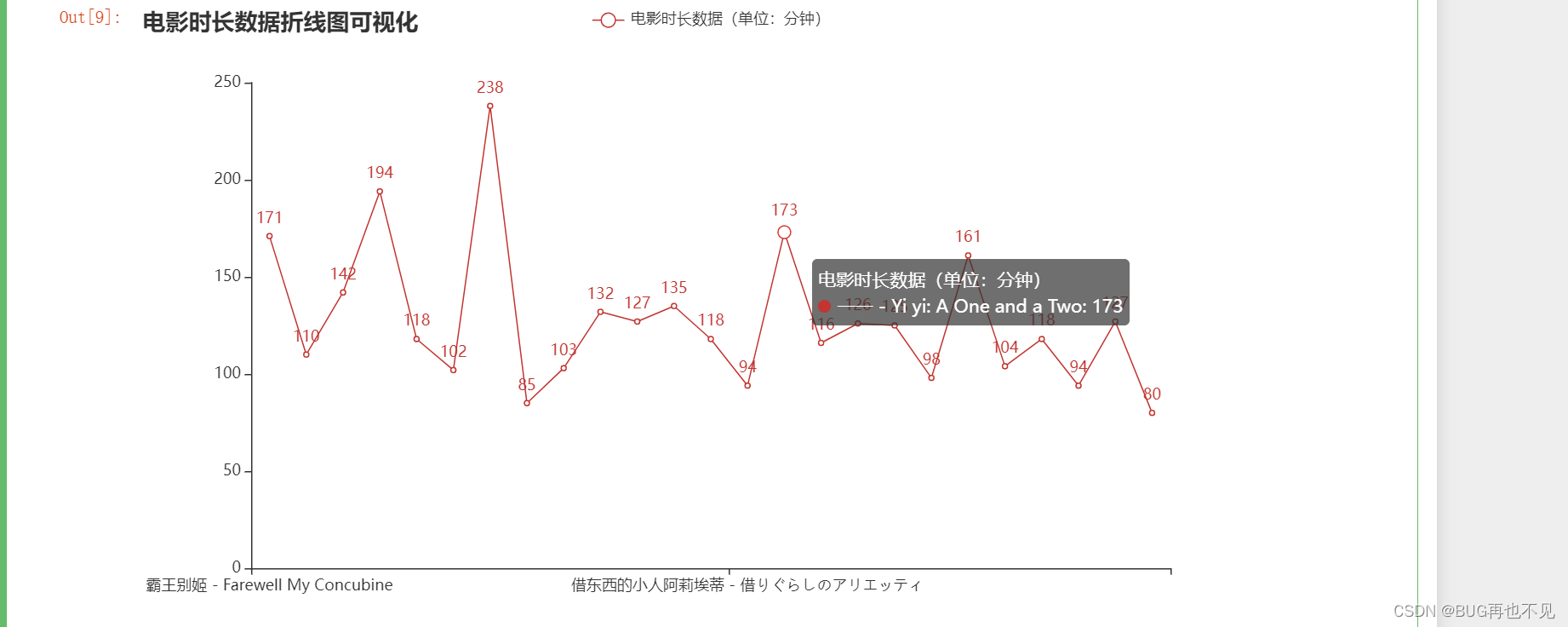
七、电影时长折线图可视化
#去除分钟和,号这个 转为int 然后再转为列表 只提取25条数据
move_time=data['电影时长'].apply(lambda x: x.replace('分钟', '').replace(',', '')).astype('int').tolist()[0:25]
# print(move_time)
#电影名 只提取25条数据
move_name=data['电影名'].tolist()[0:25]
# print(move_name)
#创建Bar实例
Bar_obj=Line()
#添加x轴数据标题
Bar_obj.add_xaxis(move_name)
#添加y轴数据
Bar_obj.add_yaxis('电影时长数据(单位:分钟)',move_time)
#设置标题
Bar_obj.set_global_opts(title_opts={'text': '电影时长数据折线图可视化'})
# 显示图表
Bar_obj.render_notebook()效果:
八、统计每个国家电影上映的数量
import jieba
title_list=[]
#遍历电影上映地这一列
for name in data['电影上映地']:
#进行精准分词
lcut=jieba.lcut(name,cut_all=False)
# print(lcut)
for i in lcut :
# print(i)
#去除无意义的词
#打开停用词表文件
file_path=open('停用词表.txt',encoding='utf-8')
#将读取的数据赋值给stop_words变量
stop_words=file_path.read()
#遍历后的值 如果没有在停用词表里面 则添加到net_data列表里面
if i not in stop_words:
title_list.append(i)
# print(title_list)
#计算词语出现的频率
from nltk import FreqDist #该模块提供了计算频率分布的功能
#FreqDist对象将计算net_data中每个单词的出现频率,,并将结果存储在freq_list中
freq_list=FreqDist(title_list)
print(freq_list) #结果:FreqDist 有1321个样本和5767个结果
#该方法返回一个包含最常出现单词及其出现频率的列表。将该列表赋值给most_common_words变量。
most_common_words=freq_list.most_common()
print(most_common_words) #结果:('单人这个词',出现185次)
#电影名 使用列表推导式来提取most_common_words中每个元素中的第一个元素,即出现次数,然后将它们存储在一个新的列表中
map_data_title = [count[0] for count in most_common_words]
print(map_data_title)
#电影数
map_data=[count[1] for count in most_common_words]
print(map_data)效果:

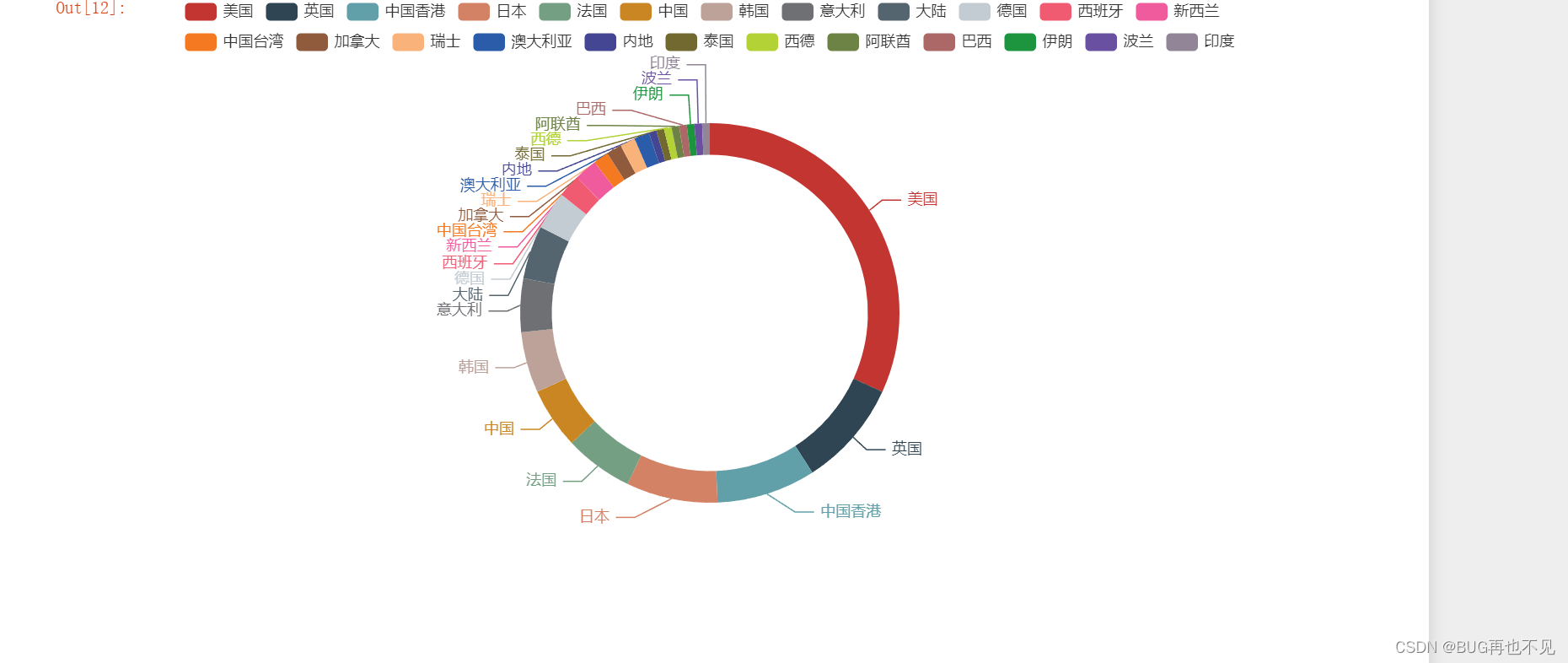
九、对每个国家电影上映数量饼图可视化
#获取map_data_title的长度,决定循环次数,赋值给遍历i 在通过下标取值
result = [[map_data_title[i], map_data[i]] for i in range(len(map_data_title))]
print(result)
# 创建Pie实例
chart=Pie()
#添加标题和数据 radius=['圆形空白处百分比','色块百分比(大小)'] 可不写
chart.add('电影上映数饼图(单位:个)',result,radius=['50%','60%'])
#显示
chart.render_notebook()效果:
觉得有帮助的话,点个赞!