环境安装
# 创建虚拟环境facechain
conda create -n facechain python=3.8
conda activate facechain
# 克隆
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
# 安装第三方库
cd facechain
pip install -r requirements.txt
pip install -U openmim
# 设置所需的CUDA,因为安装了多个版本的CUDA
export PATH=/home/xxx/.local/cuda-11.7/bin:$PATH
export LD_LIBRARY_PATH=LD_LIBRARY_PATH:/home/xxx/.local/cuda-11.7/lib64
export CUDA_HOME=/home/xxx/.local/cuda-11.7
# 安装mmcv
mim install mmcv-full==1.7.0
webui的运行方式
-
app.py文件增加临时文件存放位置,因为多个人使用同一个服务,gradio的临时文件会存放在
/tmp/gradio下存在权限问题。import tempfile tempfile.tempdir = './tmp' -
app.py文件修改modelscope和huggingface的目录
import os os.environ['MODELSCOPE_CACHE'] = '/opt/buty/work/modelscope' os.environ['HF_HOME'] = '/opt/buty/work/huggingface' os.environ['CUDA_VISIBLE_DEVICES'] = '0' -
snapdown 文件的路径使用临时文件存放位置还是有问题,需要修改
/tmp/snapdown/目录的权限sudo chmod -R 777 /tmp/snapdown/ -
运行脚本
python app.py
命令行交互界面的运行方式
-
train_text_to_image_lora.py文件修改modelscope和huggingface的目录
import os os.environ['MODELSCOPE_CACHE'] = '/opt/buty/work/modelscope' os.environ['HF_HOME'] = '/opt/buty/work/huggingface' os.environ['CUDA_VISIBLE_DEVICES'] = '0' -
模型训练
PYTHONPATH=. sh train_lora.sh "ly261666/cv_portrait_model" "v2.0" "film/film" "./imgs" "./processed" "./output" -
推理
python run_inference.py
pycharm的运行方式
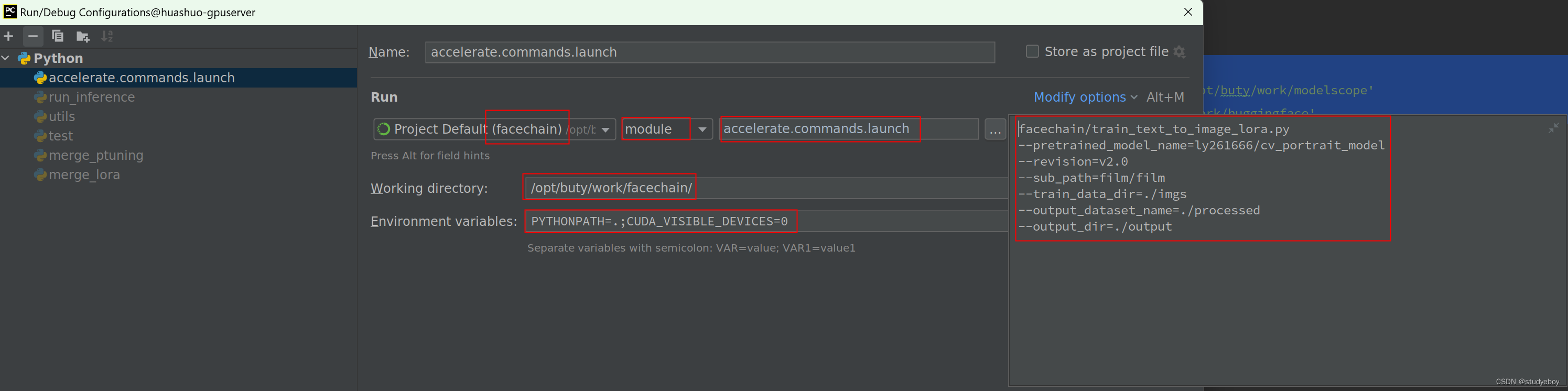
train_text_to_image_lora.py脚本Edit Configurations设置:
Name:accelerate.commands.launch
Run:facechain module accelerate.commands.launch
Parameters:
facechain/train_text_to_image_lora.py
--pretrained_model_name=ly261666/cv_portrait_model
--revision=v2.0
--sub_path=film/film
--train_data_dir=./imgs
--output_dataset_name=./processed
--output_dir=./output
Working directory:/opt/buty/work/facechain
Environment variables:
CUDA_VISIBLE_DEVICES:0
PYTHONPATH: .
参考资料
modelscope/facechain