介绍
最近我们被客户要求撰写关于性混合效应模型的研究报告,包括一些图形和统计输出。首先,请注意,围绕多层次模型的术语有很大的不一致性。例如,多层次模型本身可能被称为分层线性模型、随机效应模型、多层次模型、随机截距模型、随机斜率模型或集合模型。根据不同的学科、使用的软件和学术文献,许多这些术语可能指的是相同的一般建模策略。
相关视频:线性混合效应模型(LMM,Linear Mixed Models)和R语言实现
线性混合效应模型(LMM,Linear Mixed Models)和R语言实现案例
时长12:13
在本文中,我将试图通过演示如何在R中拟合多层次模型,并试图将模型拟合过程与有关这些模型的常用术语联系起来,为用户提供一个多层次模型的指南。
读入数据
多层次模型适合于一种特殊的数据结构,即单位嵌套在组内(一般是5个以上的组),我们想对数据的组结构进行建模。
## id extro open agree social class school
## 1 1 63.69 43.43 38.03 75.06 d IV
## 2 2 69.48 46.87 31.49 98.13 a VI
## 3 3 79.74 32.27 40.21 116.34 d VI
## 4 4 62.97 44.41 30.51 90.47 c IV
## 5 5 64.25 36.86 37.44 98.52 d IV
## 6 6 50.97 46.26 38.83 75.22 d I在这里,我们有关于嵌套在班级和学校内的科目的外向性的数据。
在我们开始之前,让我们先了解一下数据的结构。
## 'data.frame': 1200 obs. of 7 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
## $ extro : num 63.7 69.5 79.7 63 64.2 ...
## $ open : num 43.4 46.9 32.3 44.4 36.9 ...
## $ agree : num 38 31.5 40.2 30.5 37.4 ...
## $ social: num 75.1 98.1 116.3 90.5 98.5 ...
## $ class : Factor w/ 4 levels "a","b","c","d": 4 1 4 3 4 4 4 4 1 2 ...
## $ school: Factor w/ 6 levels "I","II","III",..: 4 6 6 4 4 1 3 4 3 1 ...这里我们看到我们有两个可能的分组变量--班级和学校。让我们进一步探讨一下它们。
##
## a b c d
## 300 300 300 300
##
## I II III IV V VI
## 200 200 200 200 200 200
##
## I II III IV V VI
## a 50 50 50 50 50 50
## b 50 50 50 50 50 50
## c 50 50 50 50 50 50
## d 50 50 50 50 50 50这是一个完全平衡的数据集。让我们来绘制一下数据。可以探索学校和班级之间的变量关系。
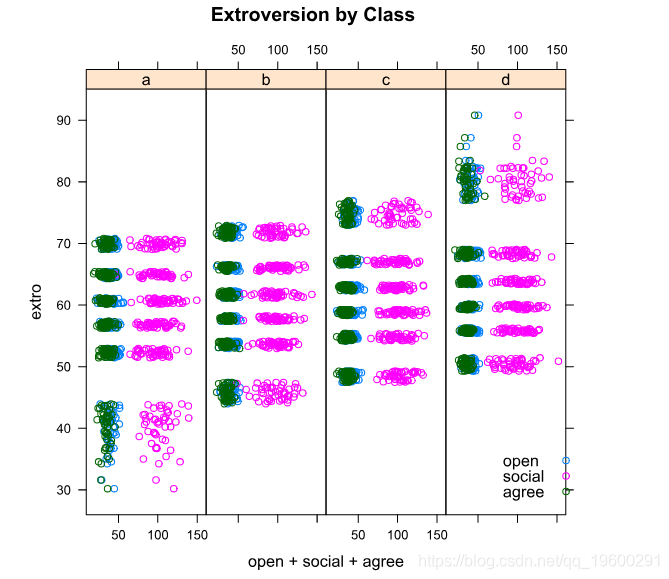
plot(extro ~ open + social + agree | school + class
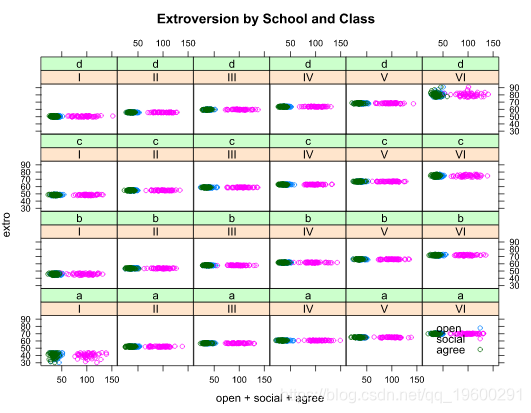
在这里我们看到,在班级内部有明显的分层,我们也看到社会变量与开放和赞同变量有强烈的区别。我们还看到,A班和D班在最低和最高段的分布明显更多。接下来让我们按学校绘制数据。
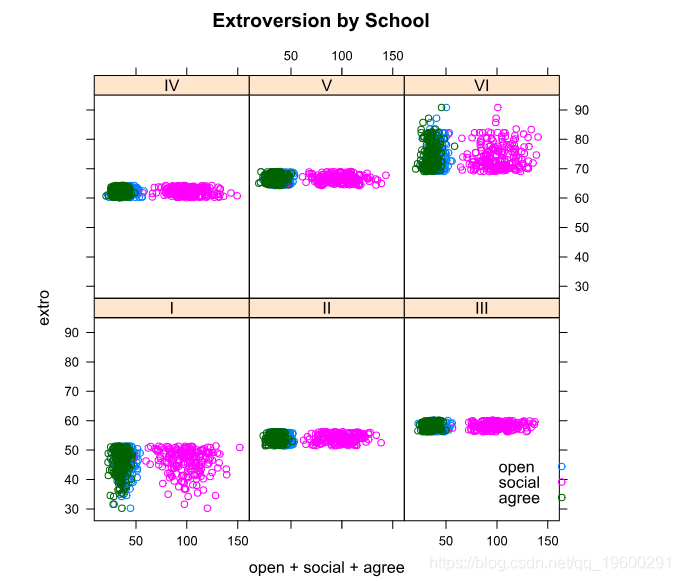
按学校划分,我们看到学生的分组很紧密,但学校一和学校六比其他学校显示出明显的分散性。在学校之间,我们的预测指标的模式与班级之间的模式相同。
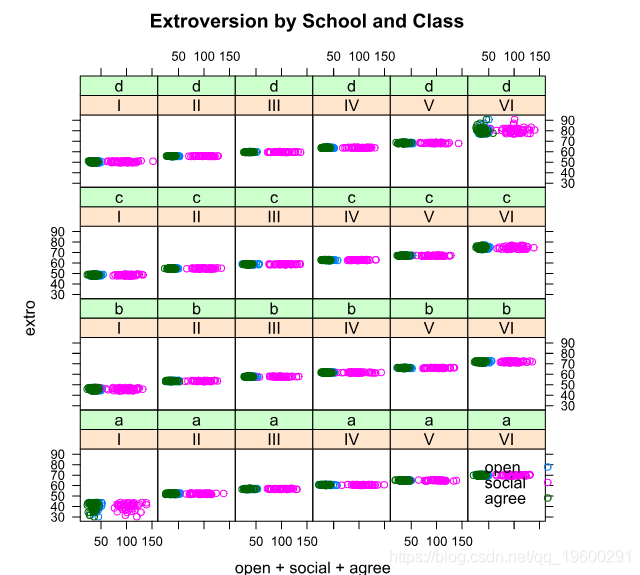
这里我们可以看到,学校和班级似乎密切区分了我们的预测因素和外向性之间的关系。
探索merMod对象
我们对我们的嵌套数据拟合了一系列的随机截距模型。我们将更深入地研究我们拟合这个模型时产生的lmerMod对象,以了解如何在R中使用混合效应模型。我们首先拟合下面这个按班级分组的基本例子。
## [1] "lmerMod"
## attr(,"package")
## [1] "lme4"首先,我们看到MLexamp1现在是一个lmerMod类的R对象。这个lmerMod对象是一个S4类,为了探索其结构,我们使用slotNames。
## [1] "resp" "Gp" "call" "frame" "flist" "cnms" "lower"
## [8] "theta" "beta" "u" "devcomp" "pp" "optinfo"在lmerMod对象中,我们看到了一些我们可能希望探索的对象。比如说。
## lmer(formula = extro ~ open + agree + social + (1 | school),
## data = lmm.data)
## [1] 59.116514 0.009751 0.027788 -0.002151
## [1] "data.frame"
## extro open agree social school
## 1 63.69 43.43 38.03 75.06 IV
## 2 69.48 46.87 31.49 98.13 VI
## 3 79.74 32.27 40.21 116.34 VI
## 4 62.97 44.41 30.51 90.47 IV
## 5 64.25 36.86 37.44 98.52 IV
## 6 50.97 46.26 38.83 75.22 ImerMod对象有许多可用的方法--在此无法一一列举。但是,我们将在下面的列表中介绍一些比较常见的方法。
## [1] anova.merMod* as.function.merMod* coef.merMod*
## [4] confint.merMod deviance.merMod* df.residual.merMod*
## [7] drop1.merMod* extractAIC.merMod* extractDIC.merMod*
## [10] family.merMod* fitted.merMod* fixef.merMod*
## [13] formula.merMod* isGLMM.merMod* isLMM.merMod*
## [16] isNLMM.merMod* isREML.merMod* logLik.merMod*
## [19] model.frame.merMod* model.matrix.merMod* ngrps.merMod*
## [22] nobs.merMod* plot.merMod* predict.merMod*
## [25] print.merMod* profile.merMod* qqmath.merMod*
## [28] ranef.merMod* refit.merMod* refitML.merMod*
## [31] residuals.merMod* sigma.merMod* simulate.merMod*
## [34] summary.merMod* terms.merMod* update.merMod*
## [37] VarCorr.merMod* vcov.merMod weights.merMod*
##
## Non-visible functions are asterisked一个常见的需求是从merMod对象中提取固定效应。 fixef提取一个固定效应的命名数字向量,这很方便。
## (Intercept) open agree social
## 59.116514 0.009751 0.027788 -0.002151了解这些参数的p值或统计显着性:
如果你想了解这些参数的P值或统计学意义,首先通过运行 "mcmcsamp "查阅lme4帮助,了解各种方法。包中内置的一个方便的方法是。
## 0.5 % 99.5 %
## .sig01 4.91840 23.88758
## .sigma 2.53287 2.81456
## (Intercept) 46.27751 71.95610
## open -0.02465 0.04415
## agree -0.01164 0.06721
## social -0.01493 0.01063从这里我们可以首先看到我们的固定效果参数重叠0表示没有效果。我们还可以看到.sig01,这是我们对随机效应变化的估计。这表明我们的群体之间的影响很小,要么得到更精确的估计的群体太少。
另一个常见的需求是提取残余标准误差,这是计算效果大小所必需的。要获得残差标准误的命名向量:
## [1] 2.671例如,教育研究中的常见做法是通过将固定效应参数除以残差标准误差来将固定效果标准化为“效果大小”:
## (Intercept) open agree social
## 22.1336705 0.0036508 0.0104042 -0.0008055从这一点,我们可以看到,我们对开放性,赞同性和社交性的预测因素在预测外向性方面几乎毫无用处。让我们把注意力转向下一个随机效应。
探索组变化和随机效果
您很可能适合混合效果模型,因为您直接对模型中的组级变化感兴趣。目前还不清楚如何从结果中探索这种群体水平的变化summary.merMod。我们从这个输出得到的是组效应的方差和标准偏差。
## $school
## (Intercept)
## I -14.091
## II -6.183
## III -1.971
## IV 1.966
## V 6.331
## VI 13.948运行ranef函数可以得到每个学校的截距,但没有太多的额外信息--例如这些估计值的精确度。我们需要一些额外的命令。
## [1] "ranef.mer"
## , , 1
##
## [,1]
## [1,] 0.03565
##
## , , 2
##
## [,1]
## [1,] 0.03565
##
## , , 3
##
## [,1]
## [1,] 0.03565
##
## , , 4
##
## [,1]
## [1,] 0.03565
##
## , , 5
##
## [,1]
## [1,] 0.03565
##
## , , 6
##
## [,1]
## [1,] 0.03565ranef.mer对象是一个列表,其中包含每个组水平的数据框。数据框包含每个组的随机效应(这里我们只有每个学校的截距)。lme4提供随机效应的条件方差时,它储存在这些数据框的一个属性中,作为方差-协方差矩阵的一个列表。
这种结构的确很复杂,但它很强大,因为它允许嵌套的、分组的和跨级别的随机效应。
## $school
## (Intercept)
## I -14.091
## II -6.183
## III -1.971
## IV 1.966
## V 6.331
## VI 13.948
##
## with conditional variances for "school"
## $school
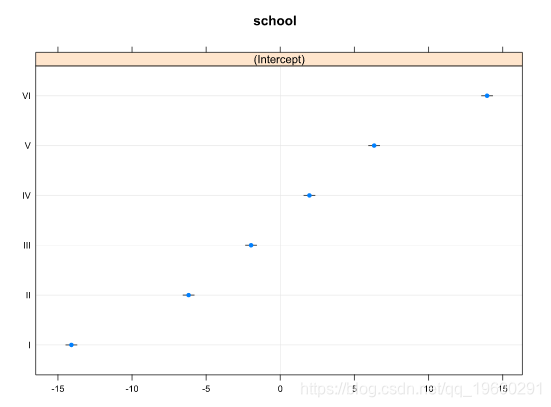
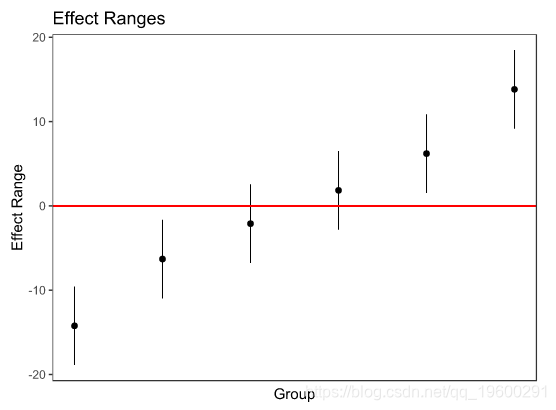
这个图形显示了随机效应项的点阵图,也被称为毛毛虫图。在这里,你可以清楚地看到每个学校对外向性的影响,以及它们的标准误差,以帮助确定随机效应之间的区别。
使用模拟和图来探索随机效应
一种常见的计量经济学方法是创建所谓的群体水平项的经验贝叶斯估计。但是,对于什么是随机效应项的适当标准误差,甚至对于如何一致地定义经验贝叶斯估计值,目前还没有太多的共识。在R中,有一些额外的方法可以获得随机效应的估计值。
## X1 X2 mean median sd
## 1 I (Intercept) -14.053 -14.093 3.990
## 2 II (Intercept) -6.141 -6.122 3.988
## 3 III (Intercept) -1.934 -1.987 3.981
## 4 IV (Intercept) 2.016 2.051 3.993
## 5 V (Intercept) 6.378 6.326 3.981
## 6 VI (Intercept) 13.992 14.011 3.987REsim函数为每个学校返回水平名称X1、估计名称X2、估计值的平均值、中位数和估计值的标准差。
另一个方便的函数可以帮助我们绘制这些结果,看看它们与dotplot的结果相比如何。
ymin = "ymin")) +
geom_pointrange() + theme_dpi() +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
axis.text.x = element_blank(), axis.ticks.x = element_blank()) +
geom_hline(yintercept = 0, color = I("red"), size = I(1.1))
}
根据你的数据收集方式和你的研究问题,估计这些效应大小的其他方法是可能的。
我们可以测试是否包含随机效应来提高模型的拟合度,我们可以使用基于模拟的似然比测试来评估额外的随机效应项的p值。
##
## simulated finite sample distribution of LRT. (p-value based on
## 10000 simulated values)
##
## data:
## LRT = 2958, p-value < 2.2e-16这里程序发出了一个警告,因为我们最初是用REML而不是完全最大似然来拟合模型。但lme4中的refitML函数允许我们使用完全最大似然法轻松地重新拟合我们的模型。
##
## simulated finite sample distribution of LRT. (p-value based on
## 10000 simulated values)
##
## data:
## LRT = 2958, p-value < 2.2e-16在这里,我们可以看到,即使每个单独的群体的影响可能是实质性的小和/或不精确的测量,但纳入我们的分组变量是显著的。这对于理解模型是很重要的。
随机效应有什么意义?
如何解释我们的随机效应的实质性影响?在使用多层次结构的观察工作中,这往往是至关重要的,了解分组对个体观察的影响。为了做到这一点,我们选择了12个随机案例,然后模拟他们的预测值,如果他们被安排在6所学校中的每一所,他们的extro预测值。请注意,这是一个非常简单的模拟,只是使用了固定效应的平均值和随机效应的条件模式,并没有进行复制或抽样。
qplot(school, yhat, data = simDat) + facet_wrap(~case) + theme_dpi() 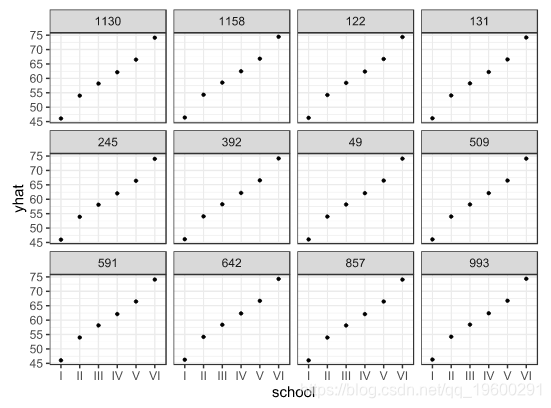
这张图告诉我们,在每个图中,代表一个案例,不同的学校有很大的变化。因此,把每个学生移到不同的学校,对外向性得分有很大的影响。但是,每个案例在每个学校都有差异吗?
+ facet_wrap(~school) + theme_dpi() +
theme(axis.text.x = element_blank())
在这里,我们可以清楚地看到,在每所学校内,案例相对相同,表明群体效应大于个体效应。
这些图在以实质性的方式展示群体和个体效应的相对重要性方面很有用。甚至还可以做更多的事情来使图表更有信息量,比如提到结果的总变异性,也可以看一下移动群体使每个观察值离其真实值的距离。
结论
R为处理混合效应模型提供了一个非常强大的面向对象的工具集。理解模型拟合和置信区间需要一些研究。