目录
一、网络结构
二、创新点分析
三、知识点
1. nn.ReLU(inplace)
2. os.getcwd与os.path.abspath
3. 使用torchvision下的datasets包
4. items()与dict()用法
5. json文件
6. tqdm
7. net.train()与net.val()
四、代码
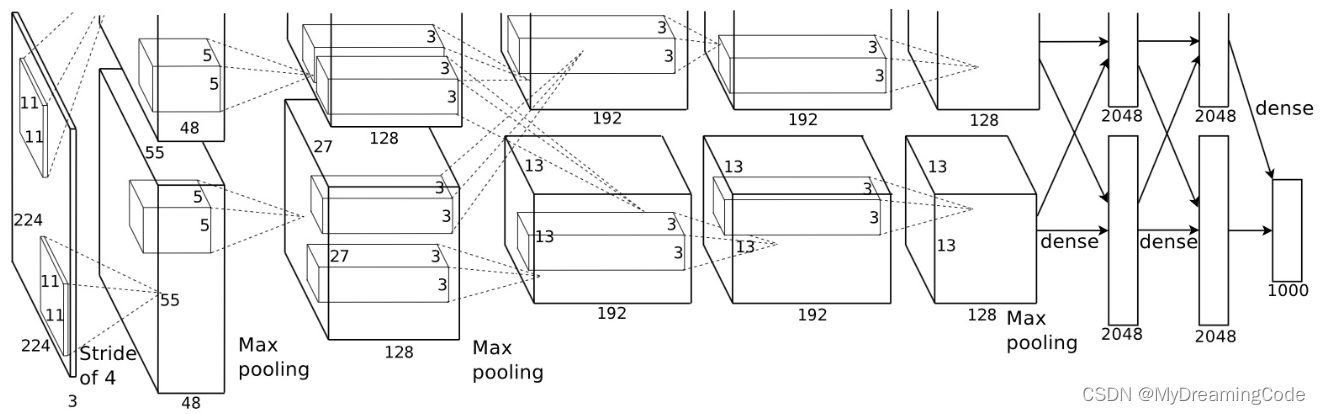
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年ImageNet图像分类竞赛中提出的一种经典的卷积神经网络。AlexNet使用了Dropout层,减少过拟合现象的发生。
一、网络结构
二、数据集
文件存放:
dataset->flower_data->flower_photos
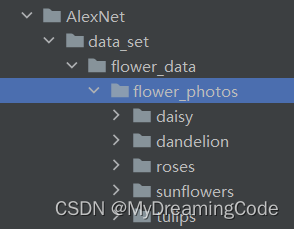
再使用split_data.py 将数据集根据比例划分成训练集和预测集
详细请查看b站up主霹雳吧啦Wz:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/master/pytorch_classification
三、创新点分析
1. deeper网络结构
通过增加网络深度,AlexNet可以更好的学习数据集的特征,并提高分类的准确率。
2. 使用ReLU激活函数,克服梯度消失以及求梯度复杂的问题。
3. 使用LRN局部响应归一化
LRN是在卷积与池化层间添加归一化操作。卷积过程中,每个卷积核都对应一个feature map,LRN对这些feature map进行归一化操作。即,对每个特征图的每个位置,计算该位置周围的像素平方和,然后将当前位置像素值除以这个和。LRN可抑制邻近神经元的响应,在一定程度上能够避免过拟合,提高网络泛化能力。
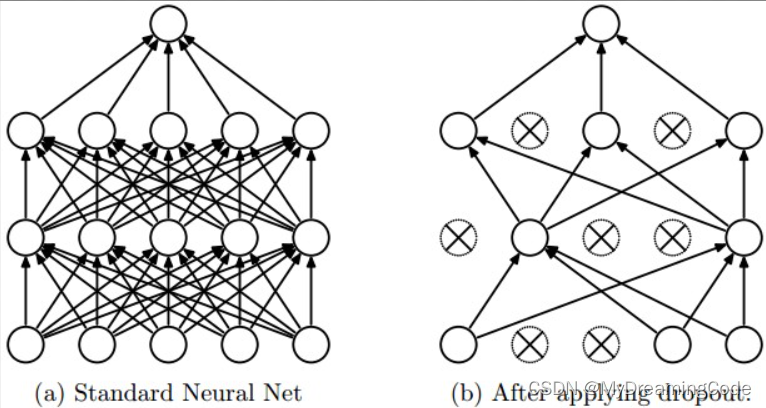
4. 使用Dropout层
Dropout层:在训练过程中随机删除一定比例的神经元,以减少过拟合。Dropout一般放在全连接层与全连接层之间。
四、知识点
1. nn.ReLU(inplace) 默认参数为:inplace=False
inplace=False:不会修改输入对象的值,而是返回一个新创建的对象,即打印出的对象存储地址不同。(值传递)
inplace=True:会修改输入对象的值,即打印的对象存储地址相同,可以节省申请与释放内存的空间与时间。(地址传递)
import torch
import numpy as np
import torch.nn as nn
# id()方法返回对象的内存地址
relu1 = nn.ReLU(inplace=False)
relu2 = nn.ReLU(inplace=True)
data = np.random.randn(2, 4)
input = torch.from_numpy(data) # 转换成tensor类型
print("input address:", id(input))
output1 = relu1(input)
print("replace=False -- output address:", id(output1))
output2 = relu2(input)
print("replace=True -- output address:", id(output2))
# input address: 1669839583200
# replace=False -- output address: 1669817512352
# replace=True -- output address: 1669839583200
2. os.getcwd与os.path.abspath
os.getcwd():获取当前工作目录
os.path.abspath('xxx.py'):获取文件当前的完整路径
import os
print(os.getcwd()) # D:\Code
print(os.path.abspath('test.py')) # D:\Code\test.py
3. 使用torchvision下的datasets包
train_dataset=datasets.ImageFolder(root=os.path.join(image_path,'train'),transform=data_transform['train'])可以得出这些信息:
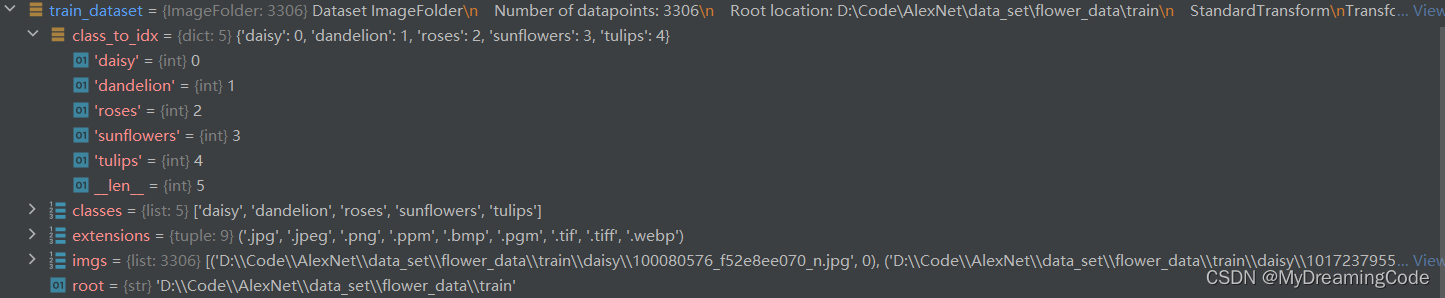
4. items()与dict()用法
items():把字典中的每对key和value组成一个元组,并将这些元组放在列表中返回。
obj = {
'dog': 0,
'cat': 1,
'fish': 2
}
print(obj) # {'dog': 0, 'cat': 1, 'fish': 2}
print(obj.items()) # dict_items([('dog', 0), ('cat', 1), ('fish', 2)])
print(dict((v, k) for k, v in obj.items())) # {0: 'dog', 1: 'cat', 2: 'fish'}5. json文件
(1)json.dumps:将Python对象编码成JSON字符串
(2)json.loads:将已编码的JSON字符串编码为Python对象
import json
data = [1, 2, 3]
data_json = json.dumps(data) # <class 'str'>
data = json.loads(data_json)
print(type(data)) # <class 'list'>6. tqdm
train_bar = tqdm(train_loader, file=sys.stdout)
使用tqdm函数,对train_loader进行迭代,将进度条输出到标准输出流sys.stdout中。可以方便用户查看训练进度。
from tqdm import tqdm
import time
for i in tqdm(range(10)):
time.sleep(0.1)
7. net.train()与net.val()
net.train():启用BatchNormalization和Dropout
net.eval|():不启用BatchNormalization和Dropout
五、代码
model.py
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
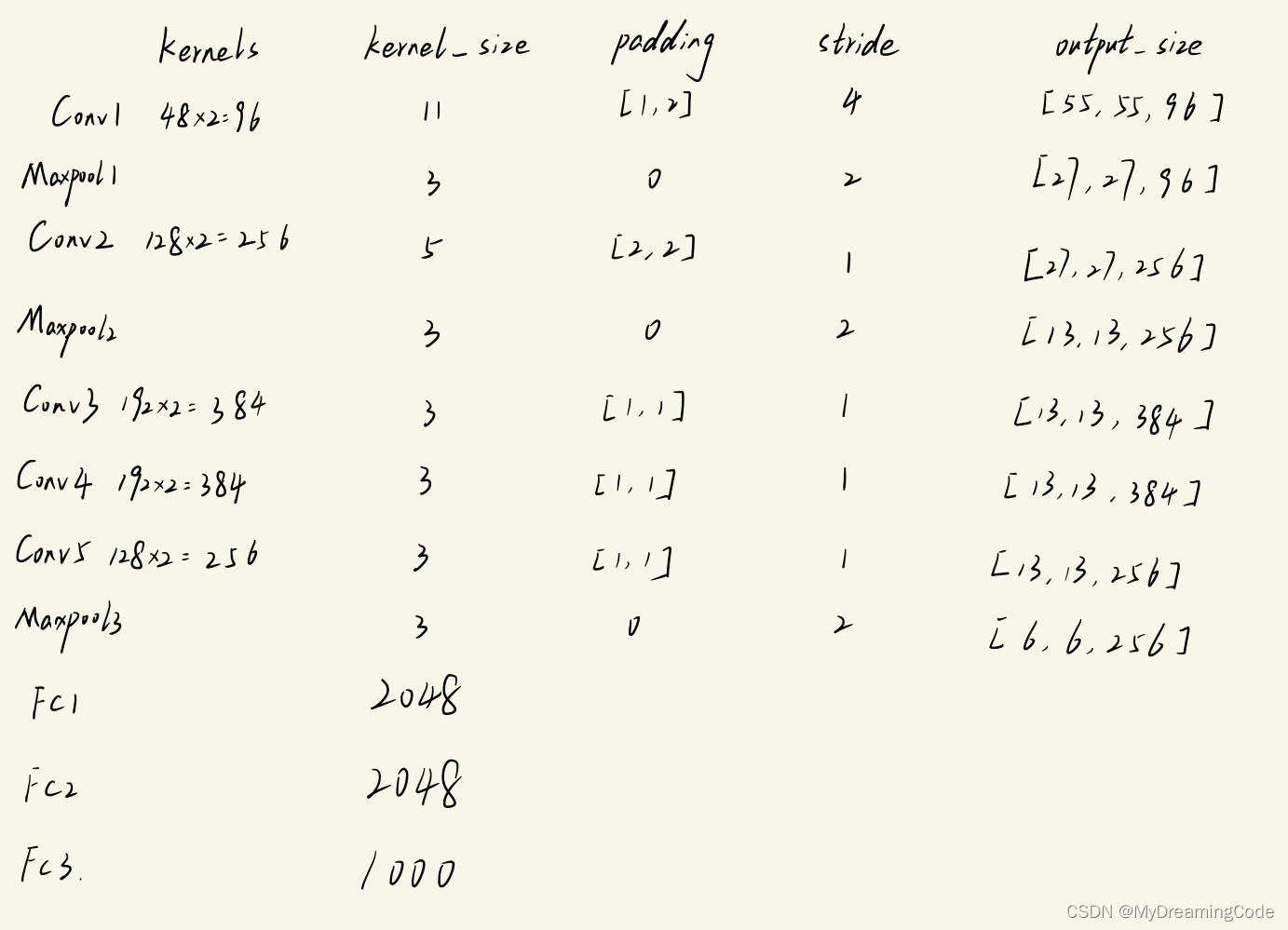
nn.Conv2d(3, 96, kernel_size=11, padding=2, stride=4), # input[3,224,224] output[96,55,55]
nn.ReLU(inplace=True), # inplace=True 址传递
nn.MaxPool2d(kernel_size=3, stride=2), # output[96,27,27]
nn.Conv2d(96, 256, kernel_size=5, padding=2), # output[256,27,27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[256,13,13]
nn.Conv2d(256, 384, kernel_size=3, padding=1), # output[384,13,13]
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), # output[384,13,13]
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # output[256,13,13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[256,6,6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # batch这一维度不用,从channel开始
x = self.classifier(x)
return x
train.py
import os
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
from model import AlexNet
import torch.optim as optim
from tqdm import tqdm
def main():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("using:{}".format(device))
data_transform = {
'train': transforms.Compose([
# 将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为指定大小
transforms.RandomResizedCrop(224),
# 水平方向随机翻转
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]),
'val': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
}
# get data root path
data_root = os.path.abspath(os.getcwd()) # D:\Code\AlexNet
# get flower data set path
image_path = os.path.join(data_root, 'data_set', 'flower_data') # D:\Code\AlexNet\data_set\flower_data
# 使用assert断言语句:出现错误条件时,就触发异常
assert os.path.exists(image_path), '{} path does not exist!'.format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, 'train'), transform=data_transform['train'])
val_dataset = datasets.ImageFolder(root=os.path.join(image_path, 'val'), transform=data_transform['val'])
train_num = len(train_dataset)
val_num = len(val_dataset)
# write class_dict into json file
flower_list = train_dataset.class_to_idx
class_dict = dict((v, k) for k, v in flower_list.items())
json_str = json.dumps(class_dict)
with open('class_indices.json', 'w') as file:
file.write(json_str)
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=0)
net = AlexNet(num_classes=5)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 5
save_path = './model/AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader) # train_num / batch_size
train_bar = tqdm(train_loader)
val_bar = tqdm(val_loader)
for epoch in range(epochs):
# train
net.train()
epoch_loss = 0.0
# 加入进度条
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step() # update x by optimizer
# print statistics
epoch_loss += loss.item()
train_bar.desc = 'train eporch[{}/{}] loss:{:.3f}'.format(epoch + 1, epochs, loss)
# validate
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1] # [1]取每行最大值的索引
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_acc = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, epoch_loss / train_steps, val_acc))
# find best accuracy
if val_acc > best_acc:
best_acc = val_acc
torch.save(net.state_dict(), save_path)
print('Train finished!')
if __name__ == '__main__':
main()
class_indices.json
{"0": "daisy", "1": "dandelion", "2": "roses", "3": "sunflowers", "4": "tulips"}predict.py
import os
import torch
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import json
from model import AlexNet
def main():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# load image
img_path = './2.jpg'
assert os.path.exists(img_path), "file:'{}' does not exist".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# input [N,C,H,W]
img = transform(img)
img = torch.unsqueeze(img, dim=0)
# read class_indices
json_path = './class_indices.json'
assert os.path.exists(json_path), "file:'{}' does not exist".format(json_path)
with open(json_path, 'r') as file:
class_dict = json.load(file) # {'0': 'daisy', '1': 'dandelion', '2': 'roses', '3': 'sunflowers', '4': 'tulips'}
# load model
net = AlexNet(num_classes=5).to(device)
# load model weights
weight_path = './model/AlexNet.pth'
assert os.path.exists(weight_path), "file:'{}' does not exist".format(weight_path)
net.load_state_dict(torch.load(weight_path))
# predict
net.eval()
with torch.no_grad():
output = torch.squeeze(net(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_class = torch.argmax(predict).numpy()
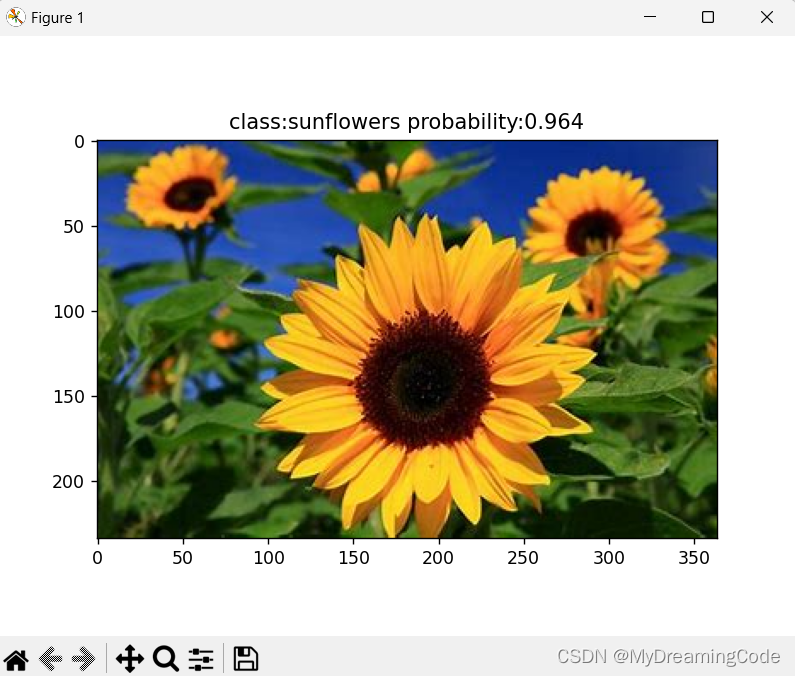
print_res = 'class:{} probability:{:.3}'.format(class_dict[str(predict_class)], predict[predict_class].numpy())
plt.title(print_res)
plt.show()
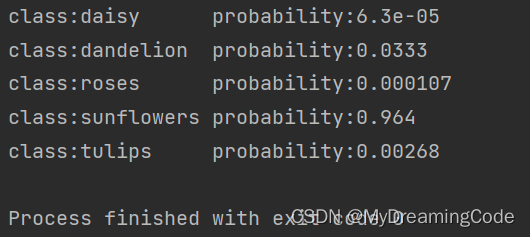
for i in range(len(predict)):
print('class:{:10} probability:{:.3}'.format(class_dict[str(i)], predict[i]))
if __name__ == '__main__':
main()
Result: