顺序查找
最基本的查找算法
举例
// 顺序查找
public static int searchSequence(int[] arr, int target) {
int i = 0;
for (int arr2 : arr) {
if (arr2 == target) {
return i;
}
i++;
}
return -1;
}
二分查找
[! warning]
值得注意的是这个二分查找算法只对无重复元素的递增或递减的数组有效, 所以我们使用的时候要保证这个数组是有序的, 我们可以利用 Arrays.sort 来对这个数组进行排序,sort 的默认排序是递增排序
最简单的二分查找算法
举例
// 二分查找,只能对排序算法使用,使用前我们需要先对这个数组进行排序
public static int searchBinary(int[] arr, int target) {
Arrays.sort(arr);
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] == target) {
return mid;
} else if (target < arr[mid]) {
right = mid - 1;
} else if (target > arr[mid]) {
left = mid + 1;
}
}
return -1;
}
二分查找的扩展插值查找
二分算法的优化, 通过逼近来实现这个查找
关键代码是
int mid = left + (target - a[left]) / (a[right] - a[left]) * (right - left);
这个与二分搜索算法类似, 本质上就是中值不太一样,
二分查找的扩展斐波那契查找
利用 0.618 的分割比进行查找这个数字
关键代码是
int mid =(int)((right - left) * (1.0 / 1.618) + left) ;
三种二分查找算法的优缺点是什么
二分查找算法
二分搜索算法(Binary Search)是一种在有序数组中查找特定元素的常用算法。它通过将数组不断分割为两半,并比较目标值与中间元素的大小关系来确定目标值所在的区间,从而逐步缩小搜索范围。以下是二分搜索算法的优缺点:
优点:
1. 效率高:二分搜索算法的时间复杂度为 O(log n),其中 n 是数组的长度。由于每次搜索都将搜索范围减半,因此它相对于线性搜索具有更高的效率。
2. 简单:二分搜索算法的实现相对简单,只需递归地分割数组并进行比较即可。
缺点:
1. 仅适用于有序数组:二分搜索算法要求数组是有序的,如果数组未排序,则需要先进行排序操作。
2. 需要额外的空间:二分搜索算法通常需要递归调用,因此可能需要额外的函数调用栈空间。
3. 不适用于插入或删除操作:二分搜索算法用于查找特定元素,但不适用于在数组中插入或删除元素。每次插入或删除操作后,数组可能会被改变,导致结果不准确。
插值搜索算法
插值搜索算法(Interpolation Search)是一种在有序数组中根据目标值的估计位置进行搜索的算法,它不是简单地将数组分割为两半,而是根据目标值与数组中元素的关系来动态计算估计位置。以下是插值搜索算法的优缺点:
优点:
1. 更快的平均搜索时间:插值搜索算法通过根据目标值的估计位置来确定搜索范围,因此平均情况下比二分搜索算法更快。
2. 在数据分布均匀时效果好:当数组中元素分布均匀且接近线性时,插值搜索算法的效果最佳。
缺点:
1. 对数据分布敏感:插值搜索算法对于数据分布不均匀的情况下效果可能很差,甚至可能比二分搜索算法更慢。
2. 可能导致不必要的比较:由于插值搜索算法根据估计位置来确定搜索范围,如果估计位置不准确,可能会导致不必要的比较操作。
斐波那契数列算法
斐波那契查找算法(Fibonacci Search)是一种在有序数组中进行查找的算法,它使用了斐波那契数列来确定搜索范围。与二分搜索和插值搜索相比,斐波那契查找算法有以下优缺点:
优点:
1. 更好的适应性:斐波那契查找算法对于分布不均匀且未知的数据集更具适应性。在某些情况下,它比二分搜索和插值搜索算法更快。
2. 减少比较次数:在某些情况下,斐波那契查找算法的平均比较次数较少,因为它动态调整搜索区间。
缺点:
1. 需要额外的空间:斐波那契查找算法需要预先计算斐波那契数列,这可能需要额外的空间来存储数列。
2. 对于小规模数据不如二分搜索:当数据规模较小时,斐波那契查找算法的性能可能不如简单的二分搜索算法。
3. 不适用于插入和删除操作:与二分搜索和插值搜索一样,斐波那契查找算法也不适用于在数组中执行插入或删除操作。
总结
二分搜索算法在大多数情况下都是一个可靠且高效的选择,特别是对于有序数组的查找操作。插值搜索算法在数据分布均匀的情况下可能会提供更好的性能,但在数据分布不均匀的情况下可能会导致不准确的结果。
斐波那契查找算法在某些情况下可以提供更好的性能,特别是在数据分布不均匀且未知的情况下。然而,它需要更多的空间和计算成本,并且不适用于插入和删除操作
分块查找
分块查找的应用场景
分块查找算法(Block Search)是一种在分块有序表中进行查找的算法。它将数据集划分为若干块(或称为块),每个块内部元素有序,但块与块之间不一定有序。对于一个给定的查找元素,首先确定其所在的块,然后在该块内进行查找。这使得分块查找算法在某些特定的应用场景下具有优势:
- 数据集较大且有序:分块查找算法适用于较大的有序数据集。通过将数据划分为块,可以快速缩小查找范围,提高查找效率。
- 块内元素相对较少:在每个块内,元素的数量相对较少。这使得块内查找的时间复杂度较低,从而进一步提高了整体查找效率。
- 需要频繁的插入和删除操作:分块查找算法相对于二分搜索等其他算法较容易处理插入和删除操作。因为只需要对块内进行相应的插入和删除操作,而不需要改变其他块的顺序。
分块查找算法常见的应用场景包括:
- 文件系统:在文件系统中,可以将文件按照某种规则划分为块,利用分块查找算法快速定位所需文件。
- 图书馆索引:图书馆中的书籍可以按照分类号等信息进行分块,利用分块查找算法进行快速检索。
- 路由表查找:在网络路由中,可以将路由表按照某种规则划分为块,利用分块查找算法快速查找匹配的路由项。
需要注意的是,分块查找算法适用于特定场景,对于一般的有序数组查找可能并不是最优选择。因此,在使用分块查找算法时需要根据具体应用场景和问题特点进行合理选择。
分块查找的介绍
就是将数组中的数据划分为几个块, 前一个块的所有数据小于后一个块的所有数据, 我们以每一个块的最大值来进行分割
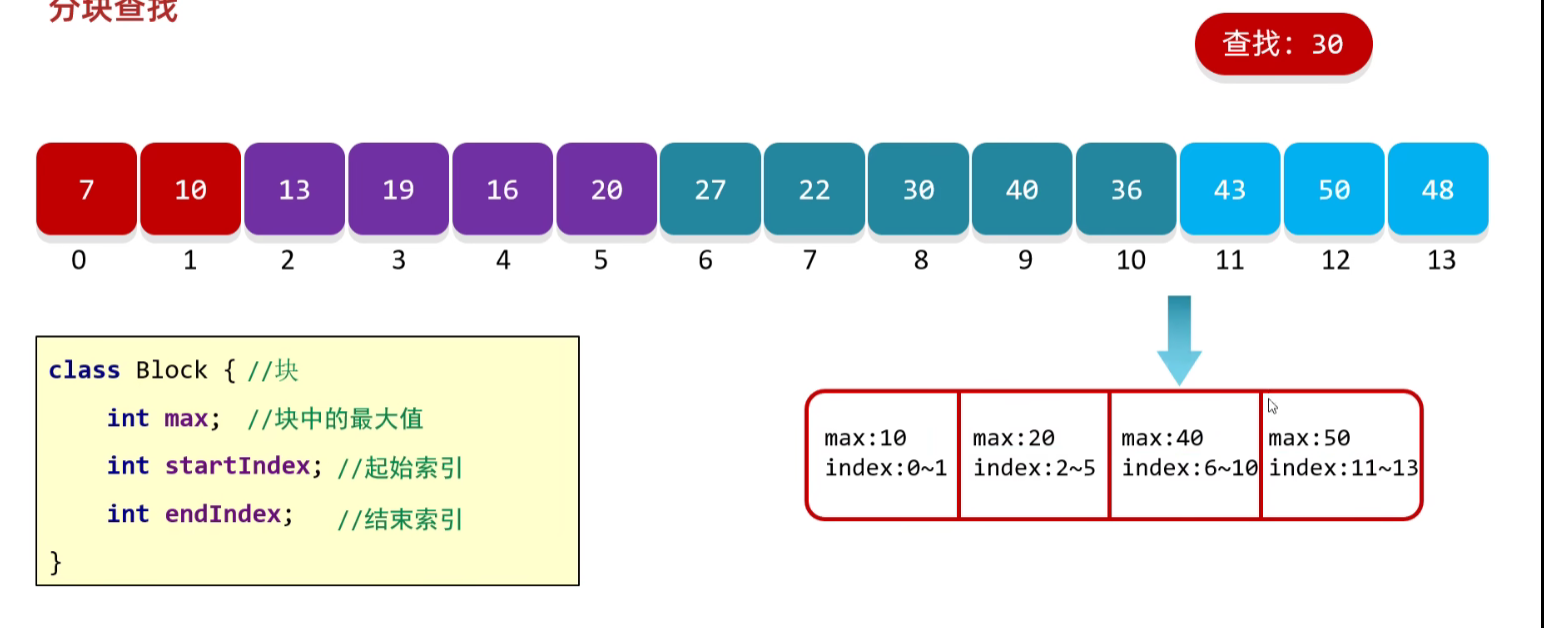

[!example]
下面的这个例子, 其实不太恰当, 只是为了描述这个分块查找的思想, 其实分块查找难点不在于如何查找, 难点在于如何分块, 如何将这个数组划分成满足前一个块的数据小于后一个块的数据. 这才是难点, 我的例子避去了这一点, 只是简单的对这个如何排序做了编辑
package heima_study.day3算法查找排序;
import java.util.Objects;
import java.util.Scanner;
public class 分块查找 {
public static void main(String[] args) {
int[] arr = { 16, 5, 9, 12, 21, 18,
32, 23, 37, 26, 45, 34,
50, 48, 61, 52, 73, 66 };
block[] brr = new block[3];
brr[0]=new block(21, 5, 0, 5);
brr[1]=new block(45, 23, 6, 11);
brr[2]=new block(73, 48, 12, 17);
int target;
Scanner input = new Scanner(System.in);
target = input.nextInt();
int i = searchBlock(brr, target);
if (i != -1) {
//查找成功
int result = searchAll(arr, target, brr[i].getStart(), brr[i].getEnd());
System.out.println(result);
} else {
System.out.println(-1);
}
input.close();
}
public static int searchAll(int[] arr, int target, int start, int end) {
for (int i = start; i <= end; i++) {
if (arr[i] == target) {
return i;
}
}
return -1;
}
public static int searchBlock(block[] brr,int target){
for (int i = 0; i < brr.length; i++) {
if (target < brr[i].getMax() && target > brr[i].getMin()) {
//说明是在这个块里面
return i;
}
}
return -1;
}
}
class block {
private int max;
private int min;
private int start;
private int end;
public block() {
}
public block(int max, int min, int start, int end) {
this.max = max;
this.min = min;
this.start = start;
this.end = end;
}
public int getMax() {
return this.max;
}
public void setMax(int max) {
this.max = max;
}
public int getMin() {
return this.min;
}
public void setMin(int min) {
this.min = min;
}
public int getStart() {
return this.start;
}
public void setStart(int start) {
this.start = start;
}
public int getEnd() {
return this.end;
}
public void setEnd(int end) {
this.end = end;
}
@Override
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof block)) {
return false;
}
block block = (block) o;
return max == block.max && min == block.min && start == block.start && end == block.end;
}
@Override
public int hashCode() {
return Objects.hash(max, min, start, end);
}
@Override
public String toString() {
return "{" +
" max='" + getMax() + "'" +
", min='" + getMin() + "'" +
", start='" + getStart() + "'" +
", end='" + getEnd() + "'" +
"}";
}
}
分块查找的补充
在学习这个分块查找的时候, 我对于这个分块查找的原理还不是特别的清楚, 于是我就去网上查找资料,
在分块查找这个网页里面看到了一个较好的解释, 并且它提供了一个个人感觉还是不错的划分块的方法
我在这里不对这个页面的内容过多介绍, 感兴趣的可以自己去了解一下, 我主要是对它代码使用的方法进行一个总结
作者使用的类是
public class BlockSearch {
private int[] index; //索引表
private ArrayList[] list; //存放每个块的元素
}
它首先建立了一个索引表
int[] index = { 10, 20, 30 };
这个索引表刚开始看会感觉有点懵, 不知道它是干什么的, 其实这个索引表就是原作者为这个块划分的最大元素, 它自己定义了三个块, 每个块的最大元素由自己决定, 然后不断向里面添加元素
blockSearch.insert(1);
blockSearch.insert(12);
blockSearch.insert(22);
blockSearch.insert(9);
blockSearch.insert(18);
blockSearch.insert(23);
……………………
添加的元素通过二分搜索法确定这个元素所属的块
private int binarySearch(int data) {
int start = 0;
int end = index.length;
int mid = -1;
while (start <= end) {
mid = (start + end) / 2;
if (index[mid] > data) {
end = mid - 1;
} else {
// 如果相等,也插入在后面
start = mid + 1;
}
}
return start;
}
举个例子:如果大于 10 小于 20 就属于第二个块, 返回 1, 然后向 list[1]里添加元素
通过这样的一个巧妙方法, 就实现了这个分块
不过这种分块方式也有自己的缺点, 就是这个大小你要自己调整, 同时块的数量也要自己去定义.
不过我感觉这个真的是已经很好了. 感觉很适合新手去理解这个分块搜索算法







![[mockjs]-mockjs的使用](https://img-blog.csdnimg.cn/decac9acee6b4df7a049648c5ecf795f.png)
