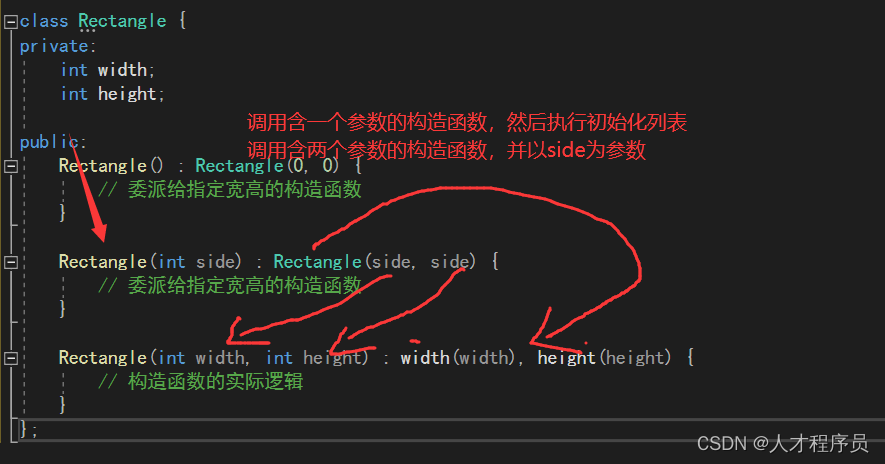
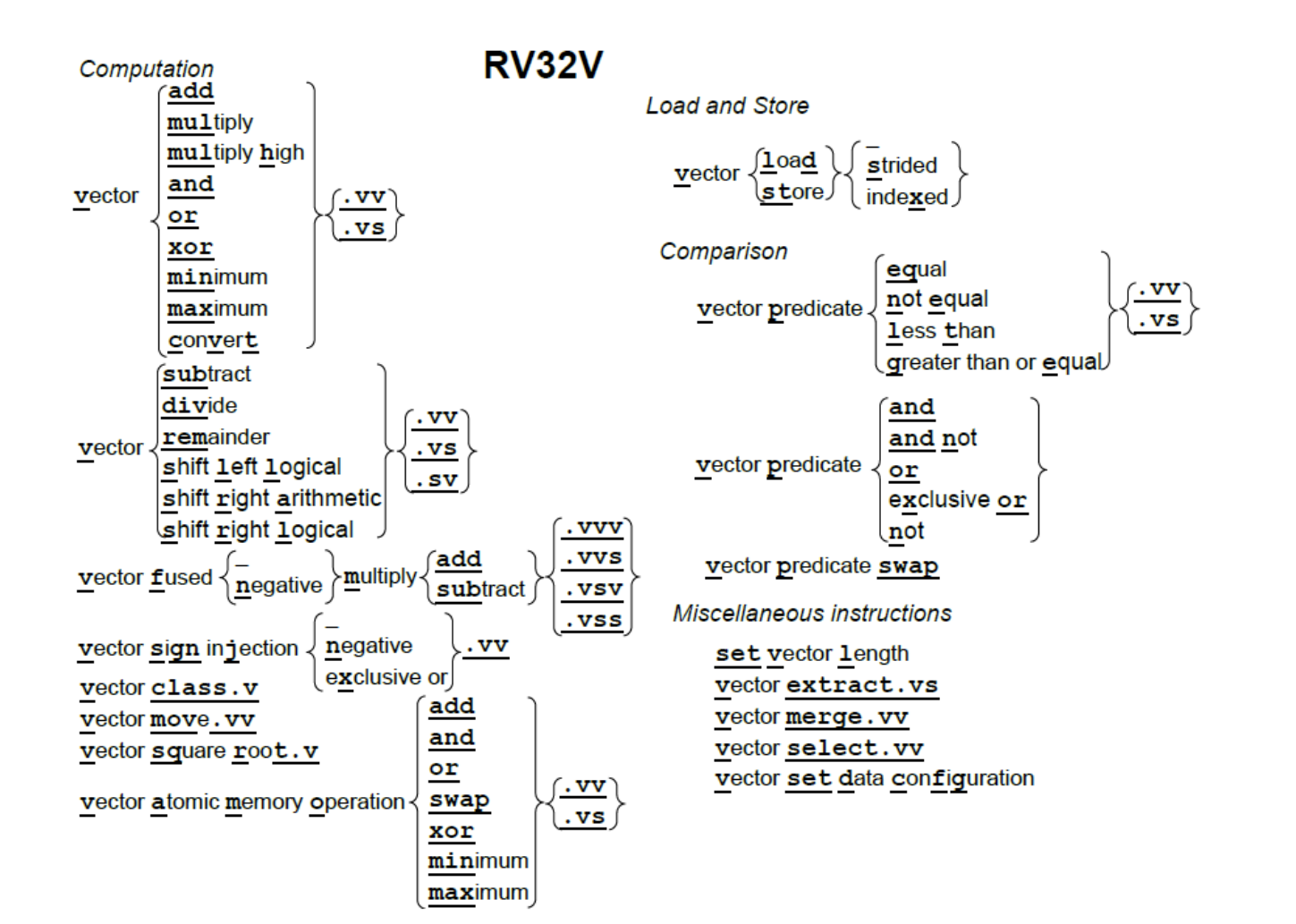
RV32V
早期并行数据计算:采用 SIMD 单指令多数据,把一个64位宽寄存器拆成若干个32 16 8 位长度部分并行计算。这种方法前期看起来十分简单诱人。但是后来如果要扩展 SIMD 寄存器宽度,也要复杂化指令集,复杂开销越来越大。
向量操作:把数据取出来放入长长的向量寄存器中,流水线并行运算后从向量寄存器中分别取回到内存。
并且,时钟周期内能进行的最大操作数和向量长度是分离的,不像 SIMD 程序员要考虑怎么分分几位,设计并行硬件的时候不用顾及程序员,程序员也不用重写代码。
向量操作在 ISA 中相比 SIMD 少见多了。
向量计算
基本每一个整数或者浮点运算都有向量版本。.vv 表示操作数都是向量,.vs 表示一个向量一个标量,即一个操作数来自x/f寄存器,一个来自v寄存器。比如 Y=aX+b。.sv 是给非对称运算比如减法 除法用的,表示操作数1是标量 如 Y=a-X。融合的乘法加法则有三个寄存器种类的指示变体。
向量寄存器
向量寄存器不固定大小,这样也减少了生成代码难度和程序员负担,也可以禁用未使用的向量寄存器。比如我们现在只有两个64位浮点类型向量寄存器,处理器有1024字节向量寄存器空间,则分给他俩每个512字节,512/8=64个元素,所以最大向量长度 mvl 为64.
源寄存器和目标寄存器都是有类型的(比如16位浮点 F16,32位浮点,64位浮点……)两者之间长度不兼容处理器会自动进行转换也就是隐式转换。可以通过 vsetdcfg 指令设定向量寄存器的类型。
Load Store
通常用来处理数组。
vld:按地址顺序填充向量寄存器。向量寄存器数据类型确定了元素大小,要取的元素数量存放在长度寄存器 vl 中。
vst:逆操作。
比如 vld v0,0(a0) v0是 x32 向量寄存器,那么 vld 就会从 a0 中的起始地址(假设是1024)开始,依次取1024 1028 1032 1036……(每次4字节)地址中的值直到到达 vl 的限制长度。
有一些结构比如以行优先序存储的二维数组,我们想对列进行顺序访问,就需要有一定的步长设定,而不是单纯的按顺序访问所有元素。可以使用 vlds 和 vsts 因为他们会通过一个寄存器来设定步长。
比如 vlds v0,a0,a1 ,a0 起始地址1024,a1行长64,那么取的位置就依次是1024,1024+64,1024+64*2……直到到达 vl 的限制长度。
第三对操作是针对稀疏数组进行操作的。
vldx v0,a0,v1 a0 起始地址还是1024,v1 中有这些字节索引:16 48 80 160,那么取的位置就是 1024+16 1024+48 1024+80 1024+160.
向量操作期间的并行性
他的并行性和早期的 SIMD 很像,首先取决于处理器每个时钟周期能操作几个多少位数。比如每个时钟周期内能操作4个64位数,那么也可以操作8个32位数,16个16位数,32个8位数。
不过 SIMD 的并行性是 ISA 架构师在设计过程中定好了的,因此寄存器数量增加指令也增加,而且编译器还要修改,相比之下 RVV 就不用改变程序,而且不管硬件结构就都能跑。
条件执行
RVV 的条件执行是每个向量里所有元素分别进行的,结果也是分别赋值给向量中对应的元素的。
RVV 有8个向量谓词寄存器 vpi。他们可以存储向量寄存的结果,也可以进行 vpand vpor vpxor 等运算。
如:vplt.vs vp0,v3,x0 就是判断 v3 中哪些元素是小于0的负数?把 vp0 中对应的这些元素都置1.
然后可以进行一些对部分元素单独进行的操作,比如 add.vv,vp0 v0,v1,v2 就是把前面 vp0 为1的部分替换令v0=v1+v2.
这种操作类似网络里的掩码,vp0 vp1 被规定用作控制向量操作的掩码。(比如我们要操作一个向量中的所有元素,那我们就得用一个全为1的掩码)。
RVV 里有 vpswap 指令可以快速把其他 vpi 的值交换到 vp0 或 vp1. 也可以选择谓词寄存器是否启用,可以通过禁用的方式来清零。
其他向量指令
setvl:把 vl 设置为源操作数和 mvl 中的最小值。如果 mvl 更大,则循环处理 mvl 长度;反之说明源操作数尾部的剩余部分长度小于最大向量长度,处理这一部分即可。
vselect:按第二个源操作数的索引位置,从第一个源操作数中取出一个新的向量。
vselect vedst, vsrc, vindices
比如 vindices 值是 8 0 4 2,则依次取出 vsrc 中第8 0 4 2索引处的元素值替换 vedst 的第0 1 2 3索引处的值。
vmerge:类似 vselect,有两个源操作数,vpo 指代替换的元素来自第一个 vsrc 还是第二个。
vmerge,vpo vdest, vsrc1, vsrc2
比如 vsrc1:1 2 3 4
vsrc2:10 20 30 40
vpo:1 0 0 1
vpo 指代取的数据是:v2的0位,v1的1位,v1的2位,v2的3位。
也就是最终赋值给 vdest 的值是 10 2 3 40。
vextract:从一个向量的中间位置开始取数,放到目标向量的起始位置。
如:vextract vdest, vsrc, start 如果向量长度64,start=32,那么就是从 vsrc 的中间取后32位数放到 vdest 开头32位。
我们可以利用 vextract 来做递归二分操作,比如循环求和所有向量寄存器元素,就可以做6次 vextract。

上例是利用 RV3V 写 DAXPY 程序(y=ax+y,一个函数处理)。
- 启用向量寄存器:我们只需要启用两个,给 x y 两个数组用。
- 每次循环开始,设定向量长度,y=a*x+y。
- 继续遍历或跳出。
简简单单10条左右的指令,一轮循环下来访存3*64次,浮点运算2*64次。每条指令平均有 19 次访存和 13 次运算。
与其他 ISA 向量运算的比较
都拿上例 DAXPY 的例子来进行分析。
MIPS:MSA 寄存器128位宽,每次可以处理2个双精度浮点数。但没有向量长度的寄存器,因此需要单独判断n是否为奇数,奇数最后要多做一次运算。平均每个指令大约有 1 个访存和 0.5 个运算操作。
x86:部分支持 256 位宽,n可以=4. 加载数据时先创建副本并在进入主循环之前进行测试。但是和 MIPS 有相似的问题,需要结尾判断 %4!=0 的部分。每条指令平均有约 2 次访存和 1 次运算。
结语
可以看出向量的一些优势。
如果不用向量,我们就要反复把代码写上好几遍,编程难度大一些。不过新指令程序员记起来也是比较复杂。
RISC-V 的向量运算不受一些向量长度等的影响,比如我把长度修改了,他仍然会自动判断 mvl 并执行,封装的比较好,程序员编码时以及编译器不用考虑这一点的影响。