一、说明
自从我开始机器学习以来,Jupyter Notebooks一直是我最忠实的伙伴。从数据预处理到模型训练、微调和测试,Jupyter Notebooks 在每一步都为我提供支持。然而,我一直都知道,在这些数字页面之外,还有一个完整的世界——一个部署和应用的世界。
从训练模型到实际部署模型的飞跃似乎令人生畏。但是,这是将数据科学项目从理论实验转变为实际实际应用的关键步骤。我知道我必须迈出额外的一步!
在本文中,我们将开始为 Kaggle 竞赛构建分类模型的旅程。我们从典型的EDA和管道构建开始,直到到达新的未开发领域 - 至少对我来说 - 将我的机器学习模型变为现实,使其能够交互并为全球用户提供见解。
当我们走出舒适的 Jupyter 笔记本时,让我们振作起来,因为我们即将开始部署之旅。拿起你的编码帽,系好安全带,让我们准备好进入机器学习部署的世界!
二、使用表格葡萄酒质量数据集的序数回归
我们的旅程从Kaggle的游乐场系列第三季的第五集开始。该系列由Kaggle推广,提出了各种机器学习挑战,邀请用户提高他们在数据分析,特征工程,数据清理和机器学习管道构建方面的技能。
第五集,使用表格葡萄酒质量数据集的序数回归,邀请Kagglers分析基于葡萄酒质量数据集的合成生成的数据集。该数据集由12个属性组成 - 包括目标变量 - 告诉我们更多关于每种葡萄酒的信息,例如酸度,pH值,氯化物量,酒精含量等。
本次比赛的评估指标是二次加权 Kappa,由以下等式给出:
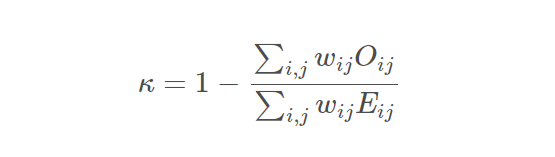
二次加权河童公式
此处:
.Oij是实际的混淆矩阵。
.Eij 是随机性下的预期混淆矩阵。
.Wij 是加权矩阵,可以计算为 (i — j)²,其中 i 和 j 是评级。
分数等于 1 表示评分者之间完全一致,而分数等于 0 表示协议并不比偶然预期的更好。
提交进行评估的文件必须是 .csv文件由ID和质量列组成,其中质量是指测试数据集中葡萄酒最终模型的预测。质量是一个值,范围从 3 到 8,其中 8 表示最佳质量,3 表示质量最差。
三、探索性数据分析
为了增强我的探索性分析,我转向了Plotly——毫无疑问,这是我在Python中实现数据可视化的首选库。我首先看了一些关键的描述性统计数据。然后,我直接开始查看相关热图。
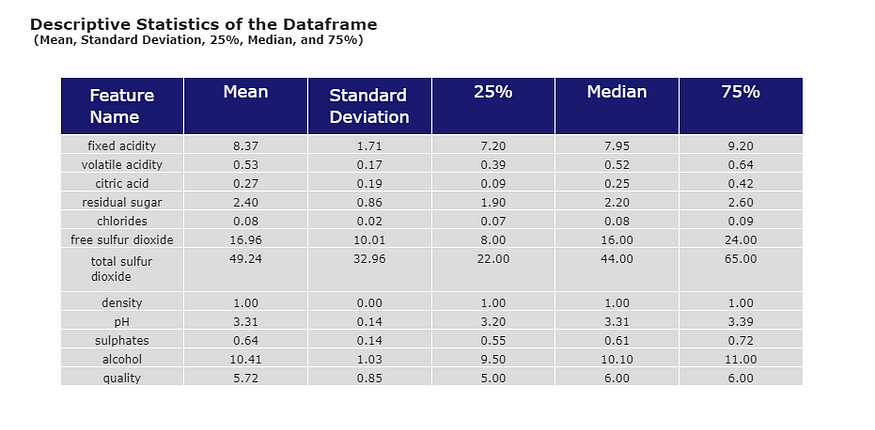
我从描述性统计表中提取的第一个见解是特征之间的尺度差异。我们稍后会处理的事情。
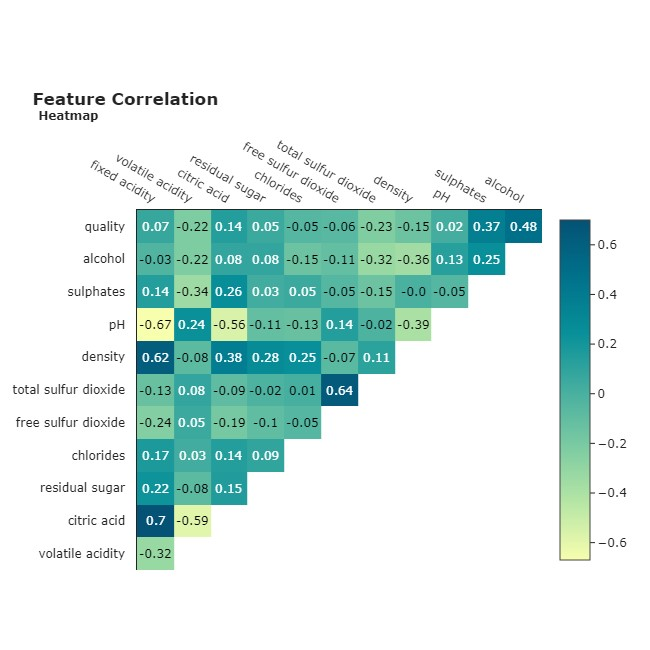
通过分析特征相关图,我不禁注意到酒精是与目标变量质量最正相关的特征。这可以通过下面的小提琴箱线图来证实。
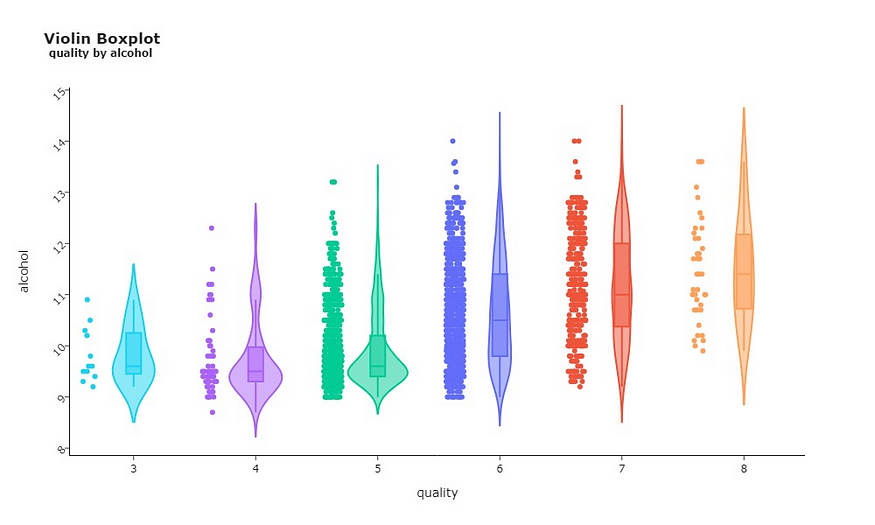
您可以在上图中轻松发现趋势。从质量 5 开始,我们看到酒精含量的中值有明显的上升趋势。这种模式暗示,酒精含量较高的葡萄酒往往也具有更高的质量。这是一个线索,这个功能可能非常擅长预测葡萄酒的质量。
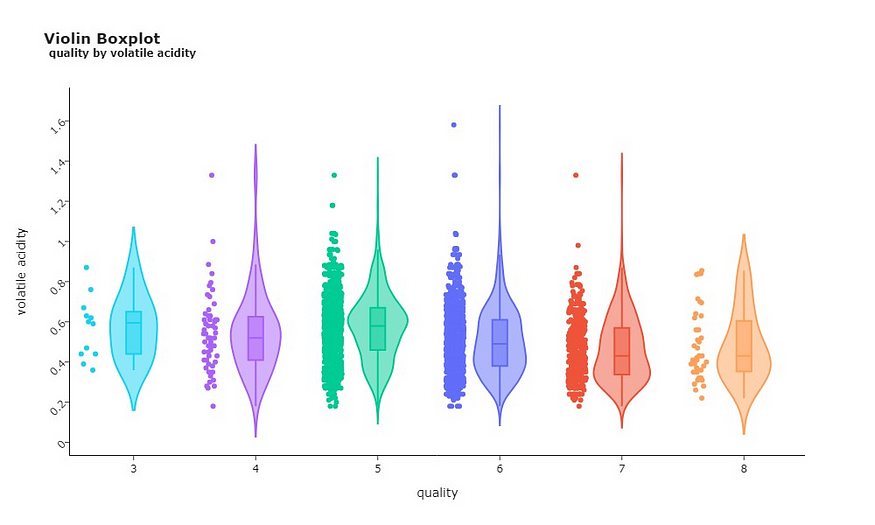
在分析质量和挥发性酸度之间的关系时,可以发现反向模式。葡萄酒的质量越高,挥发性酸度的中值越低。
说到葡萄酒质量水平,看看这些品质如何在我们数据集中的葡萄酒中分布也很有帮助。
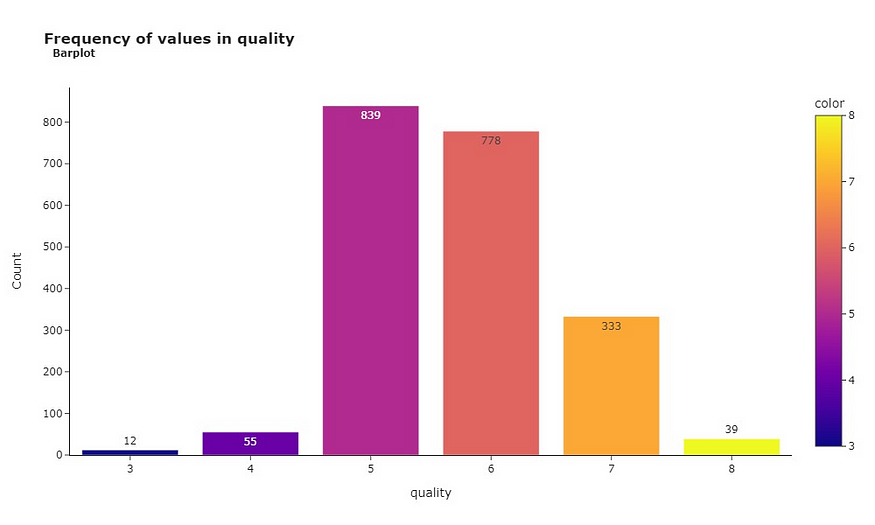
大多数葡萄酒得分为5或6,表明它们属于“平均”类别。12款葡萄酒中只有一小部分获得了3分的低评级,而其中39款以8分达到“黄金”状态。这种类别分布可能会给我们的模型带来偏见,这使得它更容易将葡萄酒分类为5或6,因为这是大多数葡萄酒所属的范围。
既然我们谈论的是分布,为什么不看看所有其他特征是如何分布在数据中的呢?
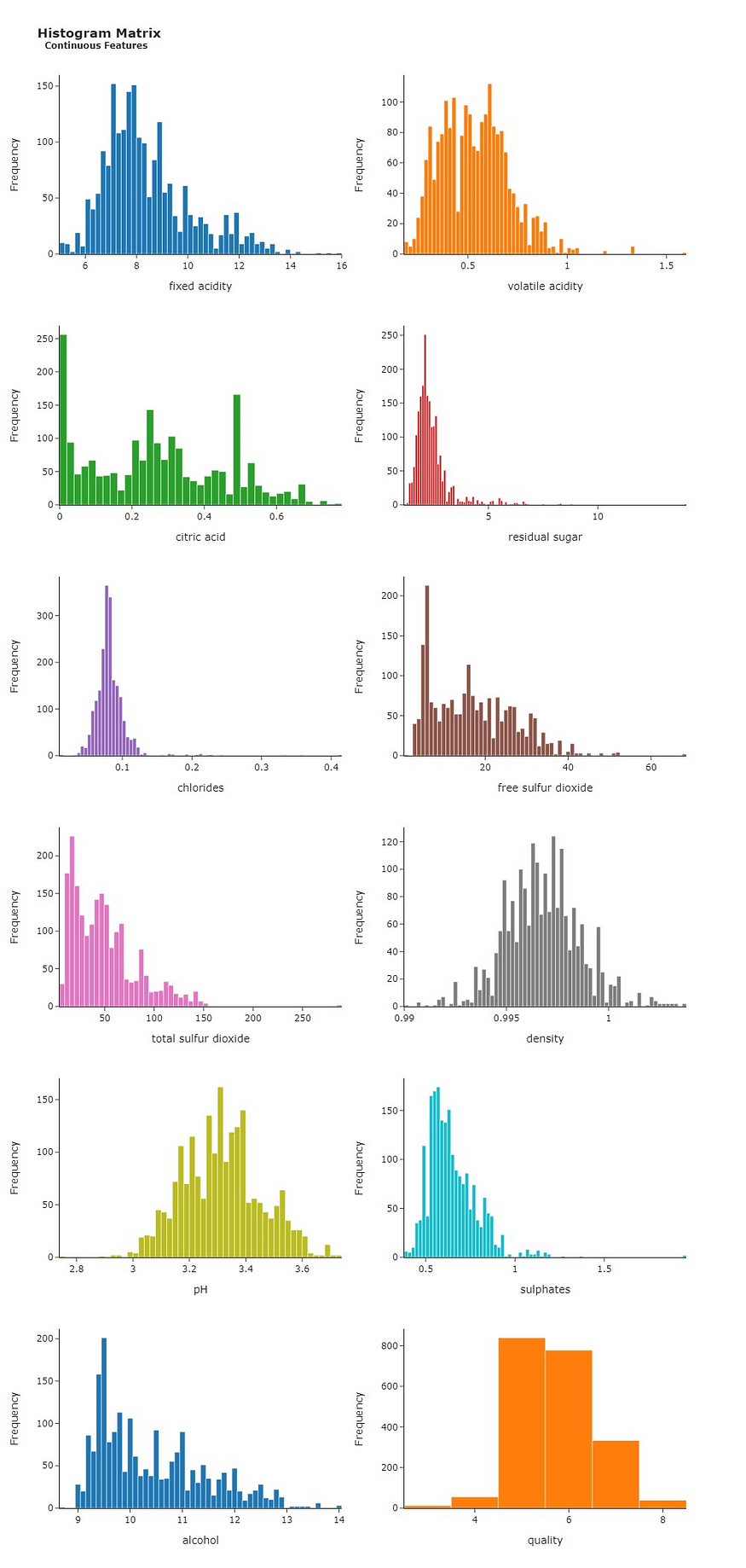
上面的直方图矩阵提供了另一个有价值的见解!我们的特征不是正态分布的,这意味着它们的直方图不像钟形曲线。这些信息是相关的,因为我们可以通过将特征分布转换为高斯分布(即正态分布)来获得更好的性能。
这总结了我们目前探索性分析的关键要点。但不要让乐趣止步于此!一定要看看这些用Plotly制作的美丽情节。要更深入地了解,请单击此处查看我在 Kaggle 上的完整笔记本!
四、预处理
在进入建模阶段之前,我们需要整理数据!我首先设计了新功能,旨在提高自变量的预测能力。
还记得我们深入研究特征之间的相关性吗?现在我们正处于功能创建阶段,这些关系可以派上用场。我们可以从与目标变量具有更强相关性的属性(例如酒精)中设计新特征。
以下是我添加到训练数据集中的以下功能:
- 总酸度:固定酸度+挥发性酸度+柠檬酸;
- 酸度与pH比:总酸度÷pH值;
- 游离二氧化硫与总二氧化硫的比例:游离二氧化硫÷总二氧化硫;
- 酒精酸度比:酒精÷总酸度;
- 残糖与柠檬酸的比例:残糖÷柠檬酸;
- 总酸度:固定酸度+挥发性酸度+柠檬酸;
- 酒精密度比:酒精÷密度;
- 总碱度:pH+酒精;
- 总矿物质:丙种内酯+硫酸盐+残糖。
除此之外,我还使用了Scikit-learn的QuantileTransformer。这帮助我将独立特征的分布塑造成更接近高斯分布的分布。结果,我们得到了我们想要的整洁的钟形曲线形状,您可以在下面的直方图矩阵中找到它。
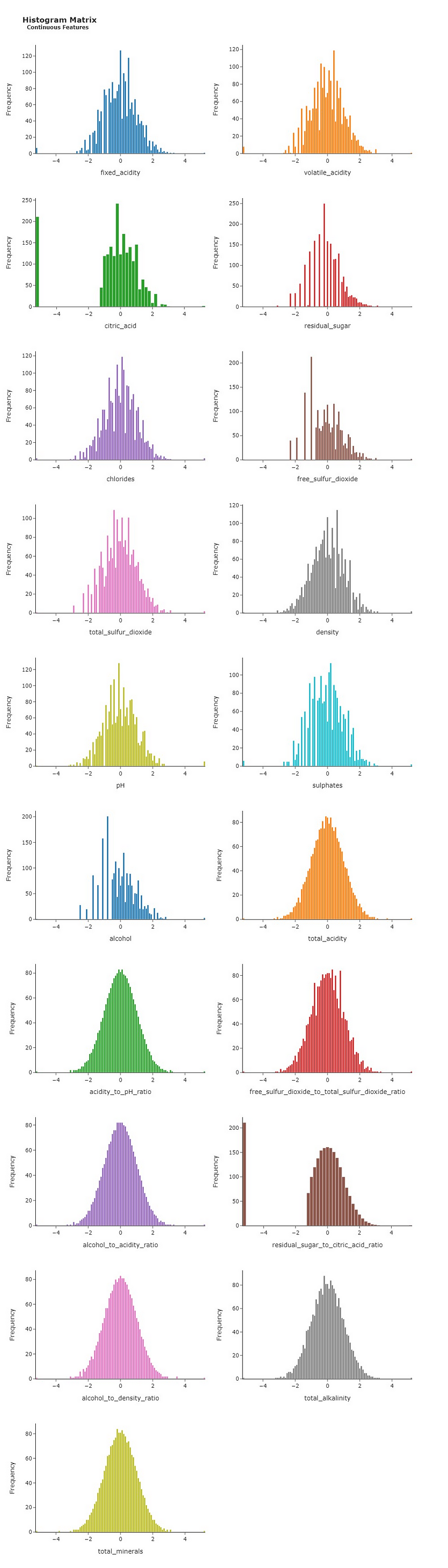
您还可以看到新功能。
此外,我还使用 StandardScaler 来调整每个特征的平均值和标准差值。多亏了这个工具,我们的平均值 (μ) 为 0,标准差 (σ) 为 1,您可以在下表中看到。
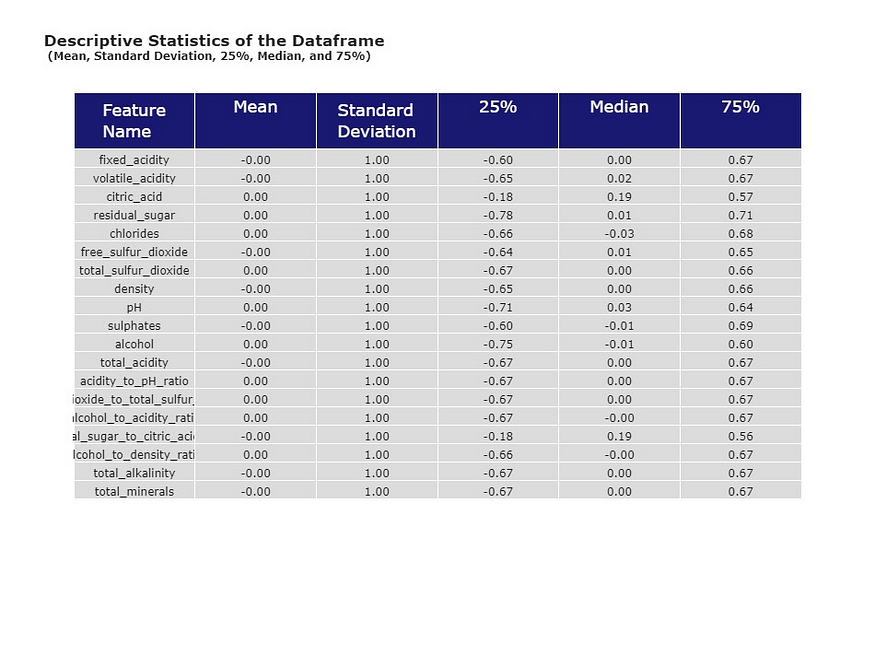
完成所有这些数据转换后,是时候进行特征选择,以确定对预测葡萄酒质量最具影响力的特征了。这就是来自Scikit-learn的便捷工具RFECV发挥作用的地方。
RFECV 代表 具有交叉验证的递归特征消除。递归特征消除是一种技术,其工作原理是拟合估计器并删除最弱的特征(绝对系数最小的特征),然后重复此过程,直到消除所有最不重要的特征。通过使用RFECV,我们可以拥有一组为预测带来真正价值的功能,从而提高准确性和效率。
运行 RFECV 后,我们有一个功能列表,这些功能被选为与质量预测最相关的功能。
volatile_acidity
citric_acid
chlorides
total_sulfur_dioxide
density
pH
sulphates
alcohol
total_acidity
acidity_to_pH_ratio
free_sulfur_dioxide_to_total_sulfur_dioxide_ratio
alcohol_to_acidity_ratio
residual_sugar_to_citric_acid_ratio
alcohol_to_density_ratio
total_alkalinity
total_minerals 预处理会话的最后一步涉及聚类。在这里,我使用 KMean 将数据捆绑到不同的组中。这些组表示从相关图中可能不会立即显现出来的潜在模式或关系。这是一种揭示和利用数据集中隐藏结构的聪明方法。
通过分析弯头曲线图,确定最佳聚类数为 K = 3,将数据分为三个不同的组。
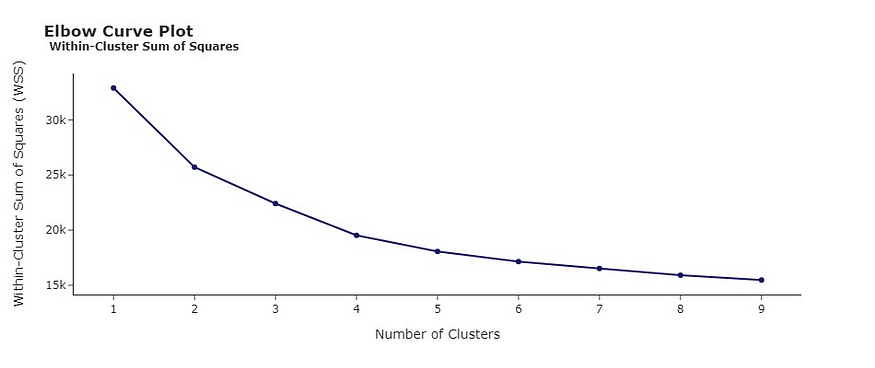
此外,我创建了一个散点图来说明总碱度和酒精之间的关系,从而更深入地了解每个聚类的构成。例如,聚类 0 包括酒精度和总碱度较低的葡萄酒。另一方面,集群1以葡萄酒为主,这两个特征倾向于更高的价值。

五、模型
我们终于进入了建模阶段!我们将从使用 Scikit-learn 的管道开始。这个有用的工具允许我们指定一系列函数和类,这些函数和类将执行我们之前完成的所有预处理步骤。这样做是为了确保交叉验证期间的每次折叠以及输入到托管模型的应用程序中的任何数据都经过所有必要的预处理。这是保持流程一致性的简单方法。
我们首先准备将在管道中执行的所有步骤。
# Cleaning and creating features
def feat_eng(df):
df.columns = df.columns.str.replace(' ', '_')
df['total_acidity'] = df['fixed_acidity'] + df['volatile_acidity'] + df['citric_acid']
df['acidity_to_pH_ratio'] = df['total_acidity'] / df['pH']
df['free_sulfur_dioxide_to_total_sulfur_dioxide_ratio'] = df['free_sulfur_dioxide'] / df['total_sulfur_dioxide']
df['alcohol_to_acidity_ratio'] = df['alcohol'] / df['total_acidity']
df['residual_sugar_to_citric_acid_ratio'] = df['residual_sugar'] / df['citric_acid']
df['alcohol_to_density_ratio'] = df['alcohol'] / df['density']
df['total_alkalinity'] = df['pH'] + df['alcohol']
df['total_minerals'] = df['chlorides'] + df['sulphates'] + df['residual_sugar']
df = df.replace([np.inf, -np.inf], 0)
df = df.dropna()
df = df[selected_features]
return df# Applying QuantileTransformer to change the distribution to a gaussian-like distribution
class CustomQuantileTransformer(BaseEstimator, TransformerMixin):
def __init__(self, random_state=None):
self.random_state = random_state
self.quantile_transformer = QuantileTransformer(output_distribution='normal', random_state=self.random_state)
def fit(self, X_train, y=None):
self.quantile_transformer.fit(X_train)
return self
def transform(self, X):
X_transformed = self.quantile_transformer.transform(X)
X = pd.DataFrame(X_transformed, columns=X.columns)
return X# Applying StandardScaler to bring every feature to the same scale
class CustomStandardScaler(BaseEstimator, TransformerMixin):
def __init__(self):
self.scaler = StandardScaler()
def fit(self, X_train, y=None):
self.scaler.fit(X_train)
return self
def transform(self, X):
X_transformed = self.scaler.transform(X)
X = pd.DataFrame(X_transformed, columns=X.columns)
return X# Applying KMeans clustering with n_clusters = 3
class KMeansTransformer(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=3, random_state=seed):
self.n_clusters = n_clusters
self.random_state = random_state
self.kmeans = KMeans(n_clusters=self.n_clusters, random_state=self.random_state)
def fit(self, X_train, y=None):
self.kmeans.fit(X_train)
return self
def transform(self, X):
X_clustered = pd.DataFrame(X.copy())
cluster_labels = self.kmeans.predict(X)
X_clustered['Cluster'] = cluster_labels
return X_clustered之后,我们需要做的就是使用 sklearn 的管道类创建一个包含上述所有步骤的元组列表。
pipeline = Pipeline([
('Feature Engineering', FunctionTransformer(feat_eng)),
('Transforming Distribution', CustomQuantileTransformer()),
('Standard Scaler', CustomStandardScaler()),
('Clustering', KMeansTransformer()),
('Model', None)
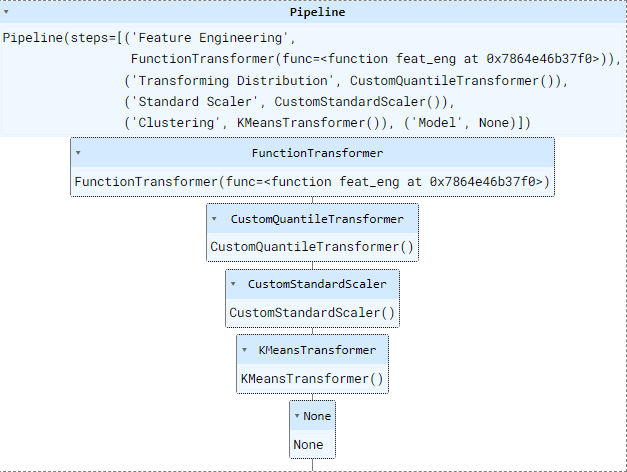
])这就是我们的管道现在的样子:
六、初始化管道
您可以看到每个预处理步骤如何遵循特定的顺序。我们首先创建并选择特征,然后对特征进行转换、缩放和聚类。您可能还会注意到最后一部分“模型”当前为空。这是我们将机器学习模型添加到管道中的地方。
我对许多模型进行了交叉验证,对它们进行了微调,并尝试了不同的集成方法,例如 VotingClassifier 和 StackingClassifier。为了避免文章过于详尽,让我们直接跳到用于该管道的最终模型,但我强调您可以在此处阅读整个过程。
性能最佳的模型是经过微调的 CatBoostClassifier,其参数如下:
Best Quadratic-Weighted Kappa score = 0.5227513447061922
Best Params = {'learning_rate': 0.16,
'iterations': 150,
'max_depth': 6,
'subsample': 0.6,
'l2_leaf_reg': 3.7,
'min_data_in_leaf': 45,
'random_strength': 3.9000000000000004,
'bootstrap_type': 'Bernoulli',
'grow_policy': 'Depthwise',
'leaf_estimation_method': 'Gradient'}在确定了最佳模型和最佳参数之后,我们需要做的就是使用 Pipeline 的 .set_params() 并将我们的模型添加到管道的最后一步。
# Setting pipeline with Tuned CatBoost Model
pipeline.set_params(Model = CatBoostClassifier(**best_params2,
random_state = seed, verbose = False))
管道的最终结构
我们还可以查看特征重要性图,该图显示了在交叉验证期间预测质量的最相关特征。
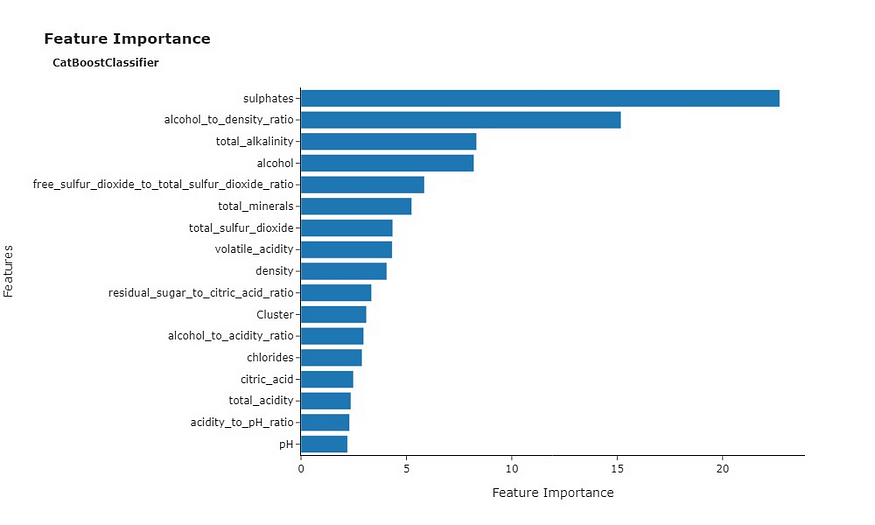
硫酸盐在交叉验证期间获得了最重要特征的称号。还值得注意的是,酒精以及酒精密度比和总碱度等相关特征对于预测质量也非常重要。这与我们之前观察到的酒精和葡萄酒质量之间的正相关关系一致。
训练并验证模型后,我使用 Joblib 保存我的管道
import joblib
joblib.dump(pipeline, 'wine_quality_prediction.pkl')运行上面的代码后,我的管道 wine_quality_prediction.pkl 被保存到我运行笔记本的同一文件夹中。使用此文件,我现在能够在另一个笔记本或环境中加载管道以运行我的模型。
七、在拥抱脸上构建流光应用
好了,现在我们已经保存了一个管道和一个经过验证的模型,可以滚动,我们进入下一步 - 部署!
老实说,一开始我对如何解决这个问题有点无知。但是在看了几个YouTube视频后,我发现了Hugging Face Spaces,它使我们能够轻松构建一个可以托管我们的机器学习模型的应用程序。
如果您没有帐户,只需单击屏幕右上角的“注册”按钮,输入您的电子邮件地址,设置密码,即可完成设置。这应该一点也不难。

注册后,您可以转到顶部菜单上的空间,然后单击创建新空间
这会将我们直接带到另一个页面,在那里我们可以为我们的空间提供名称、许可证、硬件和空间 SDK。SDK将允许我们创建应用程序的界面。
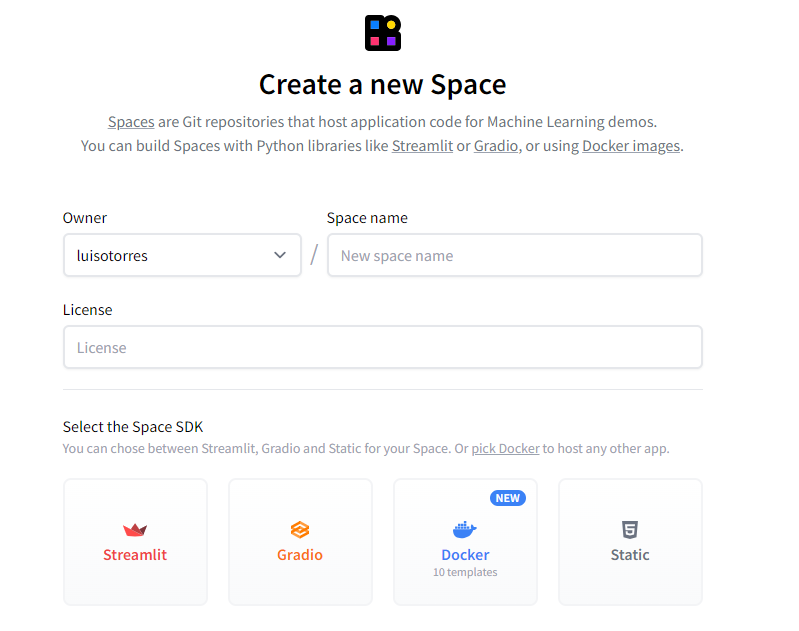
对于此任务,我使用了Streamlit。根据其网站,Streamlit允许在几分钟内更快地构建和共享数据Web应用程序。全部使用纯Python,无需前端经验。我不是 Streamlit 的专家,但用它创建我的第一个应用程序非常直观且非常容易。您可以通过单击此处访问其文档。
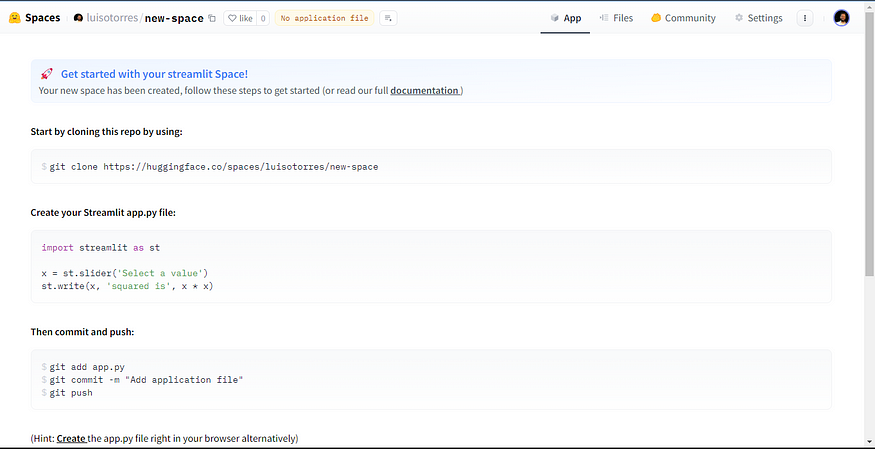
创建新空间后,您将看到一个类似于下面的页面。您可以使用 git 克隆存储库,也可以创建直接从浏览器运行应用程序所需的文件。
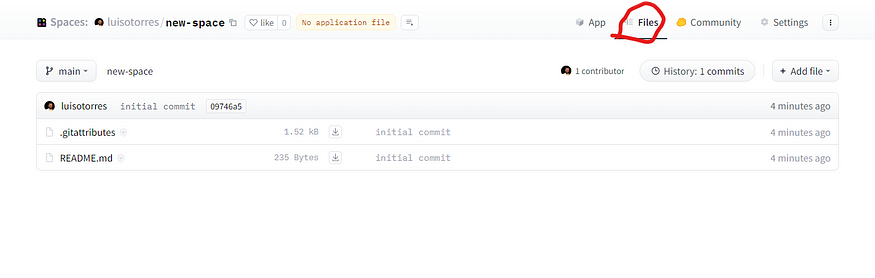
通过单击顶部菜单中的“文件”,你将有权访问存储库中的文件。最初,您在这里将拥有一个 .gitattributes 文件和一个 README.md 文件。
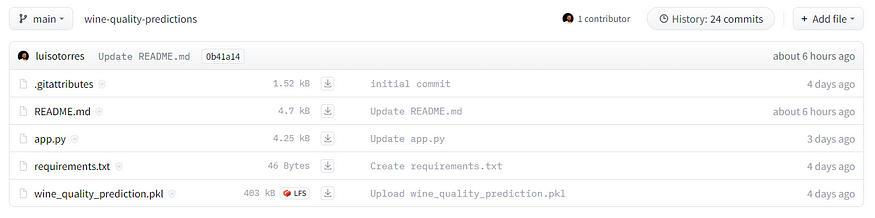
在我的葡萄酒质量预测应用中,我首先添加了管道文件 wine_quality_prediction.pkl。然后,我添加了一个 requirements.txt 文件,该文件仅包含运行我的应用程序所需的所有库的列表。您可以在下面看到我的文件页面。
app.py 文件是一个 Python 脚本,我们在其中加载管道并使用 Streamlit 塑造应用程序的界面。尽管这是我第一次使用 Streamlit,但我发现制作一个简单的界面来托管我的模型相对容易。它并不完美,关于 Streamlit,我肯定有更多的知识需要学习,但我设法让我的模型启动并运行得很好。顺便说一下,不要犹豫,使用所有这些在线提供的大型语言模型,在您觉得有必要的时候帮助编码。
设置完 app.py 文件后,您可以通过单击顶部菜单中的“应用程序”选项来运行您的应用程序,而不会遇到其他问题。
如果您想测试我的应用程序,可以在葡萄酒质量预测器模型中访问它。 通过单击此链接,您还可以看到我上传的文件以使此应用程序运行,包括 app.py 脚本的编码。随意探索!
另外,如果你想检查我的Kaggle笔记本,我在那里使用过葡萄酒质量数据集,使用Plotly执行了一些探索性数据分析,并使用了大量的机器学习库,如Scikit-learn和Optuna,来训练和调整我的机器学习模型,你可以在葡萄酒质量:EDA,预测和部署中🍷检查它。 如果您发现此笔记本有用,请随时留下反馈和点赞!
八、结论
我们终于完成了从数据预处理到部署的旅程。毫无疑问,这是一次丰富的经历。它允许我以一种我还没有探索过的方式探索机器学习的一部分——以及它的一些实际应用。为Kaggle竞赛构建分类模型,然后将其部署在Hugging Face上供公众访问的过程既具有挑战性,又很有收获。我希望这篇文章能为这个过程提供有价值的见解,并鼓励其他人从理论到实践的飞跃。请记住,机器学习的世界是广阔的,对于那些愿意走出舒适区的人来说,充满了机会。路易斯·费尔南多·托雷斯





![[当人工智能遇上安全] 9.基于API序列和深度学习的恶意家族分类实例详解](https://img-blog.csdnimg.cn/fc259b57eb4b4df297903a76b1772ffc.jpeg#pic_center)