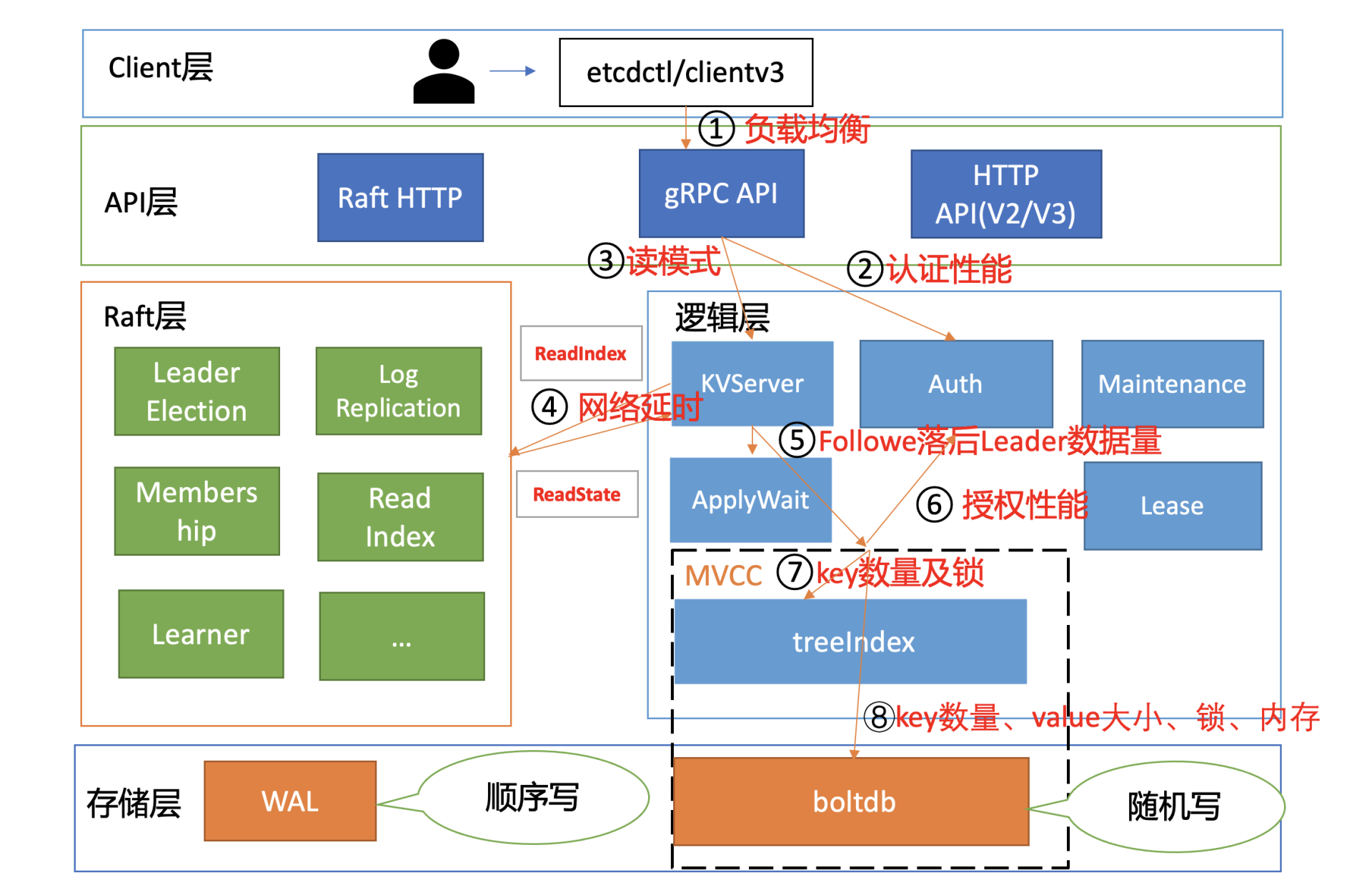
1、Raft模块-线性读ReadIndex-节点之间的RTT延时、磁盘IO
线性读时Follower节点首先会向Raft 模块发送ReadIndex请求,此时Raft模块会先向各节点发送心跳确认,一半以上节点确认 Leader 身份后由leader节点将已提交日志索引 (committed index) 封装成 ReadState 结构体通过 channel 层层返回给线性读模块,并会 等待本节点状态机的已应用日志索引 (applied index) 大于等于 Leader 的已提交日志索引,才能继续将请求发送到MVCC模块,从而确保能在本节点状态机中读取到最新数据,
心跳确认会涉及到各个节点之间网络通信,因此各个节点之间的 RTT 延时是决定线性读 ReadIndex 性能的核心因素之一。
Follower节点应用已提交日志条目到状态机的过程涉及到写磁盘,因此磁盘 IO 性能还会影响读性能,线性读性能会随着写QPS的增加而快速下降。
2、MVCC模块-总key数、查询的key数、key大小
从 treeIndex 中获取整个查询涉及的 key 列表版本号信息时,影响其性能的关键因素是 treeIndex 的总 key 数、查询的 key 数、获取 treeIndex 锁的耗时。
大 key-value 的查询非常容易导致 etcd OOM、server 节点出现丢包、性能急剧下降。
etcd写性能主要影响因素
1、Quota模块-压缩策略
Quota模块会对db配额进行校验,etcd 支持按时间周期性压缩、按版本号压缩两种策略,建议压缩策略不要配置得过于频繁,比如如果按时间周期压缩,一般情况下 5 分钟以上压缩一次比较合适。
2、KVServer 模块-磁盘IO
KVServer 模块的写请求在提交到 Raft 模块前,会进行限速判断,如果 Raft 模块已提交的日志索引(committed index)比已应用到状态机的日志索引(applied index)超过了 5000,那么它就返回一个"etcdserver: too many requests"错误给 client。主要场景有
etcd 定时批量将 boltdb 写事务提交的时候,需要对 B+ tree 进行重平衡、分裂,并将 freelist、dirty page、meta page 持久化到磁盘,此过程需要持有 boltdb 事务锁,若磁盘随机写性能较差、瞬间大量写入,则也容易写阻塞,导致应用已提交的日志条目缓慢。
执行 defrag 等运维操作时,也会导致写阻塞,它们会持有相关锁,导致写性能下降。
3、Raft模块-网络、磁盘IO、leader稳定性、快照频率
etcd 是基于 Raft 协议实现数据复制和高可用的,各节点会选出一个 Leader,etcd 写请求首先需要转发给 Leader 处理,然后由leader将写请求提交到Raft模块后,首先会通过http广播给各个followwer节点并等待半数以上节点确认,此时各节点会将待持久化的日志条目追加到 WAL 中并写入磁盘,之后返回确认信息,因此节点之间 RTT 延时、磁盘的IO延时对写性能有较大影响。
此外,leader稳定性也是影响写性能的重要因素,Leader 节点会根据 heartbeart-interval 参数(默认 100ms)定时向 Follower 节点发送心跳,如果两次发送心跳间隔超过 2*heartbeart-interval,就会打印此警告日志。超过 election timeout(默认 1000ms),Follower 节点就会发起新一轮的 Leader 选举。
etcd 默认心跳间隔是 100ms,较小的心跳间隔会导致发送频繁的消息,消耗 CPU 和网络资源,而较大的心跳间隔,又会导致检测到 Leader 故障不可用耗时过长,影响业务可用性。一般情况下,为了避免频繁 Leader 切换,建议你可以根据实际部署环境、业务场景,将心跳间隔时间调整到 100ms 到 400ms 左右,选举超时时间要求至少是心跳间隔的 10 倍。
另外,快照频率也会影响写性能,在 Raft 模块中,正常情况下,Leader 可快速地将我们的 key-value 写请求同步给其他 Follower 节点,但是某 Follower 节点数据若落后太多,Leader 内存中的 Raft 日志已经被 compact 了,那么 Leader 只能发送一个快照给 Follower 节点重建恢复,而快照重建是极其昂贵的操作,会消耗大量的 CPU、Memory、网络资源,影响我们的读写性能。
--snapshot-count 参数控制快照行为,是指收到多少个写请求后就触发生成一次快照,并对 Raft 日志条目进行压缩。默认值为 10 万,如果过小的话在某节点数据落后时,如果它请求同步的日志条目 Leader 已经压缩了,此时我们就不得不将整个 db 文件发送给落后节点,然后进行快照重建,过大它会消耗较多内存。
4、MVCC模块-总key数、key大小
写事务则会从 treeIndex 模块中查找 key、更新的 key 版本号等信息,影响其性能因素是 key 数和锁。
更新完索引后,就会把新版本号作为 boltdb key, 把用户 key/value、版本号等信息组合成一个 value,写入到 boltdb,影响其性能因素是大 value、锁。
5、watcher的数量
大量的 watcher 会显著增大 etcd server 的负载,导致读写性能下降
gRPC proxy 组件里面提供了 watcher 合并的能力

1111







![[面试] 15道最典型的k8s面试题](https://img-blog.csdnimg.cn/ce77c438e66b415e9d325b0d66e8fbd1.jpeg#pic_center)