相信有部分刚入门的小伙伴对于spark写入Mysql的过程不太熟悉。特意写一篇文章讲一下这个注意事项,以免“上大当”
我们先看一个小伙伴写的一段spark写入mysql的代码
public static void trans(SparkSession spark,
String pro_table, String pro_url, String pro_driver, String pro_user, String pro_password,
String dev_table, String dev_url, String dev_driver, String dev_user, String dev_password){
//根据连接得到mysql数据
Dataset<Row> data = spark.read()
.jdbc(pro_url, pro_table, properties(pro_driver,pro_user,pro_password));
//显示部分mysql的数据
data.show();
data.write().format("jdbc")
.mode(SaveMode.Overwrite)
.option("url", dev_url)
.option("dbtable",dev_table)
.option("user", dev_user)
.option("password", dev_password)
.option("driver",dev_driver)
.save();
}
由上我们可以发现,他选了一个Overwrite模式,这个模式有啥效果呢?我们可以继续往下看
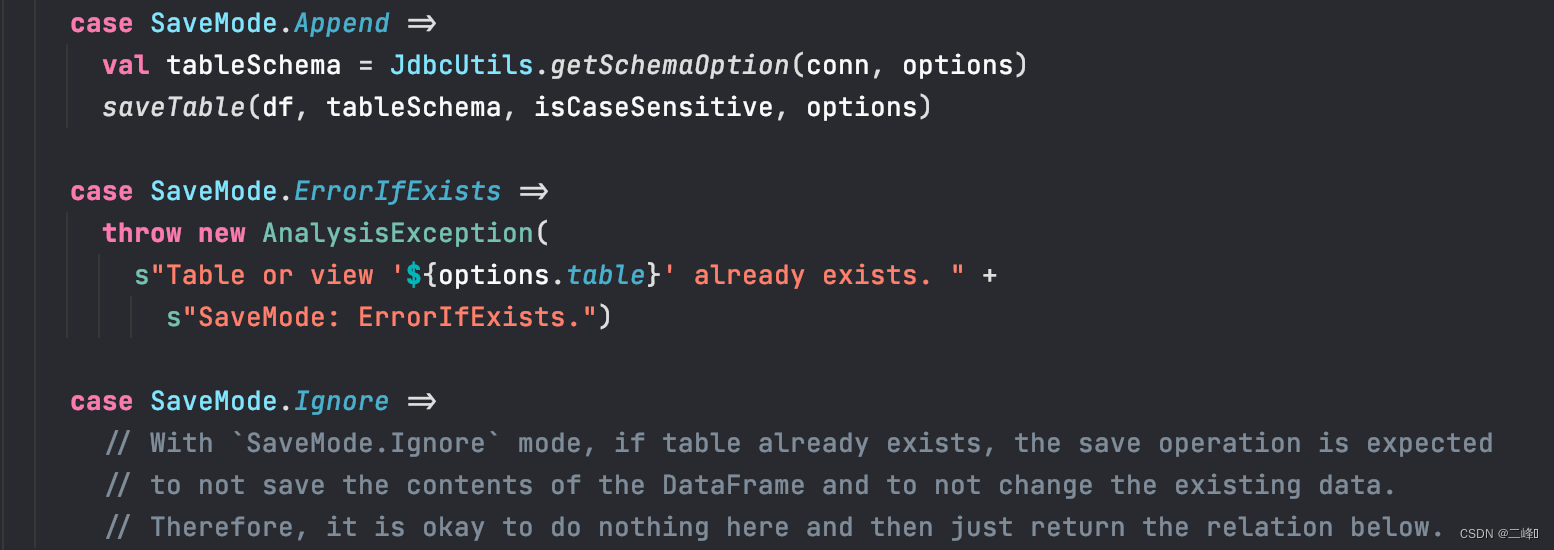
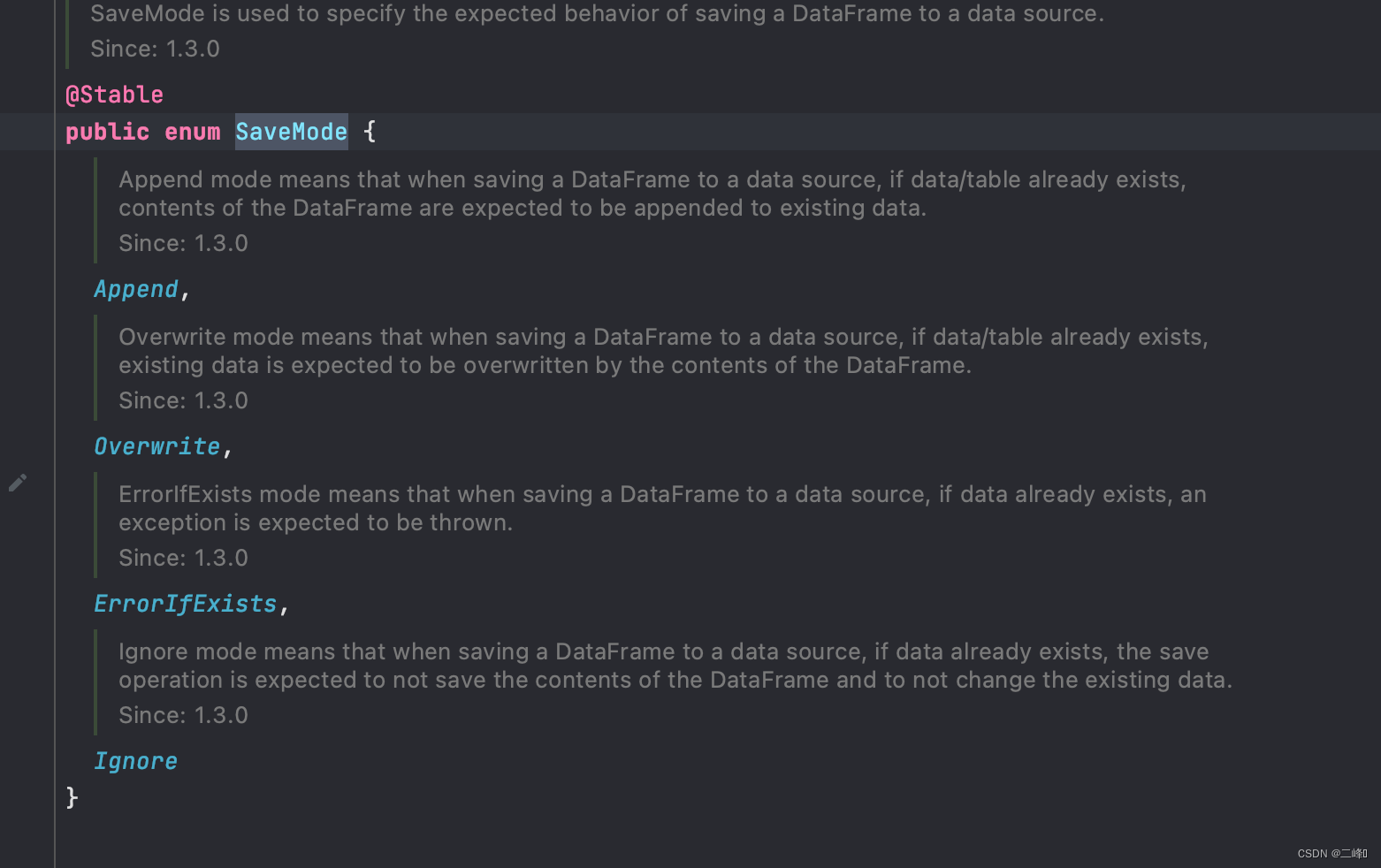 saveMode一共有四种可选模式,其中有一个叫Overwrite模式,这个模式我们去找一段关于他执行过程的一段源码来分析(重点来了)
saveMode一共有四种可选模式,其中有一个叫Overwrite模式,这个模式我们去找一段关于他执行过程的一段源码来分析(重点来了)
如下图
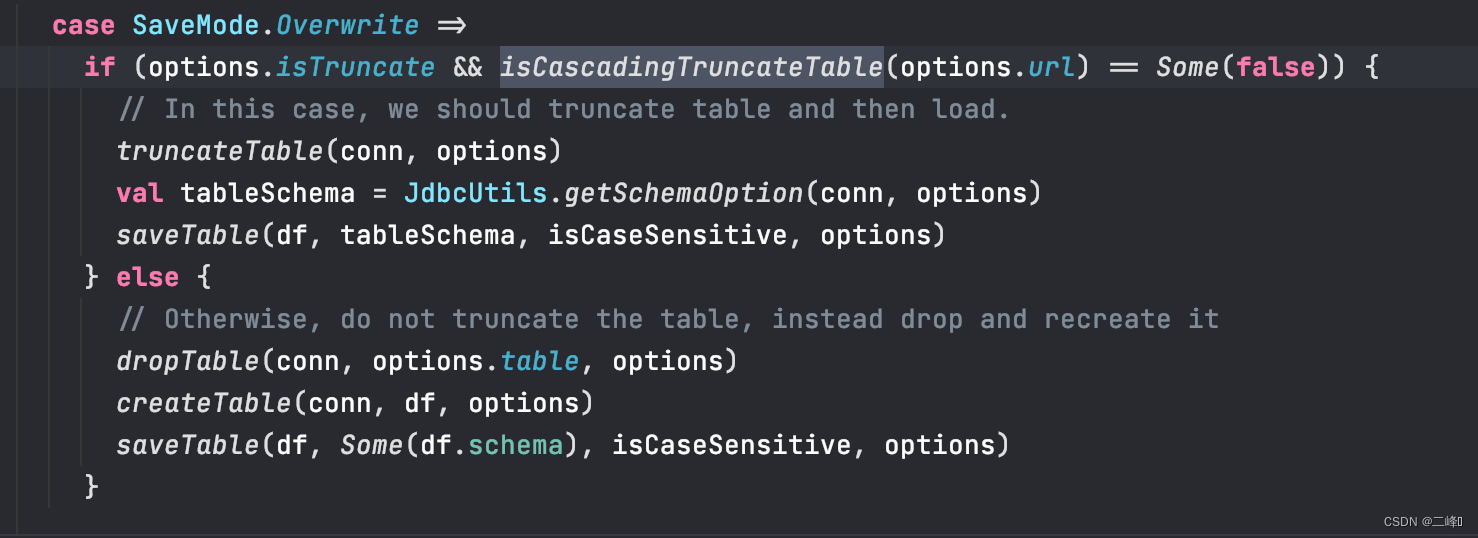
我们可以看到,如果你在save过程中填入了truncate参数,且原表支持truncate,那么他就会先把表给清空,然后再直接保存。但是(敲重点!!!),要是没有填入truncate参数或者原表不支持truncate,那么它就会把表删除掉,然后按照它所读取到的结构重新生成表,最后保存数据,这样的操作主要会造成原表的结构会丢失,例如,主键自增,原表的字段的描述,字段的索引等。所以用Overwrite模式时一定要慎重。
好了重点介绍完了,我们也可以看看其他模式的执行过程(贴上源码自行理解=,=)



![[附源码]Nodejs计算机毕业设计教师业绩考核和职称评审系统Express(程序+LW)](https://img-blog.csdnimg.cn/d21daaa733bd450ba53ebb55fe0306bc.png)
![[附源码]Nodejs计算机毕业设计教务管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/bdd7dc4dfd1d42c0be2c7586b6a6c623.png)