目录
- 1.什么是 Fork/Join 框架?
- 2.什么是工作窃取算法?它有什么作用?有什么优缺点?
- 3.如何设计一个 Fork/Join 框架?
- 4.如何使用 Fork/Join 框架?
- 5.Fork/Join 框架的实现原理是什么?
- 5.1.ForkJoinTask
- 5.1.1.fork() 方法
- 5.1.2.join() 方法
- 5.1.3.RecursiveAction 和 RecursiveTask
- 5.2.ForkJoinPool
- 6.Fork/Join 框架中如何处理异常?
参考
《Java 并发编程的艺术》
《深入浅出 Java 多线程》
1.什么是 Fork/Join 框架?
(1)Fork/Join 框架是 Java 7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
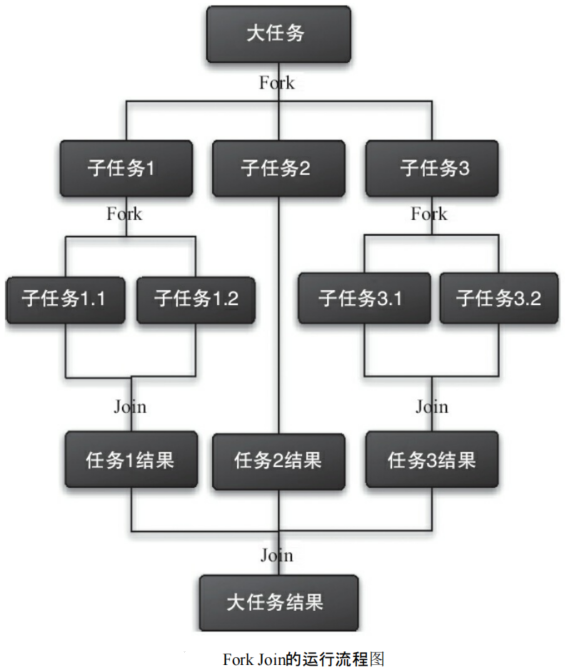
(2)下面通过 Fork 和 Join 这两个单词来理解一下 Fork/Join 框架。Fork 就是把一个大任务切分为若干子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算 1 + 2 + … + 10000,可以分割成 10 个子任务,每个子任务分别对 1000 个数进行求和,最终汇总这 10 个子任务的结果。Fork/Join 的运行流程如下图所示。
2.什么是工作窃取算法?它有什么作用?有什么优缺点?
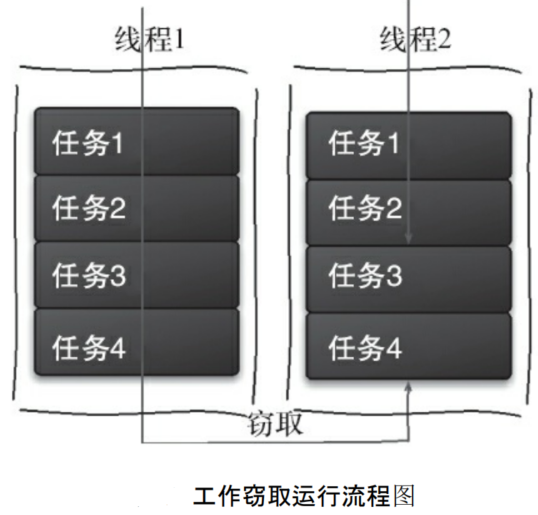
(1)工作窃取 (work-stealing) 算法是指某个线程从其他队列里窃取任务来执行。
(2)那么,为什么需要使用工作窃取算法呢?
- 假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。
- 比如 A 线程负责处理 A 队列里的任务。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。
- 干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。
- 而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。工作窃取的运行流程如下图所示。
工作窃取算法的作用包括:
- 负载均衡:工作窃取算法通过动态地将任务从繁忙线程中偷取来平衡工作负载,确保所有的线程都得到充分利用,从而提高系统的整体性能。
- 减少线程间的竞争:传统的任务调度方式可能导致线程之间竞争共享资源,如锁或队列。而工作窃取算法避免了线程之间的竞争,每个线程都独立地处理自己的任务。
- 提高任务的局部性:由于工作线程从末尾偷取任务,有利于任务的局部性。当线程执行一部分任务时,它会自然地倾向于继续执行与这些任务相关的任务,从而提高缓存的命中率和性能。
(3)工作窃取算法优缺点如下:
- 优点:充分利用线程进行并行计算,减少了线程间的竞争。
- 缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
3.如何设计一个 Fork/Join 框架?
(1)设计一个 Fork/Join 框架的大致步骤如下:
- 步骤 1,分割任务。首先我们需要有一个 fork 类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停地分割,直到分割出的子任务足够小。
- 步骤 2,执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
(2)Fork/Join 使用两个类来完成以上两件事情:
ForkJoinTask:我们要使用 Fork/Join 框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制。通常情况下,我们不需要直接继承 ForkJoinTask 类,只需要继承它的子类,Fork/Join 框架提供了以下两个子类:RecursiveAction:用于没有返回结果的任务。RecursiveTask:用于有返回结果的任务。
ForkJoinPool:ForkJoinTask 需要通过 ForkJoinPool 来执行。任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
4.如何使用 Fork/Join 框架?
(1)上面我们说 ForkJoinPool 负责管理线程和任务,ForkJoinTask 实现 fork 和 join 操作, 所以要使用 Fork/Join 框架就离不开这两个类了,只是在实际开发中我们常用 ForkJoinTask 的子类 RecursiveTask 和 RecursiveAction 来替代 ForkJoinTask。
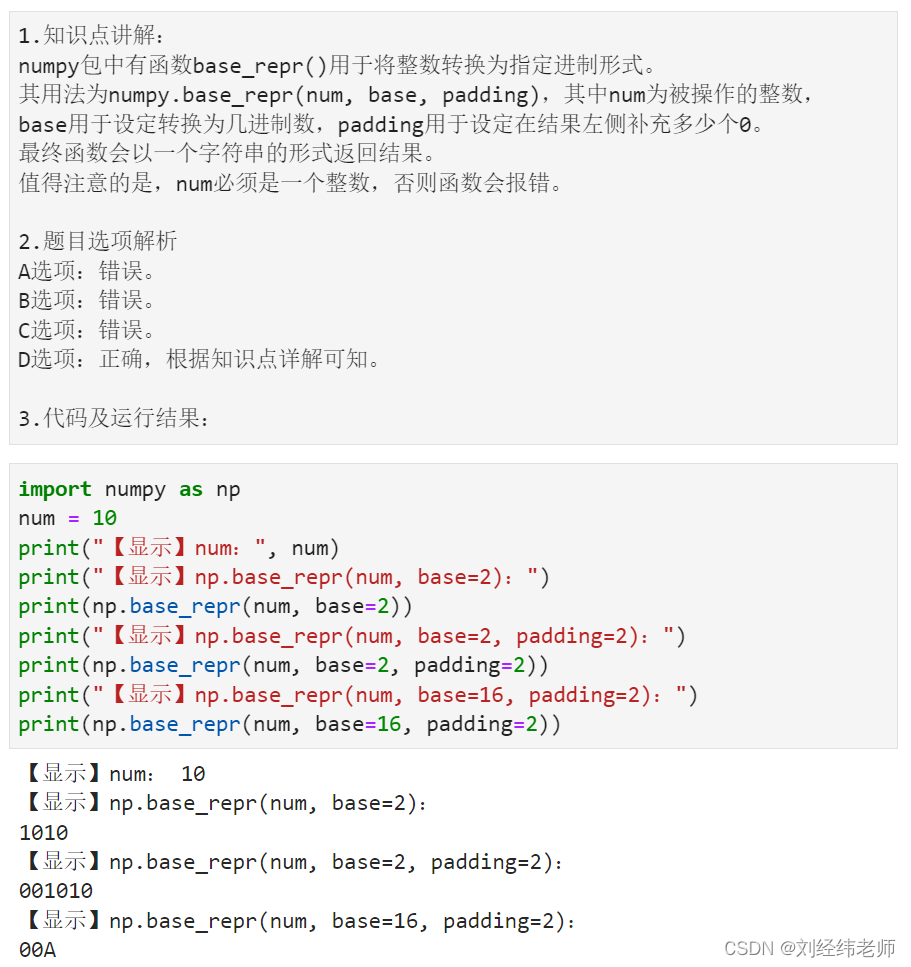
(2)下面我们用⼀个计算斐波那契数列第 n 项的例子来看⼀下 Fork/Join 的使用:
斐波那契数列是⼀个线性递推数列,从第三项开始,每⼀项的值都等于 前两项之和:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89······
如果设 f(n) 为该数列的第 n 项(n∈N*),那么有:f(n) = f(n - 1) + f(n - 2)。
public class Fibonacci extends RecursiveTask<Integer> {
int n;
public Fibonacci(int n) {
this.n = n;
}
//主要的实现逻辑都在 compute() 中
@Override
protected Integer compute() {
//假设 n ≥ 0
if (n <= 1) {
return n;
} else {
// f(n - 1)
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
// f(n - 2)
Fibonacci f2 = new Fibonacci(n - 2);
f2.fork();
// f(n) = f(n - 1) + f(n - 2)
return f1.join() + f2.join();
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
System.out.println("CPU 核数:" + Runtime.getRuntime().availableProcessors());
long start = System.currentTimeMillis();
Fibonacci fibonacci = new Fibonacci(40);
Future<Integer> future = forkJoinPool.submit(fibonacci);
System.out.println(future.get());
long end = System.currentTimeMillis();
System.out.println(String.format("耗时 %d 毫秒", end - start));
}
}
结果如下:
CPU 核数:16
102334155
耗时 1846 毫秒
(3)需要注意的是,上述计算时间复杂度为 O(2n) ,随着 n 的增长计算效率会越来越低,这也是上面的例子中 n 不敢取太大的原因。 此外,也并不是所有的任务都适合 Fork/Join 框架,比如上面的例子任务划分过于细小反而体现不出效率,下面我们试试用普通的递归来求 f(n) 的值,看看是不是要比使用 Fork/Join 快:
public class Fibonacci {
public static int plainRecursion(int n) {
if (n == 1 || n == 2) {
return 1;
} else {
return plainRecursion(n - 1) + plainRecursion(n - 2);
}
}
public static void main(String[] args) {
System.out.println("CPU 核数:" + Runtime.getRuntime().availableProcessors());
long start = System.currentTimeMillis();
int result = plainRecursion(40);
long end = System.currentTimeMillis();
System.out.println("计算结果:" + result);
System.out.println(String.format("耗时 %d 毫秒", end - start));
}
}
结果如下:
CPU 核数:16
计算结果:102334155
耗时 192 毫秒
通过输出可以很明显的看出来,使用普通递归的效率都要比使用 Fork/Join 框架要高很多。 这里我们再用另⼀种思路来计算:
public class Fibonacci {
public static int computeFibonacci(int n) {
if (n <= 2) {
return n;
} else {
int first = 1;
int second = 1;
int third = 0;
for (int i = 3; i <= n; i++) {
//第三个数是前两个数之和
third = first + second;
//前两个数右移
first = second;
second = third;
}
return third;
}
}
public static void main(String[] args) {
System.out.println("CPU 核数:" + Runtime.getRuntime().availableProcessors());
long start = System.currentTimeMillis();
int result = computeFibonacci(40);
long end = System.currentTimeMillis();
System.out.println("计算结果:" + result);
System.out.println(String.format("耗时 %d 毫秒", end - start));
}
}
结果如下:
CPU 核数:16
计算结果:102334155
耗时 0 毫秒
这里耗时为 0 不代表没有耗时,是表明这里计算的耗时几乎可以忽略不计,大家可 以在自己的电脑上试试,即使是 n 取大很多量级的数据(注意 int 溢出的问题)耗时也是很短的,或者可以用 System.nanoTime() 统计纳秒的时间。
(4)为什么在这里普通的递归或循环效率更快呢?
因为 Fork/Join 是使用多个线程协作来计算的,所以会有线程通信和线程切换的开销。 如果要计算的任务比较简单(比如案例中的斐波那契数列),那当然是直接使用单线程会更快⼀些。但如果要计算的东西比较复杂,计算机又是多核的情况下,就可以充分利用多核 CPU 来提高计算速度。另外,Java 8 Stream 的并行操作底层就是用到了 Fork/Join 框架。
5.Fork/Join 框架的实现原理是什么?
Fork/Join 框架简单来讲就是对任务的分割与子任务的合并,所以要实现这个框架,先得有任务。在 Fork/Join 框架里提供了抽象类 ForkJoinTask 来实现任务。
5.1.ForkJoinTask
ForkJoinTask 是⼀个类似普通线程的实体,但是比普通线程轻量得多。该类中常见的方法如下:
5.1.1.fork() 方法
fork() 方法使用线程池中的空闲线程异步提交任务。
//本⽂所有代码都引⾃ Java 8
public final ForkJoinTask<V> fork() {
Thread t;
// ForkJoinWorkerThread 是执⾏ ForkJoinTask 的专有线程,由 ForkJoinPool 管理
// 先判断当前线程是否是 ForkJoin 专有线程,如果是,则将任务 push 到当前线程所负责的队列里去
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread) t).workQueue.push(this);
else
// 如果不是则将线程加⼊队列
// 没有显式创建 ForkJoinPool 的时候⾛这⾥,提交任务到默认的 common 线程池中
ForkJoinPool.common.externalPush(this);
return this;
}
其实 fork() 只做了⼀件事,那就是把任务推入当前工作线程的工作队列里。
5.1.2.join() 方法
join() 方法等待处理任务的线程处理完毕,获得返回值。来看下 join() 的源码:
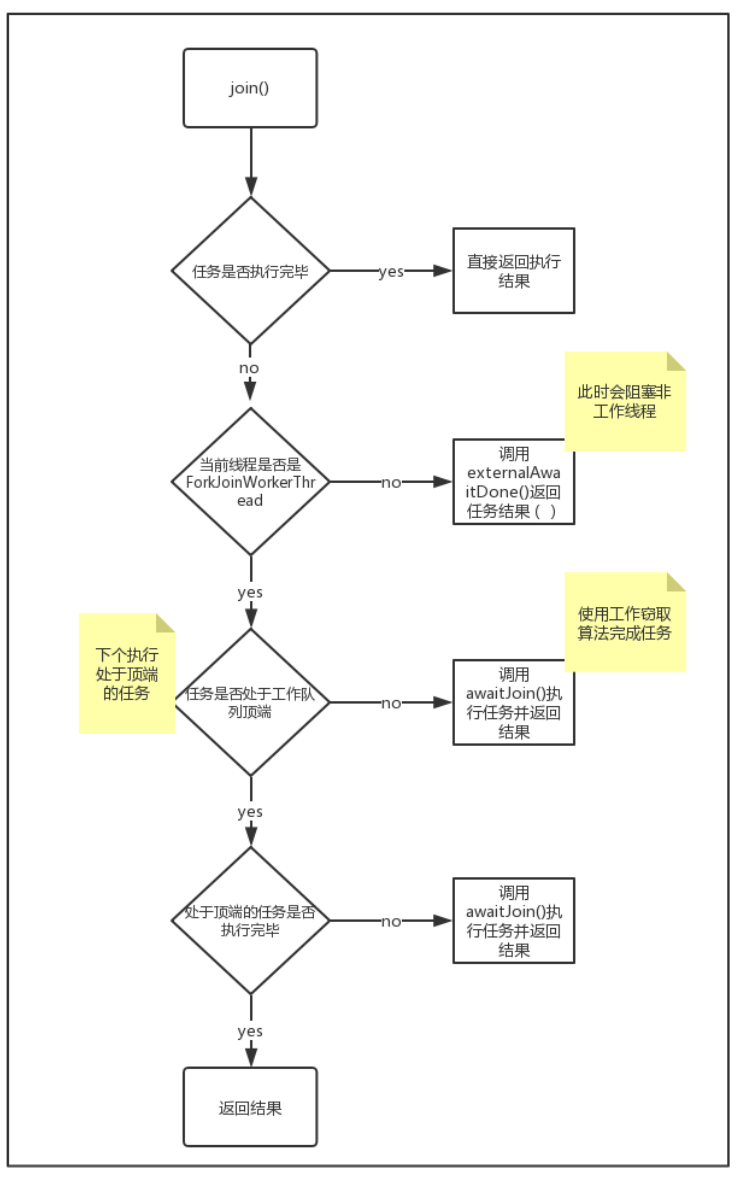
public final V join() {
int s;
// doJoin()方法来获取当前任务的执行状态
if ((s = doJoin() & DONE_MASK) != NORMAL)
// 任务异常,抛出异常
reportException(s);
// 任务正常完成,获取返回值
return getRawResult();
}
/**
* doJoin()方法⽤来返回当前任务的执⾏状态
**/
private int doJoin() {
int s;
Thread t;
ForkJoinWorkerThread wt;
ForkJoinPool.WorkQueue w;
// 先判断任务是否执行完毕,执行完毕直接返回结果(执行状态)
return (s = status) < 0 ? s :
// 如果没有执⾏完毕,先判断是否是ForkJoinWorkThread线程
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
// 如果是,先判断任务是否处于⼯作队列顶端(意味着下⼀个就执行它)
// tryUnpush() 方法判断任务是否处于当前⼯作队列顶端,是返回 true
// doExec() 方法执⾏任务
(w = (wt = (ForkJoinWorkerThread) t).workQueue).
// 如果是处于顶端并且任务执⾏完毕,返回结果
tryUnpush(this) && (s = doExec()) < 0 ? s :
// 如果不在顶端或者在顶端却没未执⾏完毕,那就调⽤ awitJoin() 执行任务
// awaitJoin():使⽤⾃旋使任务执⾏完成,返回结果
wt.pool.awaitJoin(w, this, 0L) :
// 如果不是 ForkJoinWorkThread 线程,执行externalAwaitDone()返回任务结果
externalAwaitDone();
}
我们在之前介绍过说 Thread.join() 会使线程阻塞,而 ForkJoinPool.join() 会使线程免于阻塞,下面是 ForkJoinPool.join() 的流程图:
5.1.3.RecursiveAction 和 RecursiveTask
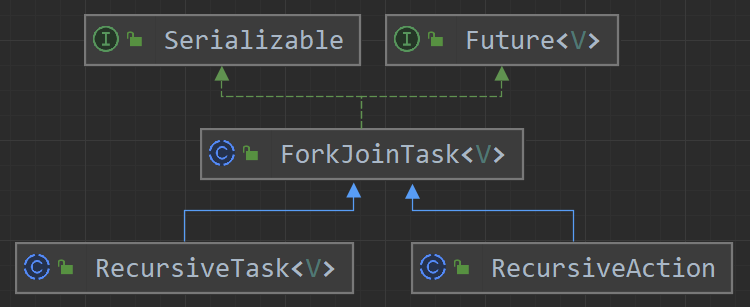
(1)通常情况下,在创建任务的时候我们⼀般不直接继承 ForkJoinTask,而是继承它的子类 RecursiveAction 和 RecursiveTask。
这两个都是 ForkJoinTask 的子类,具体关系如下图所示:
RecursiveAction可以看做是无返回值的 ForkJoinTask;RecursiveTask是有返回值的 ForkJoinTask。
(2)此外,两个子类都有执行主要计算的方法 compute(),当然,RecursiveAction的 compute() 返回 void,RecursiveTask 的 compute() 有具体的返回值。
5.2.ForkJoinPool
(1)ForkJoinPool 是用于执行 ForkJoinTask 任务的执行(线程)池。ForkJoinPool 管理着执行池中的线程和任务队列,此外,执行池是否还接受任务, 显示线程的运行状态也是在这里处理。 我们来大致看下 ForkJoinPool 的源码:
@sun.misc.Contended
public class ForkJoinPool extends AbstractExecutorService {
// 任务队列
volatile WorkQueue[] workQueues;
// 线程的运⾏状态
volatile int runState;
// 创建ForkJoinWorkerThread的默认⼯⼚,可以通过构造函数重写
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThread
// 公⽤的线程池,其运⾏状态不受shutdown()和shutdownNow()的影响
static final ForkJoinPool common;
// 私有构造⽅法,没有任何安全检查和参数校验,由makeCommonPool直接调⽤
// 其他构造⽅法都是源⾃于此⽅法
// parallelism: 并⾏度,
// 默认调⽤java.lang.Runtime.availableProcessors() ⽅法返回可⽤处理器的数量
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory, // ⼯作线程⼯⼚
UncaughtExceptionHandler handler, // 拒绝任务的handler
int mode, // 同步模式
String workerNamePrefix) { // 线程名prefix
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long) (-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK)
}
}
(2)WorkQueue
双端队列,用于存放 ForkJoinTask。 当工作线程在处理自己的工作队列时,会从队列尾取任务来执行(LIFO);如果是窃取其他队列的任务时,窃取的任务位于所属任务队列的队首(FIFO)。ForkJoinPool 与传统线程池最显著的区别就是它维护了⼀个工作队列数组(volatile WorkQueue[] workQueues,ForkJoinPool 中的每个工作线程都维护着⼀个工作队列)。
(3)runState
ForkJoinPool 的运行状态。SHUTDOWN 状态用负数表示,其他用 2 的幂次表示。
6.Fork/Join 框架中如何处理异常?
ForkJoinTask 在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以 ForkJoinTask 提供了isCompletedAbnormally() 方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过 ForkJoinTask 的 getException 方法获取异常。使用如下代码。
if(task.isCompletedAbnormally()) {
System.out.println(task.getException());
}
getException 方法返回 Throwable 对象,如果任务被取消了则返回 CancellationException。如果任务没有完成或者没有抛出异常则返回 null。