开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1300人左右 1 + 2 + 3 + 4) 3群即将突破 400 会关闭自由申请,新人会进4群
当越来越活明白的时候,人性的理解要深刻,没有人应该对你好,他不恶毒的对待你,已经是善良了。上次的陈老师在对PolarDB 的分享中,提到一个新名词,bypass,通过bypass 来提高整体的云原生数据库的性能。这在传统的数据库的技术中我未曾听过,当然上次的东西,最近比较懒,没有整理,后续我会把相关的录音转换成文字,把PolarDB到底打败了谁,之快问快答的东西整理出来。
这次先把kerne bypass 的概念搞搞清楚,这里需要抛弃传统数据库使用物理机的思维。云上的数据库产品,面对的环境要比线下的数据库的环境要复杂,面对的主机的物理形式也有不同,基于这些不同 kernel-bypass 内核旁路的技术出现了,主要解决了是超大并发下内核态与用户态之间的性能问题,这项技术的特点是不使用LINUX内核访问内存,而通过绕过系统的方式来,从用户的空间直接访问控制内存的设备,这项技术最大的目的就是高性能,低延迟。
实际上在阅读了一些相关的资料后,产生问题的核心在LINUX 本身的内核无法承受数据流量问题,而kernel bypass就是要解决这个问题。这里解决这个问题的主要解决方案如下:
1 DPDK
2 NETMAP
3 PF_RING
4 RACKET_MMAP
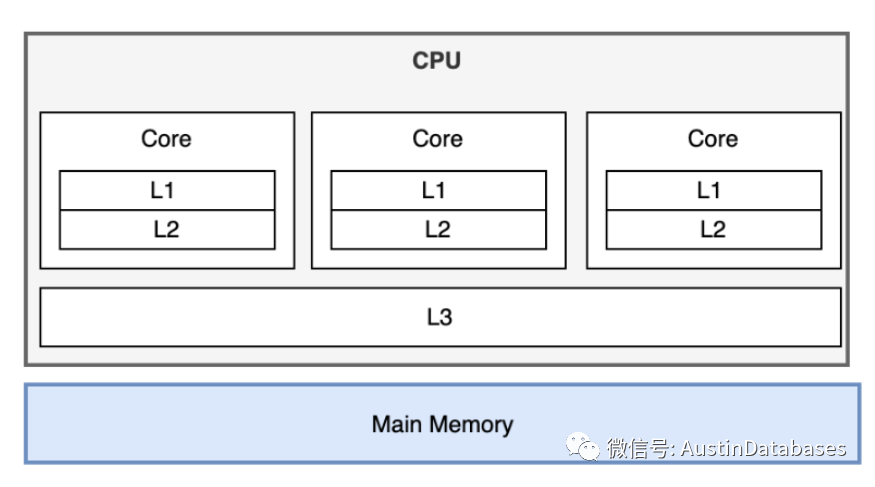
其中解决问题的核心是系统内核的数据传输中会面临中断处理,内存拷贝,上下文切换,局部性失效,内存的数据交互与使用等问题,一般CPU都有3级缓存,在系统运行中如果数据在处理中能在1 2 级别的缓存中命中,效率会较高,而如果无法命中,则就需要等待周期,1级缓存等待 4个周期,2级缓存等待12个周期,3级缓存等待30个周期 到了内存这个级别就是300个周期了。
那么什么是周期,CPU的周期指的是计算机处理指令所需要的时间单位,每个指令的执行都需要经过电子信号的传输,寄存器的操作,算数运算等步骤才能完成。这里以3.0HZ的CPU,一个周期约为0.33纳秒。所以数据切换就需要等待的周期。
而kernel-bypass要做的就是,控制层和数据层进行分离,将数据包的处理,内存的管理,处理器的调度等赚到用户的空间来操作,内核仅仅处理控制指令,这样就没有上面提到的一堆的切换问题。同时我们经常在国产数据库和国产硬件产品中的绑核,也是基于这个问题采用非Bypass kernel的思路,这是将线程和CPU的核心进行绑定,减少线程切换和调度的性能消耗。
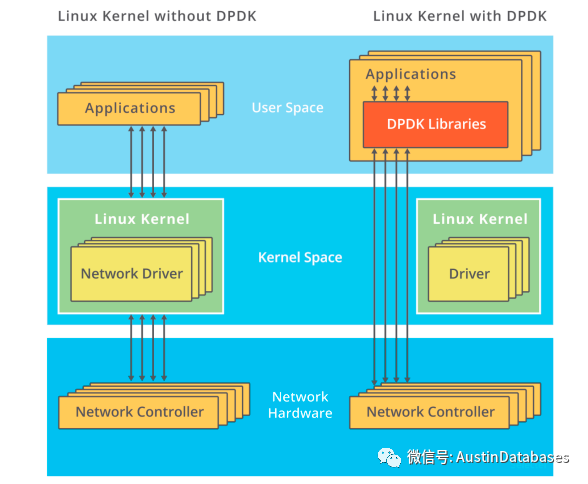
这里我们以DPDK技术作为一个学习点,了解kernel bypass的实现方式
这项技术主要做的有如下几个部分
用户空间数据包处理(内核绕过)。
避免上下文切换开销。
轮询模式驱动程序(PMD)。
避免中断处理开销。
保持核心繁忙。
内存使用优化。
轻量级mbufs。
使用巨页、缓存对齐等的内存池。
无锁环形缓冲区。
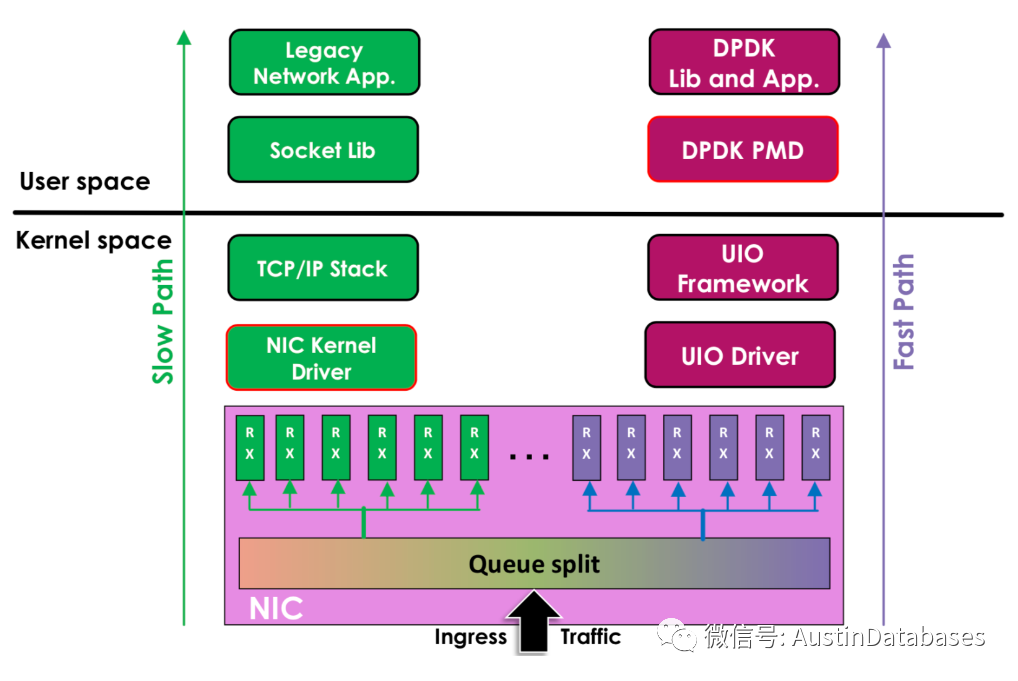
DPDK 本身也支持除X86 体系以外的 ARM, PowerPC 等,这里的UIO机制本身是在 UIO中可以通过read 感知中断,通过mmap实现和网卡的通讯,DPDK的UIO驱动屏蔽了硬件发出中断,在用户态中采用主动轮询的方式,这样的方式称为 PMD poll mode driver ,由于去除了硬中断,DPDK可以在用户态做收发包的处理,而不需要进行拷贝,没有系统调用,减少上下文的切换,最终避免了缓存没有命中后的CPU的周期等待。
所以kernel bypass 的功能在云环境是有必要的,解决了高数据量并发时的CPU 消耗的问题,同时也必须说明基于这项技术,也需要CPU 来管理,所以CPU的核心数不要太少。
基于这项技术对于数据库DBA 是一个了解就好的情况,对于这项技术的分支DPDK 中的详细知识可以访问,如下网站进行更深入的学习和了解。
https://doc.dpdk.org/guides/linux_gsg/