函数参考手册:
https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics
并在左侧选择neon\

Neon 128bit寄存器,所以可支持并行运算 加快运算速度 减少循环
CPU运算比加载数据快,速度瓶颈在加载数据这里。
指令集命名形式,后续有例子说明:

变量支持如下:此外int还分为int8,int16,int32.对应定点开发s8,s16, s32 Float uint 类似int
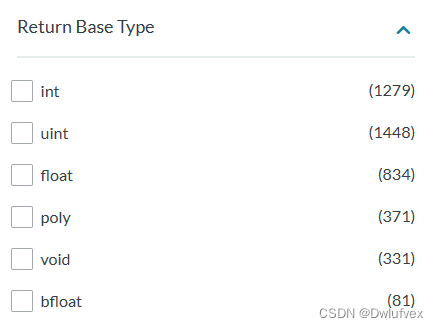
以下为目前开发中所涉及的常用指令
初始化指令
vld1q_s16 load 16x8
vld1_s16 load 16x4
示例:
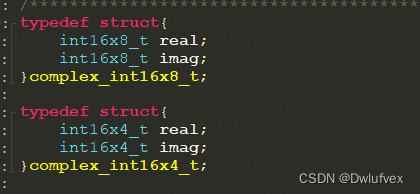

vdup_n_s16(n) 初始化int16x4_t 变量,全为n
vdupq_n_s16(n) 初始化int16x8_t 变量,全为n
乘法指令:
16x8 vqdmulhq_s16 ( 16x8, 16x8) Lshl 1 and extractH and saturating
16x8 vqrdmulhq_s16 (16x8 , 16x8) Lshl 1 and extractH and saturating + rounding
V vector q saturating r rouding d Doubling mul mult h extrachH q 区分int16x8与int16x4
16x4 vqdmulh_s16 ( 16x4, 16x4) Lshl 1 and extractH
相反数:
int16x8 vnegq_s16(int16x8) negate int16x8
int16x8 vqnegq_s16(int16x8) negate + saturating
int16x4 vneg_s16(int16x4) negate int16x4
取低位指令
int16x4 vget_low_s16(int16x8_t) 取int16x8_t 前4个值出来
移位指令
int16x4 vqshl_n_s16(s16x4 , shift) 左移shift位并饱和处理
int16x8 vqshlq_n_s16(s16x8, shift) 左移shift位并饱和处理
int16x4 vshr_n_s16(s16x4,shift) 右移shift位
int16x8 vshrq_n_s16(s16x8,shift) 右移shif