文章目录
- 01 具备对海量小文件的频繁数据访问的 I/O 效率
- 02 提高 GPU 利用率,降低成本并提高投资回报率
- 03 支持各种存储系统的原生接口
- 04 支持单云、混合云和多云部署
- 01 通过数据抽象化统一数据孤岛
- 02 通过分布式缓存实现数据本地性
- 03 优化整个工作流的数据共享
- 04 通过并行执行数据预加载、缓存和训练来编排数据工作流
- 直播预告
- 直播主题
- 直播时间
- 直播观看方式
- 抽奖方式
在人工智能(AI)和机器学习(ML)领域,数据驱动的决策和模型训练已成为现代应用和研究的核心。伴随大模型技术迅猛发展,模型训练所需数据的规模不断扩大,数据的处理、存储和传输都面临着巨大的挑战,传统的存储和处理方式已经无法满足实时性和性能需求。同时,不同计算框架之间的数据孤岛问题也制约了数据的有效利用。如何在激烈竞争的大模型赛道脱颖而出,实现华丽的弯道超车,成为了众多参赛选手投入巨大人力、物力不断探索的方向。
而这其中,模型训练成为重中之重。当我们进行模型训练时,需要高效的数据平台架构快速生成分析结果,而模型训练在很大程度上依赖于大型数据集。执行所有模型训练的第一步都是将训练数据从存储输送到计算引擎的集群,而数据工作流的效率会大大影响模型训练的效率。在现实场景中,AI/ML 模型训练任务对数据平台常常有以下几个需求:
01 具备对海量小文件的频繁数据访问的 I/O 效率
AI/ML 工作流不仅包含模型训练和推理,还包括前期的数据加载和预处理步骤,尤其是前期数据处理对整个工作流都有很大影响。与传统的数据分析应用相比,AI/ML 工作负载在数据加载和预处理阶段往往对海量小文件有较频繁的 I/O 请求。因此,数据平台需要提供更高的 I/O 效率,从而更好地为工作流提速。
02 提高 GPU 利用率,降低成本并提高投资回报率
机器学习模型训练是计算密集型的,需要消耗大量的 GPU 资源,从而快速准确地处理数据。由于 GPU 价格昂贵,因此优化 GPU 的利用率十分重要。这种情况下,I/O 就成为了瓶颈——工作负载受制于 GPU 的数据供给速度,而不是GPU 执行训练计算的速度。数据平台需要达到高吞吐量和低延迟,让 GPU 集群完全饱和,从而降低成本。
03 支持各种存储系统的原生接口
随着数据量的不断增长,企业很难只使用单一存储系统。不同业务部门会使用各类存储,包括本地分布式存储系统(HDFS和Ceph)和云存储(AWS S3,Azure Blob Store,Google 云存储等)。为了实现高效的模型训练,必须能够访问存储于不同环境中的所有训练数据,用户数据访问的接口最好是原生的。
04 支持单云、混合云和多云部署
除了支持不同的存储系统外,数据平台还需要支持不同的部署模式。随着数据量的增长,云存储成为普遍选择,它可扩展性高,成本低且易于使用。企业希望不受限制地实现单云、混合云和多云部署,实现灵活和开放的模型训练。另外,计算与存储分离的趋势也越来越明显,这会造成远程访问存储系统,这种情况下数据需要通过网络传输,带来性能上的挑战。数据平台需要满足在跨异构环境访问数据时也能达到高性能的要求。
综上,AI/ML 工作负载要求能在各种类型的异构环境中以低成本快速访问大量数据。企业需要不断优化升级数据平台,确保模型训练的工作负载在能够有效地访问数据,保持高吞吐量和高 GPU 利用率 。

Alluxio作为一款强大的分布式统一大数据虚拟文件系统,已经在众多领域展现出了其卓越的应用价值,并且为AI/ML训练赋能提供了一个全新的解决方案,其核心密码有四个方面组成:
01 通过数据抽象化统一数据孤岛
Alluxio作为数据抽象层,可以做到数据无缝访问而不拷贝和移动数据,无论是在本地还是在云上的数据都留在原地。通过Alluxio,数据被抽象化从而呈现统一的视图,大大降低数据收集阶段的复杂性。
由于Alluxio已经实现与存储系统的集成,机器学习框架只需与Alluxio交互即可从其连接的任何存储中访问数据。因此,我们可以利用来自任何数据源的数据进行训练,提高模型训练质量。在无需将数据手动移动到某一集中的数据源的情况下,包括Spark、Presto、PyTorch和TensorFlow在内所有的计算框架都可以访问数据,不必担心数据的存放位置。
02 通过分布式缓存实现数据本地性
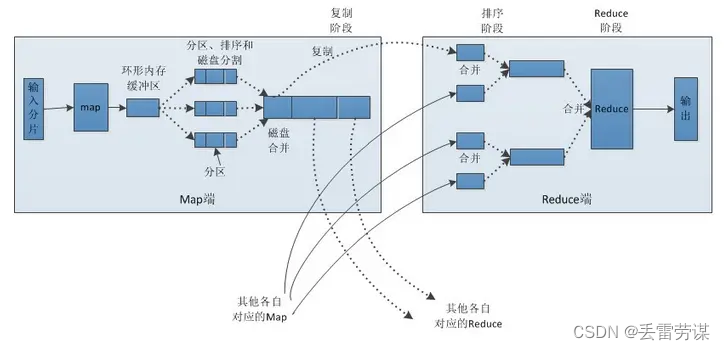
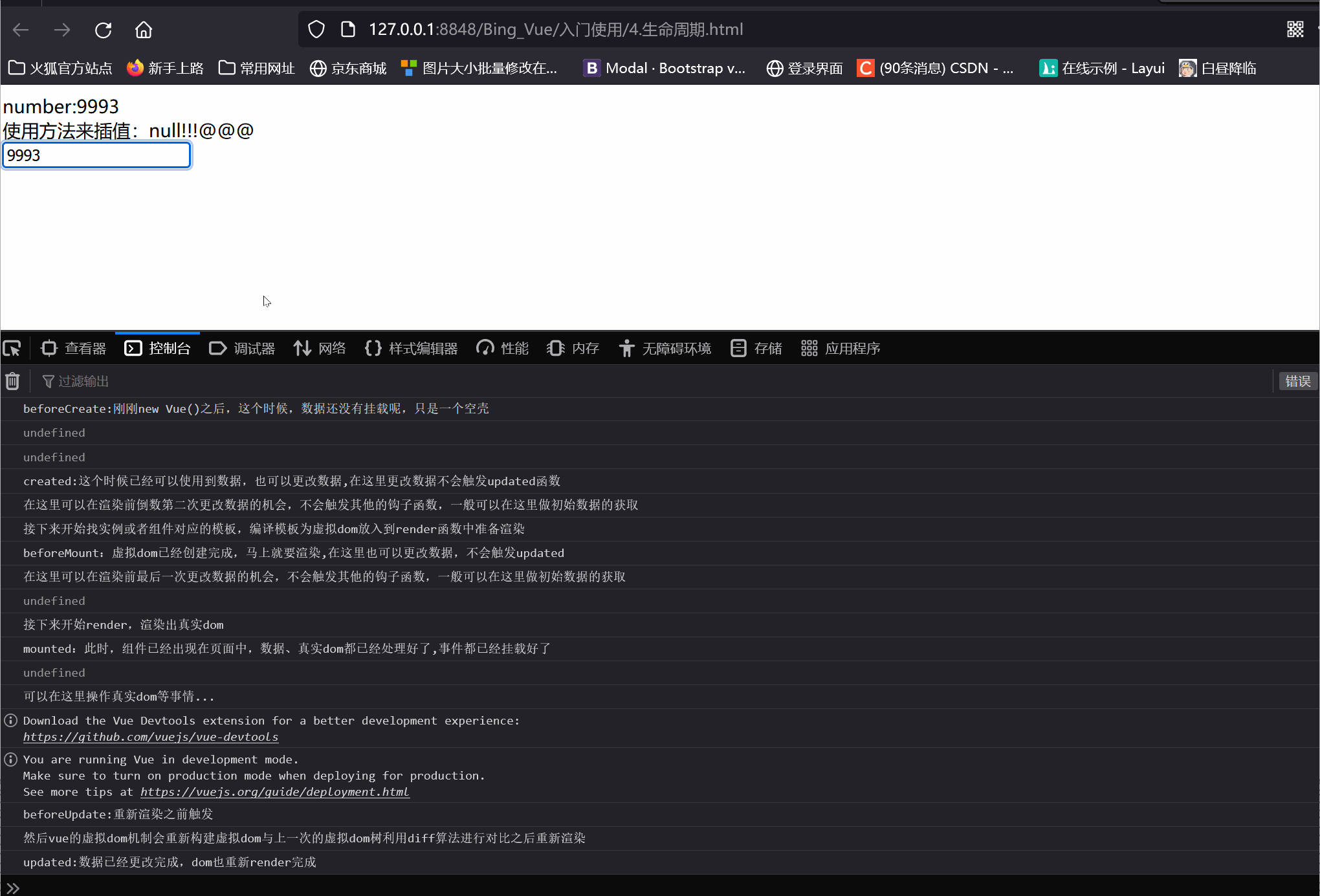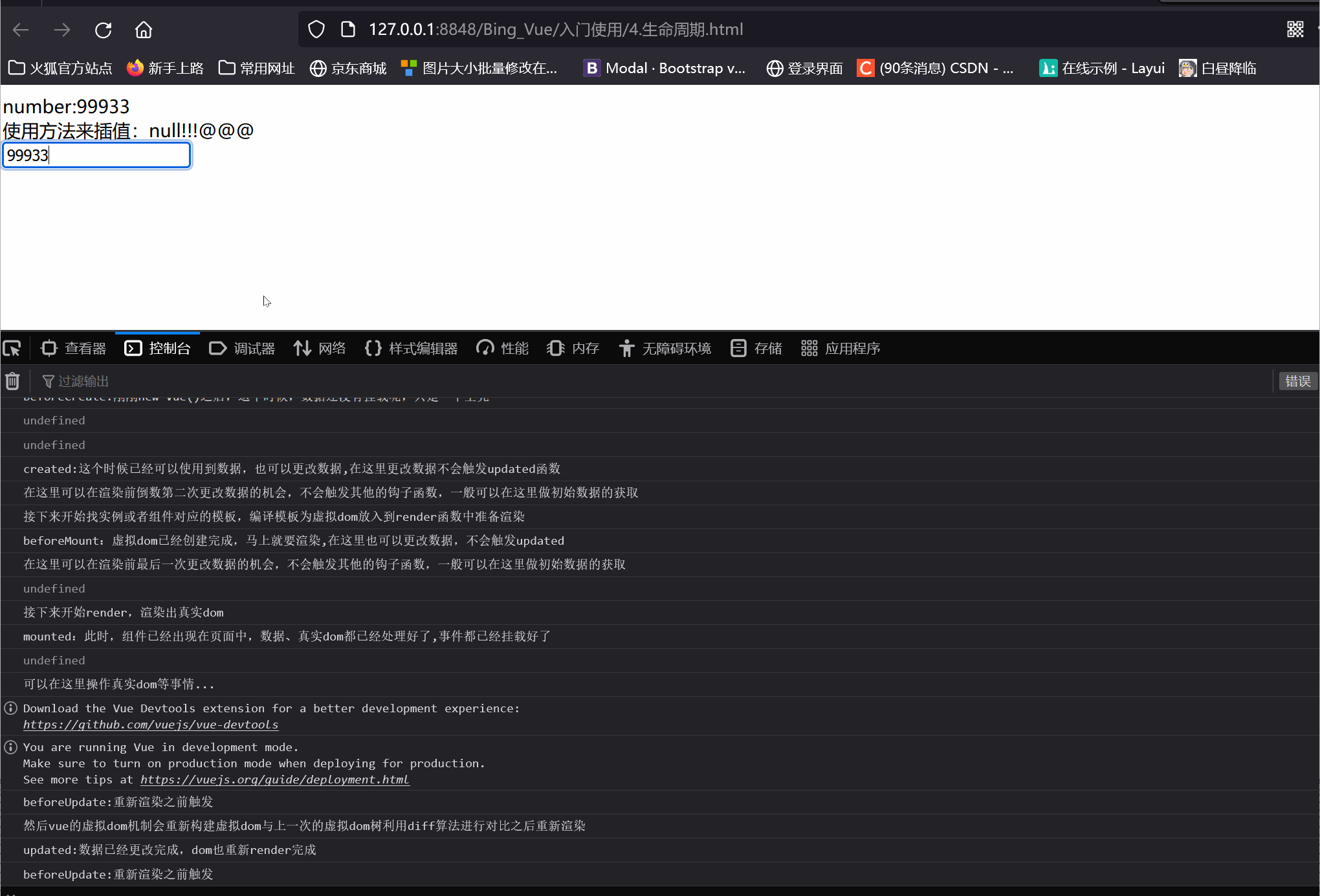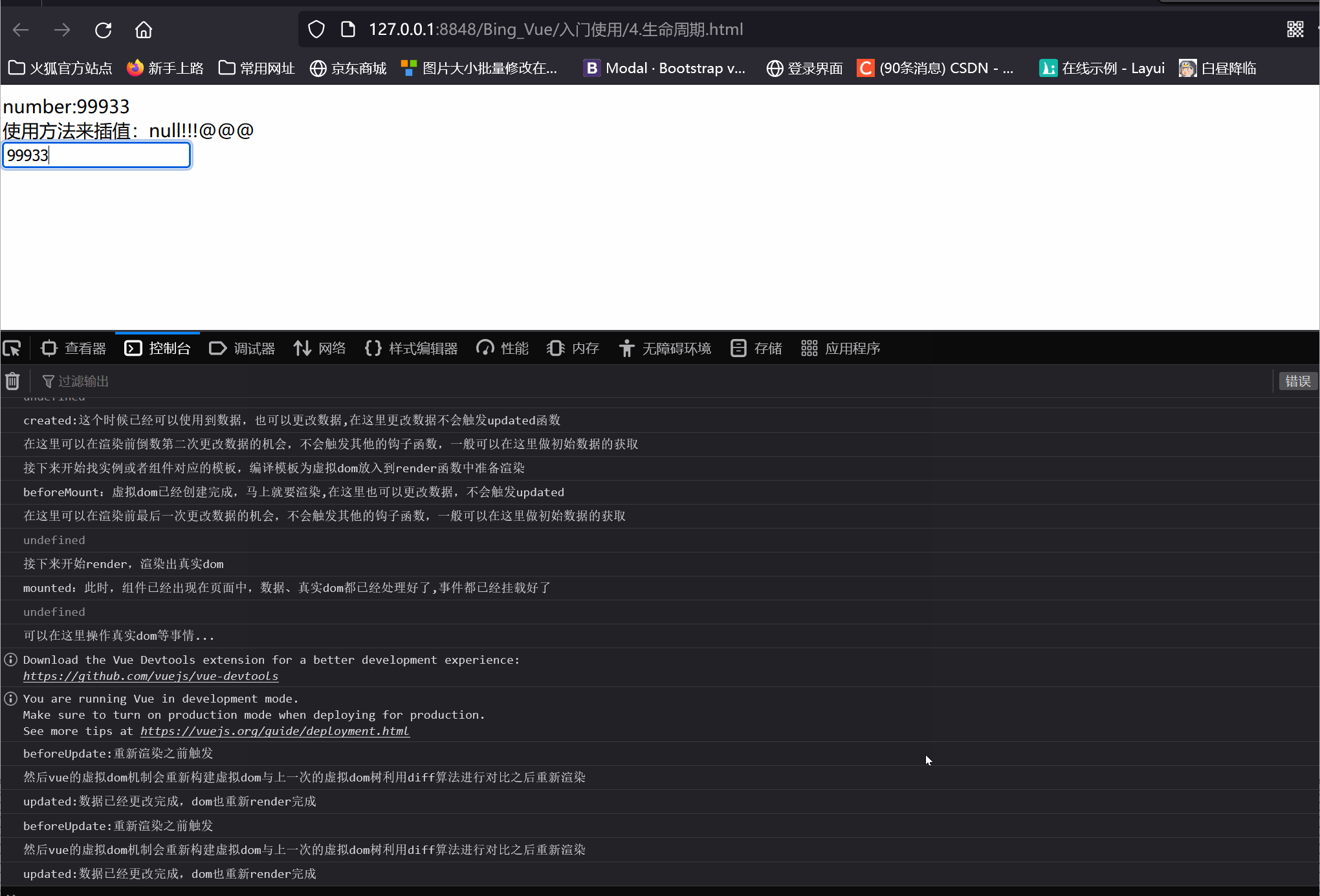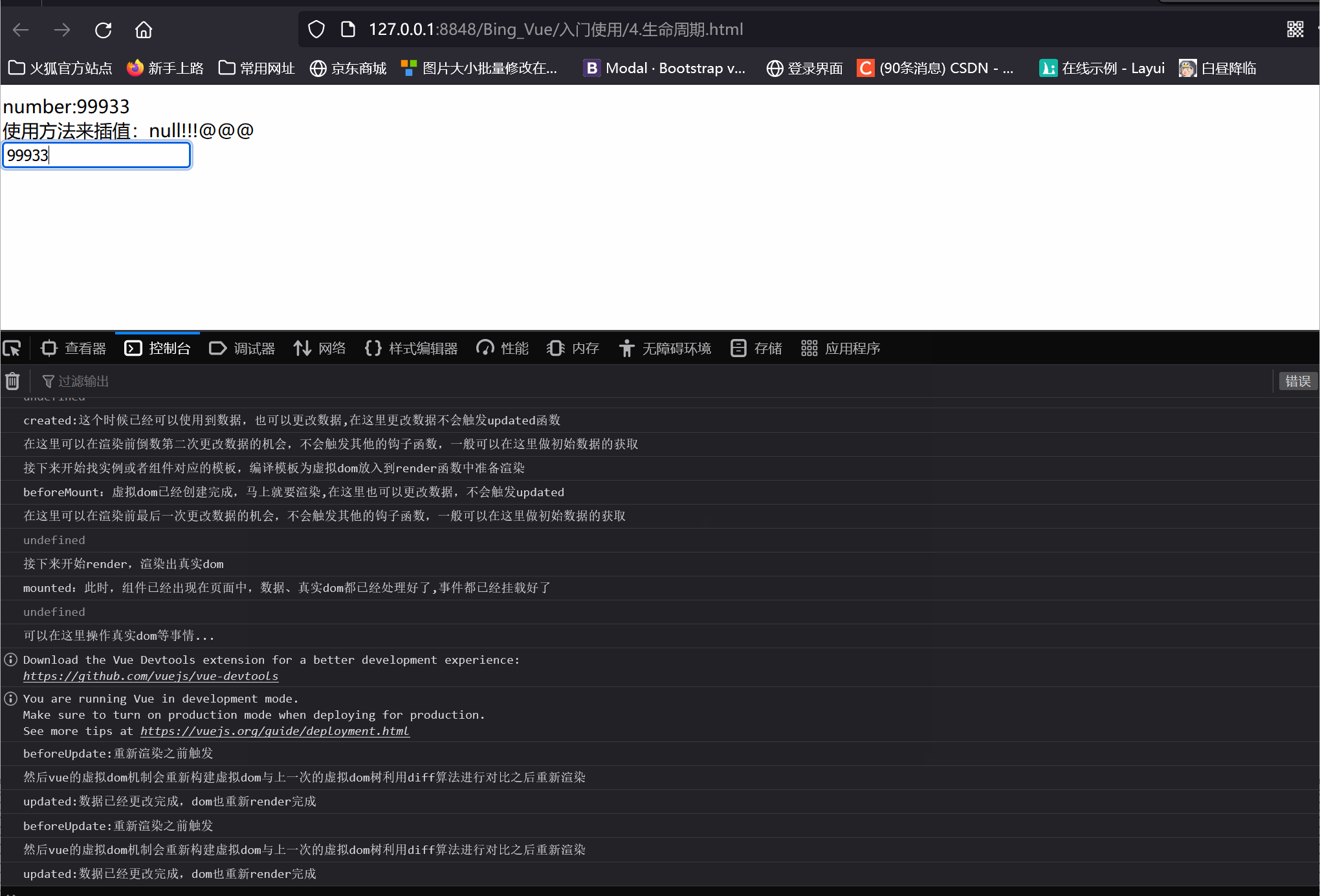
Alluxio的分布式缓存,让数据均匀地分布在集群中,而不是将整个数据集复制到每台机器上,如图1所示。当训练数据集的大小远大于单个节点的存储容量时,分布式缓存尤其有用,而当数据位于远端存储时,分布式缓存会把数据缓存在本地,有利于数据访问。此外,由于在访问数据时不产生网络I/O,机器学习训练速度更快、更高效。
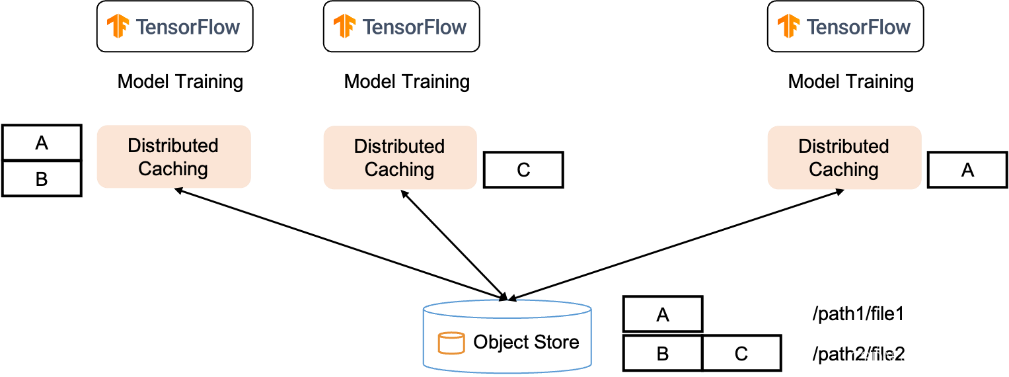
图1 分布式缓存
如上图所示,对象存储中存有全部训练数据,两个文件(/path1/file1和/path2/file2)代表数据集。我们不在每台训练节点上存储所有文件块,而是将文件块分布式地存储在多台机器上。为了防止数据丢失和提高读取并发性,每个块可以同时存储在多个服务器上。
03 优化整个工作流的数据共享
在模型训练工作中,无论是在单个作业还是不同作业之间,数据读取和写入都有很大程度的重叠。Alluxio可以让计算框架访问之前已经缓存的数据,供下一步的工作负载进行读取和写入,如图2所示。比如在数据准备阶段使用Spark进行ETL数据处理,那么数据共享可以确保输出数据被缓存,供后续阶段使用。通过数据共享,整个数据工作流都可以获得更好的端到端性能。
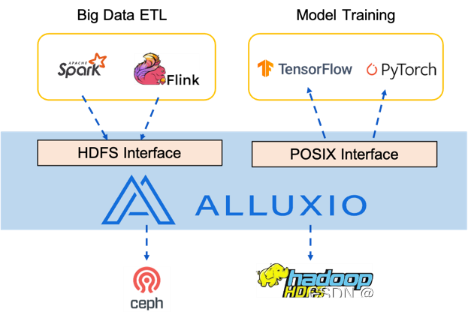
图2 通过Alluxio在工作流间传递数据
04 通过并行执行数据预加载、缓存和训练来编排数据工作流
Alluxio通过实现预加载和按需缓存来缩短模型训练的时间。如图3所示,通过数据缓存从数据源加载数据可以与实际训练任务并行执行。因此,训练在访问数据时将得益于高数据吞吐量,不必等待数据全部缓存完毕才开始训练。
图3 Alluxio数据加载提升GPU利用率
虽然一开始会出现I/O延迟,但随着越来越多的数据被加载到缓存中,I/O等待时间会减少。在本方案中,所有环节,包括训练数据集从对象存储加载到训练集群、数据缓存、按需加载用于训练的数据以及训练作业本身,都可以并行地、相互交错地执行,从而极大地加速了整个训练进程。

了解更多Alluxio与AI/ML模型训练传统方案的对比分析,具体性能测试情况,以及来自广泛行业的应用案例,欢迎阅读《分布式统一大数据虚拟文件系统——Alluxio原理、技术与实践》。
直播预告
直播主题
Alluxio: 加速新一代大数据与AI变革 |
《分布式统一大数据虚拟文件系统 Alluxio原理、技术与实践》新书发布会

直播时间
9 月 21日(星期四)
20:00 - 21:30
本次直播主要介绍Alluxio的技术原理、核心功能、使用方法,以及Alluxio在大数据分析、AI/ML等场景的实战案例。
直播观看方式
微信搜索视频号:IT阅读排行榜,预约直播

抽奖方式
-
关注 + 点赞 + 收藏 文章
-
评论区留言:学全栈知识找鹤冲天(关注并留言才能进入奖池,每人最多留言三条)
-
周日晚八点随机抽奖
-
本次送书2~5本【阅读量越多,送的越多】
500-1000 赠书2本
1000-1500 赠书3本
1500-2000 赠书4本
2000+ 赠书5本