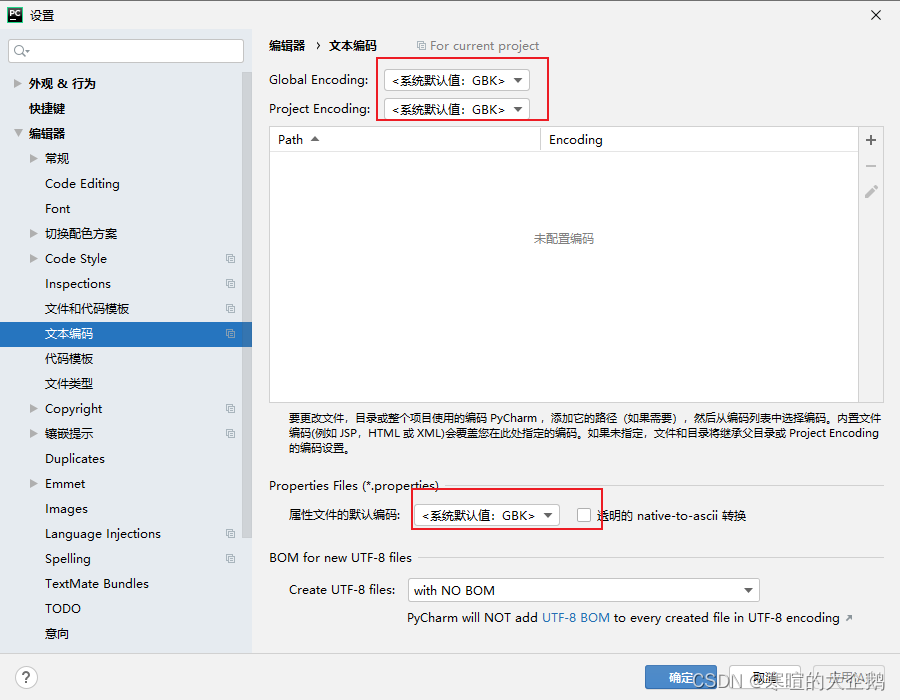
文章目录
- 1. AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions 时空局部原子视觉动作的视频数据集
- 摘要和结论
- 模型框架
- 思考不足之处
- 时间信息对于识别 AVA 类别有多重要?
- 定位与识别相比有何挑战性?
- 哪些类别具有挑战性?训练样本的数量有多重要?
- 2. A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos 在未修剪视频中基于提案时空动作检测解决方案
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- Input Pre-processing
1. AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions 时空局部原子视觉动作的视频数据集
摘要和结论
- 时空定位(spatiotemporally localized)原子视觉动作(AVA)
- 主要介绍了数据集的制作过程,是如何筛选和标记的。AVA数据集是google发布的一个视频行为检测与定位的视频数据集,包含在430个15分钟的视频片段中标注了的80种原始动作,这些动作由时间和空间定位,产生了1.58M个动作标签。
- 本文重点是介绍论文中所提出的action location模型。
模型框架
时空动作定位方法:依赖于经过训练的对象检测器object detection,以使用双流变体在帧级frame-level别区分动作类别,分别处理 RGB 和流数据。然后使用动态编程dynamic programming或跟踪tracking将生成的每帧检测链接起来linked。 所有这些方法都依赖于集成帧级检测。
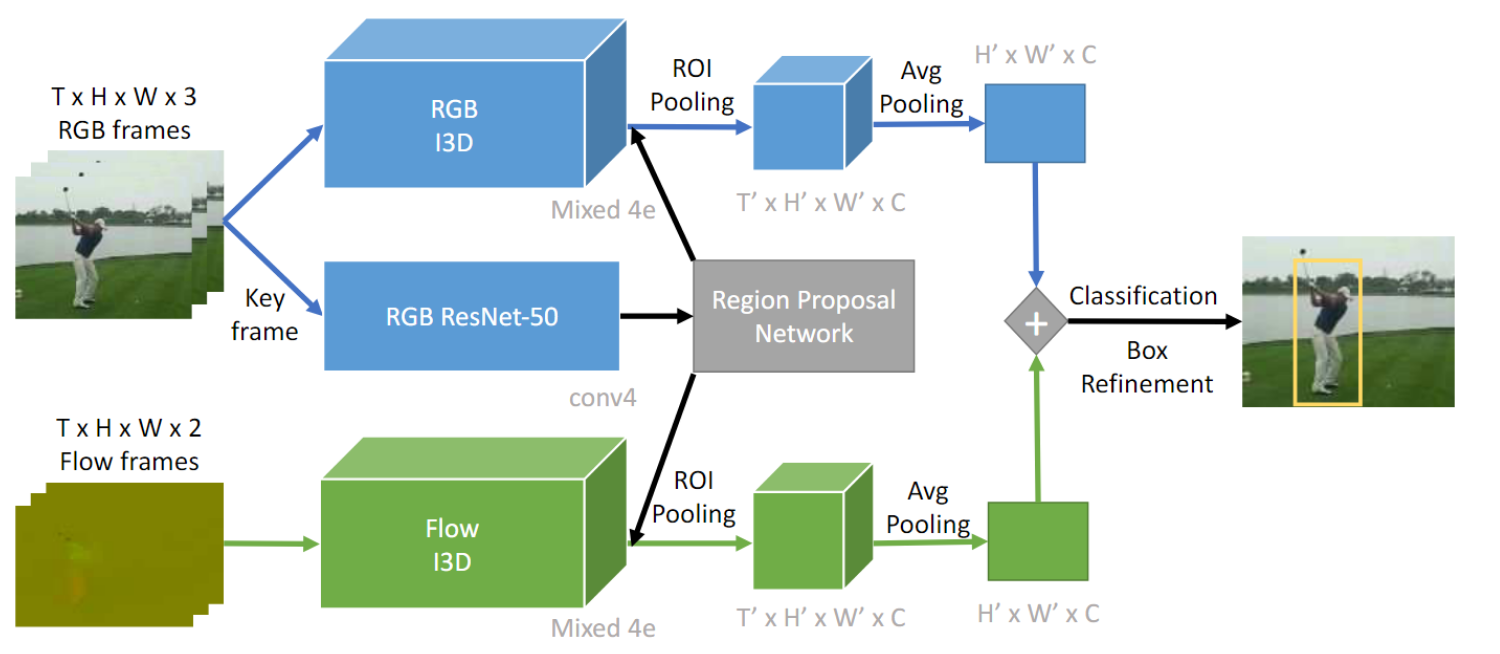
使用 Faster-RCNN 在 RGB 关键帧上检测并回归区域提案。时空管用两流I3D卷积进行分类

思考不足之处
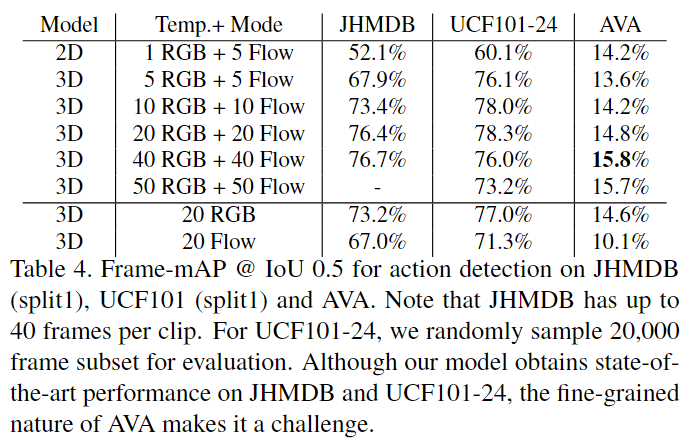
时间信息对于识别 AVA 类别有多重要?
表 4 显示了时间长度和模型类型的影响。所有 3D 模型在 JHMDB 和 UCF101-24 上的性能均优于 2D 基线。对于AVA,3D模型在使用超过10帧后表现更好。我们还可以看到,增加时间窗口的长度有助于跨所有数据集的 3D 双流模型。正如预期的那样,结合 RGB 和光流功能可提高单一输入模态的性能。此外,与 JHMDB 和 UCF101 相比,AVA 从更大的时间上下文中受益更多,后者的性能在 20 帧处达到饱和。这一增益和表 1 中的连续操作表明,人们可以通过利用 AVA 中丰富的时间上下文来获得进一步的增益。
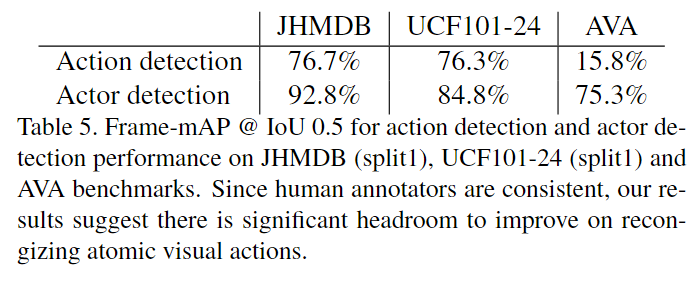
定位与识别相比有何挑战性?
表 5 比较了端到端动作定位和识别与类不可知动作定位的性能。我们可以看到,虽然 AVA 上的动作定位比 JHMDB 更具挑战性,但 AVA 上的定位和端到端检测性能之间的差距接近 60%,而 JHMDB 和 UCF101 上的差距不到 15%。这表明 AVA 的主要困难在于动作分类而不是定位。图9显示了高分误报的示例,表明识别的难度在于细粒度的细节。
哪些类别具有挑战性?训练样本的数量有多重要?
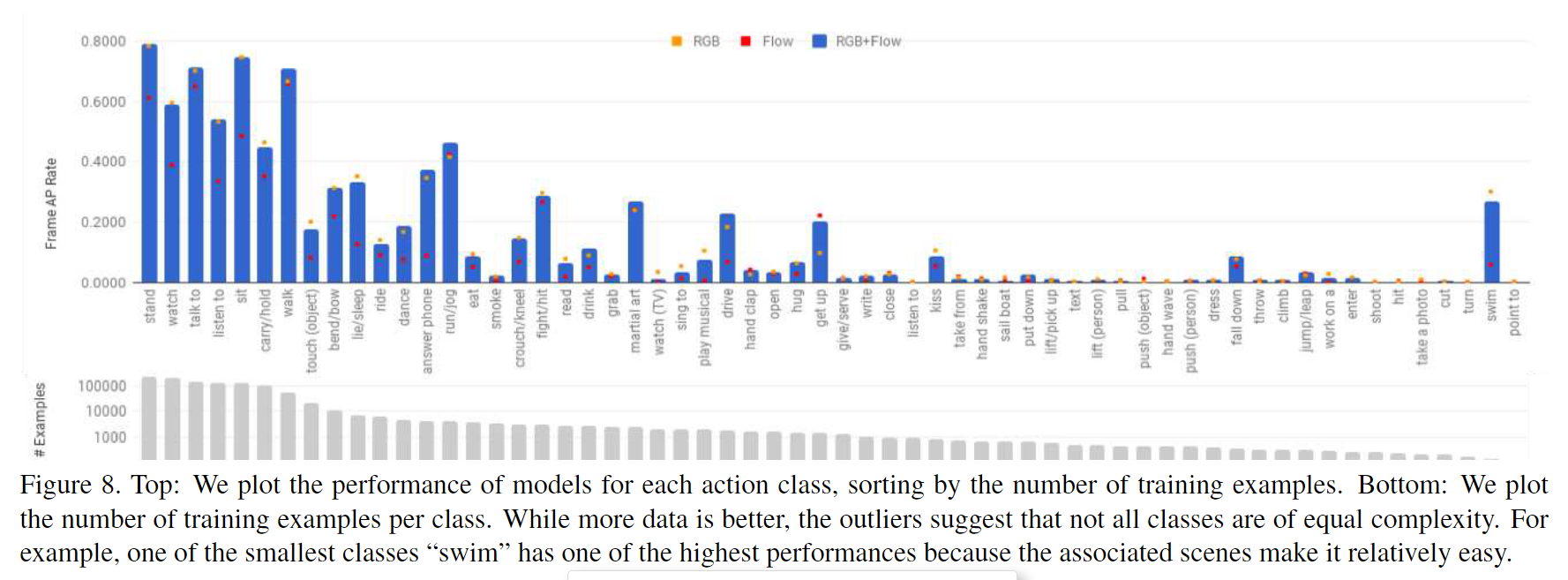
图 8 按类别和训练示例数量细分了性能。虽然更多的数据通常会产生更好的性能,但异常值表明并非所有类别都具有相同的复杂性。尽管训练样本较少,但与场景和物体相关的类别(例如游泳)或多样性较低的类别(例如跌倒)仍获得了较高的性能。相比之下,具有大量数据的类别(例如触摸和吸烟)获得相对较低的性能,可能是因为它们具有较大的视觉变化或需要细粒度的辨别,从而激发了人与物体交互的工作。我们假设,识别原子动作的成果不仅需要 AVA 等大型数据集,还需要丰富的运动和交互模型。
2. A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos 在未修剪视频中基于提案时空动作检测解决方案
摘要和结论
- 提出一个two stage方法。第一阶段:用分层聚类 hierarchical clustering 和时间抖动 temporal jittering 技术在逐帧对象检测上生成dense spatio-temporal proposals。
- 第二阶段:是一个时间细化 Temporal Refinement I3D (TRI-3D)网络,它对生成的建议proposals执行动作分类和时间细化。
- 基于对象检测的提议生成步骤有助于检测视频帧的小空间区域中发生的动作,而时间抖动和细化有助于检测可变长度的动作。
引言:针对痛点和贡献
痛点:
- 动作通常发生在相对于整个视频帧的小空间区域。这使得很难检测动作中涉及的演员/对象。
- 其次,动作的持续时间可能会有很大差异,从几秒钟到几分钟不等。这需要检测过程对时间变化具有鲁棒性。
贡献:
- 提出了一种使用层次聚类和时间抖动的算法,以使用逐帧对象检测生成动作建议。
- 提出了用于动作分类和时间定位的时间细化 I3D (TRI-3D) 网络。
- 在 DIVA 数据集上评估模型,该数据集是未修剪的安全视频数据集。
相关工作
- 动作分类:以CNN为代表的工作,双流 C3D等
- 现有的动作检测方法分类:end-to-end systems、proposal-based systems(端到端、基于提案)
模型框架
提案的方法我们的方法由三个不同的模块组成。
第一个从给定的未修剪视频序列生成与类无关的时空提案。
第二个模块使用深度 3D-CNN 对这些生成的建议执行动作分类和时间定位。
最后一个模块是后处理步骤,执行 3D 非极大值抑制 (NMS) 以实现精确的动作检测。
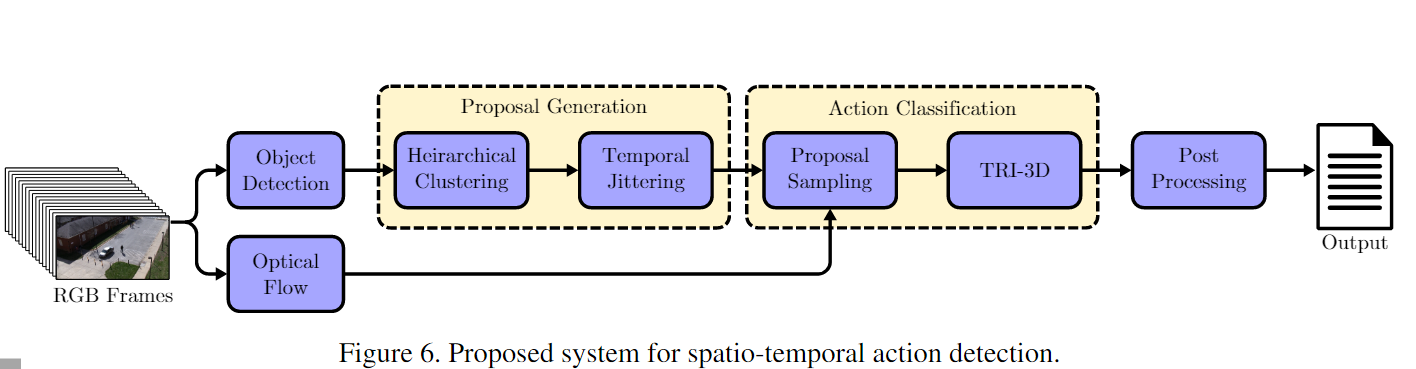
Action Proposal Generation
行动建议生成阶段的主要目标是从视频中生成具有高召回率且不考虑精度的时空长方体 (spatio-temporal cuboids) 。尽管时空空间中的滑动窗口搜索是提案生成的可行方法,但其计算成本非常昂贵。另一种解决方案是使用无监督方法对视频中的时空区域进行聚类。在我们的方法中,我们通过使用分层聚类在时空域中对从 Mask-RCNN 获得的逐帧对象检测进行分组来生成动作建议。生成的提案会进一步暂时抖动,以提高整体召回率。
Hierarchical Clustering
使用 Mask-RCNN 检测到的对象由 3 维特征向量 (x, y, f ) 表示,其中 (x, y) 表示对象边界框的中心,f 表示帧号。
Dense Action Proposals with Temporal Jittering
令现有提案的开始帧和结束帧分别由 fst 和 fend 表示。
首先通过沿着时间轴从 fst 滑动到以 s 的步幅来选择锚框。由此选择的锚帧是(fst,fst + s,fst + 2s,fst + 3s,…,fend)。于每个锚框 fa,我们生成四组具有时间边界的提案集 (fa − 16, fa + 16), (fa − 32, fa + 32)(64)(128)
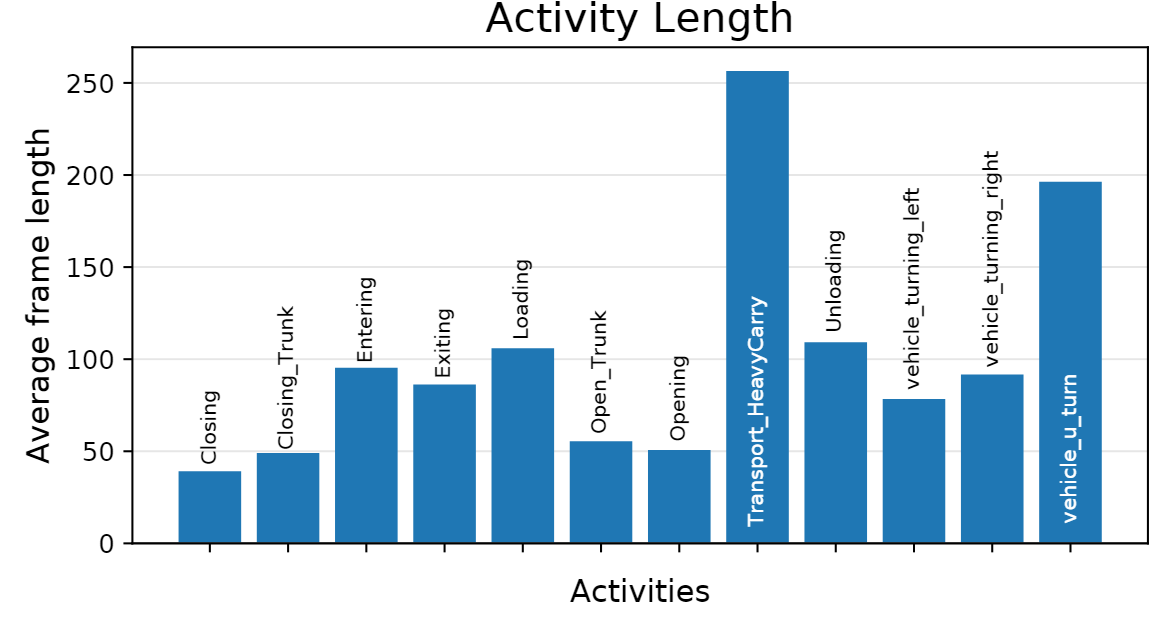
数据集DIV的动作是在32-256帧内的。
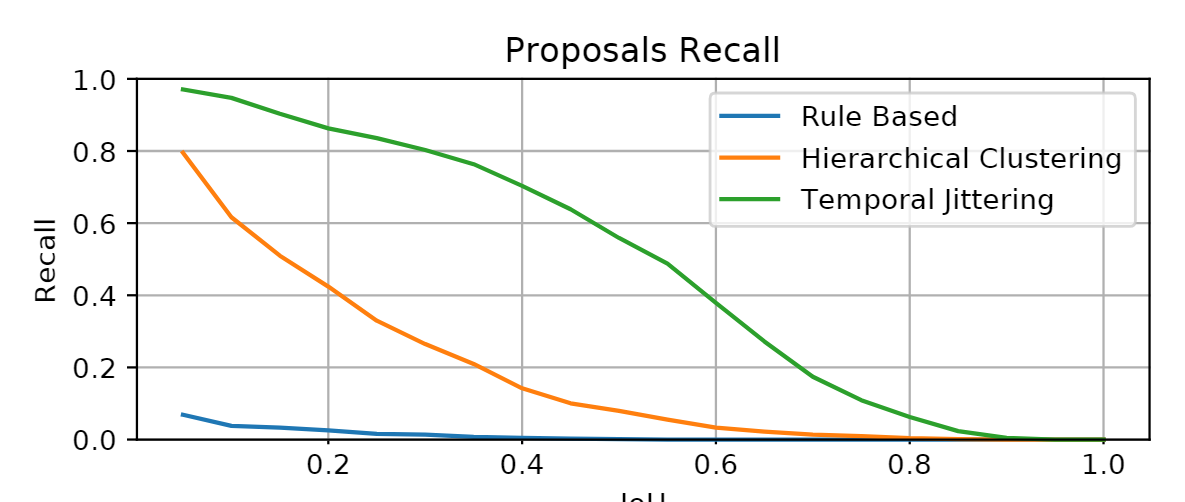
对比中,可以看到,提出的方法确实有效。
Input Pre-processing
介绍了论文中提出的TRI-3D模型的输入预处理。首先,模型输入的是64 x 224 x 224的光流帧,这些帧是使用TV-L1光流算法计算得出的。由于生成的密集提议框的宽高比是任意的,因此需要对其进行填充和裁剪。为了处理不同数量的帧,会对每个提议框在时间跨度上进行等间隔采样。然后,将裁剪后的立方体从光流视频中采样,并将其大小调整为256 x 256,然后在训练期间随机采样224 x 224的裁剪。在训练时,对除了非对称动作(如向左转弯、向右转弯和掉头)之外的所有训练样例应用随机水平翻转来提高网络的鲁棒性。最后,TRI-3D网络使用光流帧作为输入,而不是使用双流I3D网络。