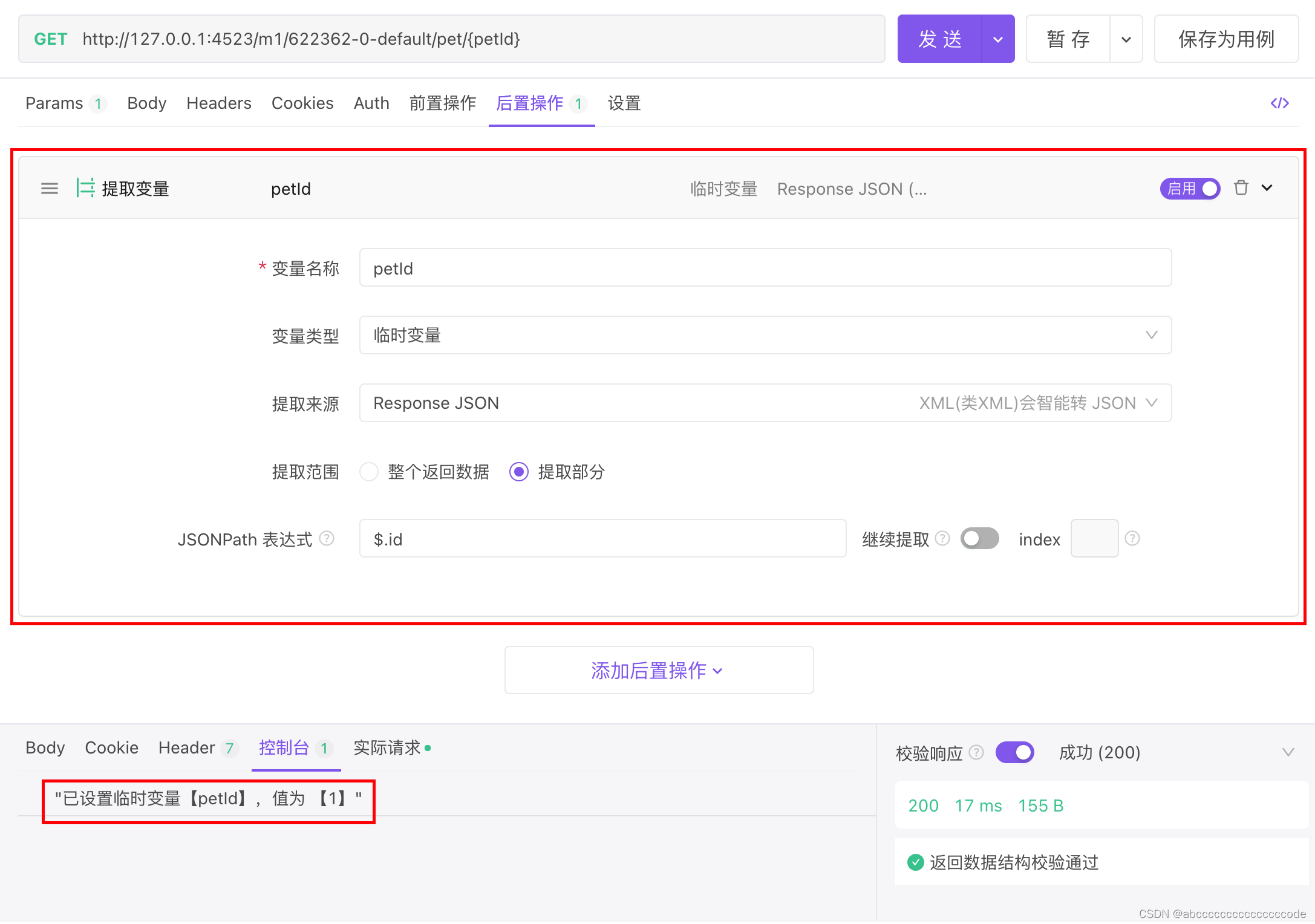
v$sql 表字段说明:
sql_id:唯一性标识;
sql_fulltext:SQL执行内容;
elapsed_time:消逝时间,即自然耗费的时间,单位是微妙,10的-6次方秒;
cpu_time:cpu花费时间,和cpu核数有关,单位是微妙,10的-6次方秒;
案例一:
新上线程序,表进行初始化1千万数据初始化完毕后,发现查询很卡。
执行的SQL:
SELECT *
FROM (SELECT tmp.*, rownum row_id
FROM (SELECT line_id
,header_id
,code_company
,code_cc
,expense_nature
,natural_account
,sub_account
/**
省略
*/
FROM tml_je_lines
WHERE (header_id = :1)
ORDER BY line_id ASC) tmp
WHERE rownum <= :2)
WHERE row_id > :3查询 v$sql表和AWR报告,这个SQL大概每次执行时间耗费83s。tml_je_lines.header_id是有索引的,这个耗费时间有点不理解。
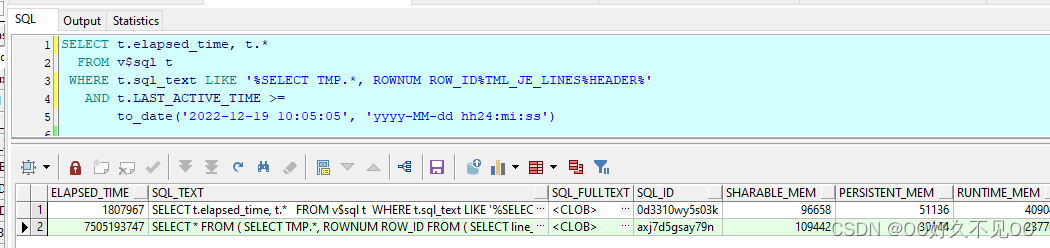
重新收集这张表的信息
begin
-- Call the procedure
sys.dbms_stats.gather_table_stats(ownname => 'HDM',
tabname => 'TML_DMS_JE');
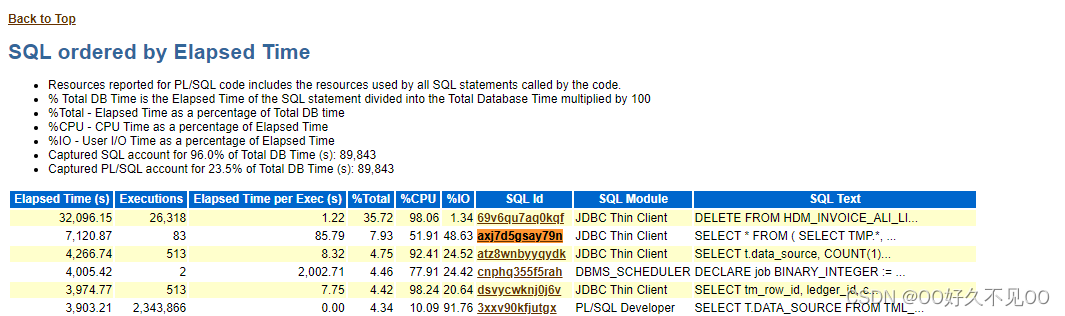
end;查看sql_id:axj7d5gsay79n 的SQL执行路线,发现是系统还是对tml_je_lines做了全表扫描。
SELECT sys.dbms_xplan.display_cursor(sql_id => 'axj7d5gsay79n'
,cursor_child_no => 0
,format => 'TYPICAL')
FROM dual;
tml_je_lines.header_id对应的索引是OK,为什么它还是不走索引了。可能是以下原因:
SQL查询需要分析耗费时间成本,生成最佳执行计划(根据索引和数据分布), 在执行相同的SQL时,在v$sql表中已经由该SQL,程序还是用走相同的执行计划,哪怕执行计划错误。所以我们需要去掉缓存里面sql_id:axj7d5gsay79n这条SQL的缓存,让它重新生成最佳执行计划。

清除缓存池的v$sql 该条数据。重新查询,发现每次耗费的时间就很短了。
SELECT 'begin sys.dbms_shared_pool.purge(''' || t.address || ',' ||
t.hash_value || ''',''c'');end;' sql_text
,sql_id
,address
,hash_value
,executions
,loads
,parse_calls
,invalidations
FROM v$sql t
WHERE t.sql_id = 'axj7d5gsay79n'
BEGIN
sys.dbms_shared_pool.purge('000000039E18DC28,4038008116', 'c');
END;






![[附源码]Python计算机毕业设计Django颐养天年辅助平台](https://img-blog.csdnimg.cn/d57f463eb46c4e20860358245f566a33.png)