文章目录
- 一、新建数据库
- 1、字符集
- 1.1 字符集作用
- 1.2 常用选择
- 2、排序规则
- 2.1 排序规则作用
- 2.2 常用选择
- 二、新建表
- 1、字符串类型
- 1.1 CHAR 和 VARCHAR 的定义
- 1.2 字符占用
- 三、常用基础知识
- 1、什么是方言?
- 2、SQL书写规范
- 3、SQL分类
- 1)DDL (data definition language 数据定义语言)
- 2)DML (data manipulation language 数据操纵语言)
- 3)DCL (data control language 数据控制语言)
- 4)TCL (Transaction Control language 事务控制语言 )
- 4、常用的数据类型
- 1). 字符型数据:
- 2). 日期时间型数据
- 3). 整数型数据
- 4). 精确小数型数据
- 5). 近似数值类型
- 6). 货币型数据
- 7). 位类型数据
- 5、常用sql语句
- 1)操作数据库
- 1.1) 创建数据库
- 1.2) 修改数据库
- 1.3)删除数据库
- 1.4) 其他常用
- 2)操作表
- 2.1) 创建表
- 2.2) 创建表修改表
- 2.3) 删除表
- 2.4) 其他
- 3) 操作数据记录
- 3.1) 添加记录
- 3.2) 修改记录
- 3.3) 删除记录
- 3.4) 查询记录
- 3.4.1) 基本查询
- 3.4.2) 条件查询
- 3.4.3) 排序
- 3.4.4) 聚合函数
- 3.4.5) 分组
- 3.4.6) 分页
- 4) 数据库约束
- 4.1) 概述
- 4.1.1) 作用
- 4.1.2) 约束有哪些:
- 4.2) 实现
- 4.2.1) 主键约束
- 4.2.2) 唯一约束
- 4.2.3) 非空约束
- 4.2.4) 默认值
- 四、数据库设计原则
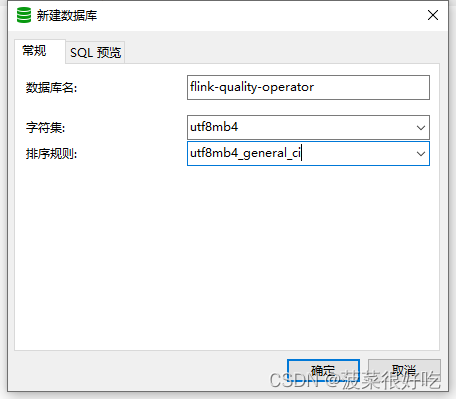
一、新建数据库
欢迎加入扣扣组织,783092701
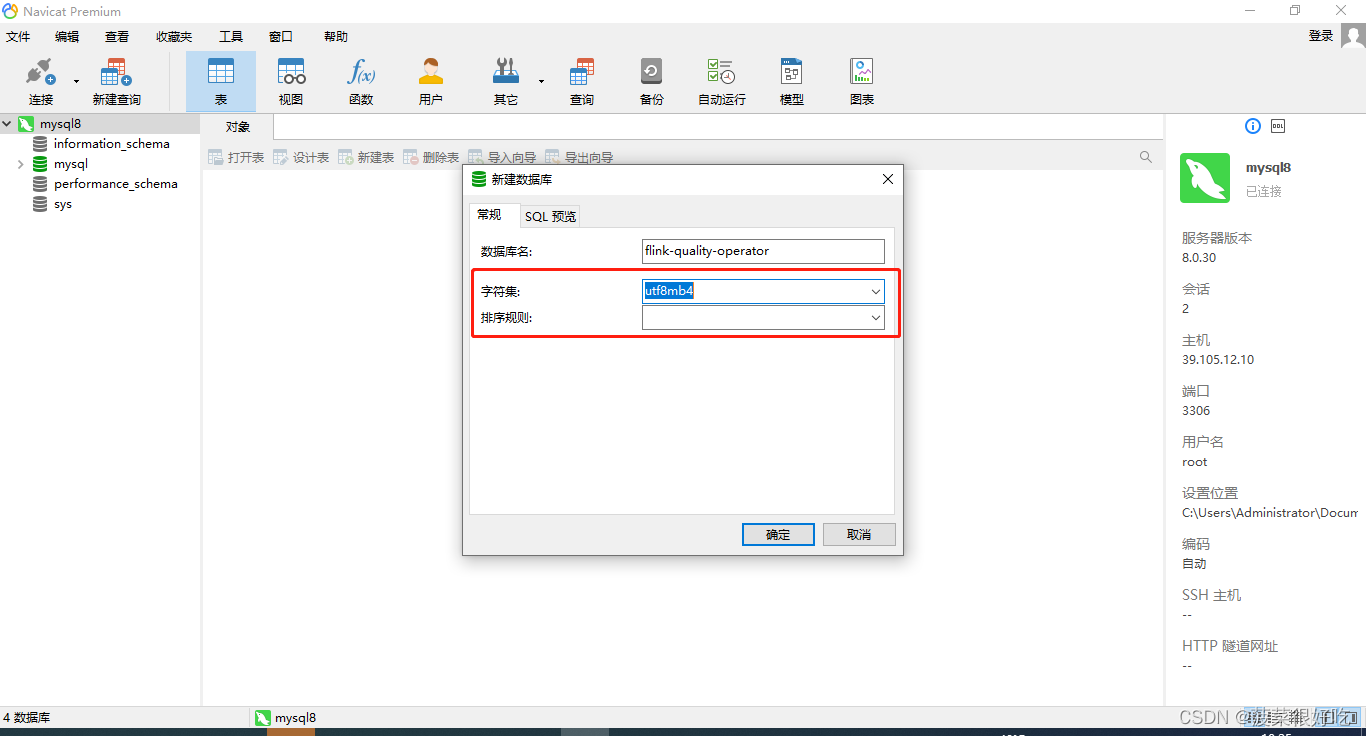
如果不选择的话:MySQL服务器级别的默认字符集和排序规则分别是latin1和latin1_swedish_ci。
一般选择:
或者通过mysqld设置:
$ mysqld --character-set-server=utf8 --collation-server=utf8_general_ci
1、字符集
1.1 字符集作用
符号(symbols)与编码(encoding)的集合
1.2 常用选择
一般选择utf8.下面介绍一下utf8与utf8mb4的区别。
utf8mb4兼容utf8,且比utf8能表示更多的字符。
2、排序规则
2.1 排序规则作用
排序规则指定后,它会影响我们使用 ORDER BY语句查询的结果顺序,会影响到 WHERE条件中大于小于号的筛选结果,会影响 DISTINCT、GROUP BY、HAVING 语句的查询结果。另外,mysql 建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都和排序规则有关。
2.2 常用选择
一般选择utf8_general_ci
mysql8使用客户端只能选择:utf8mb4_general_ci
二、新建表
1、字符串类型
1.1 CHAR 和 VARCHAR 的定义
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,N 表示的是字符,而不是字节。VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字符。
绝大部分场景使用类型 VARCHAR 就足够了。
1.2 字符占用
mysql 在新增varchar类型字段时,默认长度为255。
varchar 长度小于255时,需要额外使用1字节存储长度,大于255时,需要额外使用2字节存储长度。
varchar 栏位如果不定义not null 时,默认null也需要占1字节
- lantin1字符集存储的每个值占1字节
- gbk字符集存储的每个值占2字节
- utf8字符集存储的每个值占3字节
三、常用基础知识
1、什么是方言?
SQL 方言和我们日常生活的方言很类似,如果是学习,鸡仔建议学适用性广的,比如我们日常生活中的普通话。
2、SQL书写规范
1.sql的一条语句可以在一行上编写,中间也可以换行
2.sql语句的结束符是;
3.sql语句关键词不区分大小写
3、SQL分类
1)DDL (data definition language 数据定义语言)
主要的命令有alter、create、drop、truncate,ddl主要用在定义或者改变表的结构。
2)DML (data manipulation language 数据操纵语言)
dml英文缩写是data manipulation language(数据操纵语言),主要的命令有select、update、delete、insert,dml主要用来操作数据库中的数据
3)DCL (data control language 数据控制语言)
主要的命令有grant、deny、revoke等,dcl主要用来设置或者更新数据库用户或者角色权限
4)TCL (Transaction Control language 事务控制语言 )
主要的作用是用来控制事务的,常用的关键字有commit、rollback、setpoint等
4、常用的数据类型
1). 字符型数据:
char\varchar\text
这几种数据类型都是用来装字符串的
char 固定长度存储数据
varcahr 按变长存储数据
text 当你需要存储非常大量的字符串时使用
nchar、nvarchar、ntext
这几个也是存储字符串的,与上面的对应相同。唯一不同的是这三种类型,是采用Unicode编码,当你做国际化的网站时使用
2). 日期时间型数据
datetime、smalldatetime
都是用于存储日期和时间信息
datetime:存放1/1/1753-12/31/9999的时间数据,精确到0.001s
smalldatetime: 存放1/1/1900-6/6/2079的时间,精确到秒
3). 整数型数据
用于存放整数
bigint、int、smallint、tinyint
bigint 从 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字)。
int 从 -2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,647) 的整型数据(所有数字)。
smallint 从 -2^15 (-32,768) 到 2^15 - 1 (32,767) 的整数数据。
tinyint 从 0 到 255 的整数数据。
4). 精确小数型数据
用于存放小数
decimal、numeric
5). 近似数值类型
用于存放近似数
float、real
6). 货币型数据
用于存放货币数据
money、smallmoney
在输入货币型数据时要在其前加货币符号,若为负值,则在货币符号后加符号
7). 位类型数据
bit
这个刚学不好理解,我给你打个比方吧。比如你的表中有一列放性别,性别只有两种可能性,不是男就是女。这时你就可以把性别这列的数据类型设为bit。凡是与之类似的情况都可以用bit类型数据。
5、常用sql语句
1)操作数据库
1.1) 创建数据库
-- 最最常用的方式
create database 数据库名字;
-- 例如:
create database day01;
-- 了解的方式,当数据库不存在的时候才创建
create dababase if not exists 数据库名;
-- 了解的方式,创建数据库的时候,指定字符集
create database 数据库名 character set gbk;
1.2) 修改数据库
-- 修改数据库的字符集
alter database 数据库名字 character set 新的字符集;
-- 例如:
alter database day03 character set utf8;
1.3)删除数据库
-- 格式:
drop database 数据库名字;
-- 例如:
drop database day03;
1.4) 其他常用
-- 查看某个数据库的建库语句:
show create database 数据库名;
-- 查看全部数据库:
show databases;
-- 使用或者切换数据库 :
use 数据库名字;
-- 查看当前工作在那个数据库下 :
select database();
2)操作表
2.1) 创建表
-- 格式:
create table 表名(
字段1名字 字段1数据类型,
字段2名字 字段2数据类型
);
-- 例如:
create table user(
id int,
name varchar(8)
);
-- 创建一张和user表结构一模一样的表
create table 新表名 like 表名;
-- 例如 :
create table user1 like user;
2.2) 创建表修改表
-- 格式:
alter table 表名 操作
-- 往表中添加字段 column可以省略不写 添加一个password字段
alter table user add column password int;
-- 修改表中字段的类型 将password的类型修改为varchar
alter table user modify password varchar(8);
-- 修改表中字段的名字 将password 修改为 pwd
alter table user change password pwd varchar(8);
-- 删除字段 删除pwd字段
alter table user drop pwd;
-- 修改表名 将user1改名为user11
alter table user1 rename to user11;
2.3) 删除表
-- 格式
drop table 表名;
-- 例如:
drop table user11;
2.4) 其他
-- 查看当前库下所有的表 :
show tables;
-- 查询某个表的建表语句 :
show create table 表名;
-- 查看表结构(描述表) :
desc 表名;
3) 操作数据记录
3.1) 添加记录
-- 格式1:给指定的字段赋值
insert into 表名 (字段1,字段2) values (值1,值2);
-- 格式2:给全部字段赋值
insert into 表名 values(值1,值2,...值n);
注意事项:
1.给指定字段赋值的时候,前面括号中有几个字段,后面括号中就有几个值 .且数据类型也要对应上
2.给全部字段赋值的时候,value中值的顺序要和表结构中的字段的顺序一致.且数据类型也要对应上
3.插入数据的时候应该使用引号将值引起来.建议使用'' ,若值的类型为数字的话,引号可以省略不写.
-- 先给user表添加字段
alter table user add money double(5,2);
alter table user add sex varchar(1);
alter table user add birthday date;
-- 插入值
insert into user(id,name) values('1','tom');
insert into user values (2,'jack',900,'男','1999-12-12');
-- 常见错误
insert into user values(4,jerry,'100','男','1990-09-09');
insert into user values(4,'jerry','100','男');
insert into user (id,name,sex) values(4,'jerry','男人');
insert into user (id,name,money) values(4,'jerry',1000);
insert into user (id,name) values ('jerry',4);
insert into user(id,name) valua(4,'jerry');
3.2) 修改记录
-- 格式1:修改全部记录
update 表名 set 字段1=值1,字段2=值2 ;
-- 格式2:按条件修改记录
update 表名 set 字段1=值1,字段2=值2 where 条件语句;
-- 例如:
update user set sex='女',birthday='2000-01-01';
update user set sex='男',birthday='1999-12-31' where id = 2;
3.3) 删除记录
-- 格式1:删除全部记录
delete from 表名;
-- 格式2:删除满足条件的记录
delete from 表名 where 条件语句;
-- 例如:
-- 创建一张和user结构一模一样的表user1,然后将user表中的记录插入到新的表中
create table user1 like user;
insert into user1 select * from user;-- 蠕虫复制
-- 清空user1表中的记录
delete from user1;
-- 删除user表中id=1的记录
delete from user where id = 1;
3.4) 查询记录
3.4.1) 基本查询
-- 基本查询格式
select * from 表名;-- 查询全部的字段
select 字段1,字段2 from 表名;-- 查询指定的字段
-- 数据准备
-- 创建表
create table stu(
id int,
name varchar(20),
chinese double,
english double,
math double
);
-- 插入记录
insert into stu(id,name,chinese,english,math) values(1,'tom',89,78,90);
insert into stu(id,name,chinese,english,math) values(2,'jack',67,98,56);
insert into stu(id,name,chinese,english,math) values(3,'jerry',87,78,77);
insert into stu(id,name,chinese,english,math) values(4,'lucy',88,NULL,90);
insert into stu(id,name,chinese,english,math) values(5,'james',82,84,77);
insert into stu(id,name,chinese,english,math) values(6,'jack',55,85,45);
insert into stu(id,name,chinese,english,math) values(7,'tom',89,65,30);
-- 查询表中所有学生的信息
-- 查询表中所有学生的姓名和对应的语文成绩
-- 查询表中学生姓名(去重)
-- 在查询的所有学生数学分数上加10分特长分
-- 统计每个学生的总分
-- 使用别名表示学生总分
-- 查询表中所有学生的信息
SELECT * FROM stu;
-- 查询表中所有学生的姓名和对应的语文成绩
SELECT NAME,chinese FROM stu;
-- 查询表中学生姓名(去重)
-- 使用distinct去掉重复
-- select distinct 字段,字段 from 表名;当distinct后面所有的字段值都一样的才会去掉重复值
SELECT DISTINCT NAME FROM stu;-- 5条
SELECT DISTINCT NAME,chinese FROM stu;-- 6条
-- 在查询的所有学生数学分数上加10分特长分
-- 我们可以在查询的结果上进行运算,不影响原来数据
SELECT NAME,math,math+10 FROM stu;
-- 统计每个学生的总分
-- null和其他数据进行运算的时候结果还是null
SELECT NAME,chinese+math+english FROM stu;
-- 我们可以使用ifnull函数进行处理
-- ifnull(表达式1,表达式2) 当表达式1的结果为null时,按表达式2的结果处理
SELECT NAME,chinese+math+IFNULL(english,0) FROM stu;
-- 使用别名表示学生总分
-- 给查询的字段起别名
-- 格式 : 显示的字段名 [as] 别名
SELECT NAME,chinese+math+IFNULL(english,0) AS 总分 FROM stu;
SELECT NAME,chinese+math+IFNULL(english,0) '总 分' FROM stu;
SELECT NAME,chinese+math+IFNULL(english,0) "总 分" FROM stu;
SELECT NAME,chinese+math+IFNULL(english,0) `总 分` FROM stu;
3.4.2) 条件查询
-- 基本格式
select *|字段 from 表名 where 条件语句;
条件语句支持:关系运算符,逻辑运算符,模糊查询等.
-- 数据准备
CREATE TABLE student (
id int,
name varchar(20),
age int,
sex varchar(5),
address varchar(100),
math int,
english int
);
-- 插入记录
INSERT INTO student(id,NAME,age,sex,address,math,english) VALUES
(1,'马云',55,'男','杭州',66,78),
(2,'马化腾',45,'女','深圳',98,87),
(3,'马景涛',55,'男','香港',56,77),
(4,'柳岩',20,'女','湖南',76,65),
(5,'柳青',20,'男','湖南',86,NULL),
(6,'刘德华',57,'男','香港',99,99),
(7,'马德',22,'女','香港',99,99),
(8,'德玛西亚',18,'男','南京',56,65);
# 关系运算符
-- 查询math分数大于80分的学生
-- 查询english分数小于或等于80分的学生
-- 查询age等于20岁的学生
-- 查询age不等于20岁的学生
# 关系运算符 > < >= <= = != <>
-- 查询math分数大于80分的学生
SELECT * FROM student WHERE math>80;
-- 查询english分数小于或等于80分的学生
SELECT * FROM student WHERE english <= 80;
-- 查询age等于20岁的学生
SELECT * FROM student WHERE age = 20;
-- 查询age不等于20岁的学生
SELECT * FROM student WHERE age != 20;
SELECT * FROM student WHERE age <> 20;
# 逻辑运算符 and(&&) or(||) not(!)
-- 查询age大于35且性别为男的学生(两个条件同时满足)
-- 查询age大于35或性别为男的学生(两个条件其中一个满足)
-- 查询id是1或3或5的学生
-- 使用in关键字再次查询id是1或3或5的学生
-- 查询id不是1或3或5的学生
-- 查询english成绩大于等于77,且小于等于87的学生
-- 查询英语成绩为null的学生
-- 查询age大于35且性别为男的学生(两个条件同时满足)
SELECT * FROM student WHERE age > 35 AND sex = '男';
SELECT * FROM student WHERE age > 35 && sex = '男';
-- 查询age大于35或性别为男的学生(两个条件其中一个满足)
SELECT * FROM student WHERE age > 35 OR sex = '男';
-- 查询id是1或3或5的学生
SELECT * FROM student WHERE id = 1 OR id = 3 OR id = 5;
-- 使用in关键字再次查询id是1或3或5的学生
-- 格式: 字段名 in (值1,值2)
SELECT * FROM student WHERE id IN (1,3,5);
-- 查询id不是 1或3或5的学生
SELECT * FROM student WHERE id != 1 AND id !=3 AND id != 5;
SELECT * FROM student WHERE id NOT IN (1,3,5);
-- 查询english成绩大于等于77,且小于等于87的学生
SELECT * FROM student WHERE english >= 77 AND english <= 87
-- 可以使用 between and 进行范围查询
-- 格式: 字段名 between 较小值 and 较大值
SELECT * FROM student WHERE english BETWEEN 77 AND 87;
-- 查询英语成绩为null的学生
-- 对null的判断处理 is null 或者 is not null
SELECT * FROM student WHERE english IS NULL;
SELECT * FROM student WHERE english IS NOT NULL;
模糊查询,支持以下两种写法
% 匹配任意字符
_ 匹配一个字符
格式
where 字段名 like '匹配规则';
举个栗子:
name like '%马%'; 名字有马
name like '马%'; 姓马
name like '%马'; 名字以马结尾
name like '_马%'; 名字第二个字为马
name like '马'; 等价于 =
# 模糊查询
-- 查询姓马的学生
-- 查询姓名中包含'德'字的学生
-- 查询姓马,且姓名有三个字的学生
-- 查询姓马的学生
SELECT * FROM student WHERE NAME LIKE '马%';
-- 查询姓名中包含'德'字的学生
SELECT * FROM student WHERE NAME LIKE '%德%';
-- 查询姓马,且姓名有三个字的学生
SELECT * FROM student WHERE NAME LIKE '马__';
3.4.3) 排序
-- 格式1:
select * from 表 [where 条件] order by 排序字段名 排序方式;
-- 格式2:
select * from 表 [where 条件] order by 主排序字段名 排序方式 ,次排序字段名 排序方式;
-- 排序方式: asc(升序,默认值)和desc(降序)
# 排序
-- 查询所有数据,使用年龄降序排序
-- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩降序排序
-- 查询所有数据,使用年龄降序排序
SELECT * FROM student ORDER BY age DESC;
-- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩降序排序
SELECT * FROM student ORDER BY age DESC,math DESC;
3.4.4) 聚合函数
对字段(列)进行统计,会自动忽略null,不能跟在where后
count(字段名):计数
sum(字段名):求和
max(字段名):最大值
min(字段名):最小值
avg(字段名):平均值
# 聚合函数
-- 查询学生总数(null值处理)
-- 查询年龄大于40的总数
-- 查询数学成绩总分
-- 查询数学成绩平均分
-- 查询数学成绩最高分
-- 查询数学成绩最低分
-- 查询学生总数(null值处理)
SELECT COUNT(id) FROM student;-- 8
SELECT COUNT(english) FROM student;-- 7
SELECT COUNT(*) FROM student;
SELECT COUNT(1) FROM student;
-- 查询年龄大于40的总数
SELECT COUNT(1) FROM student WHERE age>40;
-- 查询数学成绩总分
SELECT SUM(math) FROM student;
-- 查询数学成绩平均分
SELECT AVG(math) FROM student;
-- 查询数学成绩最高分
SELECT MAX(math) FROM student;
-- 查询数学成绩最低分
SELECT MIN(math) FROM student;
3.4.5) 分组
-- 格式
select 分组的字段,聚合函数,聚合函数2 from 表名 [where 分组前的筛选条件] group by 分组字段 [having 分组后的条件筛选]
-- 查询男女各多少人
-- 查询年龄大于25岁的人,按性别分组,统计每组的人数
-- 查询年龄大于25岁的人,按性别分组,统计每组的人数,并只显示性别人数大于2的数据
-- 查询男女各多少人
SELECT COUNT(1) FROM student WHERE sex = '男';
SELECT COUNT(1) FROM student WHERE sex = '女';
SELECT sex,COUNT(1) FROM student GROUP BY sex;
-- 查询年龄大于25岁的人,按性别分组,统计每组的人数
SELECT sex, COUNT(1) FROM student WHERE age > 25 GROUP BY sex;
-- 查询年龄大于25岁的人,按性别分组,统计每组的人数,并只显示性别人数大于2的数据
SELECT sex, COUNT(1) FROM student WHERE age > 25 GROUP BY sex HAVING COUNT(1)>2
SELECT sex, COUNT(1) renshu FROM student WHERE age > 25 GROUP BY sex HAVING renshu>2
where和having区别
where 是对分组前的数据进行筛选,having是对分组后的数据进行筛选
where后面不能使用聚合函数,having后面可以使用聚合函数
3.4.6) 分页
mysql中是通过limit关键字实现的.mysql的方言
格式:
select * | 字段 from 表 [where 条件][group by 字段] [order by 排序字段] limit m,n
m : 开始的索引
n : 向后查询的条数
-- 数据准备
INSERT INTO student(id,NAME,age,sex,address,math,english) VALUES
(9,'唐僧',25,'男','长安',87,78),
(10,'孙悟空',18,'男','花果山',100,66),
(11,'猪八戒',22,'男','高老庄',58,78),
(12,'沙僧',50,'男','流沙河',77,88),
(13,'白骨精',22,'女','白虎岭',66,66),
(14,'蜘蛛精',23,'女','盘丝洞',88,88);
-- 查询学生表中数据,从第三条开始显示,显示6条
-- 查询学生表中数据,显示前6条
-- 模拟百度分页,一页显示5条
-- 查询学生表中数据,从第三条开始显示,显示6条
SELECT * FROM student LIMIT 2,6;
-- 查询学生表中数据,显示前6条
SELECT * FROM student LIMIT 0,6;
SELECT * FROM student LIMIT 6;
-- 模拟百度分页,一页显示5条
SELECT * FROM student LIMIT 0,5;
SELECT * FROM student LIMIT 5,5;
SELECT * FROM student LIMIT 10,5;
开始的索引的规律:
(页码-1)*每页显示的条数
4) 数据库约束
4.1) 概述
4.1.1) 作用
对表中的数据进行限定,保证数据的正确性、有效性和完整性。
4.1.2) 约束有哪些:
★主键约束:一条记录的唯一标识
唯一约束:字段在该列中唯一
非空约束:字段不能为null
外键约束:多表关系才用
默认值:在不具体指定数据的时候使用的值就是默认值
4.2) 实现
4.2.1) 主键约束
作用:限定某一列的值非空且唯一, 主键就是表中记录的唯一标识。
一张表中只能有一个主键.但是主键可以修饰多个字段.
主键的分类:
- 自然主键:使用实体中一个有具体业务含义的字段作为主键.例如:身份证号,手机号
- 代理主键:使用实体中没有具体业务含义的字段作为主键.一般会在每张表中引入一个id字段作为主键.
方式1:在建表的时候,在字段名后面通过primary key 声明
方式2:在建表的时候,在约束区域通过primary key 声明
方式3:通过修改表结构,添加主键约束
方式1:在建表的时候,在字段名后面通过primary key 声明
create table pk1(
id int primary key,
name varchar(8)
);
insert into pk1 values(1,'tom');-- 成功
insert into pk1 values(1,'tom');-- 重复输入1 错误 Duplicate entry '1' for key 'PRIMARY'
insert into pk1 values(null,'tom');-- 不能为空 错误 Column 'id' cannot be null
方式2:在建表的时候,在约束区域通过primary key 声明
create table pk2(
id int,
name varchar(8),
primary key(id)
);
方式3:通过修改表结构,添加主键约束
create table pk3(
id int,
name varchar(8)
);
alter table pk3 add primary key (id);
扩展:用name和sex作为主键
create table pk4(
id int,
name varchar(8),
sex varchar(1),
primary key(name,sex) -- 联合主键 也可以使用方式3添加主键
);
insert into pk4 values (1,'tom','男');-- 成功
insert into pk4 values (1,'tom','男');-- 失败
insert into pk4 values (1,'tom','女');-- 成功
insert into pk4 values (1,null,'女');-- 失败
小结:以后建表的时候务必给表加上主键.
4.2.2) 唯一约束
作用:限定某一列中的值不能重复,对null不其作用
方式1:在建表的时候,在字段名后面通过unique 声明
方式2:在建表的时候,在约束区域通过unique 声明
方式3:通过修改表结构,添加unique 约束
方式1:在建表的时候,在字段名后面通过unique 声明
create table un1(
id int,
username varchar(8) unique
);
insert into un1 values(1,'tom');-- 成功
insert into un1 values(1,'tom');-- 失败
insert into un1 values(1,null);-- 成功
方式2:在建表的时候,在约束区域通过unique 声明
create table un2(
id int,
username varchar(8),
unique(username)
);
方式3:通过修改表结构,添加unique 约束
create table un3(
id int,
username varchar(8)
);
alter table un3 add unique(username);
小结:唯一约束也可以使用java代码保证数据的唯一性.
4.2.3) 非空约束
作用:限定某一列的值不能为null
方式:在建表的时候,在字段名后面通过not null声明
create table nn(
id int,
username varchar(8) not null
);
insert into nn values(1,null);-- 失败
4.2.4) 默认值
作用:限定某一列的默认值,再没有指定的情况下所有列的默认值为null
格式 : 字段名 字段类型 default ‘默认值’
当我们给表中插入或者修改数据的时候,若没有明确给字段设置值,就会使用默认值
create table person(
id int,
name varchar(8),
country varchar(64) default '中国'
);
insert into person values(1,'韩梅梅',null);
insert into person(id,name) values(2,'李雷');
扩展 : 时间戳,timestamp,在添加或者修改的时候若没有给设置值,就让其使用系统的当前时间
ALTER TABLE person ADD update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
四、数据库设计原则
(持续更新中。。。)