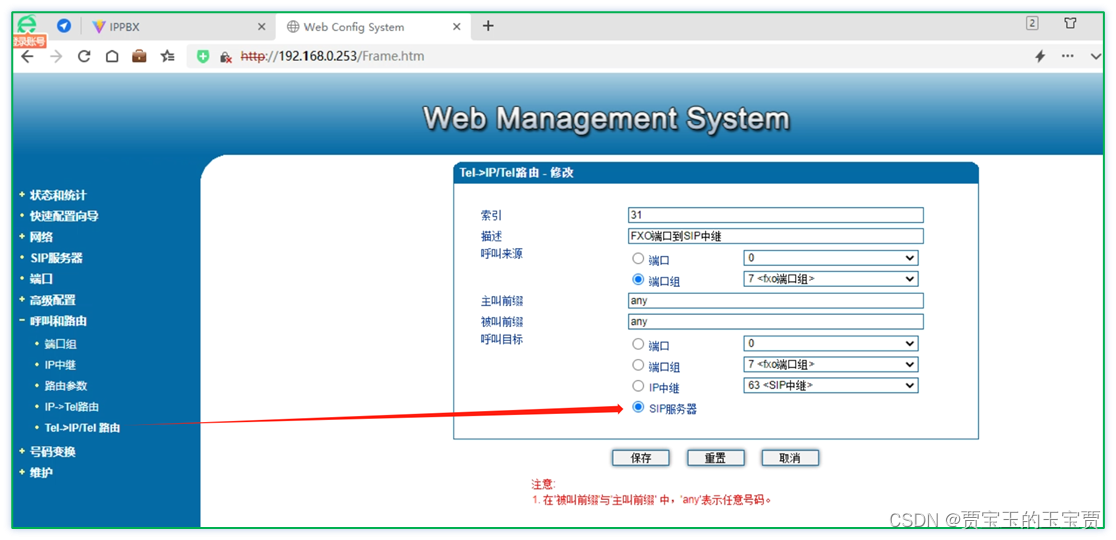
TF-IDF定义
TF-IDF: 全称为"词频一逆文档频率"。
TF:某一给定词语在该文档中出现的频率。
T
F
w
=
词语
w
在该文档中个数
该文档内总词个数
TF_w = \frac{词语w在该文档中个数}{该文档内总词个数}
TFw=该文档内总词个数词语w在该文档中个数。
IDF:整个训练集文档集合一共由
N
N
N篇文档组成,其中包含某个给定词语
w
w
w的文档数为
M
M
M. 则该给定词的
I
D
F
IDF
IDF值为:
I
D
F
=
l
o
g
e
(
N
M
+
1
)
IDF=log_e(\frac{N}{M+1})
IDF=loge(M+1N),M+1是防止分母=0。
一个词的
T
F
TF
TF值反映了该词在某一篇文档中的重要性,而它的
I
D
F
IDF
IDF值则反映了它在整个文档集中的普遍重要程度。二者的乘积(TF-lDF ) 相当于取TF 和IDF的交集, 其值理论上可以较好地反映各个词的分类特征。某一特定文件内的较高词语频次,以及该词语在整个文件集合中的较低频次,可以产生较高的TF-IDF值,TF-IDF算法倾向于过滤常见词语,保留重要词语。经常结合余弦相似度用于向量空间中,判断两份文件的相似度。
python实现
直接使用TfidfVectorizer
这里采用的是[“Chinese Beijing Chinese”, “Chinese Chinese Shanghai”,“Chinese Macao”,“Tokyo Japan Chinese”]这个训练语料库,做一个简单的试验。
起初,我以为这样就能解决:
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer() # 实例化tf实例
train = ["Chinese Beijing Chinese", "Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"] # 输入训练集矩阵,每行表示一个文本
tv_fit = tv.fit_transform(train) # 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
print(f'词汇表{tv.get_feature_names_out()}') # 查看一下构建的词汇表
print(f'不同词语对应下标:{tv.vocabulary_}')
print(f'矩阵{tv_fit.toarray()}') # 查看输入文本列表的VSM矩阵
这是借助TfidfVectorizer进行实现的,结果如下:[‘beijing’ ‘chinese’ ‘japan’ ‘macao’ ‘shanghai’ ‘tokyo’]代表了语料库内所有的词语;{‘chinese’: 1, ‘beijing’: 0, ‘shanghai’: 4, ‘macao’: 3, ‘tokyo’: 5, ‘japan’: 2}是不同词语对应下标,这个在下面的矩阵里面代表这个词语在第几列;
矩阵的每一行代表一个文档内的每一个词语的TF-IDF值。举个例子,对于文档"Chinese Beijing Chinese"来讲它的结果就是第0行[0.69183461,0.722056 ,0. , 0. , 0. , 0. ],该文档中只有Chinese和Beijing 这两个词语,因此只有两个元素非零,其中chinese对应列是1,于是它在该文档中的TF-IDF值为0.722056,beijing1对应列是0.于是它在该文档中的TF-IDF值为0.69183461。

结果解释
但是仔细一看,欸???为什么?这些数值是什么意思???
就拿"Chinese Beijing Chinese"里的chinese来说,根据定义,
T
F
=
2
3
,
I
D
F
=
l
o
g
e
(
4
5
)
,
T
F
−
I
D
F
=
−
0.1487
?
?
?
TF = \frac{2}{3},IDF = log_e(\frac{4}{5}),TF-IDF = -0.1487???
TF=32,IDF=loge(54),TF−IDF=−0.1487???,不对劲啊!!
我就在网上找啊,发现TF_IDF公式还挺多,不止有定义里的;
一个例子来使用sklearn中的TfidfVectorizer
tf-idf原理 & TfidfVectorizer参数详解及实战
经过我实践证明TfidfVectorizer使用的计算TF-IDF公式如下:
T
F
=
给定词语在该文档中出现的频数
I
D
F
=
l
n
(
1
+
N
1
+
M
)
+
1
T
F
I
D
F
=
T
F
∗
I
D
F
整个训练集文档集合一共由
N
篇文档组成,其中包含某个给定词语的文档数为
M
.
TF = 给定词语在该文档中出现的频数\\ IDF = ln(\frac{1+N}{1+M})+1\\ TFIDF = TF*IDF\\ 整个训练集文档集合一共由N篇文档组成,其中包含某个给定词语的文档数为M.
TF=给定词语在该文档中出现的频数IDF=ln(1+M1+N)+1TFIDF=TF∗IDF整个训练集文档集合一共由N篇文档组成,其中包含某个给定词语的文档数为M.
然后TfidfVectorizer还对每个文档的向量进行规范化,即对于每个文档的词语TF-IDF向量
v
v
v还要除以2范数,
v
∣
∣
v
∣
∣
2
\frac{v}{||v||_2}
∣∣v∣∣2v
手敲代码
这是我根据这个公式写出的python代码:
# 求逆文档频率IDF
def Idf(nd,df):
return np.log((1+nd)/(1+df)) + 1
train = ["Chinese Beijing Chinese", "Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
wordInDoc = [] # 记录在每个文档语句中单词出现次数,元素为字典,每个字典记录该文档中单词出现次数
wordInCor = {} # 语料库中单词出现的文档
'''
不会重复
'''
# 求出每个文档语句中单词出现次数
for doc in train:
words = doc.split() # 将句子按空格分割成单词
word_counts = {} # 使用字典存储词语出现次数
for word in words:
word = word.strip('.,!?"()[]{}') # 去除标点符号
word = word.lower() # 转换为小写以忽略大小写差异
# 更新字典中词语的出现次数
word_counts[word] = word_counts.get(word,0)+1
wordInDoc.append(word_counts) # 添加该文档字典
# 语料库中单词出现的文档
for i in wordInDoc: # 遍历每个文档字典
for j in i: # 如果词汇j出现在文档i中则该词汇出现次数+1
wordInCor[j] = wordInCor.get(j,0)+1
# 给出每个词汇在哪一列
ind = {} # 每个词汇对应下标,对应后面,词汇result中的哪一列
for i,word in enumerate(list(np.sort(list(wordInCor.keys())))):
ind[word] = i
# 结果是一个稀疏矩阵
result = np.zeros((len(train),len(wordInCor.keys())))
for i in range(len(train)): # 遍历每个文档
for word in ind.keys(): # 遍历每个词汇
if word in wordInDoc[i].keys(): # 如果该词汇在该文档中,则计算
tf = wordInDoc[i][word] # wordInDoc[i]第几个文档的字典,wordInDoc[i][word]该文档中词汇出现次数?
# 这边其实是有点疑问的,网上tf公式大多是频率,但是TfidfVectorizer从结果来倒推,TfidfVectorizer用的是频数
idf = Idf(len(train),wordInCor[word]) # len(train)为文档总数=4,wordInCor[word]为该词汇在文档中出现次数
tfidf = tf*idf
result[i,ind[word]] = tfidf
# 规范标准化,除以2范数
result = result/np.sqrt((result**2).sum(axis = 1)).reshape(-1,1)
print(result)
结果:可以看出结果是和调用TfidfVectorizer是一样的。当然,这里词语对应的列与上面不同。

总结
TfidfVectorizer使用的计算TF-IDF的公式与定义有差别。但实际上表达的意思是相同的,都是在该文档中的重要性TF乘以在语料库中的重要性IDF的乘积。
np.log()其实是以e为底的,所以如果要计算以其他数为底的对数,需要进行换底公式
L
o
g
a
b
=
l
o
g
c
b
l
o
g
c
a
Log_ {a}b=\frac {log_ {c}b} {log_ {c}a}
Logab=logcalogcb
def Log(newd,number): #newd新底
return np.log(number)/np.log(newd)
Log(10,10)