本文从如下7个维度,带你全面理解Redis的最佳实践和优化:
- 内存
- 性能
- 可靠性
- 运维
- 安全
- 资源规划
- 监控
1、如何节省内存
1.1、控制Key的长度
- 在开发业务时,要提前预估Redis中写入key的数量,如果key数量达到了百万级别,那过长的key也会占用过多的内存空间
- 在保证key简单、清晰的前提下,key要尽可能地简短,这对内存的优化非常直接和高效
1.2、避免存储bigkey
- 如果大量存储bigkey(value过大或过多),会占用大量Redis内存;此外,客户端读写bigkey也会产生性能问题
- 避免Redis存储bigkey,建议如下:
1)String类型:控制在10KB以下
2)List/Hash/Set/ZSet:元素数量控制在1万以下
1.3、选择合适的数据类型
- Redis提供了丰富的数据类型,这些数据类型底层对应着多种数据结构来实现(可进一步节约内存资源):如,String、Set在存储int数据时,会采用整数编码来存储;Hash、ZSet在存储元素较少时,会采用压缩列表(ZipList)存储,在元素较多时,会转为哈希表(HashTable)和跳表(SkipList)存储 ==》 Hash:HashTable;ZSet:HashTable + SkipTable
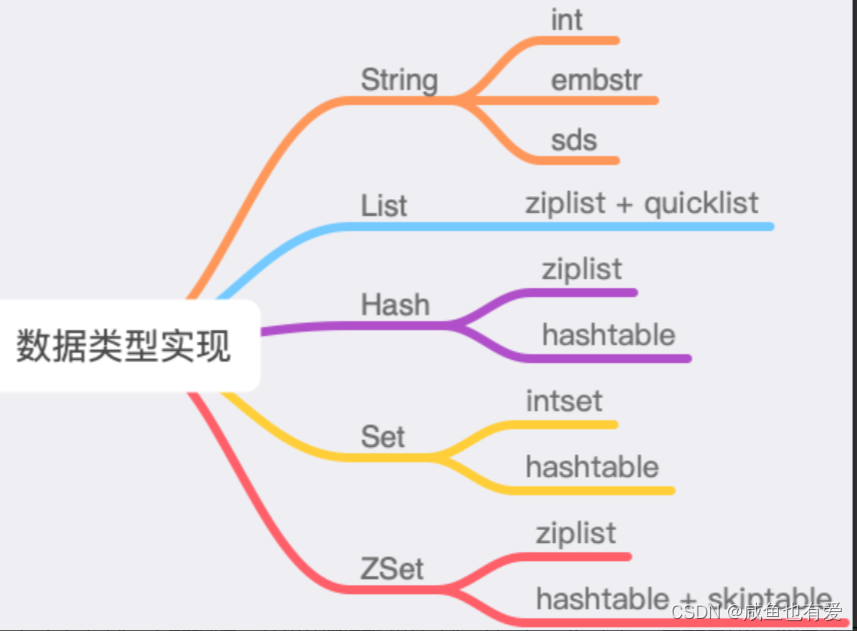
- 利用如上数据存储的特性,建议如下:
1)String、Set:尽量存储int类型数据
2)List/Hash/Set/Zset:存储的元素数量尽可能地控制在转换阈值之下(元素数量尽量控制在1万以下),以便节省内存
1.4、把Redis当做缓存而非数据库
- 要把Redis当作缓存而非数据库,即Redis只存储经常访问的热点数据,以此保证较高的内存利用率
- 写入到Redis中的数据,尽可能设置过期时间
- 业务应用在Redis中无法查询到数据时,才从后端数据库查询并加载到Redis
1.5、设置内存上限和淘汰策略
- Redis中key都设置了过期时间,但如果业务应用写入数据量很大,并设置的过期时间比较久,则短期内Redis内存依旧会快速增长。如果控制Redis内存的上限,就会导致使用过多的内存资源
- 对于此种场景,你需要提前预估业务数据量,并为Redis实例设置maxmemory来控制实例的内存上限,如此来避免Redis占用内存持增长
- 此外,还需要结合业务特点设置数据的淘汰策略(默认情况下,推荐使用allkeys-lru)
1)基于LFU算法的淘汰策略(对是否设置了过期时间TTL进行再分类)
allkeys-lfu:对全体key,基于LFU算法进行淘汰(默认推荐)
volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
2)基于LFU算法的淘汰策略(对是否设置了过期时间TTL进行再分类)
allkeys-lru:对全体key,基于LRU算法进行淘汰
volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰
3)随机淘汰(对是否设置了过期时间TTL进行再分类)
allkeys-random:对全体key ,随机进行淘汰
volatile-random:对设置了TTL的key ,随机进行淘汰
4)其他
volatile-ttl:对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略
1.6、数据压缩后写入Redis
- 如果想进一步优化Redis内存,还可以在业务应用中先将数据压缩,再写入到Redis(采用snappy、gzip等压缩算法),但是,客户端在读取压缩存储的数据时要解压数据,这会消耗一定的CPU资源,这需要根据实际情况来权衡
2、如何发挥Redis的高性能
- 在使用Redis时,往往需要我们关注于如何持续发挥Redis的高性能,从而避免操作延迟的情况发生,结合实战经验给出的建议如下:
2.1、避免存储bigkey
- 由于Redis处理请求是单线程的,当写入一个bigkey时,会在内存分配上耗费较多时间,导致操作延迟会增加,同理,删除bigkey会耗时地释放内存
- 在读取bigkey时,会在
网络数据传输上花费更多时间,后续执行的请求会发生排队,导致Redis性能下降 - 如果确实有存储bigkey的需求,可以将bigkey拆分为多个小key存储
2.2、开启lazy-free机制
- 如果无法避免存储bigkey的情况,建议开启Redis的lazy-free机制。当开启lazy-free后,删除bigkey时释放内存的耗时操作将会交由后台线程去执行,如此以避免对主线程的影响
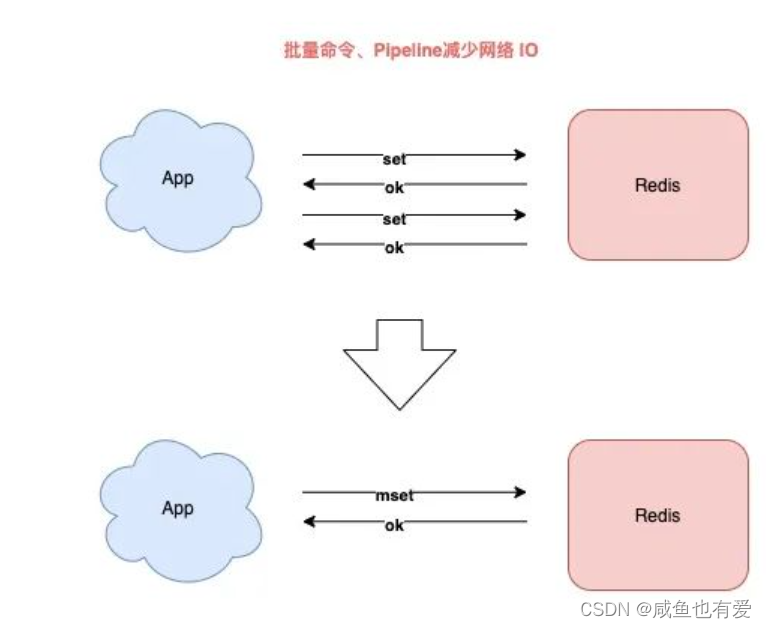
2.3、批量命令代替单个命令
- 当需要一次性操作多个key时,推荐使用批量命令来处理,相较于多次单个操作的优势在于,可减少客户端和服务端之间的网络IO次数
1)String或Hash结构使用MGET/MSET代替GET/SET命令,HMGET/HMSET代替HGET/HSET命令
2)其他数据类型使用Pipeline,一次性打包发送多个命令到服务端执行
2.4、注意DEL操作的时间复杂度
- 当删除String类型的Key时,时间复杂度为O(1)
- 当删除数据类型为List、Hash、Set、ZSet,时间复杂度为O(N),N为集合的元素个数,即集合中的元素越多,DEL操作花费时间越多,原因在于删除大量元素时,需要依次回收每个元素占用的内存,元素越多,花费时间也就越久,该过程在主线程中执行,存在阻塞主线程的风险,推荐分批删除,操作如下:
- List类型:多次执行LPOP/RPOP,直到所有元素都删除完成
Hash/Set/ZSet类型:先对应执行HSCAN/SSCAN/SCAN查询元素,再对应执行HDEL/ SREM / ZREM依次删除每个元素
2)
2.5、避免key集中过期
- Redis通过定时+懒惰的方式来清理过期key,该过程在主线程中执行
- 如果业务中存在大量key过期的情况,Redis在清理过期key的过程中,存在主线程阻塞的风险,可以通过给过期时间增加一个随机值,将key的过期时间分散开来,从而避免大量key集中过期对主线程的影响

2.6、使用长连接操作Redis,合理配置连接池
- 业务应用要使用长连接操作Redis,而非短连接
- 当使用短连接操作Redis时,每次都需要经过TCP三次握手,四次挥手,会徒增操作耗时
- 客户端应该使用连接池的方式访问Redis,并设置合理的参数,长时间不操作Redis时,应及时释放连接资源
2.7、只使用db0
- Redis尽管提供了16个db,但推荐只使用db0,理由如下:
1)在一个连接上操作多个db数据时,每次都需要执行SELECT,会给Redis带来额外的压力
2)Redis Cluster只支持db0,如果想要在集群中迁移数据,迁移成本会很高
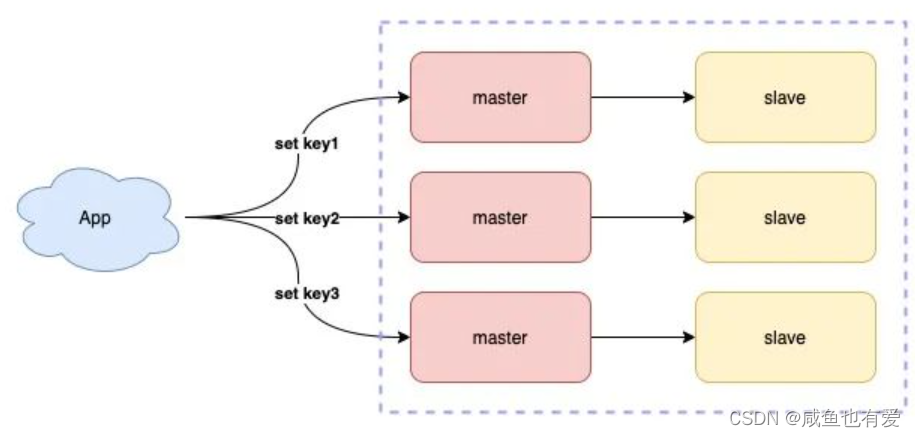
2.8、使用读写分离 & 分片集群
- 如果
业务读请求量很大,则可以采用部署多个从库的方式,实现读写分离,通过Redis的从库来分担读请求的压力,进而提升性能
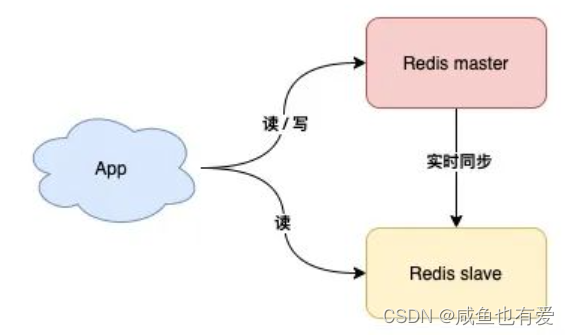
- 如果
业务写请求量很大,单个Redis实例已经无法支撑写流量,则可以使用分片集群来减轻写请求的压力