1、原论文数据双标图
代码:
setwd("D:/Desktop/0000/R") #更改路径
#导入数据
df <- read.table("Input data.csv", header = T, sep = ",")
# -----------------------------------
#所需的包:
packages <- c("ggplot2", "tidyr", "dplyr", "readr", "ggrepel", "cowplot", "factoextra")
#安装你尚未安装的R包
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {
install.packages(packages[!installed_packages])
}
invisible(lapply(packages, library, character.only = TRUE))
# -----------------------------------
# 设置一些颜色、文字的基础设置
# Colors:
CatCol <- c(
CSH = "#586158", DBF = "#C46B39", EBF = "#4DD8C0", ENF = "#3885AB", GRA = "#9C4DC4",
MF = "#C4AA4D", OSH = "#443396", SAV = "#CC99CC", WET = "#88C44D", WSA = "#AB3232"
)
Three_colorblind <- c("#A8AD6F", "#AD6FA8", "#6FA8AD") #c("#809844", "#4f85b0", "#b07495")
graph_elements_dark <- "black"
plot_elements_light <- "gray75"
plot_elements_dark <- "gray25"
# Transparency:
boot_alpha_main <- 0.9
boot_alpha_small <- 0.05
# Text:
# if (n_pcs > 3) {x_angle <- 270; x_adjust <- 0.25} else {x_angle <- 0; x_adjust <- 0} # option to change orientation of x axis text
x_angle <- 0; x_adjust <- 0
title_text <- 9 # Nature Communications: max 7 pt; cowplot multiplier: 1/1.618; 7 pt : 1/1.618 = x pt : 1; x = 7 / 1/1.618; x = 11.326 (round up to integer)
subtitle_text <- 9
normal_text <- 9 # Nature Communications: min 5 pt; cowplot multiplier: 1/1.618; 5 pt : 1/1.618 = x pt : 1; x = 5 / 1/1.618; x = 8.09 (round up to integer)
# Element dimensions:
plot_linewidth <- 0.33
point_shape <- 18
point_size <- 1.5
# Initialize figure lists:
p_biplot <- list(); p_r2 <- list(); p_load <- list(); p_contr <- list(); col_ii <- list()
# Labels:
veg_sub_labels <- c("All Sites", "All Forests", "Evergreen Needle-Forests")
# -----------------------------------
#选择PCA所需的数据
codes_4_PCA <- c("SITE_ID", "IGBP", "GPPsat", "wLL", "wNmass", "wLMA", "RECOmax") # 选择需要的列数据
#执行筛选
df_subset <- df %>%
dplyr::select(all_of(codes_4_PCA))
#运行PCA。dplyr::select(-species):将不需要的列数据去除
pca_result <- FactoMineR::PCA(df_subset %>% dplyr::select(-SITE_ID, -IGBP), scale.unit = T, ncp = 10, graph = F)
# -----------------------------------
#绘图
p1<- fviz_pca_biplot(pca_result,
axes = c(1, 2),
col.ind = df_subset$IGBP, #"grey50",
# col.ind = NA, #plot_elements_light, #"white",
geom.ind = "point",
palette = CatCol,#'futurama',
label = "var",
col.var = plot_elements_dark,
labelsize = 3,
repel = TRUE,
pointshape = 16,
pointsize = 2,
alpha.ind = 0.67,
arrowsize = 0.5)
# -----------------------------------
# 它是ggplot2对象,我们在此基础上进一步修改一下标注。
p1<-p1+
labs(title = "",
x = "PC1",
y = "PC2",
fill = "IGBP") +
guides(fill = guide_legend(title = "")) +
theme(title = element_blank(),
text = element_text(size = normal_text),
axis.line = element_blank(),
axis.ticks = element_blank(),
axis.title = element_text(size = title_text, face = "bold"),
axis.text = element_text(size = normal_text),
#plot.margin = unit(c(0, 0, 0, 0), "cm"),
# legend.position = "none"
legend.text = element_text(size = subtitle_text),
legend.key.height = unit(5, "mm"),
legend.key.width = unit(2, "mm")
)
p1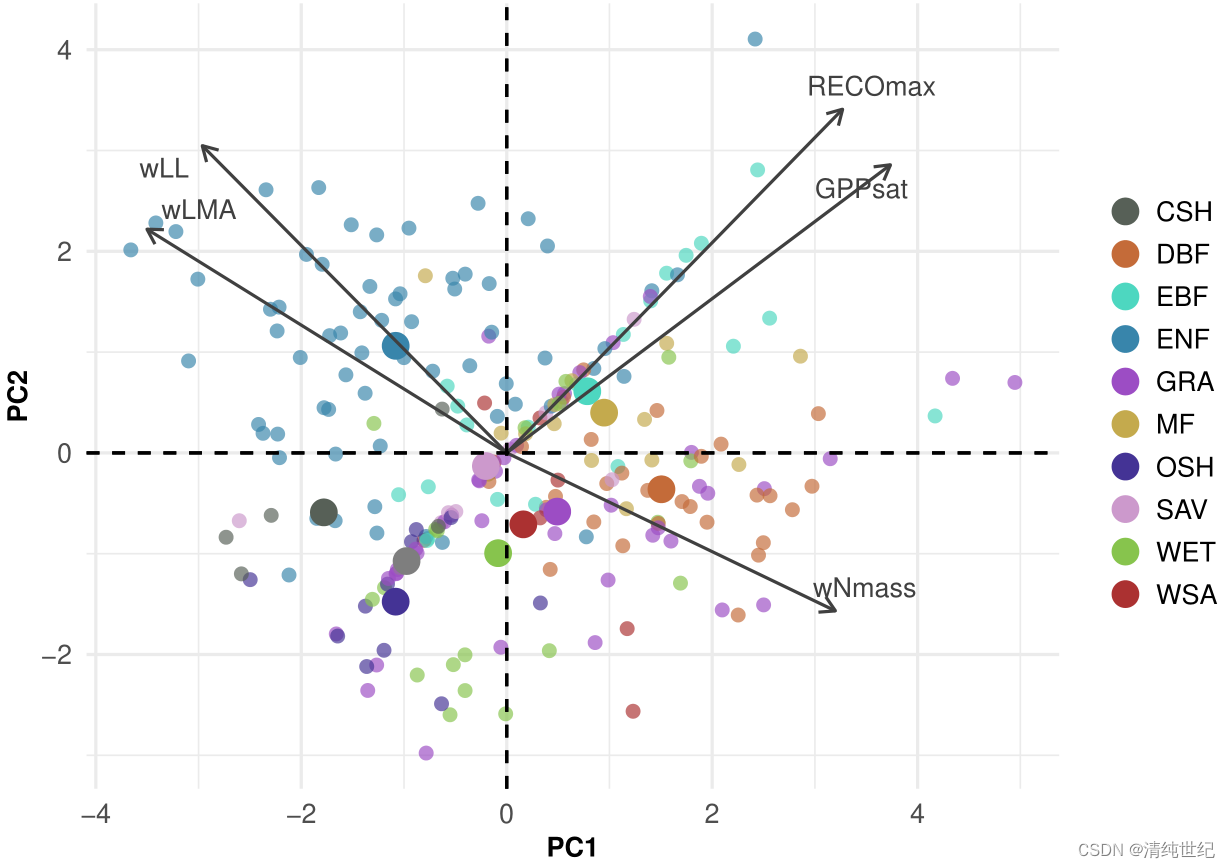
参考:Leaf-level coordination principles propagate to the ecosystem scale (https://doi.org/10.1038/s41467-023-39572-5)、主成分分析图。
2、我选用iris数据进行重新绘制测试双标图
代码:
setwd("D:/Desktop/0000/R") #更改路径
#导入数据
df <- read.table("iris1.csv", header = T, sep = ",")
# -----------------------------------
#所需的包:
packages <- c("ggplot2", "tidyr", "dplyr", "readr", "ggrepel", "cowplot", "factoextra")
#安装你尚未安装的R包
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {
install.packages(packages[!installed_packages])
}
invisible(lapply(packages, library, character.only = TRUE))
# -----------------------------------
# 设置一些颜色、文字的基础设置
# Colors:
CatCol <- c(
setosa = "#586158", versicolor = "#C46B39", virginica = "#4DD8C0") # 设置类别颜色
Three_colorblind <- c("#A8AD6F", "#AD6FA8", "#6FA8AD") #c("#809844", "#4f85b0", "#b07495")
graph_elements_dark <- "black"
plot_elements_light <- "gray75"
plot_elements_dark <- "gray25"
# Transparency:
boot_alpha_main <- 0.9
boot_alpha_small <- 0.05
# Text:
# if (n_pcs > 3) {x_angle <- 270; x_adjust <- 0.25} else {x_angle <- 0; x_adjust <- 0} # option to change orientation of x axis text
x_angle <- 0; x_adjust <- 0
title_text <- 9 # Nature Communications: max 7 pt; cowplot multiplier: 1/1.618; 7 pt : 1/1.618 = x pt : 1; x = 7 / 1/1.618; x = 11.326 (round up to integer)
subtitle_text <- 9
normal_text <- 9 # Nature Communications: min 5 pt; cowplot multiplier: 1/1.618; 5 pt : 1/1.618 = x pt : 1; x = 5 / 1/1.618; x = 8.09 (round up to integer)
# Element dimensions:
plot_linewidth <- 0.33
point_shape <- 18
point_size <- 1.5
# Initialize figure lists:
p_biplot <- list(); p_r2 <- list(); p_load <- list(); p_contr <- list(); col_ii <- list()
# Labels:
veg_sub_labels <- c("All Sites", "All Forests", "Evergreen Needle-Forests")
# -----------------------------------
#选择PCA所需的数据
codes_4_PCA <- c("sepal_length", "sepal_width", "petal_length", "petal_width", "species") # 选择需要的列数据
#执行筛选
df_subset <- df %>%
dplyr::select(all_of(codes_4_PCA))
#运行PCA。dplyr::select(-species):将不需要的列数据去除
pca_result <- FactoMineR::PCA(df_subset %>% dplyr::select(-species), scale.unit = T, ncp = 10, graph = F)
# -----------------------------------
#绘图
p1<- fviz_pca_biplot(pca_result,
axes = c(1, 2),
col.ind = df_subset$species, #"grey50",
# col.ind = NA, #plot_elements_light, #"white",
geom.ind = "point",
palette = CatCol,#'futurama',
label = "var",
col.var = plot_elements_dark,
labelsize = 3,
repel = TRUE,
pointshape = 16,
pointsize = 2,
alpha.ind = 0.67,
arrowsize = 0.5)
# -----------------------------------
# 它是ggplot2对象,我们在此基础上修改一下标注。
p1<-p1+
labs(title = "",
x = "PC1",
y = "PC2",
fill = "IGBP") +
guides(fill = guide_legend(title = "")) +
theme(title = element_blank(),
text = element_text(size = normal_text),
axis.line = element_blank(),
axis.ticks = element_blank(),
axis.title = element_text(size = title_text, face = "bold"),
axis.text = element_text(size = normal_text),
#plot.margin = unit(c(0, 0, 0, 0), "cm"),
# legend.position = "none"
legend.text = element_text(size = subtitle_text),
legend.key.height = unit(5, "mm"),
legend.key.width = unit(2, "mm")
)
p1
3、iris数据进行绘制碎石图、变量载荷图、变量贡献图
代码:
#加载包
library(dplyr) #用于数据预处理
library(tidyr) #用于数据预处理
library(stringr) #用于字符串处理
library(modelr) #用于自助法重抽样
library(FactoMineR) #用于PCA
library(ade4) #用于PCA
library(factoextra) #用于PCA结果提取及绘图
#所需的包:
packages <- c("ggplot2", "tidyr", "dplyr", "readr", "ggrepel", "cowplot", "factoextra")
#安装你尚未安装的R包
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {
install.packages(packages[!installed_packages])
}
invisible(lapply(packages, library, character.only = TRUE))
setwd("D:/Desktop/0000/R") #更改路径
# 加载数据
df <- read.csv("iris.csv",header = T, row.names = 1) # row.names = 1: 第一列为标签,这时赋值给df时就没有这列了
#重抽样
set.seed(123) #设置随机种子
tt=99 #设置重抽样的次数。iris[,-5]:表示去除第5列,因为这是类别
df_boot <- iris[,-5] %>% modelr::bootstrap(n = tt) #重抽样,结果是一个列表,包含499个数据框
#使用循环对每一个数据集进行PCA
#初始化3个空变量
N_PCS <- tibble() #使用维数检验保留的PC数量
pca_stats <- tibble() #变量的贡献和载荷
R2 <- c() #解释方差占比
#使用循环对每一个数据集进行PCA
#初始化3个空变量
N_PCS <- tibble() #使用维数检验保留的PC数量
pca_stats <- tibble() #变量的贡献和载荷
R2 <- c() #解释方差占比
#循环
for (j in 1:tt) {
##提取第j次bootstrap的数据
dat <- df_boot %>%
slice(j) %>% # 选择第j行
pull(strap) %>% # 提取列表
as.data.frame() # 提取数据集
#使用FactoMineR包执行PCA
pca_result <- FactoMineR::PCA(dat, scale.unit = T, ncp = 4, graph = F) # ncp = 4:降维几个主成分,设置最大即为全部
#使用ade4包执行PCA
# center:指定是否对数据进行中心化,默认为 TRUE。中心化意味着将数据减去各自的均值,使得数据在每个维度上的平均值为零。
# scale:指定是否对数据进行缩放,默认为 TRUE。缩放意味着将数据除以各自的标准差,使得数据在每个维度上的标准差为一。
# scannf:指定是否计算特征值和特征向量,默认为 FALSE。如果设置为 TRUE,则会计算特征值和特征向量。
pca1 <- ade4::dudi.pca(dat, center = TRUE, scale = TRUE, scannf = FALSE, nf = 4) # nf= 4:降维几个主成分,设置最大即为全部
#检测不确定性和显著性
#执行维数检验
pc_tested <-testdim(pca1, nrepet = 999)
###提取bootstrap数据集的PCA结果
N_PCS <- N_PCS %>%
bind_rows(tibble(strap = j, n_pcs = pc_tested$nb.cor)) #第j次运行的PCA
pca_stats <- bind_rows(pca_stats,
pca_result$var$contrib %>% # add contributions
as_tibble(rownames = "var") %>%
pivot_longer(cols = !var, names_to = "PC", values_to = "contrib") %>%
left_join(pca_result$var$coord %>% # add loadings
as_tibble(rownames = "var") %>%
pivot_longer(cols = !var, names_to = "PC", values_to = "loading"),
by = c("var", "PC")
) %>%
mutate(PC = str_sub(PC, start = 5), #提取PC名称中的数字
strap = j) # bootstrap run number
) #得到变量贡献和载荷
R2 <- bind_rows(R2,
tibble(PC = pca_result[["eig"]]%>% rownames(),
exp_var = pca_result[["eig"]][,2],
strap = j) %>%
mutate(PC = str_sub(PC, start = 6)) #提取PC名称中的数字
)
}
#保留的PC数量
N_PCS <- N_PCS %>%
group_by(n_pcs) %>%
summarise(n_rep = n()) %>% #对重复值进行计数
mutate(retained = n_rep / tt * 100) #计算运行次数百分比
pc_ret <- N_PCS %>% filter(retained == max(retained))
#输出结果的摘要
print(paste0("Number of statistical significant components according to Dray method (Dray et al., 2008) was ",pc_ret[1,1], " in ", round(pc_ret[1,3], digits = 1), "% of runs."))
n_pcs <- NA #保留PC数的初始设置
# n_pcs <- 2 #可以手动设置保留PC数
if (is.na(n_pcs)) {
n_pcs <- N_PCS %>%
filter(retained == max(retained)) %>%
select(n_pcs) %>%
unlist() %>% unname()
} #按照Dray等人的方法设置保留PC数
##变量贡献和载荷
pca_stats <- pca_stats %>%
group_by(PC, var) %>%
mutate(
contrib_mean = mean(contrib),
contrib_median = median(contrib),
contrib_std = sd(contrib),
# contrib_q25 = quantile(contrib, 0.25), contrib_q75 = quantile(contrib, 0.75),
loading_mean = mean(loading),
loading_median = median(loading),
loading_std = sd(loading),
# loading_q25 = quantile(loading, 0.25), loading_q75 = quantile(loading, 0.75)
) %>%
ungroup() %>%
dplyr::rename(contrib_boot = contrib, loading_boot = loading) #重命名以免后续的匹配过程出现混乱
##修改PC名称
pca_stats <- pca_stats %>%
mutate(PC_name = paste0("PC", PC))
##解释方差占比
R2 <- R2 %>%
group_by(PC) %>%
mutate(
R2_mean = mean(exp_var),
R2_median = median(exp_var),
R2_std = sd(exp_var),
# R2_q25 = quantile(exp_var, 0.25), R2_q75 = quantile(exp_var, 0.75)
) %>%
ungroup() %>%
dplyr::rename(R2_boot = exp_var) #重命名以免后续的匹配过程出现混乱
##添加到pca_stats的表格中
pca_stats <- pca_stats %>% left_join(R2, by = c("PC", "strap"))
#对原始数据的PCA
pca_result <- FactoMineR::PCA(iris[,-5], scale.unit = T, ncp = 4, graph = F)
#添加原始数据计算得到的实际值
pca_stats <- pca_stats %>%
dplyr::left_join( #添加原始数据的R2(不是bootstrapping的均值)
tibble(PC = pca_result[["eig"]] %>% rownames(),
R2 = pca_result[["eig"]][,2]
) %>%
mutate(PC = str_sub(PC, start = 6)), #提取PC数
by = "PC"
) %>%
dplyr::left_join( #添加原始数据的变量贡献(不是bootstrapping的均值)
pca_result$var$contrib %>% #添加贡献
as_tibble(rownames = "var") %>%
pivot_longer(cols = !var, names_to = "PC", values_to = "contrib") %>%
mutate(PC = str_sub(PC, start = 5)), #提取PC数
by = c("PC", "var")
) %>%
dplyr::left_join( #添加原始数据的变量载荷(不是bootstrapping的均值)
pca_result$var$coord %>% #添加载荷
as_tibble(rownames = "var") %>%
pivot_longer(cols = !var, names_to = "PC", values_to = "loading") %>%
mutate(PC = str_sub(PC, start = 5)), # extract PC numbers
by = c("PC", "var")
)
## 添加PC数的保留百分比(在自助法中PC被保留得有多频繁)
pca_stats <- pca_stats %>%
dplyr::left_join(N_PCS %>% dplyr::mutate(PC = n_pcs %>% as.character) %>% dplyr::select(PC, retained),
by = "PC"
)
# -----------------------------------
# 绘制图碎石图
dat_boot <- pca_stats %>%
dplyr::select(PC_name, PC, R2_boot) %>% unique()%>% #去除重复
dplyr::mutate(PC = as.character(PC))
dat_true <- pca_stats %>%
dplyr::select(PC_name, PC, R2, R2_median, R2_std) %>% unique() %>% #去除重复
dplyr::mutate(PC = as.character(PC))
p2 <- ggplot(data = dat_true, aes(x = PC_name, y = R2, group = 1)) + # x = PC -> only numbers on axis, x = PC_name -> can give problems with PC10 being ordered before PC2;
# group 1 是用来避免某些warning/error的
geom_errorbar(aes(ymin = R2 - R2_std, ymax = R2 + R2_std),
color = Three_colorblind[1], linewidth = plot_linewidth, width = 0.4) + # bootstrapping的标准差
# geom_bar(stat = "identity", position = position_dodge(), fill = Three_colorblind[1], width = 0.61) + #b07a4f, #9c6a5e, #643c3c
geom_line(color = Three_colorblind[1]) +
geom_point(color = Three_colorblind[1], size = point_size) + #实际值
geom_jitter(data = dat_boot, aes(x = PC_name, y = R2_boot, group = 1), alpha = 0.1,
color = "black", shape = point_shape, size = 0.5, width = 0.1) + #每次自助样本的值
geom_point(aes(x = PC_name, y = R2_median), color = plot_elements_dark,
alpha = boot_alpha_main, shape = point_shape, size = point_size) + #添加自助法得到的中位数值
geom_text(aes(x = PC_name, y = R2 + R2_std + 2, label = paste0(R2 %>% round(digits = 1), "%")),
nudge_x = 0.33, size = 2) + #添加数值标注
labs(title = "", x = "", y = "Explained variance") +
theme_classic() +
theme(title = element_blank(),
text = element_text(size = normal_text),
axis.line = element_line(color = graph_elements_dark),
axis.ticks.x = element_line(color = graph_elements_dark),
axis.ticks.y = element_blank(),
axis.title = element_text(size = title_text, face = "bold"),
# axis.title.x = element_blank(), #已经在'labs'中指定
axis.text = element_text(size = normal_text),
axis.text.y = element_blank(),
plot.margin = unit(c(0, 1, 0, 1), "cm"),
legend.position = "none"
) +
NULL
p2
# -----------------------------------
# 绘制变量载荷图
dat_boot <- pca_stats %>%
dplyr::filter(PC <= n_pcs[1]) %>% #去除额外的PC
dplyr::select(PC_name, var, loading_boot) %>% unique() #去除重复
dat_true <- pca_stats %>%
dplyr::filter(PC <= n_pcs[1]) %>% #去除额外的PC
dplyr::select(PC_name, var, loading, loading_median, loading_std) %>% unique() #去除重复
p3 <- ggplot(data = dat_true, aes(x = var, y = loading)) +
facet_grid(. ~ PC_name, scales = "free_y") +
geom_errorbar(aes(ymin = loading - loading_std, ymax = loading + loading_std), # loading_q25, ymax = loading_q75
color = Three_colorblind[2], linewidth = plot_linewidth, width = 0.9) + # standard error = std from bootstrapping
geom_bar(stat = "identity", position = position_dodge(), fill = Three_colorblind[2]) + #b07a4f, #9c6a5e, #643c3c
geom_hline(yintercept = 0, color = graph_elements_dark) +
geom_jitter(data = dat_boot, aes(x = var, y = loading_boot), alpha = boot_alpha_small, color = plot_elements_dark,
shape = point_shape, size = 0.2, width = 0.1) + #每次自助抽样的值
geom_point(aes(x = var, y = loading_median), alpha = boot_alpha_main, shape = point_shape,
size = point_size, color = plot_elements_dark) + #添加自助法得到的中位数值
coord_flip() + #对调坐标轴以更好地展示图形
scale_y_continuous(breaks = waiver(), n.breaks = 4) + #修改x轴(对调后,这就是y轴)
labs(y = "Loadings", x = "", title = "") +
theme_classic() +
theme(title = element_text(size = normal_text, face = "bold"),
text = element_text(size = normal_text),
axis.line.x = element_line(color = graph_elements_dark),
axis.line.y = element_blank(),
axis.ticks.x = element_line(color = graph_elements_dark),
axis.ticks.y = element_blank(),
axis.title = element_text(size = title_text),
axis.text = element_text(size = normal_text),
axis.text.x = element_text(angle = x_angle, vjust = x_adjust),
legend.position = "none",
legend.title = element_text(size = title_text),
legend.text = element_text(size = subtitle_text),
legend.key.height = unit(1.0, "mm"),
legend.key.width = unit(1.0, "mm"),
plot.margin = unit(c(0, 0, 0, 0), "cm"),
strip.text = element_text(face = "bold", size = title_text),
strip.background = element_blank()
) +
NULL
p3
# -----------------------------------
# 绘制变量贡献图
dat_boot <- pca_stats %>%
dplyr::filter(PC <= n_pcs[1]) %>% #去除额外的PC
dplyr::select(PC_name, var, contrib_boot) %>% unique() #去除重复
dat_true <- pca_stats %>%
dplyr::filter(PC <= n_pcs[1]) %>% # remove additional PCs
dplyr::select(PC_name, var, contrib, contrib_median, contrib_std) %>% unique() #去除重复
p4<- ggplot(data = dat_true, aes(x = var, y = contrib)) +
facet_grid(. ~ PC_name, scales = "free_y") +
geom_errorbar(aes(ymin = contrib_median - contrib_std, ymax = contrib_median + contrib_std), # ymin = contrib_q25, ymax = contrib_q75
color = Three_colorblind[3], linewidth = plot_linewidth, width = 0.9) + # standard error = standard deviation from bootstrapping
geom_bar(stat = "identity", position = position_dodge(), fill = Three_colorblind[3]) + #4f85b0, #59918e, #3c6464
geom_hline(yintercept = 0, color = graph_elements_dark) +
geom_jitter(data = dat_boot, aes(x = var, y = contrib_boot), alpha = boot_alpha_small, color = plot_elements_dark,
shape = point_shape, size = 0.2, width = 0.1) + #每次自助抽样的值
geom_point(aes(x = var, y = contrib_median), alpha = boot_alpha_main, shape = point_shape,
size = point_size, color = plot_elements_dark) + #添加自助法得到的中位数值
coord_flip() + #对调坐标轴以更好地展示图形
scale_y_continuous(breaks = waiver(), n.breaks = 4) + #添加自助法得到的中位数值
labs(y = "Contribution [%]", x = "", title = "") +
theme_classic() +
theme(title = element_text(size = normal_text, face = "bold"),
text = element_text(size = normal_text),
axis.line.x = element_line(color = graph_elements_dark),
axis.line.y = element_blank(),
axis.ticks.x = element_line(color = graph_elements_dark),
axis.ticks.y = element_blank(),
axis.title = element_text(size = title_text),
axis.text = element_text(size = normal_text),
axis.text.x = element_text(angle = x_angle, vjust = x_adjust),
legend.position = "none",
legend.title = element_text(size = title_text),
legend.text = element_text(size = subtitle_text),
legend.key.height = unit(1.0, "mm"),
legend.key.width = unit(1.0, "mm"),
# plot.margin = unit(c(0, 0, 0, 0), "cm"),
strip.text = element_text(face = "bold", size = title_text),
strip.background = element_blank()
) +
NULL
p4
# -----------------------------------
# 拼图
library(patchwork)
p2+p3/p4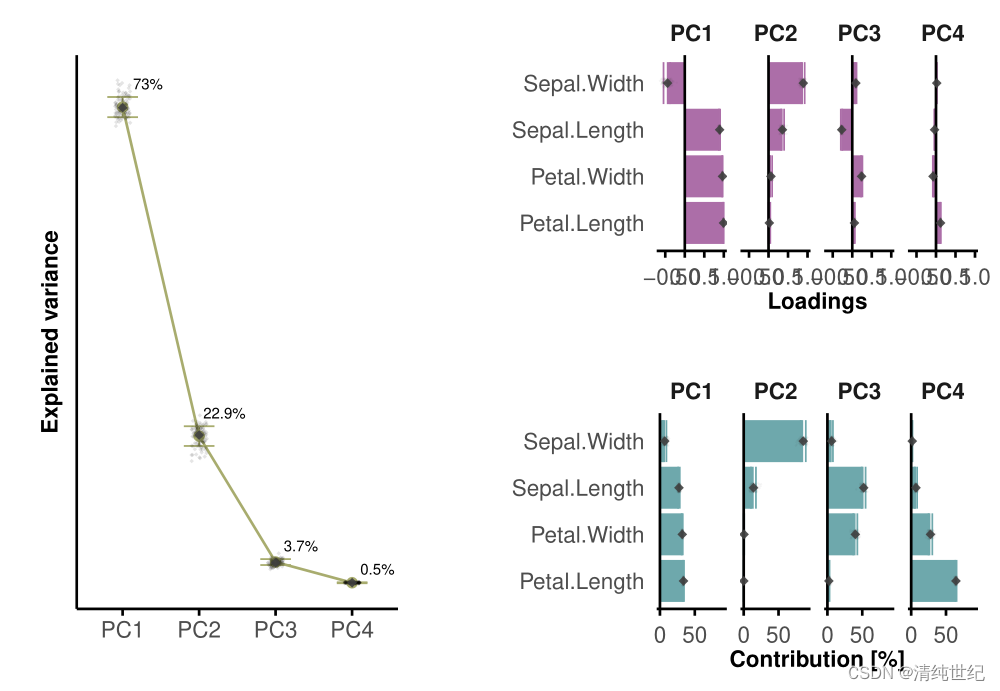
文中用到的数据代码:R语言绘制 PCA 双标图、碎石图、变量载荷图和变量贡献图(self).zip - 蓝奏云


![[JAVEee]SpringBoot项目的创建](https://img-blog.csdnimg.cn/c442331086054eaa95af7505e3ac4422.png)