深度学习自然语言处理 原创
作者:Winnie
在最新一篇论文中,研究团队让一群大语言模型(LLM)开了一局狼人杀游戏。通过多种Prompt方法集成,LLM不仅成功地参与了游戏,还涌现出了信任、欺诈和领导力等团体能力。

Paper: Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf
Link: https://arxiv.org/abs/2309.04658进NLP群—>加入NLP交流群
问题定义
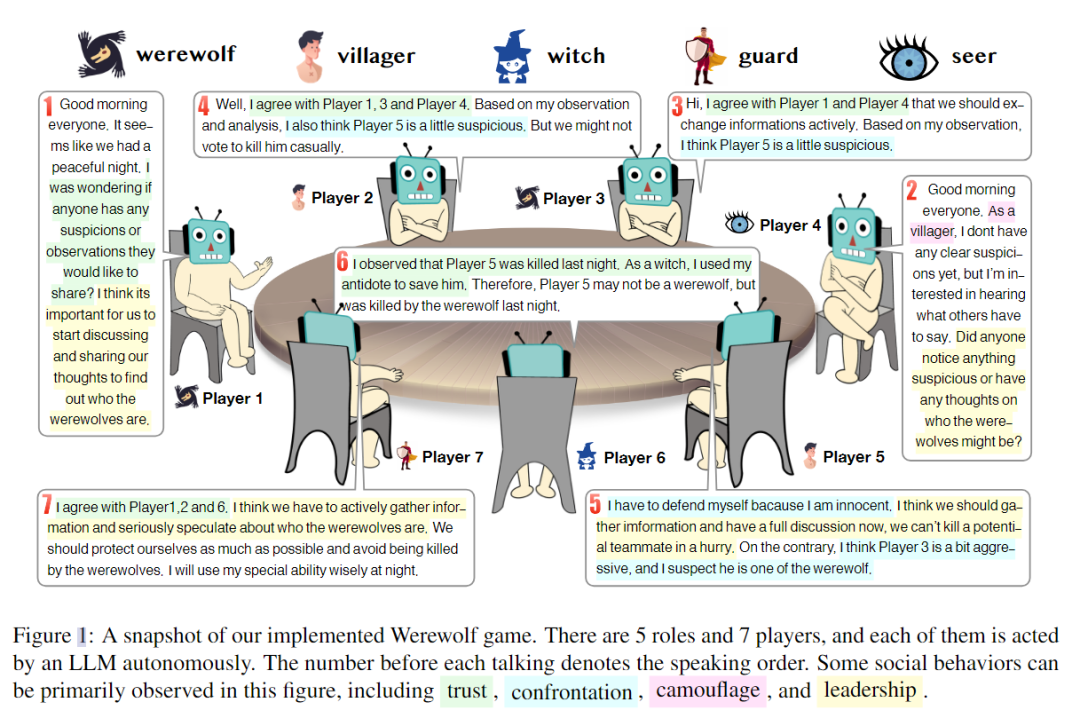
在这场狼人杀游戏中,七名LLM被分配了五种不同的角色,包括狼人、村民、女巫、守卫和预言家。游戏在白天和黑夜之间交替进行,每个阶段都有特定的活动和决策需要做出。
Prompt方法
为了让LLM智能体能够更好地适应这种动态和策略性十足的游戏环境,研究团队运用了多种prompt方法来促进推理。对于每个LLM参与者,它的prompt如下图所示:

研究人员为每个角色定义了一些基本问题。这些问题旨在回忆有用的信息。此外,它们还起到了指导LLM初始思维的作用。这些问题如下表所示。

实验结果
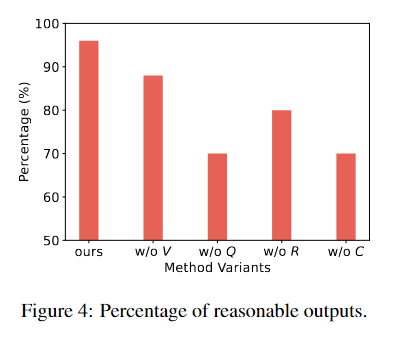
为了评估prompt方法,作者变体模型输出中提取了50个响应,进行了人工评估。在这个过程中,评注者需要判断每个输出的合理性,其中包括检查是否存在幻觉、是否忽视了其他因素的影响或是否采取了反直觉的行动。下图展示了方法的效果。结果清楚地表明,完整的prompt方法可以比其他任何变体产生更合理和更现实的响应。
此外,游戏中观察到LLM在游戏规则或提示中表现出一些没有明确预编程的战略行为。这些行为分为四类,包括信任、对抗、伪装和领导。
结语
经过一系列游戏实验,LLM不仅展示了深刻的游戏理解力,还成功地模拟了人类玩家在游戏中可能展示的多元特质。这项实验不仅丰富了我们对LLM在策略游戏中的能力理解,还为未来的多LLM合作解决任务打开了新的可能性。
进NLP群—>加入NLP交流群











![[面试] 15道最典型的k8s面试题](https://img-blog.csdnimg.cn/ce77c438e66b415e9d325b0d66e8fbd1.jpeg#pic_center)