- 哈希位图
- 优缺点
- 位图应用
- 模拟实现代码
- 哈希布隆过滤器
- 哈希布隆过滤器的提出
- 哈希布隆过滤器概念
- 模拟实现代码
- 为什么哈希布隆图要比位图省空间
哈希位图和布隆过滤器都是常用的概率数据结构,用于高效地判断一个元素是否存在于一个集合当中,但它们在实现方法和各自的优缺点上有所区别。
哈希位图
哈希位图(Hash Bitmap)是由一个位数组构成,每个元素(通常是一个整数)被映射到位数组中的某个位置。对于集合中的每个元素,通过哈希函数将其映射到位数组的对应位置,并将该位置标记为已经存在。判断一个元素是否存在时,只需检查位数组中对应的位置是否被标记,若被标记则表示元素存在,否则表示元素不存在
哈希位图(Hash Bitmap)是由一个位数组构成,每个元素(通常是一个整数)被映射到位数组中的某个位置。对于集合中的每个元素,通过哈希函数将其映射到位数组的对应位置,并将该位置标记为已经存在。判断一个元素是否存在时,只需检查位数组中对应的位置是否被标记,若被标记则表示元素存在,否则表示元素不存在。
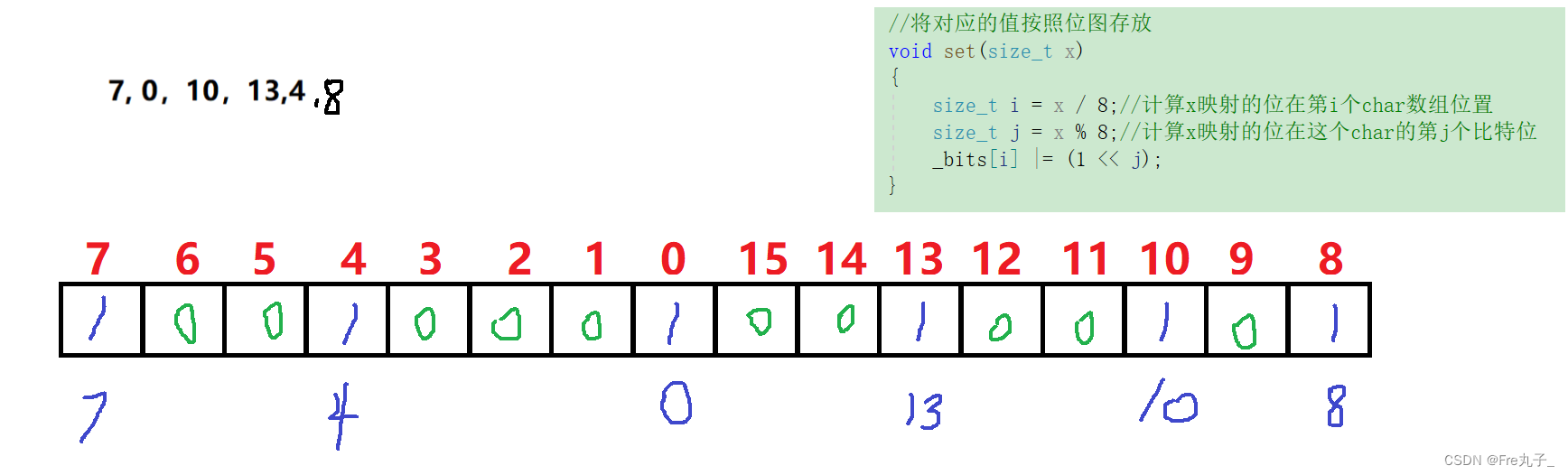
当我们存储整数时,因为一个整数为四个bit位,一个比特位八个字节,这样算下来占存的空间极大,我们可以使用
char类型进行存储,因为char只占一个字节。
我们可以将数组按字节来进行归类,就如上图来说
当我们要进行存储X的时候,我们先用 X / 8 来算出它在哪个比特位,然后再进行X % 8 来计算出他在这个bit位的第几个字节,计算出后将此位置设置为1,标记此数字
优缺点
优点
- 简单高效:哈希位图通过位运算可以在常量时间内完成元素的插入和查询操作。
- 空间效率高:相对于其他数据结构,哈希位图在空间使用上非常紧凑,只需要存储每个元素的标记位即可。
缺点
- 无法删除元素:哈希位图只能进行插入和查询操作,无法删除已经插入的元素。
- 内存占用:如果集合中的元素较多,哈希位图会占用较大的内存空间。
位图应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
例:
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
分析:首先不要受到题目的迷惑,100亿整数中包括很多重复数据,实际范围是0到0xffffffff。
512M左右就可以表示数据是否存在了。
代码逻辑分析:
用两个位图来放两文件中的数据,用两个位图中的对应位置表示不同的状态:
00表示两文件中都没有某个数据,10表示在一个位图中出现过,01表示在两个位图中都出现了,这种状态也就是交集数据的状态。
模拟实现代码
using namespace std;
//普通类型模板
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize((N / 8) + 1, 0);
}
//将对应的值按照位图存放
void set(size_t x)
{
size_t i = x / 8;//计算x映射的位在第i个char数组位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
_bits[i] |= (1 << j);
}
void reset(size_t x)
{
size_t i = x / 8;//计算x映射的位在第i个char数组位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
_bits[i] &= ~(1 << j);
}
//检查是否将位图修改
bool test(size_t x)
{
size_t i = x / 8;//计算x映射的位在第i个char数组位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
return _bits[i] & (1 << j);
}
private:
vector<char> _bits;
};
template<size_t N>
class twobitset
{
public:
//查找唯一出现一次的数
void set(size_t x)
{
// 00 -> 01
if (_bs1.test(x) == false
&& _bs2.test(x) == false)
{
_bs2.set(x);
}
else
{
//01 -> 10
_bs1.set(x);
_bs2.reset(x);
}
}
、
void Print()
{
for (size_t i = 0; i < N; ++i)
{
if (_bs2.test(i))
{
cout << i << endl;
}
}
}
void Print_more()
{
for (size_t i = 0; i < N; ++i)
{
if (_bs1.test(i))
{
cout << i << endl;
}
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
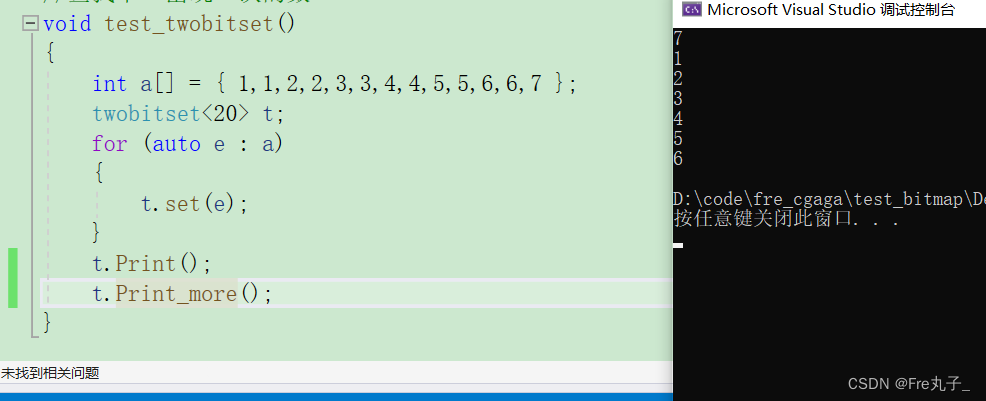
void test_twobitset()
{
int a[] = { 1,1,2,2,3,3,4,4,5,5,6,6,7 };
twobitset<20> t;
for (auto e : a)
{
t.set(e);
}
t.Print();
t.Print_more();
}
哈希布隆过滤器
布隆过滤器(Bloom Filter)是一种概率型数据结构,基于位数组和多个哈希函数实现。对于集合中的每个元素,通过多个哈希函数将其映射到位数组的多个位置,并将对应位置标记为已经存在。判断一个元素是否存在时,需要对该元素进行多次哈希,并检查所有对应位置是否都被标记,若有任何一个位置未被标记,则表示元素不存在。
哈希布隆过滤器的提出
在注册账号设置昵称的时候,为了保证每个用户昵称的唯一性,系统必须检测你输入的昵称是否被使用过,这本质就是一个key的模型,我们只需要判断这个昵称被用过,还是没被用过。
- 方法一:用红黑树或哈希表将所有使用过的昵称存储起来,当需要判断一个昵称是否被用过时,直接判断该昵称是否在红黑树或哈希表中即可。但红黑树和哈希表最大的问题就是浪费空间,当昵称数量非常多的时候内存当中根本无法存储这些昵称
- 方法二:用位图将所有使用过的昵称存储起来,虽然位图只能存储整型数据,但我们可以通过一些哈希算法将字符串转换成整型,比如BKDR哈希算法。当需要判断一个昵称是否被用过时,直接判断位图中该昵称对应的比特位是否被设置即可。
位图虽然能够大大节省内存空间,但由于字符串的组合形式太多了,一个字符的取值有256种,而一个数字的取值只有10种,因此无论通过何种哈希算法将字符串转换成整型都不可避免会存在哈希冲突。
这里的哈希冲突就是不同的昵称最终被转换成了相同的整型,此时就可能会引发误判,即某个昵称明明没有被使用过,却被系统判定为已经使用过了,于是就出现了布隆过滤器。
哈希布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询。
- 布隆过滤器其实就是位图的一个变形和延申,虽然无法避免存在哈希冲突,但我们可以想办法降低误判的概率。
- 当一个数据映射到位图中时,布隆过滤器会用多个哈希函数将其映射到多个比特位,当判断一个数据是否在位图当中时,需要分别根据这些哈希函数计算出对应的比特位,如果这些比特位都被设置为1则判定为该数据存在,否则则判定为该数据不存在。
- 布隆过滤器使用多个哈希函数进行映射,目的就在于降低哈希冲突的概率,一个哈希函数产生冲突的概率可能比较大,但多个哈希函数同时产生冲突的概率可就没那么大了。
假设布隆过滤器使用三个哈希函数进行映射,那么“张三”这个昵称被使用后位图中会有三个比特位会被置1,当有人要使用“李四”这个昵称时,就算前两个哈希函数计算出来的位置都产生了冲突,但由于第三个哈希函数计算出的比特位的值为0,此时系统就会判定“李四”这个昵称没有被使用过。
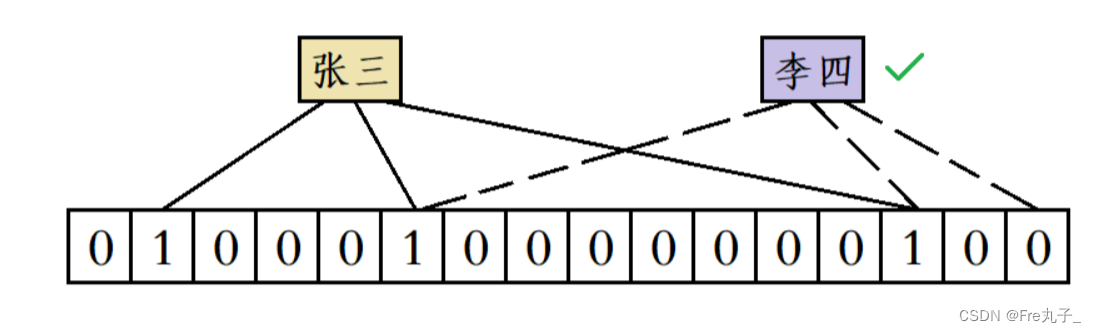
但随着位图中添加的数据不断增多,位图中1的个数也在不断增多,此时就会导致误判的概率增加。
比如“张三”和“李四”都添加到位图中后,当有人要使用“王五”这个昵称时,虽然“王五”计算出来的三个位置既不和“张三”完全一样,也不和“李四”完全一样,但“王五”计算出来的三个位置分别被“张三”和“李四”占用了,此时系统也会误判为“王五”这个昵称已经被使用过了。
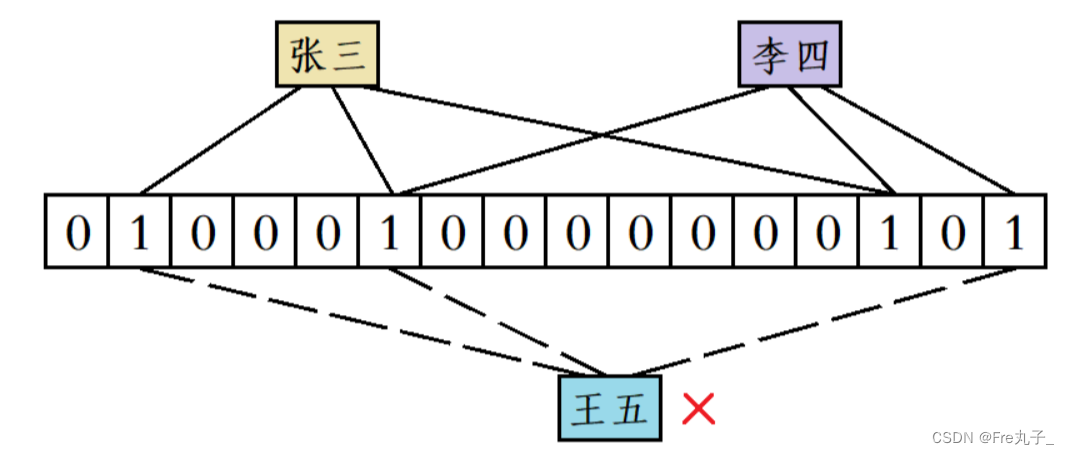
布隆过滤器的特点
- 当布隆过滤器判断一个数据存在可能是不准确的,因为这个数据对应的比特位可能被其他一个数据或多个数据占用了。
- 当布隆过滤器判断一个数据不存在是准确的,因为如果该数据存在那么该数据对应的比特位都应该已经被设置为1了。
如何控制误判率
- 很显然,过小的布隆过滤器很快所有的比特位都会被设置为1,此时布隆过滤器的误判率就会变得很高,因此布隆过滤器的长度会直接影响误判率,布隆过滤器的长度越长其误判率越小。
- 此外,哈希函数的个数也需要权衡,哈希函数的个数越多布隆过滤器中比特位被设置为1的速度越快,并且布隆过滤器的效率越低,但如果哈希函数的个数太少,也会导致误判率变高。
那应该如何选择哈希函数的个数和布隆过滤器的长度呢,有人通过计算后得出了以下关系式:

其中k为哈希函数个数,m为布隆过滤器长度,n为插入的元素个数,p为误判率。
我们这里可以大概估算一下,如果使用3个哈希函数,即k的值为3,l n 2 的值我们取0.7,那么 m 和 n的关系大概是m = 4 × n ,也就是布隆过滤器的长度应该是插入元素个数的4倍。
模拟实现代码
//布隆过滤器
//N位最多插入的key个数据
template<size_t N, class K = string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter
{
public:
void set(const K& key)
{
size_t len = N * _x;
size_t hash1 = Hash1()(key) % len;
_bs.set(hash1);
size_t hash2 = Hash2()(key) % len;
_bs.set(hash2);
size_t hash3 = Hash3()(key) % len;
_bs.set(hash3);
cout << hash1 << " " << hash2 << " " << hash3 << endl;
}
bool test(const K& key)
{
size_t len = N * _x;
size_t hash1 = Hash1()(key) % len;
if (!_bs.test(hash1))
{
return false;
}
size_t hash2 = Hash2()(key) % len;
if (!_bs.test(hash2))
{
return false;
}
size_t hash3 = Hash3()(key) % len;
if (!_bs.test(hash3))
{
return false;
}
return true; //key对应的三个位都被设置,key存在(可能误判)
}
private:
static const size_t _x = 4;
bitset<N * _x> _bs;//求布隆过滤器长度
};
_X代表布隆过滤器的长度,是通过以下公式计算得来的

为什么哈希布隆图要比位图省空间
哈希布隆图相比于位图在空间使用上更加高效,这是因为哈希布隆图利用了多个哈希函数和位数组的重复利用,减少了所需的内存空间。
首先,让我们对比一下位图和哈希布隆图的实现方式:
-
位图:位图是一个固定大小的位数组,数组中的每个位置表示一个元素,当元素存在时,对应位置的位值为1;当元素不存在时,对应位置的位值为0。位图的大小与集合中元素的总数相一致,每个元素都需要一个位置来进行标记。
-
哈希布隆图:哈希布隆图也是一个位数组,但与位图不同的是,哈希布隆图的位数组长度通常会远远小于集合中元素的总数。它利用了多个哈希函数,每个元素通过这些哈希函数映射到位数组中的多个位置,将这些位置标记为1。判断一个元素是否存在时,需要对该元素进行多次哈希,并检查所有对应位置是否都被标记。
那么为什么哈希布隆图能够在空间上节省?
-
多个哈希函数:哈希布隆图使用多个哈希函数,将每个元素映射到位数组的多个位置上。通过这种方式,可以减少冲突的可能性,使得位数组中的每个位置都能够被更多元素共享,从而减少了位图中的重复位。
-
位数组的重复利用:由于每个元素都会被多次哈希并占用多个位置,在位数组中的某个位置可能被多个元素标记。利用这种重复标记的方式,哈希布隆图可以在相对较小的位数组中表示更多的元素。
举个例子来说明,假设我们要表示一个集合,其中包含100个元素。如果使用位图,我们需要一个大小为100的位数组,每个元素都占用一个位;而使用布隆过滤器,我们可以选择一个相对较小的位数组,比如大小为50,并使用多个哈希函数将元素映射到位数组的多个位置,每个元素可以占用多个位。通过合理的设计,可以在仅占用50个位的情况下,仍然能够高效地判断集合中的元素是否存在。
需要注意的是,哈希布隆图的节省空间是以牺牲一定的查询准确率为代价的。由于哈希冲突和位数组的重复利用,布隆过滤器可能存在一定的误判率,即判断元素不存在时,仍有一定概率判断为存在。因此,在使用哈希布隆图时需要权衡空间利用和查询准确率之间的关系。









![NSS [HNCTF 2022 WEEK2]easy_sql](https://img-blog.csdnimg.cn/img_convert/69e004b62ceb80499f3a56e5b99bef81.png)