技术格言
世界上并没有完美的程序,但是我们并不因此而沮丧,因为写程序就是一个不断追求完美的过程。
什么是脑裂
字面含义
首先,脑裂从字面上理解就是脑袋裂开了,就是思想分家了,就是有了两个山头,就是有了两个主思想。
技术定义
在高可用集群中,当两台高可用服务器在指定的时间内,由于网络的原因无法互相检测到对方心跳而各自启动故障转移功能,取得了资源以及服务的所有权,而此时的两台高可用服务器对都还活着并作正常运行,这样就会导致同一个服务在两端同时启动而发生冲突的严重问题,最严重的就是两台主机同时占用一个VIP的地址(类似双端导入概念),当用户写入数据的时候可能会分别写入到两端,这样可能会导致服务器两端的数据不一致或造成数据的丢失,这种情况就称为裂脑,也有的人称之为分区集群或者大脑垂直分隔,互相接管对方的资源,出现多个Master的情况,称为脑裂。
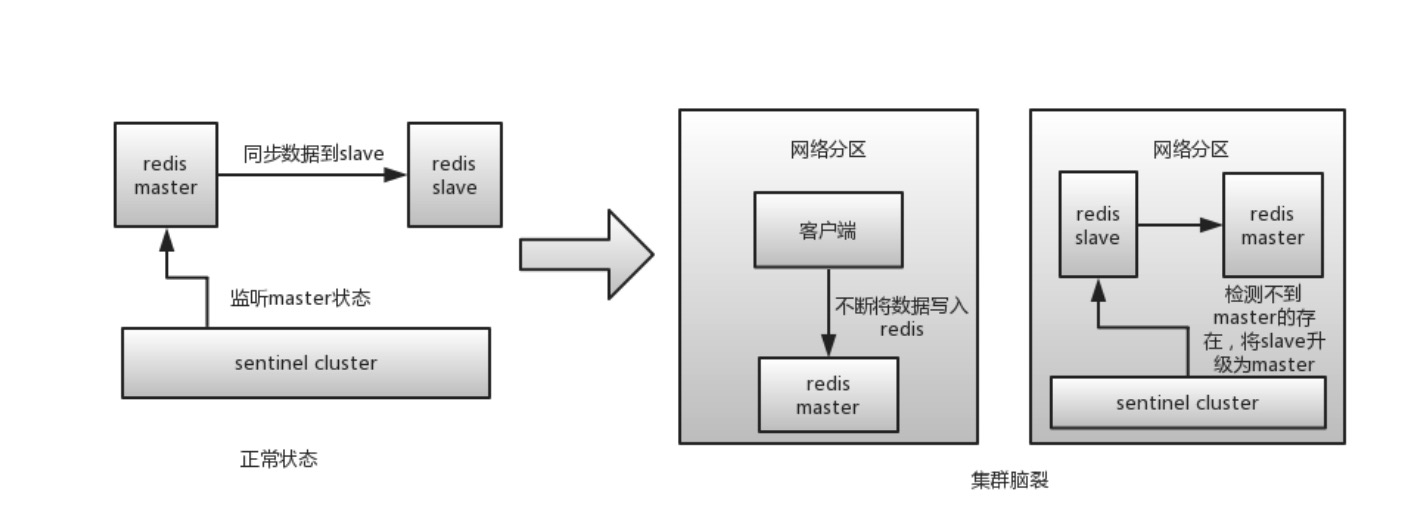
脑裂导致的问题
引起数据的不完整性:在集群节点出现脑裂的时候,如果外部无法判断哪个为主节点,脑裂的集群都可以正常访问的时候,这时候就会出现数据不完整的可能性。
- 服务异常:对外提供服务出现异常。
导致裂脑发生的原因
优先考虑心跳线路上的问题,在可能是心跳服务,软件层面的问题
-
1)高可用服务器对之间心跳线路故障,导致无法正常的通信。原因比如:
-
1——心跳线本身就坏了(包括断了,老化);
-
2——网卡以及相关驱动坏了,IP配置及冲突问题;
-
3——心跳线间连接的设备故障(交换机的故障或者是网卡的故障);
-
4——仲裁的服务器出现问题。
-
-
2)高可用服务器对上开启了防火墙阻挡了心跳消息的传输;
-
3)高可用服务器对上的心跳网卡地址等信息配置的不正确,导致发送心跳失败;
-
4)其他服务配置不当等原因,如心跳的方式不同,心跳广播冲突,软件出现了BUG等。
解决脑裂所出现的问题
-
添加冗余的心跳线,尽量减少“脑裂”的机会
-
启用磁盘锁:在发生脑裂的时候可以协调控制对资源的访问设置仲裁机制
实际的生产环境中,我们可以从以下几个方面来防止裂脑的发生:
-
1)同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个线路还是好的,依然能传送消息(推荐的)
-
2)检测到裂脑的时候强行的关闭一个心跳节点(需要特殊的节点支持,如stonith,fence),相当于程序上备节点发现心跳线故障,发送关机命令到主节点。
-
3)多节点集群中,可以通过增加仲裁的机制,确定谁该获得资源,这里面有几个参考的思路:
1——增加一个仲裁机制。例如设置参考的IP,当心跳完全断开的时候,2个节点各自都ping一下参考的IP,不同则表明断点就出现在本段,这样就主动放弃竞争,让能够ping通参考IP的一端去接管服务。
2——通过第三方软件仲裁谁该获得资源,这个在阿里有类似的软件应用
-
4)做好对裂脑的监控报警(如邮件以及手机短信等),在问题发生的时候能够人为的介入到仲裁,降低损失。当然,在实施高可用方案的时候,要根据业务的实际需求确定是否能够容忍这样的损失。对于一般的网站业务,这个损失是可控的(公司使用)
-
5)启用磁盘锁。正在服务一方锁住共享磁盘,脑裂发生的时候,让对方完全抢不走共享的磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的乙方不主动解锁,另一方就永远得不到共享磁盘。现实中介入服务节点突然死机或者崩溃,另一方就永远不可能执行解锁命令。后备节点也就截关不了共享的资源和应用服务。于是有人在HA中涉及了“智能”锁,正在服务的一方只在发现心跳线全部断开时才启用磁盘锁,平时就不上锁了
什么是redis脑裂?
如果在redis中,形式上就是有了两个master,记住两个master才是脑裂的前提。
哨兵(sentinel)模式下的脑裂
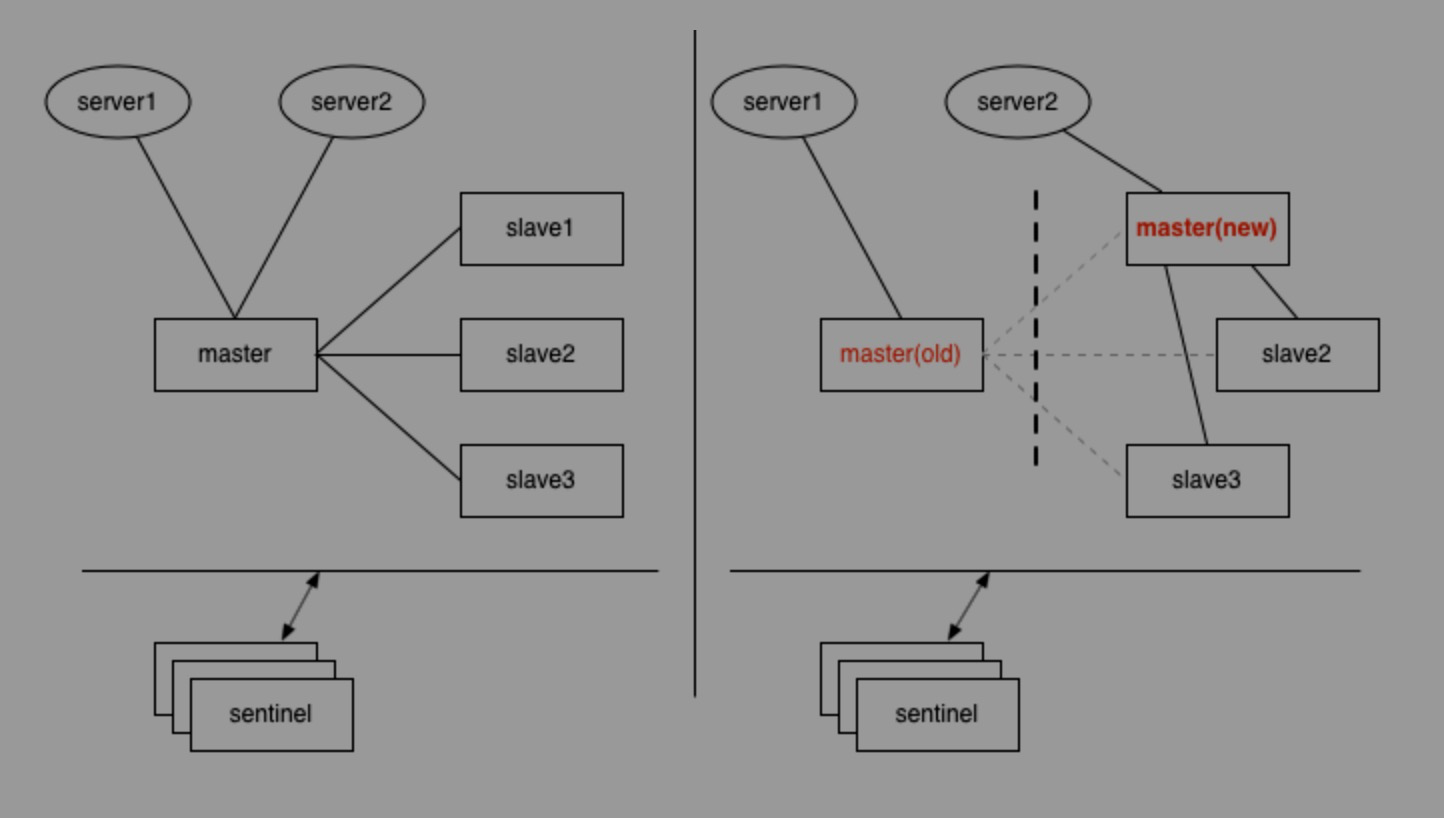
1个master与3个slave组成的哨兵模式(哨兵独立部署于其它机器),刚开始时,2个应用服务器server1、server2都连接在master上,如果master与slave及哨兵之间的网络发生故障,但是哨兵与slave之间通讯正常,这时3个slave其中1个经过哨兵投票后,提升为新master,如果恰好此时server1仍然连接的是旧的master,而server2连接到了新的master上。
数据就不一致了,基于setNX指令的分布式锁,可能会拿到相同的锁;基于incr生成的全局唯一id,也可能出现重复。
集群(cluster)模式下的脑裂
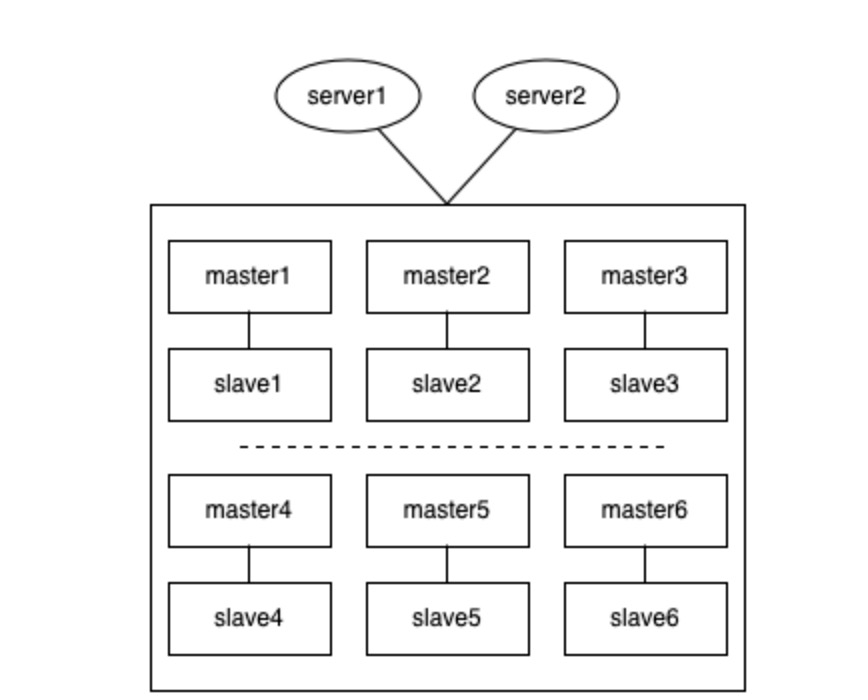
cluster模式下,这种情况要更复杂,例如集群中有6组分片,每给分片节点都有1主1从,如果出现网络分区时,各种节点之间的分区组合都有可能。
手动解决问题
在正常情况下,如果master挂了,那么写入就会失败,如果是手动解决,那么人为会检测master以及slave的网络状况,然后视情况,如果是master挂了,重启master,如果是master与slave之间的连接断了,可以调试网络,这样虽然麻烦,但是是可以保证只有一个master的,所以只要认真负责,不会出现脑裂。
自动解决问题
Redis中有一个哨兵机制,哨兵机制的作用就是通过redis哨兵来检测redis服务的状态,如果一旦发现master挂了,就在slave中选举新的master节点以实现故障自动转移。
问题,就出现在这个自动故障转移上,如果是哨兵和slave同时与master断了联系,即哨兵可以监测到slave,但是监测不到master,而master虽然连接不上slave和哨兵,但是还是在正常运行,这样如果哨兵因为监测不到master,认为它挂了,会在slave中选举新的master,而有一部分应用仍然与旧的master交互。当旧的master与新的master重新建立连接,旧的master会同步新的master中的数据,而旧的master中的数据就会丢失。所以我认为redis脑裂就是自动故障转移造成的。
总结梳理解决方案
如何解决脑裂?
设置每个master限制slave的数量
redis的配置文件中,存在两个参数
min-slaves-to-write 3
min-slaves-max-lag 10
- 第一个参数表示连接到master的最少slave数量
- 第二个参数表示slave连接到master的最大延迟时间
按照上面的配置,要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
注意:较新版本的redis.conf文件中的参数变成了
min-replicas-to-write 3
min-replicas-max-lag 10
redis中的异步复制情况下的数据丢失问题也能使用这两个参数
总结
官方文档所言,redis并不能保证强一致性(Redis Cluster is not able to guarantee strong consistency. / In general Redis + Sentinel as a whole are a an eventually consistent system) 对于要求强一致性的应用,更应该倾向于相信RDBMS(传统关系型数据库)。







![[附源码]Nodejs计算机毕业设计教师业绩考核和职称评审系统Express(程序+LW)](https://img-blog.csdnimg.cn/d21daaa733bd450ba53ebb55fe0306bc.png)
![[附源码]Nodejs计算机毕业设计教务管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/bdd7dc4dfd1d42c0be2c7586b6a6c623.png)