文本分类优化方法
文本分类是NLP的基础工作之一,也是文本机器学习中最常见的监督学习任务之一,情感分类,新闻分类,相似度判断、问答匹配、意图识别、推断等等领域都使用到了文本分类的相关知识或技术。文本分类技术在机器学习的发展过程中也不断的进行技术迭代,在开始介绍文本分类优化方法之前,我们先介绍文本分类的技术发展,有助于我们了解文本分类的技术痛点以及文本分类的技术方向。
文本分类的技术发展
文本特征向量
文本特征向量方式一般是指通过获取文本特征向量后通过BOE(Bag of Embeddings) 将多个文本特征进行融合,获取文本特征的方法有TFIDF、Word Embedding、OneHot等方式,下面是 Word2Vec 算法示意图:

通过文本特征获取文本表示,最终通过BOE的方式来融合多个文本特征,最终文本的最终表示。
文本特征向量方法主要缺点是语义特征不够丰富,以及上下文信息缺失。
神经网络模型
传统神经网络模型应用在NLP文本表示的算法主要是以下两种:CNN 和 RNN,这两种算法相对 BOE 算法的优势在于考虑文本上下文信息,在 BOE 算法中直接是将单个字和词的表示通过 SUM 或者 MEAN 融合起来,这样的方法主要的弊端在于没有考虑上下文,因此在 CNN 或者 RNN 的方法中主要是考虑文本的上下文关系,下面是RNN算法的算法示意图:
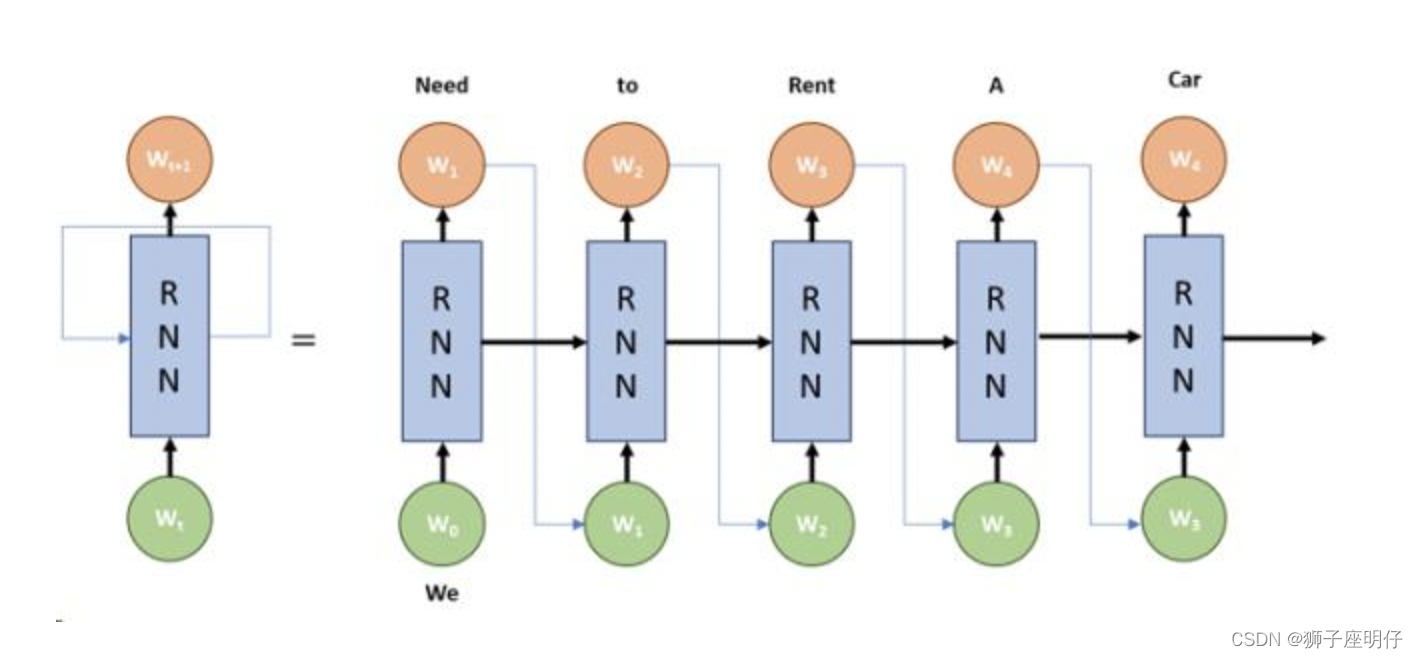
RNN的相关算法的出现使 NLP 场景中文本分类任务的效果有较大提升。
RNN 相关方法主要缺点是上下文本信息长度较短,训练梯度容易梯度消失。
预训练模型
预训练模型一般以 Transformer 为模型结构,以 Pretrain 方式训练的模型, 预训练主要分为两大分支,一支是自编码语言模型(Autoencoder Language Model),自回归语言模型(Autoregressive Language Model)。目前在文本分类任务中主要以自编码语言模型为主,这里中文经典模型包括了 BERT 、 ERNIE 、Mengzi等模型。

预训练模型是新一代NLP场景技术,预训练模型优点在于
- 模型结构注重文本上下文,并且可以捕捉较长的文本信息
- 很多知识在 Pretrain 阶段融入模型参数中
- 模型结构特性让更大的模型具备更好的效果
目前预训练模型在文本分类效果中非常突出,因此我们下面主要是以预训练模型来构建NLP的文本分类应用,并使用预训练模型解决实际的文本分类应用场景。
问题
预训练模型目前在NLP场景中使用相关广泛,目前在文本分类场景中使用预训练模型来是技术趋势,那使用预训练模型来文本分类目前还会遇到什么问题吗?有没有一种端到端预训练模型文本分类解决方案能快速帮助用户上线了? 我们进行文本分类业务落地的过程中我们遇到以下的一些问题:
数据标注成本高
在预训练模型时代,非常多的预训练模型做了开源,例如 BERT、ERNIE 、T5 、Roformer 等中文预训练模型,模型的获取成本相对比较低,目前使用预训练模型来做文本分类,最大的成本在于训练数据获取,与数据相关的机器学习成本主要表现在数据集方面,包括数据集获取、数据标注等。Dimensional Research代表 Alegion 所做的一项最新研究表明,所有组织中的 96%都遇到了与训练数据质量和数量相关的问题。
同一项研究表明,大多数项目需要超过 100,000 个数据样本才能表现良好,外包 10 万个数据样本的初始成本可能会增加大约 2500 至 5,000 美元。

模型调优成本高
在深度学习领域中模型可解释性是一个相对比较突出的问题,在预训练模型时代这个问题依然相对突出,模型使用者只知道把文本输入到模型中,最终模型输出了相应的结果,这里就会面临一个问题,如果的模型效果不佳,一般的使用者完全不知道如何调优模型,这个是预训练模型的一个非常大的使用成本。

很多使用者在预训练模型进行文本分类的过程中发现预训练模型效果不好,同时发现目前很少的工作能指导如何调优模型,直接让开发者直接就放弃了预训练模型分类方案。
模型算力成本高
预训练模型参数大小和模型结构复杂,导致在预测部署时有较高的算力要求,算力要求会导致很多工业生产环境无法部署上线,例如耗费一定的人力训练了一个效果较好的模型,但是最终无法部署上线,这种情况在工业部署环节时常遇到,那此时如何提升模型的计算效率?

优化方法
文本分类任务处理方案:
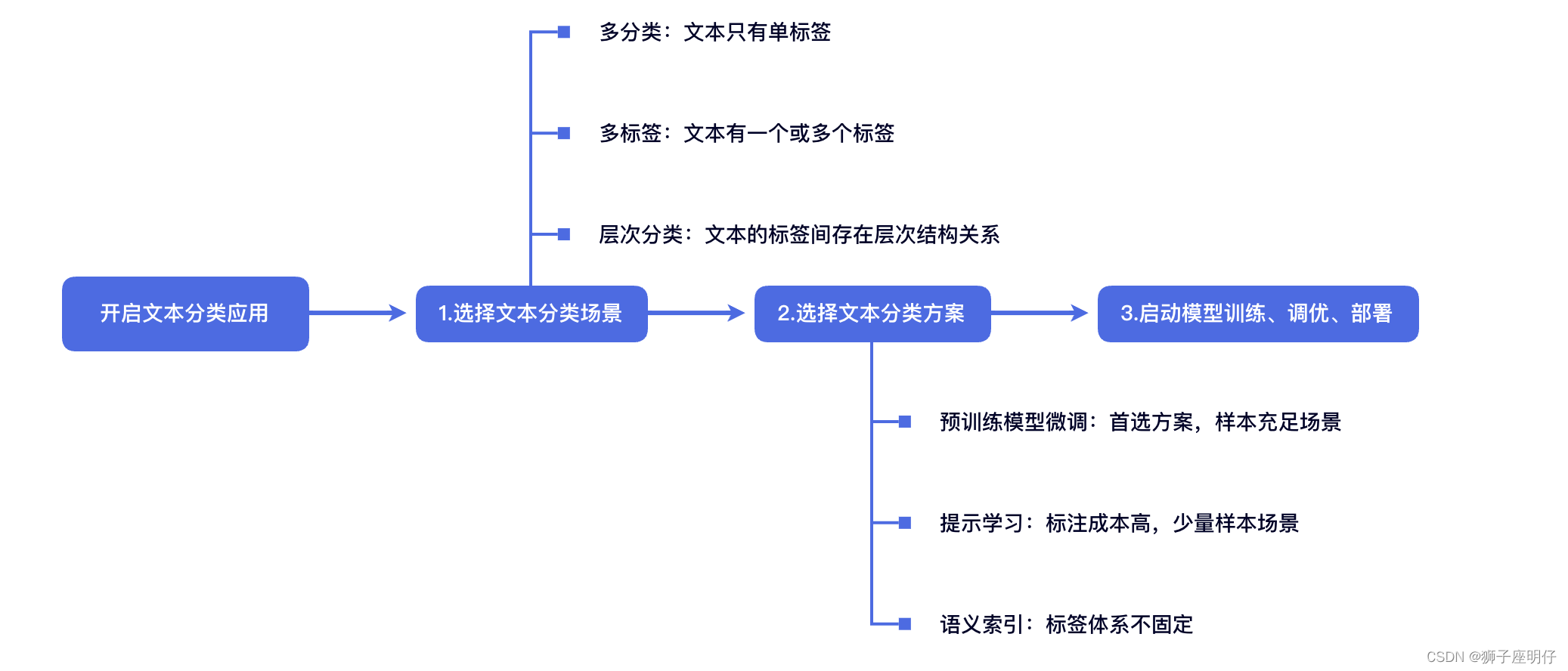
分类场景覆盖全
文本分类应用覆盖多分类(multi class)、多标签(multi label)、层级分类(或层次分类hierarchical)三种场景,我们将以下图的新闻文本分类为例介绍三种分类场景的区别。

多分类:数据集的标签集含有两个或两个以上的类别,所有输入句子/文本有且只有一个标签。在文本多分类场景中,我们需要预测输入句子/文本最可能来自 n 个标签类别中的哪一个类别。以上图多分类中新闻文本为例,该新闻文本的标签为娱乐。
多标签:数据集的标签集含有两个或两个以上的类别,输入句子/文本具有一个或多个标签。在文本多标签任务中,我们需要预测输入句子/文本可能来自 n 个标签类别中的哪几个类别。以上图多标签中新闻文本为例,该新闻文本具有相机和芯片两个标签。
层次分类:数据集的标签集具有多级标签且标签之间具有层级结构关系,输入句子/文本具有一个或多个标签。在文本层次分类任务中,我们需要预测输入句子/文本可能来自于不同级标签类别中的某一个或几个类别。以上图层次分类中新闻文本为例(新闻为根节点),该新闻一级分类标签为体育,二级分类标签为足球。
覆盖了三大文本分类场景,提供目前简单易用的方案,只需要通过制定好任务之后进入相关目录即可进行方案的实现。
模型方案全
方案一:预训练模型微调
对于大多数任务,推荐使用预训练模型微调作为首选的文本分类方案,该套方案就是在预训练模型基础上加上一个分类器,通过数据微调的方式来不断提升分类器的分类效果。
方案二:提示学习
预训练微调方案虽然适用的范围非常广,但是预训练微调对数据量的要求会比较高,那有什么方案可以进一步降低数据成本,加快产业落地了?提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。
提示学习的主要思想是将文本分类任务转换为构造提示中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]向量后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本, 策略,帮助提升模型效果。
我们以下图情感二分类任务为例来具体介绍提示学习流程,分类任务标签分为0:负向和1:正向 。在文本加入构造提示我[MASK]喜欢。 ,将情感分类任务转化为预测掩码 [MASK] 的待预测字是不还是很。具体实现方法是在掩码[MASK]的输出向量后接入线性分类器(二分类),然后用不和很的预训练向量来初始化分类器进行训练,分类器预测分类为0:不或1:很对应原始标签0:负向或1:正向。而预训练模型微调则是在预训练模型[CLS]向量接入随机初始化线性分类器进行训练,分类器直接预测分类为0:负向或1:正向。

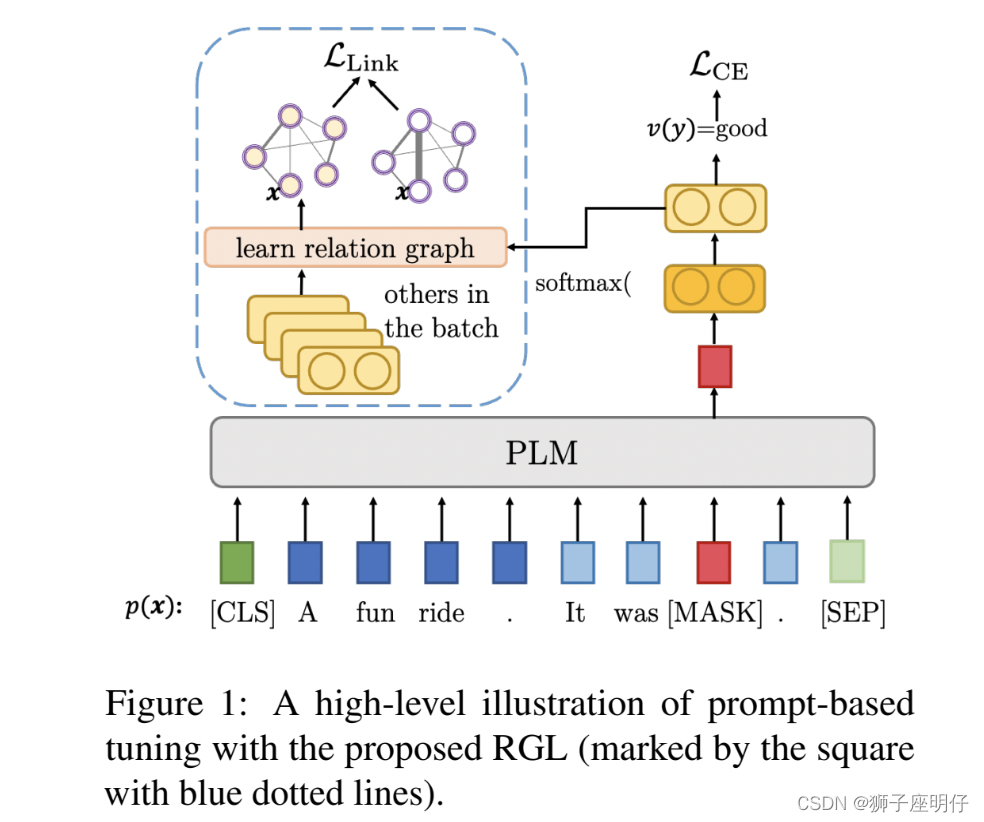
同时方案中也集成了百度最新的Prompt tuning SOTA 算法RGL,目前该算法已经发布在NCALL 2022中,其模型结构如下:
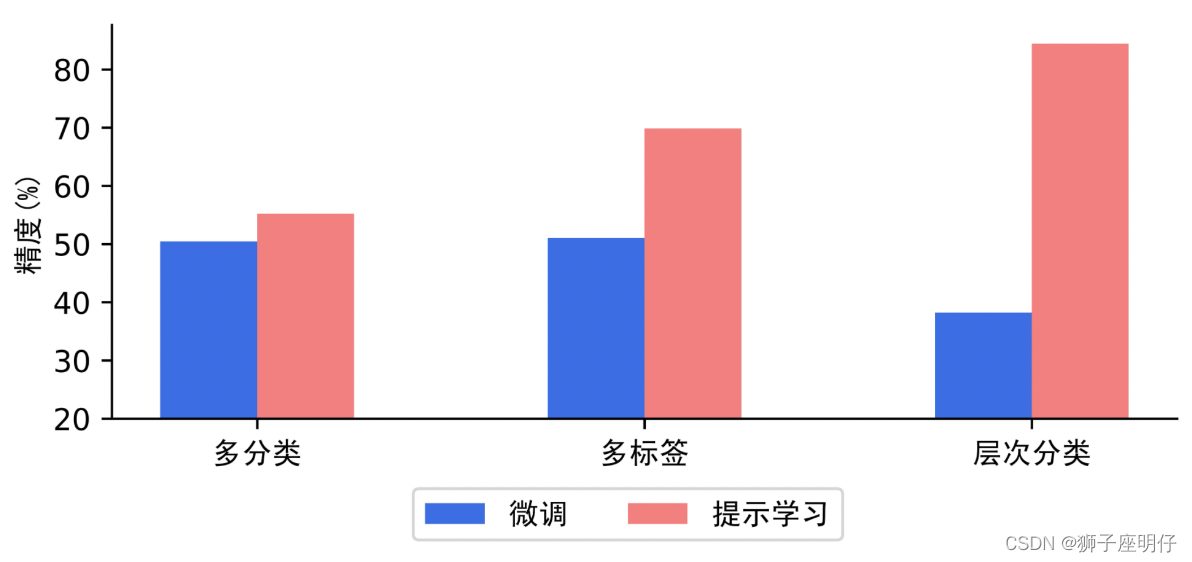
比较预训练模型微调与提示学习在多分类、多标签、层次分类小样本场景的模型表现(多分类精度为准确率,多标签和层次分类精度为Macro F1值),可以看到在样本较少的情况下,提示学习比预训练模型微调有明显优势。
方案三:语义索引
基于语义索引的文本分类方案适用于标签类别不固定的场景,对于新增标签类别或新的相关分类任务无需重新训练,模型仍然能获得较好预测效果,方案具有良好的拓展性。
语义索引目标是从海量候选召回集中快速、准确地召回一批与输入文本语义相关的文本。基于语义索引的文本分类方法具体来说是将标签集作为召回目标集,召回与输入文本语义相似的标签作为文本的标签类别。将语义检索的方法应用到文本分类的方案中,是一种创新探索,同时也会很好解决标签扩增的应用场景。

模型调优方法多
预训练模型由于它的可解释性较弱,会导致在模型训练完毕之后,可以做的模型调优方案非常少,大多数调参的方式就是学习率和 Batch Size 调整;但是在预训练模型时代,模型效果不佳大多数的原因都是集中在数据层面,例如数据中有『脏数据』、数据偏置、稀疏数据,这些数据问题都会导致模型的分类效果差;但是目前基于模型可解释性的模型调优方案非常少,目前在文本分类的应用中我们集成一套数据调优方案,该套方案是文本分类应用中非常大的特色。
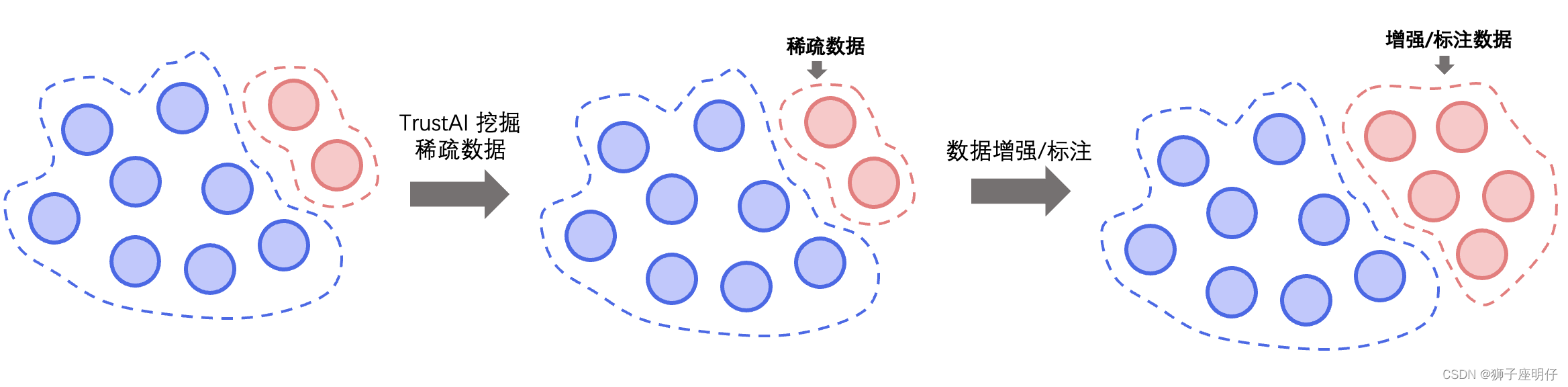
针对标注数据质量不高、训练数据覆盖不足、样本数量少等文本分类常见数据痛点,提供稀疏数据筛选、脏数据清洗、数据增强三种数据优化方案,解决训练数据缺陷问题,用低成本方式获得大幅度的效果提升。这些数据分析工具目前主要是集成在 TrustAI,通过实例级别的分析可以甄别出脏数据、稀疏数据。
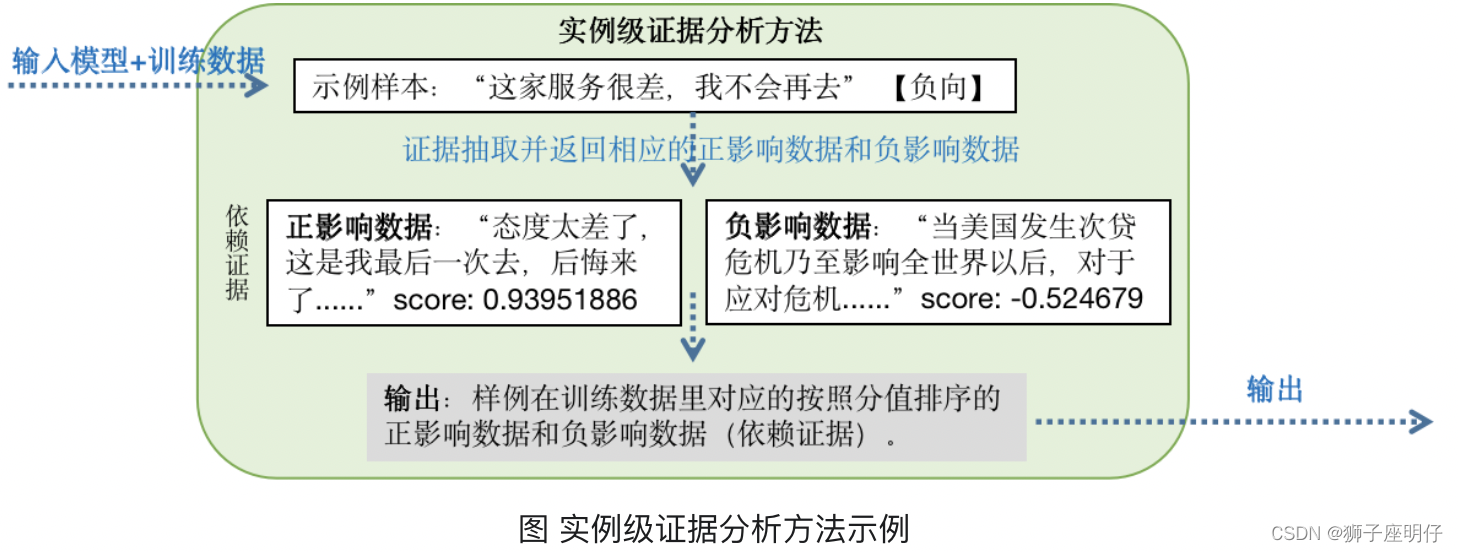
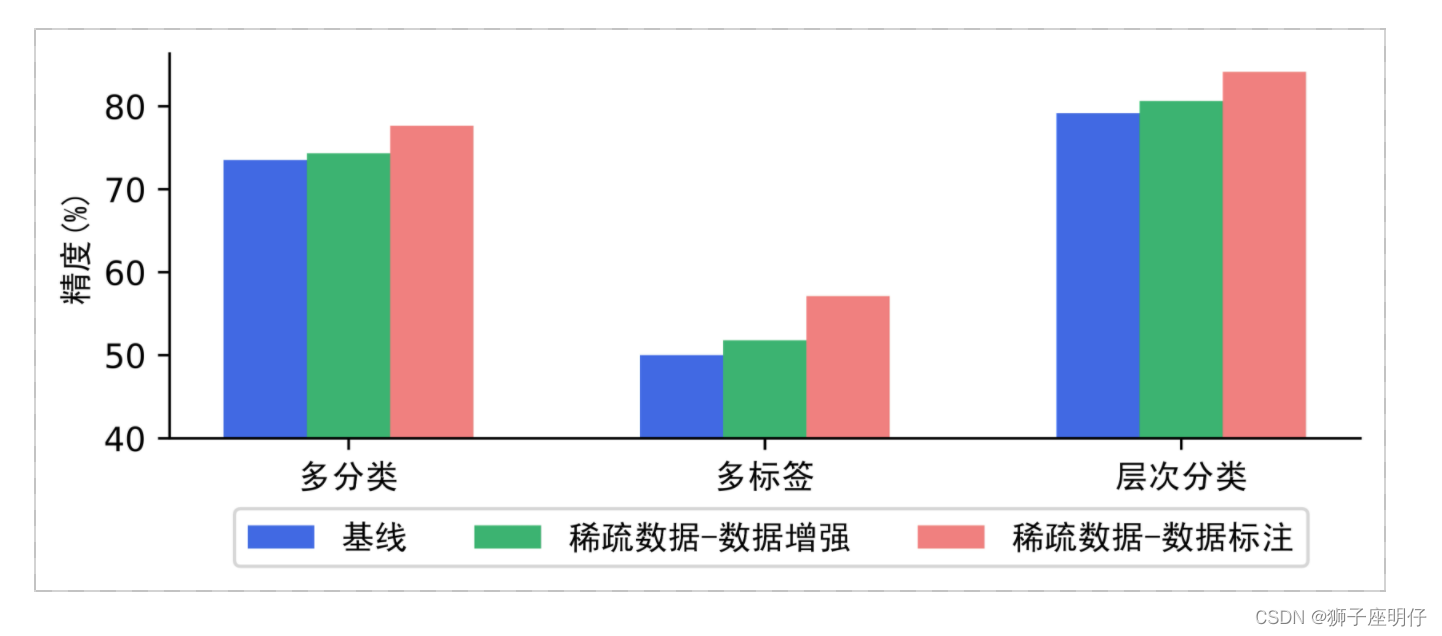
- 稀疏数据筛选基于特征相似度的实例级证据分析方法挖掘待预测数据中缺乏证据支持的数据(也即稀疏数据),并进行有选择的训练集数据增强或针对性筛选未标注数据进行标注来解决稀疏数据问题,有效提升模型表现。
我们采用在多分类、多标签、层次分类场景中评测稀疏数据-数据增强策略和稀疏数据-数据标注策略,下图表明稀疏数据筛选方案在各场景能够有效提高模型表现(多分类精度为准确率,多标签和层次分类精度为Macro F1值)。
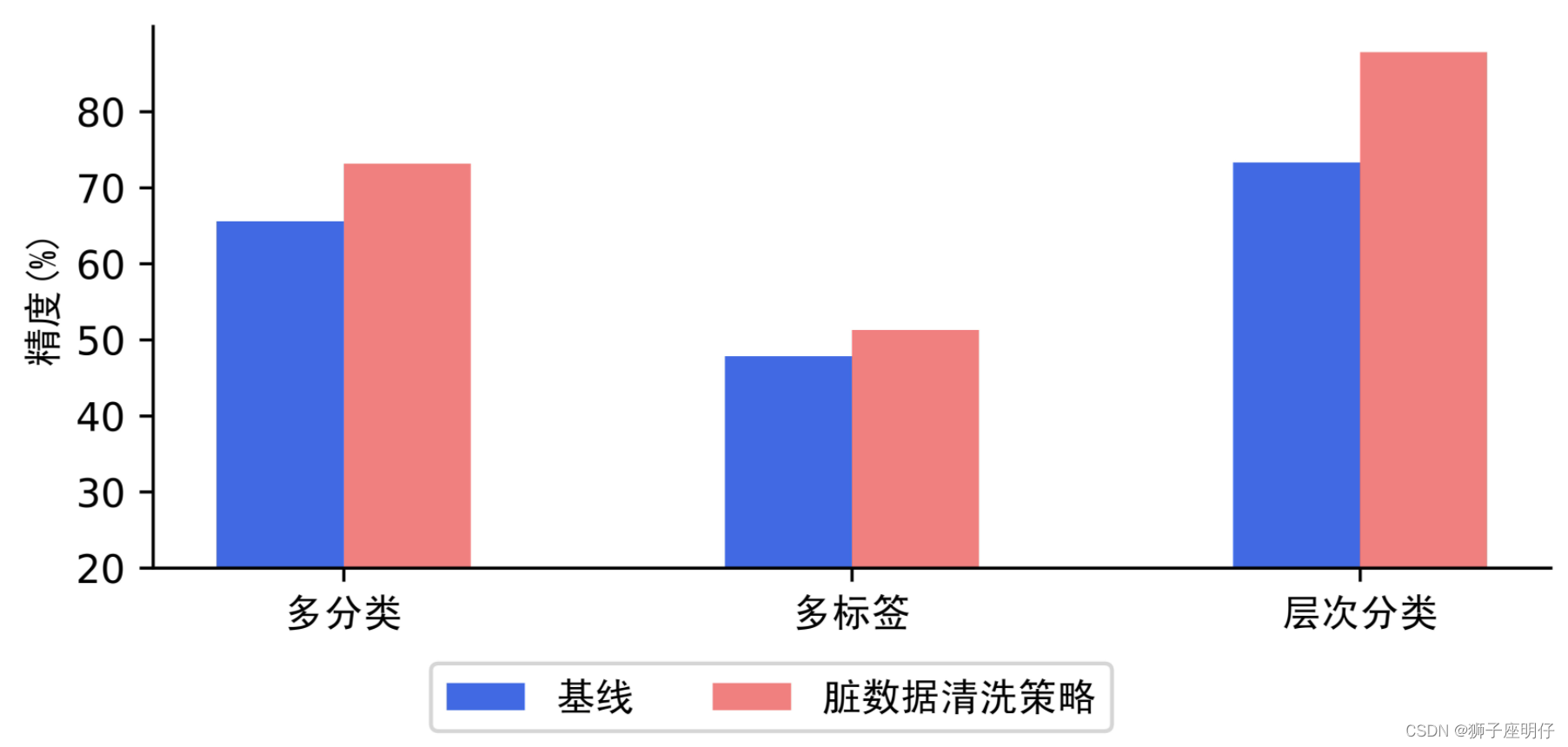
- 脏数据清洗基于表示点方法的实例级证据分析方法,例如通过逻辑回归等表示点学习方法来甄别脏数据。脏数据清洗方案通过高效识别训练集中脏数据(也即标注质量差的数据),有效降低人力检查成本。

我们采用在多分类、多标签、层次分类场景中评测脏数据清洗方案,实验表明方案能够高效筛选出训练集中脏数据,提高模型表现(多分类精度为准确率,多标签和层次分类精度为Macro F1值)。
- 数据增强在数据量较少的情况下能够通过增加数据集多样性,提升模型效果。数据增强,包括词替换、词删除、词插入、词置换、基于上下文生成词(MLM预测)、TF-IDF等多种数据增强策略。以CAIL2019—婚姻家庭要素提取数据子集(500条)为例,我们在数据集应用多种数据增强策略,策略效果如下表。

后续工作
- 打磨目前文本分类方案,将补齐短文本分类、长文本分类方案
- 文本分类任务统一,Prompt tuning(提示学习)打造文本分类更好的零样本、小样本能力
Reference
- NLP发新打卡课-文本分类
- PaddlePaddle/PaddleNLP
- TrustAI
- 文本分类应用