🚀欢迎来到本文🚀
🍉个人简介:陈童学哦,目前学习C/C++、算法、Python、Java等方向,一个正在慢慢前行的普通人。
🏀系列专栏:陈童学的日记
💡其他专栏:C++STL,感兴趣的小伙伴可以看看。
🎁希望各位→点赞👍 + 收藏⭐️ + 留言📝
⛱️万物从心起,心动则万物动🏄♂️

4个维度讲透ChatGPT技术原理,揭开ChatGPT神秘技术黑盒!
- 写在前面
- 1.Tansformer架构模型
- 2.ChatGPT原理
- 3.提示学习与大模型能力的涌现
- 3.1提示学习
- 3.2上下文学习
- 3.3思维链
- 4.行业参考建议
- 4.1拥抱变化
- 4.2定位清晰
- 4.3合规可控
- 4.4经验沉淀
- 写在最后
写在前面
2022年11月30日,ChatGPT模型问世后,立刻在全球范围内掀起了轩然大波。无论AI从业者还是非从业者,都在热议ChatGPT极具冲击力的交互体验和惊人的生成内容。这使得广大群众重新认识到人工智能的潜力和价值。对于AI从业者来说,ChatGPT模型成为一种思路的扩充,大模型不再是刷榜的玩具,所有人都认识到高质量数据的重要性,并坚信“有多少人工,就会有多少智能”。
ChatGPT模型效果过于优秀,在许多任务上,即使是零样本或少样本数据也可以达到SOTA效果,使得很多人转向大模型的研究。
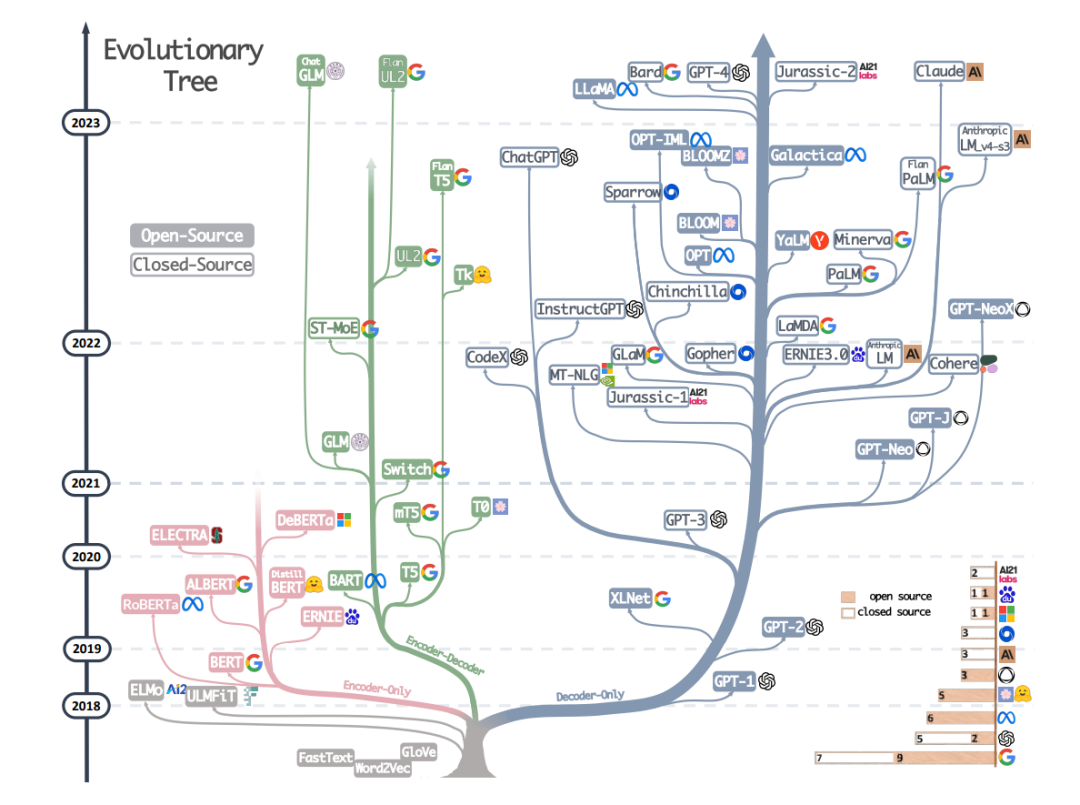
不仅Google提出了对标ChatGPT的Bard模型,国内涌现出了许多中文大模型,如百度的“文心一言”、阿里的“通义千问”、商汤的“日日新”、知乎的“知海图AI”、清华智谱的“ChatGLM”、复旦的“MOSS”、Meta的“Llama1&Llama2”等等。
Alpaca模型问世之后,证明了70亿参数量的模型虽然达不到ChatGPT的效果,但已经极大程度上降低了大模型的算力成本,使得普通用户和一般企业也可以使用大模型。之前一直强调的数据问题,可以通过GPT-3.5或GPT-4接口来获取数据,并且数据质量也相当高。如果只需要基本的效果模型,数据是否再次精标已经不是那么重要了(当然,要获得更好的效果,则需要更精准的数据)。
1.Tansformer架构模型
预训练语言模型的本质是通过从海量数据中学到语言的通用表达,使得在下游子任务中可以获得更优异的结果。随着模型参数不断增加,很多预训练语言模型又被称为大型语言模型(Large Language Model,LLM)。不同人对于“大”的定义不同,很难说多少参数量的模型是大型语言模型,通常并不强行区分预训练语言模型和大型语言模型之间的差别。
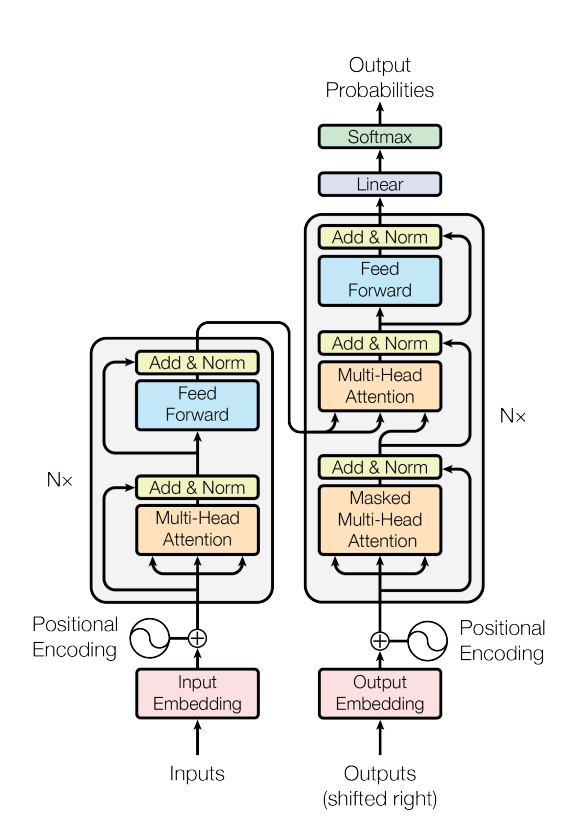
预训练语言模型根据底层模型网络结构,一般分为仅Encoder架构模型、仅Decoder架构模型和Encoder-Decoder架构模型。其中,仅Encoder架构模型包括但不限于BERT、RoBerta、Ernie、SpanBert、AlBert等;仅Decoder架构模型包括但不限于GPT、CPM、PaLM、OPT、Bloom、Llama等;Encoder-Decoder架构模型包括但不限于Mass、Bart、T5等。
2.ChatGPT原理
ChatGPT训练的整体流程主要分为3个阶段,预训练与提示学习阶段,结果评价与奖励建模阶段以及强化学习自我进化阶段;3个阶段分工明确,实现了模型从模仿期、管教期、自主期的阶段转变。
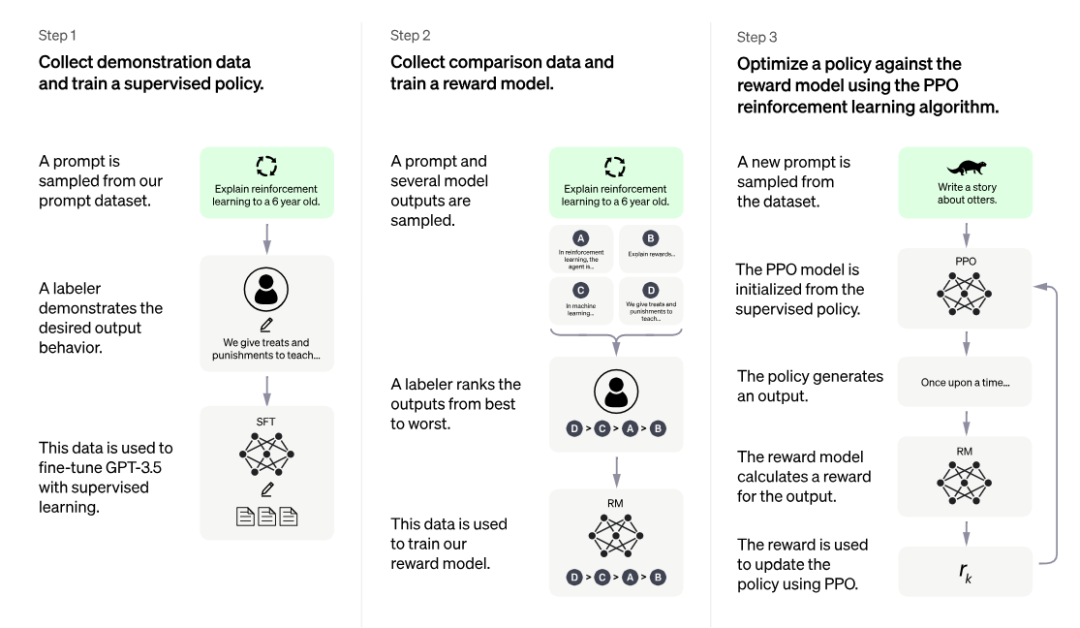
在第一阶段的模仿期,模型将重点放在学习各项指令型任务中,这个阶段的模型没有自我判别意识,更多的是模仿人工行为的过程,通过不断学习人类标注结果让其行为本身具有一定的智能型。然而仅仅是模仿往往会让机器的学习行为变成邯郸学步。
在第二阶段的管教期,优化内容发生了方向性转变,将重点从教育机器答案内容改变为教育机器答案的好坏。如果第一阶段,重点希望机器利用输入X,模仿学习输出Y’,并力求让Y’与原先标注的Y保持一致。那么,在第二阶段,重点则希望多个模型在针对X输出多个结果(Y1,Y2,Y3,Y4)时,可以自行判断多个结果的优劣情况。
当模型具备一定的判断能力时,认为该模型已经完成第二阶段的学习,可以进入第三阶段——自主期。在自主期的模型,需要通过左右互博的方式完成自我进化,即一方面自动生成多个输出结果,另一方面判断不同结果的优劣程度,并基于不同输出的效果模型差异评估,优化改进自动生成过程的模型参数,进而完成模型的自我强化学习。
总结来说,也可以将ChatGPT的3个阶段比喻为人成长的3个阶段,模仿期的目的是“知天理”,管教期的目的是“辨是非”,自主期的目的是“格万物”。
3.提示学习与大模型能力的涌现
ChatGPT模型发布后,因其流畅的对话表达、极强的上下文存储、丰富的知识创作及其全面解决问题的能力而风靡全球,刷新了大众对人工智能的认知。提示学习(Prompt Learning)、上下文学习(In-Context Learning)、思维链(Chain of Thought,CoT)等概念也随之进入大众视野。市面上甚至出现了提示工程师这个职业,专门为指定任务编写提示模板。
提示学习被广大学者认为是自然语言处理在特征工程、深度学习、预训练+微调之后的第四范式。随着语言模型的参数不断增加,模型也涌现了上下文学习、思维链等能力,在不训练语言模型参数的前提下,仅通过几个演示示例就可以在很多自然语言处理任务上取得较好的成绩。
3.1提示学习
提示学习是在原始输入文本上附加额外的提示(Prompt)信息作为新的输入,将下游的预测任务转化为语言模型任务,并将语言模型的预测结果转化为原本下游任务的预测结果。
以情感分析任务为例,原始任务是根据给定输入文本“我爱中国”,判断该段文本的情感极性。提示学习则是在原始输入文本“我爱中国”上增加额外的提示模板,例如:“这句话的情感为{mask}。”得到新的输入文本“我爱中国。这句话的情感为{mask}。”然后利用语言模型的掩码语言模型任务,针对{mask}标记进行预测,再将其预测出的Token映射到情感极性标签上,最终实现情感极性预测。
3.2上下文学习
上下文学习可以看作提示学习的一种特殊情况,即演示示例看作提示学习中人工编写提示模板(离散型提示模板)的一部分,并且不进行模型参数的更新。
上下文学习的核心思想是通过类比来学习。对于一个情感分类任务来说,首先从已存在的情感分析样本库中抽取出部分演示示例,包含一些正向或负向的情感文本及对应标签;然后将其演示示例与待分析的情感文本进行拼接,送入到大型语言模型中;最终通过对演示示例的学习类比得出文本的情感极性。
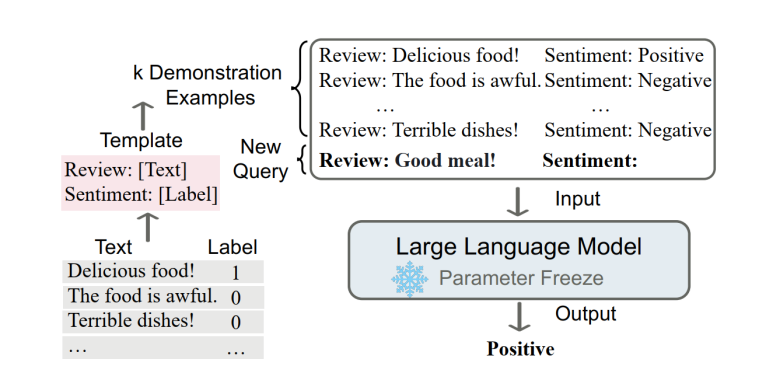
这种学习方法也更加贴近人类学习后进行决策过程,通过观察别人对某些事件的处理方法,当自己遇到相同或类似事件时,可以轻松地并很好地解决。
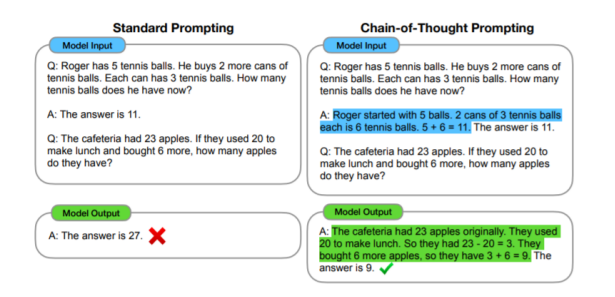
3.3思维链
大型语言模型横行的时代,它彻底改变了自然语言处理的模式。随着模型参数的增加,例如:情感分析、主题分类等系统-1任务(人类可以快速直观地完成的任务),即使是在少样本和零样本条件下均可以获得较好的效果。但对于系统-2任务(人类需要缓慢而深思熟虑的思考才能完成的任务),例如:逻辑推理、数学推理和常识推理等任务,即使模型参数增加到数千亿时,效果也并不理想,也就是简单地增加模型参数量并不能带来实质性的性能提升。
Google于2022年提出了思维链(Chain of thought,CoT)的概念,来提高大型语言模型执行各种推理任务的能力。思维链本质上是一种离散式提示模板,主旨是通过提示模板使得大型语言模型可以模仿人类思考的过程,给出逐步的推理依据,来推导出最终的答案,而每一步的推理依据组成的句子集合就是思维链的内容。
思维链其实是帮助大型语言模型将一个多步问题分解为多个可以被单独解答的中间步骤,而不是在一次向前传递中解决整个多跳问题。
4.行业参考建议
4.1拥抱变化
与其他领域不同,AIGC领域是当前变化最迅速的领域之一。以2023年3月13日至2023年3月19日这一周为例,我们经历了清华发布ChatGLM 6B开源模型、openAI将GPT4接口发布、百度文心一言举办发布会、微软推出Office同ChatGPT相结合的全新产品Copilot等一系列重大事件。
这些事件都会影响行业研究方向,并引发更多思考,例如,下一步技术路线是基于开源模型,还是从头预训练新模型,参数量应该设计多少?Copilot已经做好,办公插件AIGC的应用开发者如何应对?
即便如此,仍建议从业者拥抱变化,快速调整策略,借助前沿资源,以加速实现自身任务。
4.2定位清晰
一定要明确自身细分赛道的目标,例如是做应用层还是底座优化层,是做C端市场还是B端市场,是做行业垂类应用还是通用工具软件。千万不要好高骛远,把握住风口,“切准蛋糕”。
定位清晰并不是指不撞南墙不回,更多的是明白自身目的及意义所在。
4.3合规可控
AIGC最大的问题在于输出的不可控性,如果无法解决这个问题,它的发展将面临很大的瓶颈,无法在B端和C端市场广泛使用。在产品设计过程中,需要关注如何融合规则引擎、强化奖惩机制以及适当的人工介入。从业者应重点关注AIGC生成内容所涉及的版权、道德和法律风险。
4.4经验沉淀
经验沉淀的目的是为了建立自身的壁垒。不要将所有的希望寄托于单个模型上,例如我们曾经将产品设计成纯文本格式,以便同ChatGPT无缝结合,但最新的GPT4已经支持多模态输入。我们不应气!馁,而是要快速拥抱变化,并利用之前积累的经验(数据维度、Prompt维度、交互设计维度)快速完成产品升级,以更好地应对全新的场景和交互形态。
写在最后
虽然AIGC的浪潮下存在不少泡沫,但只要我们怀揣着拥抱变化的决心,始终明确我们要到达的远方,认真面对周围的风险危机,不断在实战中锻炼自身的能力,相信终有一天,会到达我们心中所向往的目的地。

推荐语:
BAT资深AI专家和大模型技术专家撰写,MOSS系统负责人邱锡鹏等多位专家鼎力推荐!系统梳理并深入解析ChatGPT的核心技术、算法实现、工作原理、训练方法,提供大量代码及注解。它山之石,可以攻玉,不仅教你如何实现大模型的迁移和私有化,而且手把手教你零基础搭建自己专属的ChatGPT!