stack:https://cplusplus.com/reference/stack/stack/?kw=stack
1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行 元素的插入与提取操作。
2. stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定 的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
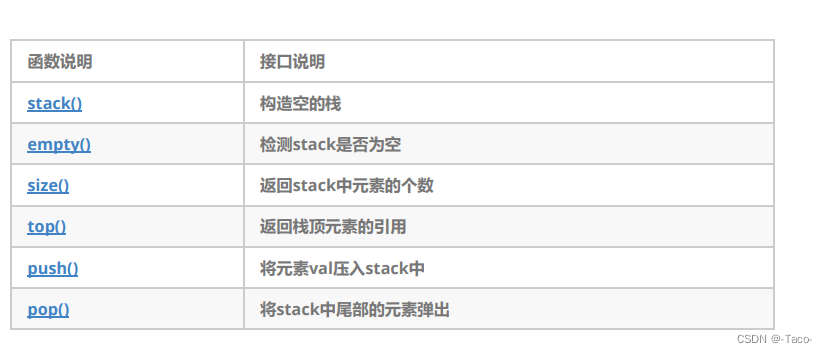
3. stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下 操作: empty:判空操作 back:获取尾部元素操作 push_back:尾部插入元素操作 pop_back:尾部删除元素操作
4. 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器, 默认情况下使用deque。

文档中我们发现:stack和queue的接口少了许多,没有了迭代器(这是因为要保持他们的特性)
如果有了迭代器的话,就可以直接遍历,失去了这两个数据结构的特性 ;
栈:是先进后出
队列:先进先出
stack的使用
#pragma once
#include<iostream>
#include<vector>
#include<deque>
using namespace std;
namespace lrx
{
template<class T,class Container=deque<T>>
//通过访问STL库我们发现在这里的cointainer这里的模板有一个缺省值,是deque,他也是一个容器,
//通过查询我们发现他的接口比起vector跟list来说多了一个头插头删,更加的全能
class stack
//相当于对vector进行了一个简单的封装
{
public:
void push(const T&x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
T& top()
{
return _con.back();
}
T& top()const
{
_con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
//vector<T> _con;
Container _con;//不需要知道container是谁,只需要知道他是一个容器
//这里就是container(转接器)的意义,只用vector的话他就是顺序栈。但是链表栈也是存在的,所以底层也可以给一个容器,
//给哪个就用哪个
};
void test_stack1()
{
//lrx::stack<int, vector<int>> st;
lrx::stack<int> st;
st.push(1);
st.push(2);
st.push(3);
st.push(4);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
}
}
2. queue的介绍和使用
2.1 queue的介绍
queue的文档介绍 翻译:
1. 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端 提取元素。
2. 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的 成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3. 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操 作: empty:检测队列是否为空 size:返回队列中有效元素的个数 front:返回队头元素的引用 back:返回队尾元素的引用 push_back:在队列尾部入队列 pop_front:在队列头部出队列
4. 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标 准容器deque。

queue 的使用
https://cplusplus.com/reference/queue/queue/

#pragma once
#include<iostream>
#include<deque>
using namespace std;
namespace lrx
{
template<class T,class Container=deque<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
T& back()const
{
return _con.back();
}
T& front()
{
return _con.front();
}
bool empty()const
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
private:
Container _con;
};
void test_queue1()
{
lrx::queue<int> q1;
q1.push(1);
q1.push(2);
q1.push(3);
q1.push(4);
while (!q1.empty())
{
cout << q1.front() << " ";
q1.pop();
}
cout << endl;
}
}deque:

https://cplusplus.com/reference/deque/deque/




deque真正适合的场景:尾插尾删多,任意的访问就得用vector,任意位置要插入删除,中间位置也要,就得用list,deque适合头尾的插入删除,相比vector和list而言,vector每次头插都要挪动空间,list每次都要创造一个新节点,缓存利用率高,所以deque很适合做stack和deque的默认适配容器,如果是中间插入删除,直接用list,随机访问多就用vector;
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总 结),该种模式是将一个类的接口转换成客户希望的另外一个接口;
priority_queue的介绍和使用:
https://cplusplus.com/reference/queue/priority_queue/
1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元 素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特 定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
4. 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭 代器访问,并支持以下操作:
empty():检测容器是否为空
size():返回容器中有效元素个数
front():返回容器中第一个元素的引用
push_back():在容器尾部插入元素
pop_back():删除容器尾部元素
优先级队列的模拟实现:
再模拟实现之前,我们要引入仿函数的观点:
如果没用仿函数的引用进去,实现的优先级队列如下所示(举大堆的例子)
#pragma once
#include<iostream>
#include<vector>
using namespace std;
namespace lrx
{
//大堆(我们如果想建小堆总不能进函数里来通过改变函数的结果来完成目的,失去了封装性的意义,应该再提供一个接口(仿函数))
template<class T,class Container=vector<T>>
class priority_queue
{
public:
priority_queue()//这里写构造函数的原因是:迭代器区间的构造也算是函数的构造
//类和对象中我们了解到,如果一旦我们写了函数的构造函数,则不会生成构造函数,使用自己写的
//这里差了一个空的构造函数,我们自己补上,后面就会调用_con对应的构造函数
{}
template<class InputIterator>
//迭代器区间的构造
priority_queue(InputIterator first, InputIterator last)
{
while (first != last)
{
_con.push_back(*first);
++first;
}
//建堆(向下建堆)
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(i);
}
}
void AdjustUp(size_t child)
{
size_t parent = (child - 1) / 2;
while (child>=0)//最坏的情况就是调整树的高度次数,logN
{
if (_con[child] > _con[parent])
{
std::swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}//插入就可以看的出是一个logN的时间复杂度
void push(const T&x)//向上调整
{
_con.push_back(x);
AdjustUp(_con.size()-1);
}
//向下调整最多也是高度次logN
void AdjustDown(size_t parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())//找左右孩子大的那一个,先找左孩子,<size:是因为堆空间上看是一个数组,如果找完数组都没有找到则不存在
{
//选出左右孩子更大的那一个
if (child + 1 < _con.size()&&_con[child+1>_con[child]])//找左右孩子更大的那一个,右孩子可能不存在,左孩子存在右孩子不一定存在
//且如果右孩子大于左孩子
{
++child;
}//这一段逻辑是默认是指向左孩子的,如果右孩子大于左孩子指向右孩子,如果是小于就指向左孩子
if (_con[child] > _con[parent])
{
std::swap(_con[child], _con[parent]);
//向下走:
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
const T& top()
{
return _con[0];
}
}
//删除可以看出也是个logN的算法
void pop()//向下调整
{
//逻辑上是一个二叉树,物理上是一个数组,不能像vector一样挪动删除,而应该堆顶跟最后一个数据交换,之后尾删
//这时候左子树依旧是小堆,右子树也是小堆,之后向下排序一下就行。
std::swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown();
}
const T& top()
{
return _con[0];
}
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
private:
Container _con;
};
void prioriy_queue_test1()
{
priority_queue<int> pq;
pq.push(3);
pq.push(4);
pq.push(6);
pq.push(2);
pq.push(8);
pq.push(0);
pq.push(7);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
}
}这里我们提出如果想建立小堆,不可能把函数里面的建堆接口的大小于号,c++仿函数就是用来解决这个问题的
仿函数:
//仿函数,也叫函数对象,其实是一个类,这个类重载了operator(),
namespace lrx
{
struct less//写一个比较大小的(小于的)
{
bool operator()(const int& l, const int& r)const//参数取决于要干什么,比较大小的话就给两个变量
{
return l < r;
}
};
}
int main()
{
lrx::less lsFunc;
cout << lsFunc(1, 2) << endl;
//这里的lsFunc是一个类对象可以像函数一样去使用
//本质上是lsFunc.operator()(1,2)
return 0;
}
经过仿函数的改造之后我们发现我们可以跟STL库里面的优先级队列一样控制参数从而达到建大堆还是小堆;
下面是代码实现:
#pragma once
#include<iostream>
#include<vector>
using namespace std;
namespace lrx
{
//大堆(我们如果想建小堆总不能进函数里来通过改变函数的结果来完成目的,失去了封装性的意义,应该再提供一个接口(仿函数))
//Compare 进行比较的仿函数,less是大堆,greater是小堆
template<class T, class Container = vector<T>, class Compare=std::less<T> >
class priority_queue
{
public:
priority_queue()
{}
template<class InputIterator>
//迭代器区间的构造
priority_queue(InputIterator first, InputIterator last)
{
while (first != last)
{
_con.push_back(*first);
++first;
}
//建堆(向下建堆)
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(i);
}
}
void AdjustUp(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child>0)//最坏的情况就是调整树的高度次数,logN
{
//if (_con[child] > _con[parent])
//if(_con[parent]<_con[child])//用小于实现大堆
if(com(_con[parent],_con[child]))
{
std::swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}//插入就可以看的出是一个logN的时间复杂度
void push(const T&x)//向上调整
{
_con.push_back(x);
AdjustUp(_con.size()-1);
}
//向下调整最多也是高度次logN
void AdjustDown(size_t parent)
{
Compare com;
size_t child = parent * 2 + 1;
while (child < _con.size())//找左右孩子大的那一个,先找左孩子,<size:是因为堆空间上看是一个数组,如果找完数组都没有找到则不存在
{
//选出左右孩子更大的那一个
//if (child + 1 < _con.size()&&_con[child+1>]_con[child])//找左右孩子更大的那一个,右孩子可能不存在,左孩子存在右孩子不一定存在
//且如果右孩子大于左孩子
//if(_chlid+1<_con.size()&&_con[child]<_con[child+1])
if(child+1<_con.size() && com(_con[child], _con[child + 1]))
{
++child;
}
//这一段逻辑是默认是指向左孩子的,如果右孩子大于左孩子指向右孩子,如果是小于就指向左孩子
//if (_con[child] > _con[parent])
//if(_con[parent]<_con[child])
if(com(_con[parent],_con[child]))
{
std::swap(_con[child], _con[parent]);
//向下走:
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//删除可以看出也是个logN的算法
void pop()//向下调整
{
//逻辑上是一个二叉树,物理上是一个数组,不能像vector一样挪动删除,而应该堆顶跟最后一个数据交换,之后尾删
//这时候左子树依旧是小堆,右子树也是小堆,之后向下排序一下就行。
std::swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}
const T& top()
{
return _con[0];
}
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
private:
Container _con;
};
void prioriy_queue_test1()
{
priority_queue<int> pq;
pq.push(3);
pq.push(4);
pq.push(6);
pq.push(2);
pq.push(8);
pq.push(0);
pq.push(7);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
}
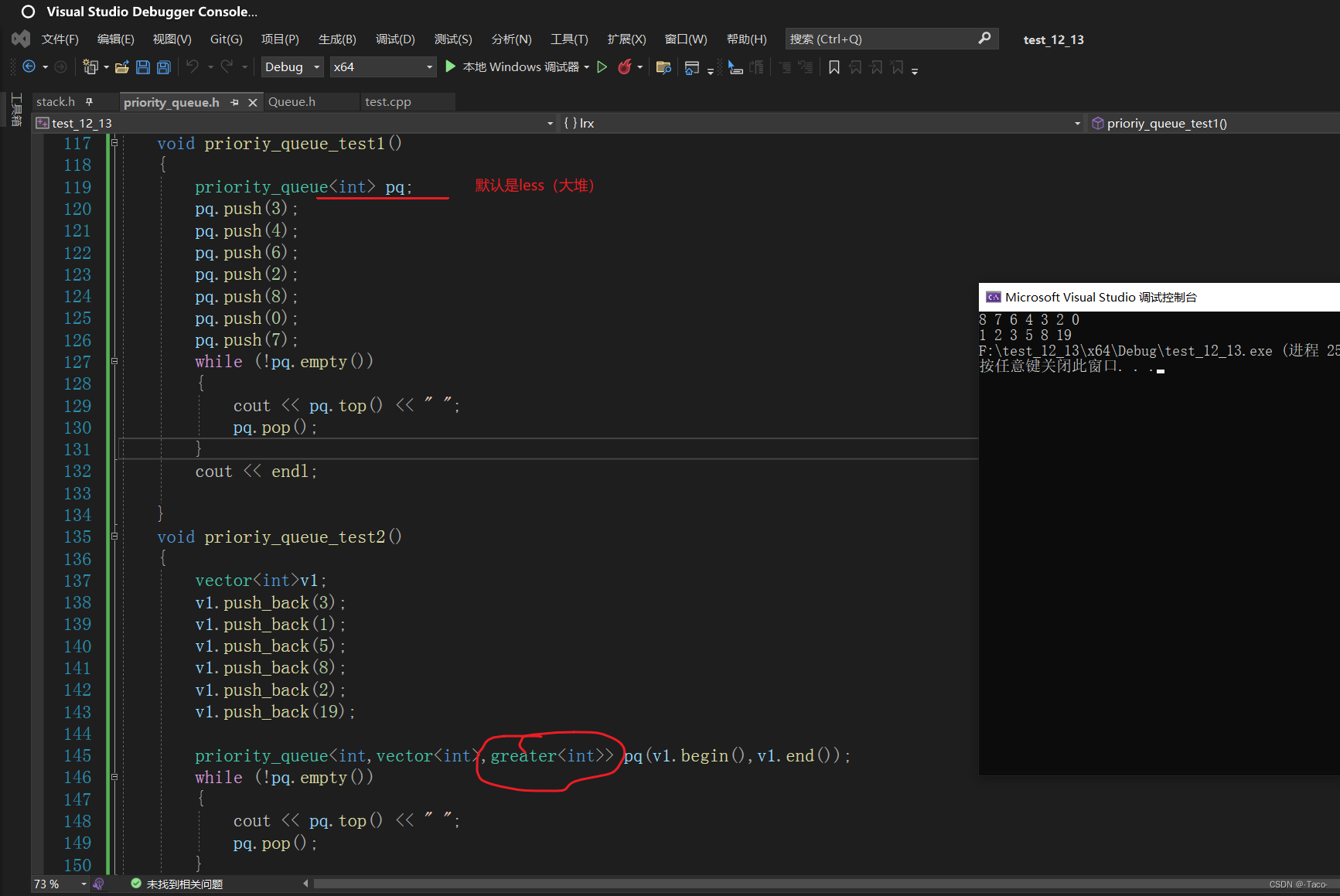
void prioriy_queue_test2()
{
vector<int>v1;
v1.push_back(3);
v1.push_back(1);
v1.push_back(5);
v1.push_back(8);
v1.push_back(2);
v1.push_back(19);
priority_queue<int,vector<int>,greater<int>> pq(v1.begin(),v1.end());
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
}
}仿函数默认是库里面的less(大堆),这里的less跟greater有一点反人类,正好对应相反的堆;
改造函数的过程:
先在模板处增加一个class Compare=std::less<T> ,之后再每个建堆的adjust里面创建com对象
先把if整体的格式变成默认的小于号建大堆(这样做符合库里面less表示大堆的过程),之后将com写成仿函数的方式,将大小比较的两个作为参数传入,即改造完成。这么是泛型编程的经典实现,通过控制com来控制大堆还是小堆。