为什么要使用异步组件
- 节省打包出的结果,异步组件分开打包,采用
jsonp的方式进行加载,有效解决文件过大的问题。 - 核心就是包组件定义变成一个函数,依赖
import()语法,可以实现文件的分割加载。
components:{
AddCustomerSchedule:(resolve)=>import("../components/AddCustomer") // require([])
}
原理
export function ( Ctor: Class<Component> | Function | Object | void, data: ?VNodeData, context: Component, children: ?Array<VNode>, tag?: string ): VNode | Array<VNode> | void {
// async component
let asyncFactory
if (isUndef(Ctor.cid)) {
asyncFactory = Ctor
Ctor = resolveAsyncComponent(asyncFactory, baseCtor) // 默认调用此函数时返回 undefiend
// 第二次渲染时Ctor不为undefined
if (Ctor === undefined) {
return createAsyncPlaceholder( // 渲染占位符 空虚拟节点
asyncFactory,
data,
context,
children,
tag
)
}
}
}
function resolveAsyncComponent ( factory: Function, baseCtor: Class<Component> ): Class<Component> | void {
if (isDef(factory.resolved)) {
// 3.在次渲染时可以拿到获取的最新组件
return factory.resolved
}
const resolve = once((res: Object | Class<Component>) => {
factory.resolved = ensureCtor(res, baseCtor)
if (!sync) {
forceRender(true) //2. 强制更新视图重新渲染
} else {
owners.length = 0
}
})
const reject = once(reason => {
if (isDef(factory.errorComp)) {
factory.error = true forceRender(true)
}
})
const res = factory(resolve, reject)// 1.将resolve方法和reject方法传入,用户调用 resolve方法后
sync = false
return factory.resolved
}
谈谈你对MVVM的理解
为什么要有这些模式,目的:职责划分、分层(将Model层、View层进行分类)借鉴后端思想,对于前端而已,就是如何将数据同步到页面上
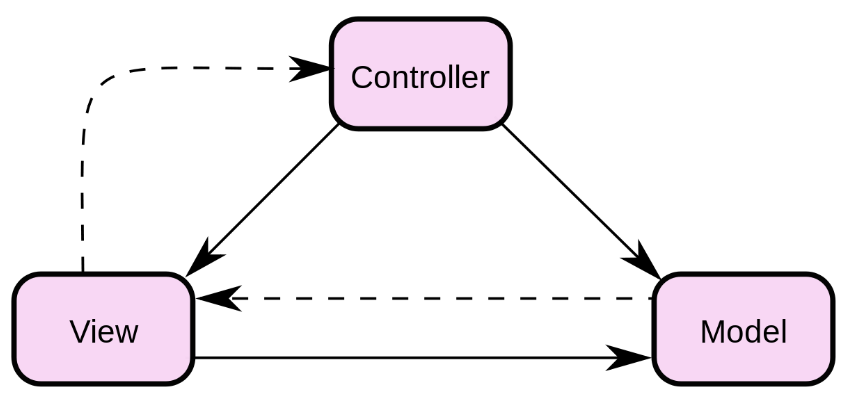
MVC模式 代表:Backbone + underscore + jquery
- 传统的
MVC指的是,用户操作会请求服务端路由,路由会调用对应的控制器来处理,控制器会获取数据。将结果返回给前端,页面重新渲染 MVVM:传统的前端会将数据手动渲染到页面上,MVVM模式不需要用户收到操作dom元素,将数据绑定到viewModel层上,会自动将数据渲染到页面中,视图变化会通知viewModel层 更新数据。ViewModel就是我们MVVM模式中的桥梁
MVVM模式 映射关系的简化,隐藏了controller
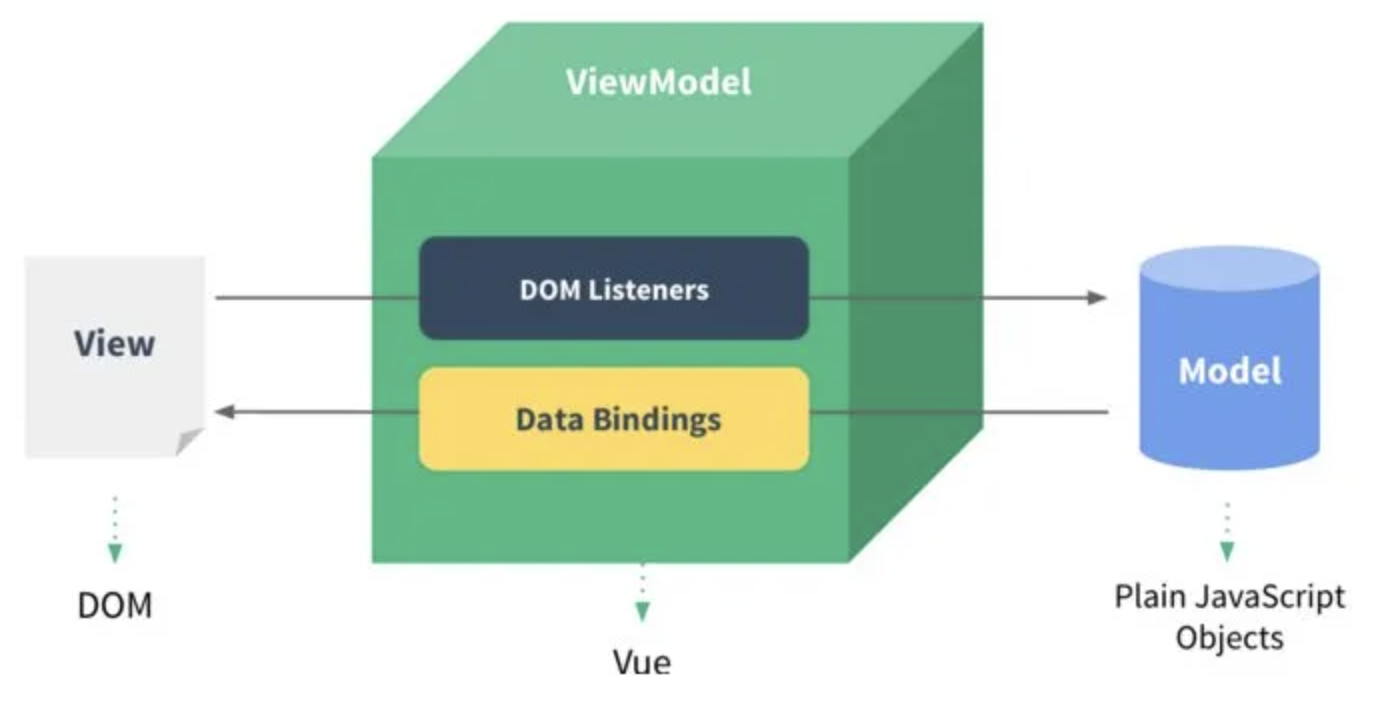
MVVM是Model-View-ViewModel缩写,也就是把MVC中的Controller演变成ViewModel。Model层代表数据模型,View代表UI组件,ViewModel是View和Model层的桥梁,数据会绑定到viewModel层并自动将数据渲染到页面中,视图变化的时候会通知viewModel层更新数据。
Model: 代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑。我们可以把Model称为数据层,因为它仅仅关注数据本身,不关心任何行为View: 用户操作界面。当ViewModel对Model进行更新的时候,会通过数据绑定更新到ViewViewModel: 业务逻辑层,View需要什么数据,ViewModel要提供这个数据;View有某些操作,ViewModel就要响应这些操作,所以可以说它是Model for View.
总结 : MVVM模式简化了界面与业务的依赖,解决了数据频繁更新。MVVM 在使用当中,利用双向绑定技术,使得 Model 变化时,ViewModel 会自动更新,而 ViewModel 变化时,View 也会自动变化。
我们以下通过一个 Vue 实例来说明 MVVM 的具体实现
<!-- View 层 -->
<div id="app">
<p>{{message}}</p>
<button v-on:click="showMessage()">Click me</button>
</div>
// ViewModel 层
var app = new Vue({
el: '#app',
data: { // 用于描述视图状态
message: 'Hello Vue!',
},
methods: { // 用于描述视图行为
showMessage(){
let vm = this;
alert(vm.message);
}
},
created(){
let vm = this;
// Ajax 获取 Model 层的数据
ajax({
url: '/your/server/data/api',
success(res){
vm.message = res;
}
});
}
})
// Model 层
{
"url": "/your/server/data/api",
"res": {
"success": true,
"name": "test",
"domain": "www.baidu.com"
}
}
如何保存页面的当前的状态
既然是要保持页面的状态(其实也就是组件的状态),那么会出现以下两种情况:
- 前组件会被卸载
- 前组件不会被卸载
那么可以按照这两种情况分别得到以下方法:
组件会被卸载:
(1)将状态存储在LocalStorage / SessionStorage
只需要在组件即将被销毁的生命周期 componentWillUnmount (react)中在 LocalStorage / SessionStorage 中把当前组件的 state 通过 JSON.stringify() 储存下来就可以了。在这里面需要注意的是组件更新状态的时机。
比如从 B 组件跳转到 A 组件的时候,A 组件需要更新自身的状态。但是如果从别的组件跳转到 B 组件的时候,实际上是希望 B 组件重新渲染的,也就是不要从 Storage 中读取信息。所以需要在 Storage 中的状态加入一个 flag 属性,用来控制 A 组件是否读取 Storage 中的状态。
优点:
- 兼容性好,不需要额外库或工具。
- 简单快捷,基本可以满足大部分需求。
缺点:
- 状态通过 JSON 方法储存(相当于深拷贝),如果状态中有特殊情况(比如 Date 对象、Regexp 对象等)的时候会得到字符串而不是原来的值。(具体参考用 JSON 深拷贝的缺点)
- 如果 B 组件后退或者下一页跳转并不是前组件,那么 flag 判断会失效,导致从其他页面进入 A 组件页面时 A 组件会重新读取 Storage,会造成很奇怪的现象
(2)路由传值
通过 react-router 的 Link 组件的 prop —— to 可以实现路由间传递参数的效果。
在这里需要用到 state 参数,在 B 组件中通过 history.location.state 就可以拿到 state 值,保存它。返回 A 组件时再次携带 state 达到路由状态保持的效果。
优点:
- 简单快捷,不会污染 LocalStorage / SessionStorage。
- 可以传递 Date、RegExp 等特殊对象(不用担心 JSON.stringify / parse 的不足)
缺点:
- 如果 A 组件可以跳转至多个组件,那么在每一个跳转组件内都要写相同的逻辑。
组件不会被卸载:
(1)单页面渲染
要切换的组件作为子组件全屏渲染,父组件中正常储存页面状态。
优点:
- 代码量少
- 不需要考虑状态传递过程中的错误
缺点:
- 增加 A 组件维护成本
- 需要传入额外的 prop 到 B 组件
- 无法利用路由定位页面
除此之外,在Vue中,还可以是用keep-alive来缓存页面,当组件在keep-alive内被切换时组件的activated、deactivated这两个生命周期钩子函数会被执行
被包裹在keep-alive中的组件的状态将会被保留:
<keep-alive>
<router-view v-if="$route.meta.keepAlive"></router-view>
</kepp-alive>
router.js
{
path: '/',
name: 'xxx',
component: ()=>import('../src/views/xxx.vue'),
meta:{
keepAlive: true // 需要被缓存
}
},
Vue是如何收集依赖的?
在初始化 Vue 的每个组件时,会对组件的 data 进行初始化,就会将由普通对象变成响应式对象,在这个过程中便会进行依赖收集的相关逻辑,如下所示∶
function defieneReactive (obj, key, val){
const dep = new Dep();
...
Object.defineProperty(obj, key, {
...
get: function reactiveGetter () {
if(Dep.target){
dep.depend();
...
}
return val
}
...
})
}
以上只保留了关键代码,主要就是 const dep = new Dep()实例化一个 Dep 的实例,然后在 get 函数中通过 dep.depend() 进行依赖收集。 (1)Dep Dep是整个依赖收集的核心,其关键代码如下:
class Dep {
static target;
subs;
constructor () {
...
this.subs = [];
}
addSub (sub) {
this.subs.push(sub)
}
removeSub (sub) {
remove(this.sub, sub)
}
depend () {
if(Dep.target){
Dep.target.addDep(this)
}
}
notify () {
const subs = this.subds.slice();
for(let i = 0;i < subs.length; i++){
subs[i].update()
}
}
}
Dep 是一个 class ,其中有一个关 键的静态属性 static,它指向了一个全局唯一 Watcher,保证了同一时间全局只有一个 watcher 被计算,另一个属性 subs 则是一个 Watcher 的数组,所以 Dep 实际上就是对 Watcher 的管理,再看看 Watcher 的相关代码∶
(2)Watcher
class Watcher {
getter;
...
constructor (vm, expression){
...
this.getter = expression;
this.get();
}
get () {
pushTarget(this);
value = this.getter.call(vm, vm)
...
return value
}
addDep (dep){
...
dep.addSub(this)
}
...
}
function pushTarget (_target) {
Dep.target = _target
}
Watcher 是一个 class,它定义了一些方法,其中和依赖收集相关的主要有 get、addDep 等。
(3)过程
在实例化 Vue 时,依赖收集的相关过程如下∶
初 始 化 状 态 initState , 这 中 间 便 会 通 过 defineReactive 将数据变成响应式对象,其中的 getter 部分便是用来依赖收集的。
初始化最终会走 mount 过程,其中会实例化 Watcher ,进入 Watcher 中,便会执行 this.get() 方法,
updateComponent = () => {
vm._update(vm._render())
}
new Watcher(vm, updateComponent)
get 方法中的 pushTarget 实际上就是把 Dep.target 赋值为当前的 watcher。
this.getter.call(vm,vm),这里的 getter 会执行 vm._render() 方法,在这个过程中便会触发数据对象的 getter。那么每个对象值的 getter 都持有一个 dep,在触发 getter 的时候会调用 dep.depend() 方法,也就会执行 Dep.target.addDep(this)。刚才 Dep.target 已经被赋值为 watcher,于是便会执行 addDep 方法,然后走到 dep.addSub() 方法,便将当前的 watcher 订阅到这个数据持有的 dep 的 subs 中,这个目的是为后续数据变化时候能通知到哪些 subs 做准备。所以在 vm._render() 过程中,会触发所有数据的 getter,这样便已经完成了一个依赖收集的过程。
常见的事件修饰符及其作用
.stop:等同于 JavaScript 中的event.stopPropagation(),防止事件冒泡;.prevent:等同于 JavaScript 中的event.preventDefault(),防止执行预设的行为(如果事件可取消,则取消该事件,而不停止事件的进一步传播);.capture:与事件冒泡的方向相反,事件捕获由外到内;.self:只会触发自己范围内的事件,不包含子元素;.once:只会触发一次。
Vue 单页应用与多页应用的区别
概念:
- SPA单页面应用(SinglePage Web Application),指只有一个主页面的应用,一开始只需要加载一次js、css等相关资源。所有内容都包含在主页面,对每一个功能模块组件化。单页应用跳转,就是切换相关组件,仅仅刷新局部资源。
- MPA多页面应用 (MultiPage Application),指有多个独立页面的应用,每个页面必须重复加载js、css等相关资源。多页应用跳转,需要整页资源刷新。
参考 前端进阶面试题详细解答
Computed 和 Watch 的区别
对于Computed:
- 它支持缓存,只有依赖的数据发生了变化,才会重新计算
- 不支持异步,当Computed中有异步操作时,无法监听数据的变化
- computed的值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data声明过,或者父组件传递过来的props中的数据进行计算的。
- 如果一个属性是由其他属性计算而来的,这个属性依赖其他的属性,一般会使用computed
- 如果computed属性的属性值是函数,那么默认使用get方法,函数的返回值就是属性的属性值;在computed中,属性有一个get方法和一个set方法,当数据发生变化时,会调用set方法。
对于Watch:
- 它不支持缓存,数据变化时,它就会触发相应的操作
- 支持异步监听
- 监听的函数接收两个参数,第一个参数是最新的值,第二个是变化之前的值
- 当一个属性发生变化时,就需要执行相应的操作
- 监听数据必须是data中声明的或者父组件传递过来的props中的数据,当发生变化时,会触发其他操作,函数有两个的参数:
- immediate:组件加载立即触发回调函数
- deep:深度监听,发现数据内部的变化,在复杂数据类型中使用,例如数组中的对象发生变化。需要注意的是,deep无法监听到数组和对象内部的变化。
当想要执行异步或者昂贵的操作以响应不断的变化时,就需要使用watch。
总结:
- computed 计算属性 : 依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值。
- watch 侦听器 : 更多的是观察的作用,无缓存性,类似于某些数据的监听回调,每当监听的数据变化时都会执行回调进行后续操作。
运用场景:
- 当需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时都要重新计算。
- 当需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许执行异步操作 ( 访问一个 API ),限制执行该操作的频率,并在得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
Vue中如何检测数组变化
前言
Vue 不能检测到以下数组的变动:
- 当你利用索引直接设置一个数组项时,例如:
vm.items[indexOfItem] = newValue - 当你修改数组的长度时,例如:
vm.items.length = newLength
Vue 提供了以下操作方法
// Vue.set
Vue.set(vm.items, indexOfItem, newValue)
// vm.$set,Vue.set的一个别名
vm.$set(vm.items, indexOfItem, newValue)
// Array.prototype.splice
vm.items.splice(indexOfItem, 1, newValue)
分析
数组考虑性能原因没有用
defineProperty对数组的每一项进行拦截,而是选择对7种数组(push,shift,pop,splice,unshift,sort,reverse)方法进行重写(AOP切片思想)
所以在 Vue 中修改数组的索引和长度是无法监控到的。需要通过以上 7 种变异方法修改数组才会触发数组对应的 watcher 进行更新
- 用函数劫持的方式,重写了数组方法,具体呢就是更改了数组的原型,更改成自己的,用户调数组的一些方法的时候,走的就是自己的方法,然后通知视图去更新
- 数组里每一项可能是对象,那么我就是会对数组的每一项进行观测,(且只有数组里的对象才能进行观测,观测过的也不会进行观测)
原理
Vue将data中的数组,进行了原型链重写。指向了自己定义的数组原型方法,这样当调用数组api时,可以通知依赖更新,如果数组中包含着引用类型。会对数组中的引用类型再次进行监控。
手写简版分析
let oldArray = Object.create(Array.prototype);
['shift', 'unshift', 'push', 'pop', 'reverse','sort'].forEach(method => {
oldArray[method] = function() { // 这里可以触发页面更新逻辑
console.log('method', method)
Array.prototype[method].call(this,...arguments);
}
});
let arr = [1,2,3];
arr.__proto__ = oldArray;
arr.unshift(4);
源码分析
// 拿到数组原型拷贝一份
const arrayProto = Array.prototype
// 然后将arrayMethods继承自数组原型
// 这里是面向切片编程思想(AOP)--不破坏封装的前提下,动态的扩展功能
export const arrayMethods = Object.create(arrayProto)
const methodsToPatch = [ 'push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse' ]
methodsToPatch.forEach(function (method) { // 重写原型方法
const original = arrayProto[method] // 调用原数组的方法
def(arrayMethods, method, function mutator (...args) {
// 这里保留原型方法的执行结果
const result = original.apply(this, args)
// 这句话是关键
// this代表的就是数据本身 比如数据是{a:[1,2,3]} 那么我们使用a.push(4) this就是a ob就是a.__ob__ 这个属性就是上段代码增加的 代表的是该数据已经被响应式观察过了指向Observer实例
const ob = this.__ob__
// 这里的标志就是代表数组有新增操作
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
// 如果有新增的元素 inserted是一个数组 调用Observer实例的observeArray对数组每一项进行观测
if (inserted) ob.observeArray(inserted)
ob.dep.notify() // 当调用数组方法后,手动通知视图更新
return result
})
})
this.observeArray(value) // 进行深度监控
vue3:改用proxy,可直接监听对象数组的变化
Vue 的父子组件生命周期钩子函数执行顺序
- 渲染顺序 :先父后子,完成顺序:先子后父
- 更新顺序 :父更新导致子更新,子更新完成后父
- 销毁顺序 :先父后子,完成顺序:先子后父
加载渲染过程
父 beforeCreate->父 created->父 beforeMount->子 beforeCreate->子 created->子 beforeMount->子 mounted->父 mounted。子组件先挂载,然后到父组件
子组件更新过程
父 beforeUpdate->子 beforeUpdate->子 updated->父 updated
父组件更新过程
父 beforeUpdate->父 updated
销毁过程
父 beforeDestroy->子 beforeDestroy->子 destroyed->父 destroyed
之所以会这样是因为
Vue创建过程是一个递归过程,先创建父组件,有子组件就会创建子组件,因此创建时先有父组件再有子组件;子组件首次创建时会添加mounted钩子到队列,等到patch结束再执行它们,可见子组件的mounted钩子是先进入到队列中的,因此等到patch结束执行这些钩子时也先执行。
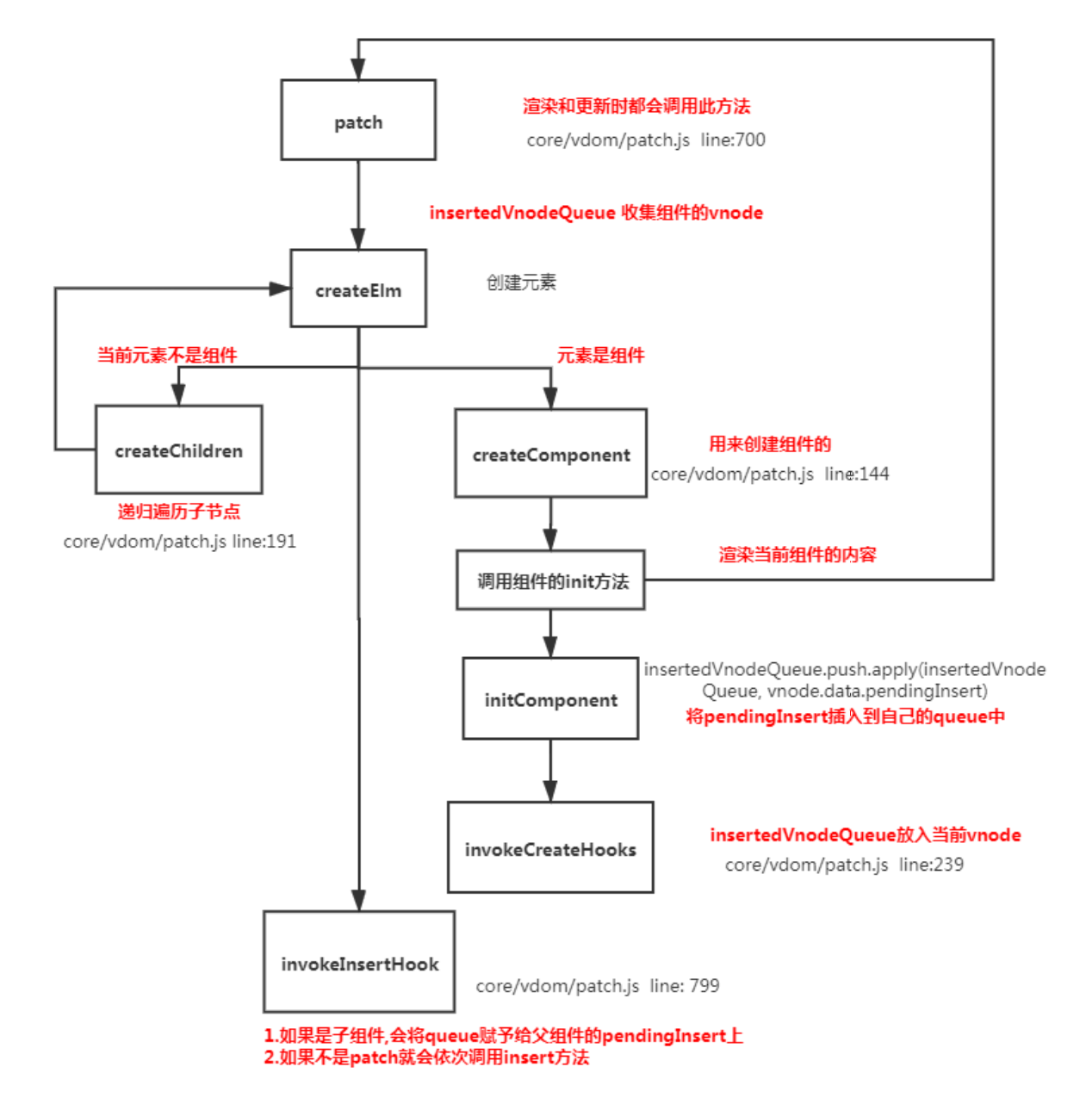
function patch (oldVnode, vnode, hydrating, removeOnly) {
if (isUndef(vnode)) {
if (isDef(oldVnode)) invokeDestroyHook(oldVnode) return
}
let isInitialPatch = false
const insertedVnodeQueue = [] // 定义收集所有组件的insert hook方法的数组 // somthing ...
createElm(
vnode,
insertedVnodeQueue, oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
)// somthing...
// 最终会依次调用收集的insert hook
invokeInsertHook(vnode, insertedVnodeQueue, isInitialPatch);
return vnode.elm
}
function createElm ( vnode, insertedVnodeQueue, parentElm, refElm, nested, ownerArray, index ) {
// createChildren 会递归创建儿子组件
createChildren(vnode, children, insertedVnodeQueue) // something...
}
// 将组件的vnode插入到数组中
function invokeCreateHooks (vnode, insertedVnodeQueue) {
for (let i = 0; i < cbs.create.length; ++i) {
cbs.create[i](emptyNode, vnode)
}
i = vnode.data.hook // Reuse variable
if (isDef(i)) {
if (isDef(i.create)) i.create(emptyNode, vnode)
if (isDef(i.insert)) insertedVnodeQueue.push(vnode)
}
}
// insert方法中会依次调用mounted方法
insert (vnode: MountedComponentVNode) {
const { context, componentInstance } = vnode
if (!componentInstance._isMounted) {
componentInstance._isMounted = true
callHook(componentInstance, 'mounted')
}
}
function invokeInsertHook (vnode, queue, initial) {
// delay insert hooks for component root nodes, invoke them after the // element is really inserted
if (isTrue(initial) && isDef(vnode.parent)) {
vnode.parent.data.pendingInsert = queue
} else {
for (let i = 0; i < queue.length; ++i) {
queue[i].data.hook.insert(queue[i]); // 调用insert方法
}
}
}
Vue.prototype.$destroy = function () {
callHook(vm, 'beforeDestroy')
// invoke destroy hooks on current rendered tree
vm.__patch__(vm._vnode, null) // 先销毁儿子
// fire destroyed hook
callHook(vm, 'destroyed')
}
Vue组件data为什么必须是个函数?
- 根实例对象
data可以是对象也可以是函数 (根实例是单例),不会产生数据污染情况 - 组件实例对象
data必须为函数 一个组件被复用多次的话,也就会创建多个实例。本质上,这些实例用的都是同一个构造函数。如果data是对象的话,对象属于引用类型,会影响到所有的实例。所以为了保证组件不同的实例之间data不冲突,data必须是一个函数,
简版理解
// 1.组件的渲染流程 调用Vue.component -> Vue.extend -> 子类 -> new 子类
// Vue.extend 根据用户定义产生一个新的类
function Vue() {}
function Sub() { // 会将data存起来
this.data = this.constructor.options.data();
}
Vue.extend = function(options) {
Sub.options = options; // 静态属性
return Sub;
}
let Child = Vue.extend({
data:()=>( { name: 'zf' })
});
// 两个组件就是两个实例, 希望数据互不感染
let child1 = new Child();
let child2 = new Child();
console.log(child1.data.name);
child1.data.name = 'poetry';
console.log(child2.data.name);
// 根不需要 任何的合并操作 根才有vm属性 所以他可以是函数和对象 但是组件mixin他们都没有vm 所以我就可以判断 当前data是不是个函数
相关源码
// 源码位置 src/core/global-api/extend.js
export function initExtend (Vue: GlobalAPI) {
Vue.extend = function (extendOptions: Object): Function {
extendOptions = extendOptions || {}
const Super = this
const SuperId = Super.cid
const cachedCtors = extendOptions._Ctor || (extendOptions._Ctor = {})
if (cachedCtors[SuperId]) {
return cachedCtors[SuperId]
}
const name = extendOptions.name || Super.options.name
if (process.env.NODE_ENV !== 'production' && name) {
validateComponentName(name)
}
const Sub = function VueComponent (options) {
this._init(options)
}
// 子类继承大Vue父类的原型
Sub.prototype = Object.create(Super.prototype)
Sub.prototype.constructor = Sub
Sub.cid = cid++
Sub.options = mergeOptions(
Super.options,
extendOptions
)
Sub['super'] = Super
// For props and computed properties, we define the proxy getters on
// the Vue instances at extension time, on the extended prototype. This
// avoids Object.defineProperty calls for each instance created.
if (Sub.options.props) {
initProps(Sub)
}
if (Sub.options.computed) {
initComputed(Sub)
}
// allow further extension/mixin/plugin usage
Sub.extend = Super.extend
Sub.mixin = Super.mixin
Sub.use = Super.use
// create asset registers, so extended classes
// can have their private assets too.
ASSET_TYPES.forEach(function (type) {
Sub[type] = Super[type]
})
// enable recursive self-lookup
if (name) {
Sub.options.components[name] = Sub // 记录自己 在组件中递归自己 -> jsx
}
// keep a reference to the super options at extension time.
// later at instantiation we can check if Super's options have
// been updated.
Sub.superOptions = Super.options
Sub.extendOptions = extendOptions
Sub.sealedOptions = extend({}, Sub.options)
// cache constructor
cachedCtors[SuperId] = Sub
return Sub
}
}
Vue 中给 data 中的对象属性添加一个新的属性时会发生什么?如何解决?
<template>
<div>
<ul>
<li v-for="value in obj" :key="value"> {{value}} </li> </ul> <button @click="addObjB">添加 obj.b</button> </div>
</template>
<script>
export default { data () { return { obj: { a: 'obj.a' } } }, methods: { addObjB () { this.obj.b = 'obj.b' console.log(this.obj) } } }
</script>
点击 button 会发现,obj.b 已经成功添加,但是视图并未刷新。这是因为在Vue实例创建时,obj.b并未声明,因此就没有被Vue转换为响应式的属性,自然就不会触发视图的更新,这时就需要使用Vue的全局 api $set():
addObjB () (
this.$set(this.obj, 'b', 'obj.b')
console.log(this.obj)
}
$set()方法相当于手动的去把obj.b处理成一个响应式的属性,此时视图也会跟着改变了。
$nextTick 原理及作用
Vue 的 nextTick 其本质是对 JavaScript 执行原理 EventLoop 的一种应用。
nextTick 的核心是利用了如 Promise 、MutationObserver、setImmediate、setTimeout的原生 JavaScript 方法来模拟对应的微/宏任务的实现,本质是为了利用 JavaScript 的这些异步回调任务队列来实现 Vue 框架中自己的异步回调队列。
nextTick 不仅是 Vue 内部的异步队列的调用方法,同时也允许开发者在实际项目中使用这个方法来满足实际应用中对 DOM 更新数据时机的后续逻辑处理
nextTick 是典型的将底层 JavaScript 执行原理应用到具体案例中的示例,引入异步更新队列机制的原因∶
- 如果是同步更新,则多次对一个或多个属性赋值,会频繁触发 UI/DOM 的渲染,可以减少一些无用渲染
- 同时由于 VirtualDOM 的引入,每一次状态发生变化后,状态变化的信号会发送给组件,组件内部使用 VirtualDOM 进行计算得出需要更新的具体的 DOM 节点,然后对 DOM 进行更新操作,每次更新状态后的渲染过程需要更多的计算,而这种无用功也将浪费更多的性能,所以异步渲染变得更加至关重要
Vue采用了数据驱动视图的思想,但是在一些情况下,仍然需要操作DOM。有时候,可能遇到这样的情况,DOM1的数据发生了变化,而DOM2需要从DOM1中获取数据,那这时就会发现DOM2的视图并没有更新,这时就需要用到了nextTick了。
由于Vue的DOM操作是异步的,所以,在上面的情况中,就要将DOM2获取数据的操作写在$nextTick中。
this.$nextTick(() => { // 获取数据的操作...})
所以,在以下情况下,会用到nextTick:
- 在数据变化后执行的某个操作,而这个操作需要使用随数据变化而变化的DOM结构的时候,这个操作就需要方法在
nextTick()的回调函数中。 - 在vue生命周期中,如果在created()钩子进行DOM操作,也一定要放在
nextTick()的回调函数中。
因为在created()钩子函数中,页面的DOM还未渲染,这时候也没办法操作DOM,所以,此时如果想要操作DOM,必须将操作的代码放在nextTick()的回调函数中。
v-if、v-show、v-html 的原理
- v-if会调用addIfCondition方法,生成vnode的时候会忽略对应节点,render的时候就不会渲染;
- v-show会生成vnode,render的时候也会渲染成真实节点,只是在render过程中会在节点的属性中修改show属性值,也就是常说的display;
- v-html会先移除节点下的所有节点,调用html方法,通过addProp添加innerHTML属性,归根结底还是设置innerHTML为v-html的值。
assets和static的区别
相同点: assets 和 static 两个都是存放静态资源文件。项目中所需要的资源文件图片,字体图标,样式文件等都可以放在这两个文件下,这是相同点
不相同点:assets 中存放的静态资源文件在项目打包时,也就是运行 npm run build 时会将 assets 中放置的静态资源文件进行打包上传,所谓打包简单点可以理解为压缩体积,代码格式化。而压缩后的静态资源文件最终也都会放置在 static 文件中跟着 index.html 一同上传至服务器。static 中放置的静态资源文件就不会要走打包压缩格式化等流程,而是直接进入打包好的目录,直接上传至服务器。因为避免了压缩直接进行上传,在打包时会提高一定的效率,但是 static 中的资源文件由于没有进行压缩等操作,所以文件的体积也就相对于 assets 中打包后的文件提交较大点。在服务器中就会占据更大的空间。
建议: 将项目中 template需要的样式文件js文件等都可以放置在 assets 中,走打包这一流程。减少体积。而项目中引入的第三方的资源文件如iconfoont.css 等文件可以放置在 static 中,因为这些引入的第三方文件已经经过处理,不再需要处理,直接上传。
vue3中 watch、watchEffect区别
watch是惰性执行,也就是只有监听的值发生变化的时候才会执行,但是watchEffect不同,每次代码加载watchEffect都会执行(忽略watch第三个参数的配置,如果修改配置项也可以实现立即执行)watch需要传递监听的对象,watchEffect不需要watch只能监听响应式数据:ref定义的属性和reactive定义的对象,如果直接监听reactive定义对象中的属性是不允许的(会报警告),除非使用函数转换一下。其实就是官网上说的监听一个getterwatchEffect如果监听reactive定义的对象是不起作用的,只能监听对象中的属性
看一下watchEffect的代码
<template>
<div>
请输入firstName:
<input type="text" v-model="firstName">
</div>
<div>
请输入lastName:
<input type="text" v-model="lastName">
</div>
<div>
请输入obj.text:
<input type="text" v-model="obj.text">
</div>
<div>
【obj.text】 {{obj.text}}
</div>
</template>
<script>
import {ref, reactive, watch, watchEffect} from 'vue'
export default {
name: "HelloWorld",
props: {
msg: String,
},
setup(props,content){
let firstName = ref('')
let lastName = ref('')
let obj= reactive({
text:'hello'
})
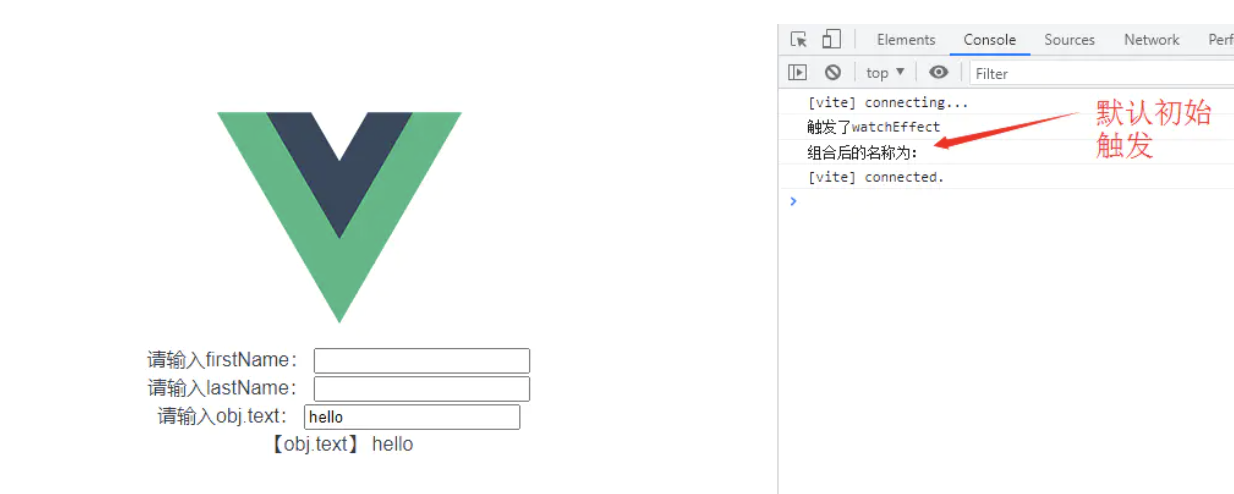
watchEffect(()=>{
console.log('触发了watchEffect');
console.log(`组合后的名称为:${firstName.value}${lastName.value}`)
})
return{
obj,
firstName,
lastName
}
}
};
</script>
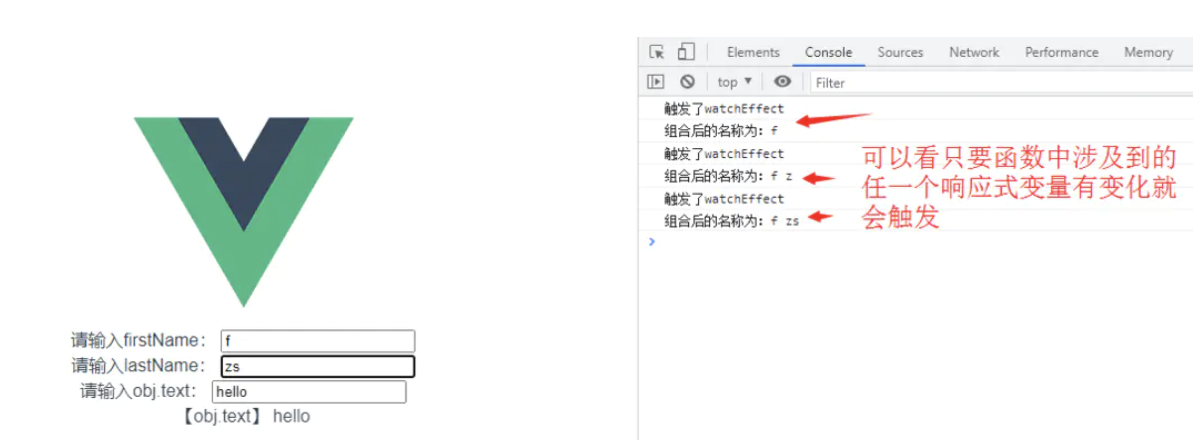
改造一下代码
watchEffect(()=>{
console.log('触发了watchEffect');
// 这里我们不使用firstName.value/lastName.value ,相当于是监控整个ref,对应第四点上面的结论
console.log(`组合后的名称为:${firstName}${lastName}`)
})
watchEffect(()=>{
console.log('触发了watchEffect');
console.log(obj);
})
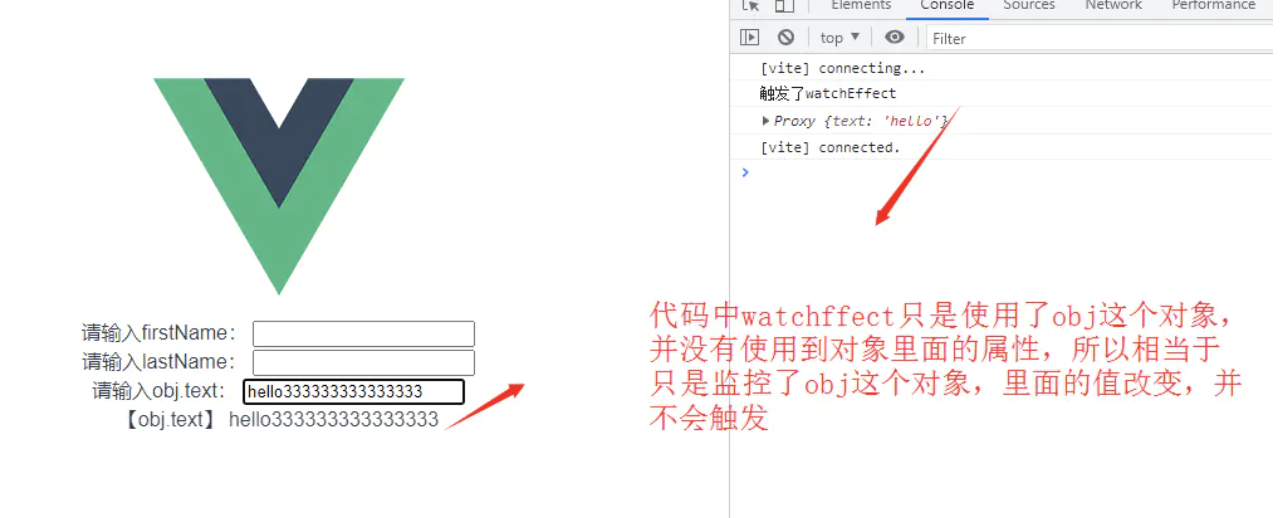
稍微改造一下
let obj = reactive({
text:'hello'
})
watchEffect(()=>{
console.log('触发了watchEffect');
console.log(obj.text);
})
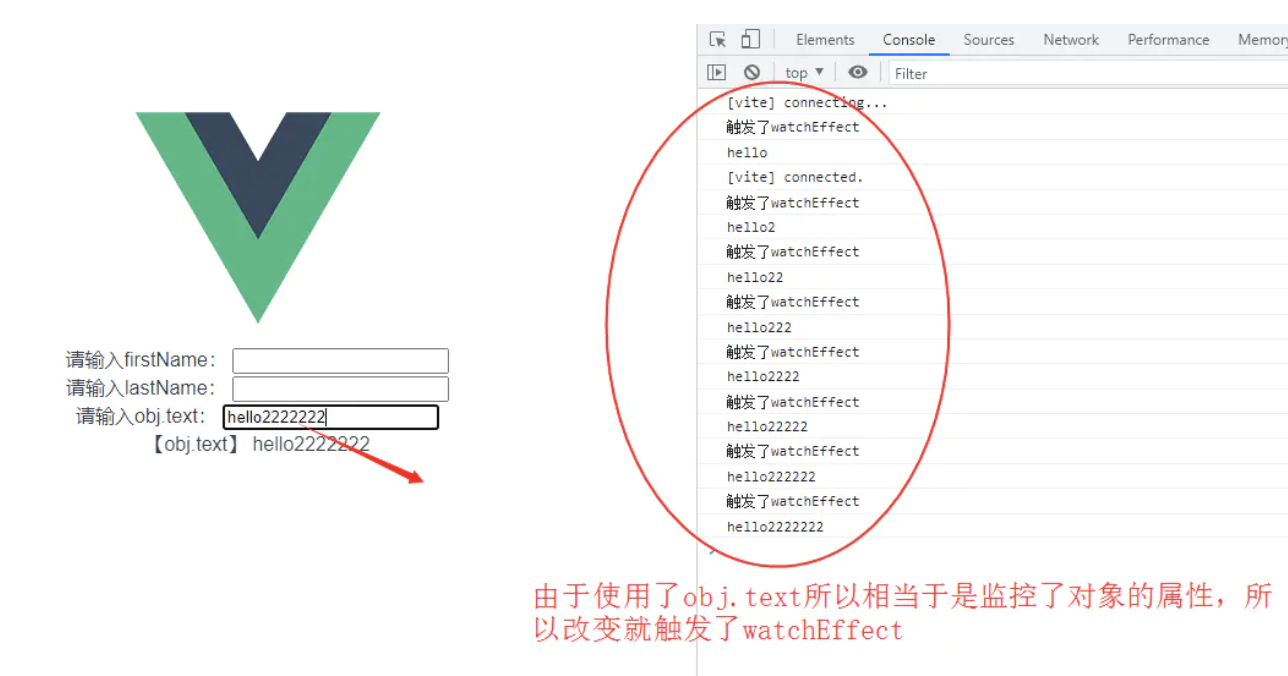
再看一下watch的代码,验证一下
let obj= reactive({
text:'hello'
})
// watch是惰性执行, 默认初始化之后不会执行,只有值有变化才会触发,可通过配置参数实现默认执行
watch(obj, (newValue, oldValue) => {
// 回调函数
console.log('触发监控更新了new', newValue);
console.log('触发监控更新了old', oldValue);
},{
// 配置immediate参数,立即执行,以及深层次监听
immediate: true,
deep: true
})
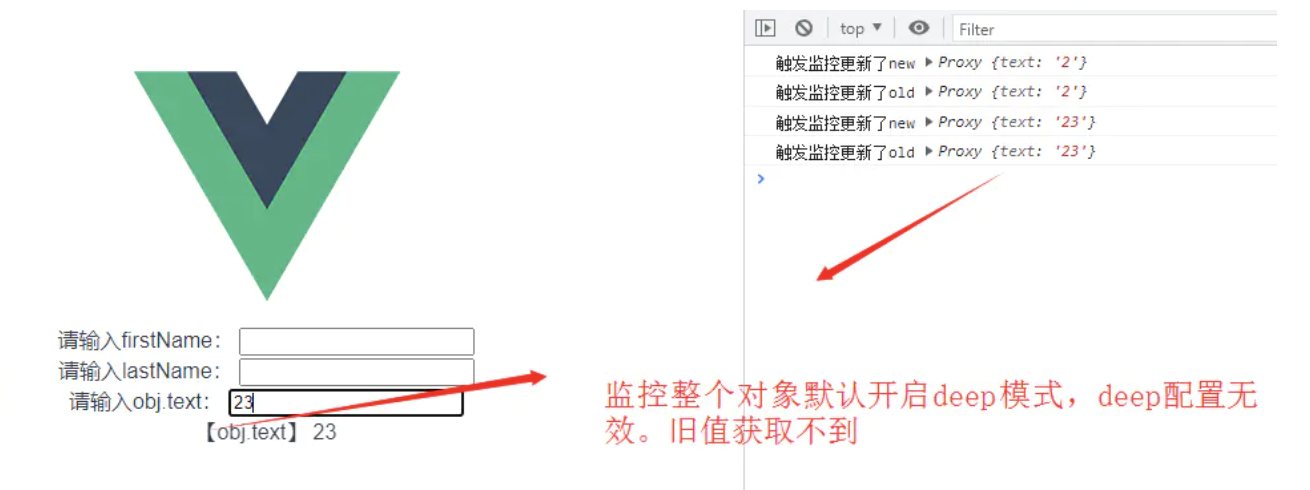
- 监控整个
reactive对象,从上面的图可以看到deep实际默认是开启的,就算我们设置为false也还是无效。而且旧值获取不到。 - 要获取旧值则需要监控对象的属性,也就是监听一个
getter,看下图
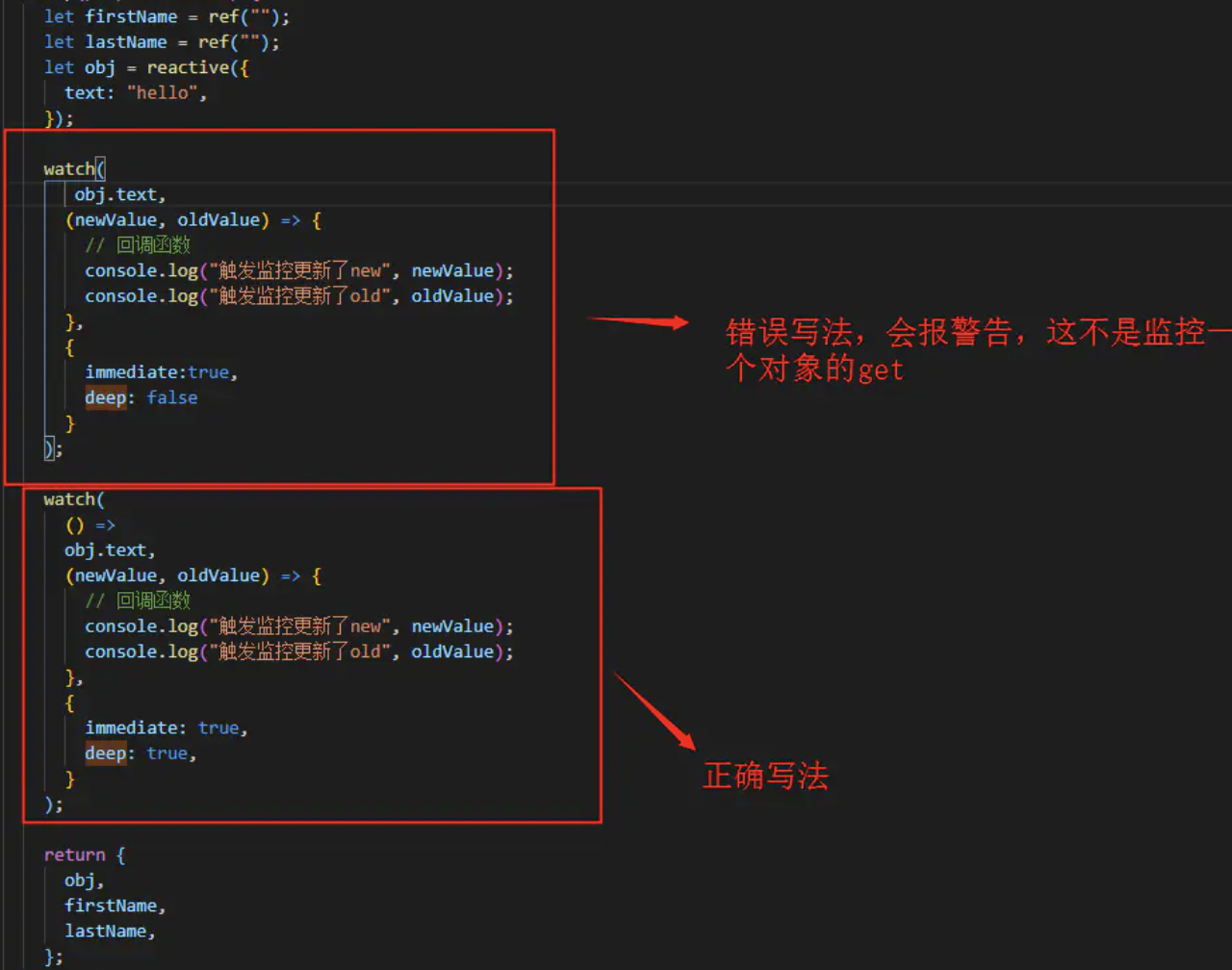
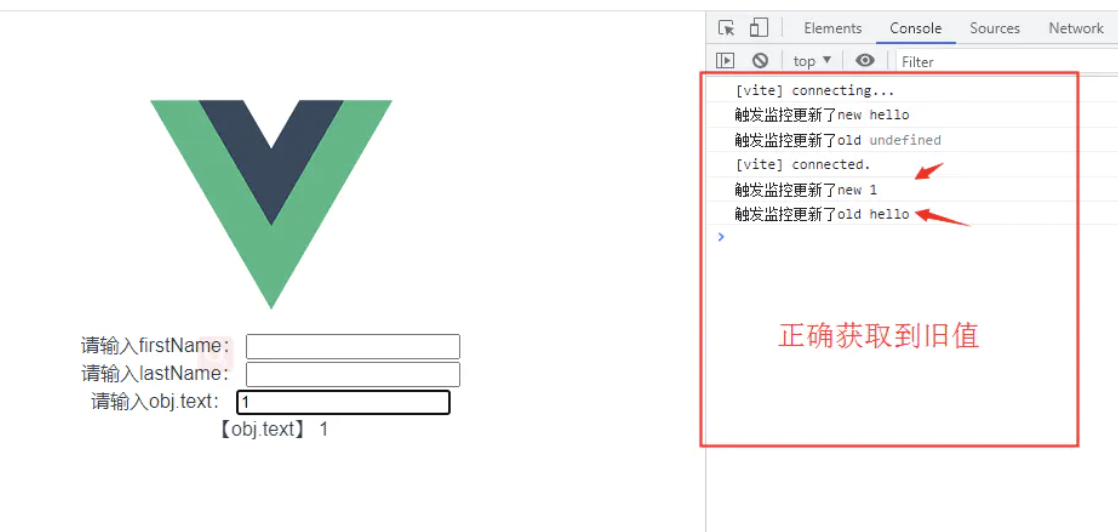
总结
- 如果定义了
reactive的数据,想去使用watch监听数据改变,则无法正确获取旧值,并且deep属性配置无效,自动强制开启了深层次监听。 - 如果使用
ref初始化一个对象或者数组类型的数据,会被自动转成reactive的实现方式,生成proxy代理对象。也会变得无法正确取旧值。 - 用任何方式生成的数据,如果接收的变量是一个
proxy代理对象,就都会导致watch这个对象时,watch回调里无法正确获取旧值。 - 所以当大家使用
watch监听对象时,如果在不需要使用旧值的情况,可以正常监听对象没关系;但是如果当监听改变函数里面需要用到旧值时,只能监听 对象.xxx`属性 的方式才行
watch和watchEffect异同总结
体验
watchEffect立即运行一个函数,然后被动地追踪它的依赖,当这些依赖改变时重新执行该函数
const count = ref(0)
watchEffect(() => console.log(count.value))
// -> logs 0
count.value++
// -> logs 1
watch侦测一个或多个响应式数据源并在数据源变化时调用一个回调函数
const state = reactive({ count: 0 })
watch(
() => state.count,
(count, prevCount) => {
/* ... */
}
)
回答范例
watchEffect立即运行一个函数,然后被动地追踪它的依赖,当这些依赖改变时重新执行该函数。watch侦测一个或多个响应式数据源并在数据源变化时调用一个回调函数watchEffect(effect)是一种特殊watch,传入的函数既是依赖收集的数据源,也是回调函数。如果我们不关心响应式数据变化前后的值,只是想拿这些数据做些事情,那么watchEffect就是我们需要的。watch更底层,可以接收多种数据源,包括用于依赖收集的getter函数,因此它完全可以实现watchEffect的功能,同时由于可以指定getter函数,依赖可以控制的更精确,还能获取数据变化前后的值,因此如果需要这些时我们会使用watchwatchEffect在使用时,传入的函数会立刻执行一次。watch默认情况下并不会执行回调函数,除非我们手动设置immediate选项- 从实现上来说,
watchEffect(fn)相当于watch(fn,fn,{immediate:true})
watchEffect定义如下
export function watchEffect(
effect: WatchEffect,
options?: WatchOptionsBase
): WatchStopHandle {
return doWatch(effect, null, options)
}
watch定义如下
export function watch<T = any, Immediate extends Readonly<boolean> = false>(
source: T | WatchSource<T>,
cb: any,
options?: WatchOptions<Immediate>
): WatchStopHandle {
return doWatch(source as any, cb, options)
}
很明显watchEffect就是一种特殊的watch实现。
Vue模版编译原理知道吗,能简单说一下吗?
简单说,Vue的编译过程就是将template转化为render函数的过程。会经历以下阶段:
- 生成AST树
- 优化
- codegen
首先解析模版,生成AST语法树(一种用JavaScript对象的形式来描述整个模板)。 使用大量的正则表达式对模板进行解析,遇到标签、文本的时候都会执行对应的钩子进行相关处理。
Vue的数据是响应式的,但其实模板中并不是所有的数据都是响应式的。有一些数据首次渲染后就不会再变化,对应的DOM也不会变化。那么优化过程就是深度遍历AST树,按照相关条件对树节点进行标记。这些被标记的节点(静态节点)我们就可以跳过对它们的比对,对运行时的模板起到很大的优化作用。
编译的最后一步是将优化后的AST树转换为可执行的代码。
v-for 为什么要加 key
如果不使用 key,Vue 会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速
更准确:因为带 key 就不是就地复用了,在 sameNode 函数 a.key === b.key 对比中可以避免就地复用的情况。所以会更加准确。
更快速:利用 key 的唯一性生成 map 对象来获取对应节点,比遍历方式更快
你有对 Vue 项目进行哪些优化?
(1)代码层面的优化
- v-if 和 v-show 区分使用场景
- computed 和 watch 区分使用场景
- v-for 遍历必须为 item 添加 key,且避免同时使用 v-if
- 长列表性能优化
- 事件的销毁
- 图片资源懒加载
- 路由懒加载
- 第三方插件的按需引入
- 优化无限列表性能
- 服务端渲染 SSR or 预渲染
(2)Webpack 层面的优化
- Webpack 对图片进行压缩
- 减少 ES6 转为 ES5 的冗余代码
- 提取公共代码
- 模板预编译
- 提取组件的 CSS
- 优化 SourceMap
- 构建结果输出分析
- Vue 项目的编译优化
(3)基础的 Web 技术的优化
- 开启 gzip 压缩
- 浏览器缓存
- CDN 的使用
- 使用 Chrome Performance 查找性能瓶颈
Proxy 与 Object.defineProperty 优劣对比
Proxy 的优势如下:
- Proxy 可以直接监听对象而非属性;
- Proxy 可以直接监听数组的变化;
- Proxy 有多达 13 种拦截方法,不限于 apply、ownKeys、deleteProperty、has 等等是 Object.defineProperty 不具备的;
- Proxy 返回的是一个新对象,我们可以只操作新的对象达到目的,而 Object.defineProperty 只能遍历对象属性直接修改;
Proxy 作为新标准将受到浏览器厂商重点持续的性能优化,也就是传说中的新标准的性能红利;
Object.defineProperty 的优势如下:
- 兼容性好,支持 IE9,而 Proxy 的存在浏览器兼容性问题,而且无法用 polyfill 磨平,因此 Vue 的作者才声明需要等到下个大版本( 3.0 )才能用 Proxy 重写。
computed 的实现原理
computed 本质是一个惰性求值的观察者。
computed 内部实现了一个惰性的 watcher,也就是 computed watcher,computed watcher 不会立刻求值,同时持有一个 dep 实例。
其内部通过 this.dirty 属性标记计算属性是否需要重新求值。
当 computed 的依赖状态发生改变时,就会通知这个惰性的 watcher,
computed watcher 通过 this.dep.subs.length 判断有没有订阅者,
有的话,会重新计算,然后对比新旧值,如果变化了,会重新渲染。 (Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性最终计算的值发生变化时才会触发渲染 watcher 重新渲染,本质上是一种优化。)
没有的话,仅仅把 this.dirty = true。 (当计算属性依赖于其他数据时,属性并不会立即重新计算,只有之后其他地方需要读取属性的时候,它才会真正计算,即具备 lazy(懒计算)特性。)