前言
在现代互联网时代,网页数据获取和处理已经成为了重要的技能之一。无论是为了获取信息、做市场研究,还是进行数据分析,掌握网页爬取和数据处理技术都是非常有用的。本文将介绍从网页加载到数据存储的完整过程,包括网络请求、数据解析、反爬措施、多任务异步爬虫、数据存储和面向对象编程等内容。通过本文的学习,读者将能够掌握从网页上收集信息的基本原理和技术,以及如何将这些信息进行处理和存储。
网页加载的全过程
假设我们在浏览器输入www.example.com这个网址并回车,会发生以下过程:
- 浏览器检查本地缓存,看看这个网页是否访问过,如果访问过就直接显示本地缓存内容,不用再到服务器请求。
- 如果没有本地缓存,浏览器就创建一个HTTP请求,请求www.example.com这个服务器上的网页。
- 请求发出去,服务器接收到请求后查找网页文件,找到后把网页文件的内容放入HTTP响应返回给浏览器。
- 浏览器接收到服务器返回的HTML内容,就像得到一块土豆一样,先要洗干净、切块,才能烹饪。浏览器也要解析HTML、CSS、JS,才能显示出漂亮的界面。
- 浏览器会生成DOM树来存储HTML标签结构,生成CSSOM树来存储CSS样式规则。
- 浏览器执行页面的JavaScript代码,这可能会修改DOM或CSSOM。
- 浏览器会将DOM和CSSOM整合形成一棵渲染树,确定每个节点的样式和坐标。
- 按渲染树来布局,计算每个节点的大小和位置,然后把页面绘制出来。
- 把绘制好的页面显示在浏览器窗口。
- 当我们点击、输入时,浏览器会实时响应,重新执行JavaScript、调整样式、重新布局、重绘页面。
我用通俗易懂的语言,详细再给你解释一遍网页的加载过程:
- 小明输入网址,按下回车键,浏览器听到后开始工作。
- 浏览器先看看小明是不是之前来过这个网站,如果来过就拿出旧网页给小明看。
- 如果没来过,浏览器就给网站服务器发个邮件,说想看看你家的网站,请把网页的内容回复我。
- 网站服务器收到浏览器的邮件,找到网页文件后封入信封回邮给浏览器。
- 浏览器收到服务器的回信,把信封打开,里面是一堆代码和图片之类的。
- 浏览器把这些代码和图片像积木一样拼在一起,先建立一个DOM树结构,再确定CSS样式,然后把两棵树合成一棵渲染树。
- 浏览器按渲染树计算每个部分的位置和大小,然后把网页画出来。
- 把画好的网页拿给小明看,小明开心地浏览网页了。
- 如果小明点击网页或者输入内容,浏览器会重新执行代码,重绘页面。
网页加载的渲染的两种形式:
- 服务器端渲染
- 服务器收到客户端请求后,使用服务器语言(如PHP)生成整合了数据的HTML内容。
- 这样浏览器拿到的源代码中已经包含了需要展示的数据。
- 客户端渲染
- 浏览器拿到服务器返回的HTML源代码后,开始解析和渲染。
- 通过执行JavaScript代码,可以实现网页的动态效果和交互。
- 数据和页面内容的整合在浏览器本地完成。
- 这样的渲染方式需要通过F12-network,在Fetch/XHR或JS中寻找需要的数据。
- preserver log可以记录你访问过的页面,打钩可避免网页302,重定向造成的影响
区分服务器端和客户端渲染非常重要。服务器端渲染可以减轻客户端压力,客户端渲染可以提供更好的交互体验。现代网页开发通常会结合两种渲染方式的优点。
Network面板中的各部分:
- Headers
请求头和响应头,显示了请求和响应的所有HTTP头信息,包括通用头和自定义头。重要的头会展开显示,如User-Agent, Cookie, Referer等。 - Payload
请求Payload显示发送给服务器的数据体,比如POST请求的表单数据或JSON体。
响应Preview显示接收到的响应结果内容,比如HTML代码,图片文件,JSON数据等。 - Cookies
请求Cookies显示请求头中Cookie相关信息。
响应Cookies显示响应头设置的Cookie内容。
可查看Cookie的传递过程。 - Initiator
显示发起该请求的资源信息,比如HTML标签引入的img/script/link等。
可了解资源之间的依赖关系。 - Timing
累积持续时间:整个请求过程总计耗时。
块级别时间明细:分别显示队列、域名解析、TCP连接、TLS安全连接、请求响应等每个阶段的耗时。
方便找出性能瓶颈。 - Response
显示响应状态码(200, 404等)和响应来源(服务端响应,浏览器缓存等)
可快速识别请求是否成功。 - 筛选条件
可按方法,域名,类型,文本等条件进行过滤,组合使用可保存筛选条件。
requests库的用法:
安装
pip install requests
GET请求
GET请求用于获取服务器的数据。它通过URL的参数传递请求数据。
import requests
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('http://httpbin.org/get', params=params)
print(response.url)
# http://httpbin.org/get?key1=value1&key2=value2
requests会将params字典类型自动转换为url参数。
也可以直接将参数拼接到url中:
import requests
response = requests.get('http://httpbin.org/get?key1=value1&key2=value2')
百度搜索实例
https://www.baidu.com/s?tn=85070231_38_hao_pg&wd=总结
https://www.baidu.com/s?tn=85070231_38_hao_pg&wd=%E6%80%BB%E7%BB%93
params = {‘tn’: ‘85070231_38_hao_pg’, ‘wd’: ‘总结’}

POST请求
POST请求用于向服务器发送数据。它通过请求体传递参数。
import requests
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('http://httpbin.org/post', data=data)
print(response.text)
# {
# "form": {
# "key1": "value1",
# "key2": "value2"
# }
# }
requests会自动编码data字典为表单格式。
也可以直接传递字符串:
data = 'key1=value1&key2=value2'
response = requests.post('http://httpbin.org/post', data=data)
此外,还可以传递JSON数据:
import json
data = {'key1': 'value1', 'key2': 'value2'}
data = json.dumps(data)
response = requests.post('http://httpbin.org/post', data=data)
两种不同实例
Form Data形式
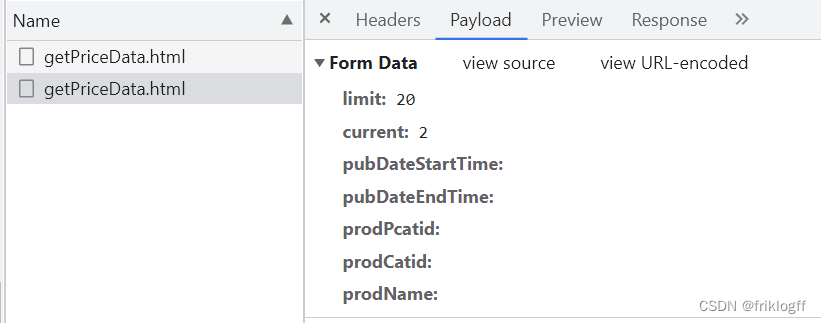
http://www.xinfadi.com.cn/priceDetail.html data = {‘key1’:‘value1’, ‘key2’: ‘value2’}response = requests.post(‘http://httpbin.org/post’, data=data)
传递字典即可
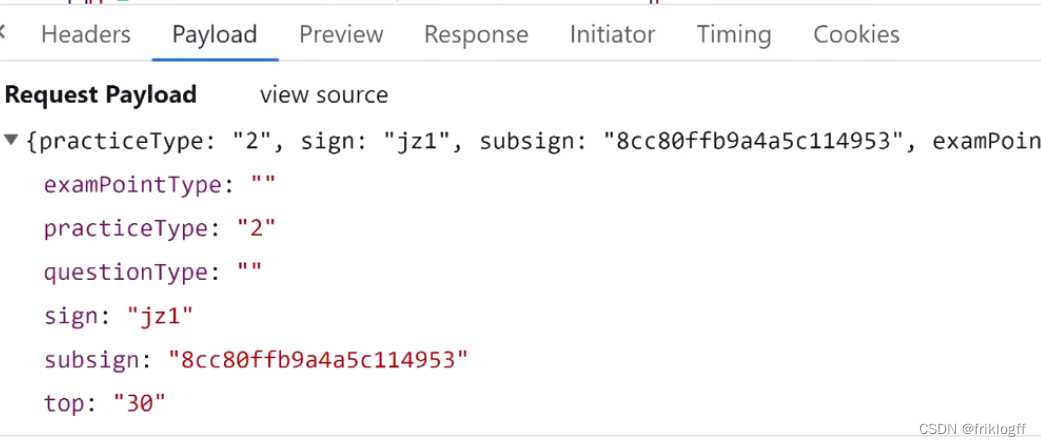
Request Payload形式
能直观的看到是json类型的数据
两种方案
- requests.post(url,json={字典})
- requests.post(url,data=json.dumps({字典}),
headers={ “Content-Type” : “application/json; charset=UTF-8” })
HTTP状态码
- 200系列 - 请求成功,表示服务器成功处理了请求。常见有:
- 200 OK - 一般请求成功返回此代码
- 204 No Content - 请求成功但无内容返回
- 300系列 - 重定向,表示资源已被分配了新的URI。常见有:
- 301 Moved Permanently - 永久重定向
- 302 Found - 临时重定向->location
- 304 Not Modified - 资源未修改,直接使用缓存
- 400系列 - 客户端错误,表示请求存在语法错误或无法完成请求。常见有:
- 400 Bad Request - 请求报文存在语法错误
- 401 Unauthorized - 需要身份认证信息
- 403 Forbidden - 服务器拒绝请求
- 404 Not Found - 请求资源不存在
- 500系列 - 服务器内部错误,表示服务器无法完成请求。常见有:
- 500 Internal Server Error - 服务器内部错误
- 503 Service Unavailable - 服务器暂时过载或维护
简单的反爬操作:
请求头:
-
User-Agent:标识客户端浏览器信息,可用于反爬检测,表示用户用什么设备发送的请求。
- 直接从浏览器复制,用于伪装访问设备。
-
Cookie:网站用于跟踪会话,可检测非正常Cookie来实现反爬,是服务器记录在浏览器上的一个字符串,写入在本地的一个文件中,作用是和服务器保持住会话,在服务器端叫session。(HTTP请求是无状态请求)
-
- 从浏览器直接复制,适用于简单场景。
-
- 使用requests.session()自动保持会话,处理set-cookie,适用于复杂场景。如果网页使用Js维护Cookie,需要自己额外处理。
-
-
Referer:标识来源页面,用来检测上一个url是什么,可检测Referer来防止盗链。
- 直接复制来源页面URL,用于伪造访问来源。
-
网页自定义参数:这是最难处理的,需要通过逆向工程分析参数算法,找到生成参数的代码逻辑。
响应头:
- Location:302重定向地址,可设置跳转难以解析的页面用于反爬。
- Set-Cookie:设置Cookie,可用于保存难以伪造的Cookie实现访问控制。
- 网站还可以在这些头部中添加各种参数,来进行访问验证、opensession遥测等,以识别爬虫行为。
requests.Session的用法:
创建Session对象
import requests
session = requests.Session()
首先导入requests模块,然后调用requests.Session()来创建一个Session对象。
设置请求头
可以通过Session对象的headers属性预设请求头,这些头信息将会应用于该Session实例发出的所有请求:
session.headers = {
'User-Agent': 'Mozilla/5.0',
'Authorization': 'Bearer xxxxxxxxxxxxx'
}
设置Cookies
session.cookies.update({
'name': 'value',
'foo': 'bar'
})
通过Session的cookies属性可以预设请求中的Cookies。
发送请求
response = session.get(url, params=params)
response = session.post(url, data=data)
可以使用Session对象的get()、post()等方法发送请求。
关闭Session
session.close()
当Session使用完后,可以调用close()方法关闭该Session对象。
相比直接使用requests.get()/post()等函数,使用Session对象的好处是:
- 避免重复传参,提高效率
- 自动处理Cookies,实现状态保持
- 方便REQUESTS头及Cookies的管理
数据解析方法
三种解析HTML数据的方法:
- 正则表达式re
- 在html中获取到js的一部分代码(字符串)
- 使用re.compile()编译正则表达式
- re.findall()方法根据正则在文本中提取匹配内容
- 适用于从文本中提取固定模式的字符串
import re
html = '<script>var data = "abc"</script>'
pattern = re.compile(r'var data = "(.*)"')
result = pattern.findall(html)
- 调用xpath()提取指定节点
- 用来解析常规的html结构.
- 可以获取属性、文本等信息
- 处理速度快
from lxml import etree
html = etree.HTML(resp.text)
result = html.xpath('//li/text()')
etree的xpath默认返回的是列表.
if ret:
ret[0]
else:
XXX
- BeautifulSoup
- 创建BeautifulSoup对象解析.xml,.svg
- 使用find()/find_all()搜索文档树
- 获取name、attrs、text等信息
- 可以处理不规整文档
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
result = soup.find_all('li')
综合来说,正则适合提取固定模式字符串,lxml解析速度快,BeautifulSoup可以应对“烂”文档。
json和jsonp的解析方法:
- JSON数据解析
- 从响应中获取JSON字符串
resp_text = response.text
- 尝试直接加载解析
try:
data = response.json()
except:
# 处理异常
- 如果失败,则手动加载解析
import json
data = json.loads(resp_text )
- 在解析前,一定要打印检查resp_text 确认是标准JSON格式,才进行解析。
- 如果遇到反爬.你很可能拿到的东西和抓包工具不一致.
- 切记,先打印resp_text .确定好你的返回的内容是json格式,才开始转化
- JSONP数据解析
- JSONP格式如:XXXXXX({json}) => {json}
- 想办法去掉左右两端的XXXXXX( )=>得到的就是json
- “XXXXXX({json}) “.replace(“XXXXXX(”,””)[:-1]
- 需要去除方法调用部分,保留JSON字符串
- 得到JSON字符串后,加载解析

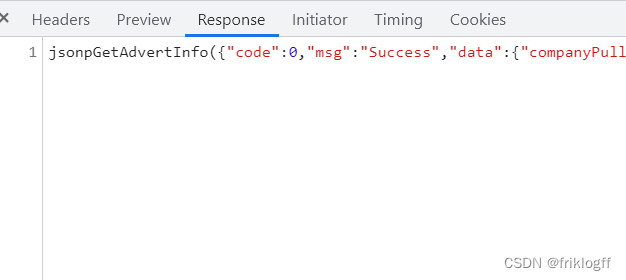
以上两张图可以看出XXXXXX为callback值
多任务异步爬虫.多线程,多进程,协程异步I/O
- 区别
- 多线程:线程之间共享进程内存空间,线程切换成本低,适合I/O密集作业。但线程不安全,需要锁机制。
- 多进程:进程有独立内存, Kosten比线程高,适合CPU密集作业。进程间通信复杂,需要IPC。
- 协程:在单线程中以异步方式实现并发,减少切换带来的消耗。适合I/O密集场景,可大幅提升效率。
- 适用场景
- 多线程:爬取大量小页面,线程间共享解析函数等。
- 多进程:爬取数据规模巨大,CPU密集型数据处理。
- 协程:需要大量I/O操作的异步爬虫,提高并发量。
- 实现难度
- 多线程:线程模块较为简单,难点在线程安全和死锁问题。
- 多进程:进程间通信和数据传递实现复杂度高。
- 协程:需理解异步语法,错误调试难度较大。
多线程
- 原理:导入threading模块,用Thread类创建线程。线程间共享进程内存空间,互不影响,可同时执行。
- 实例:
from threading import Thread
import requests
def crawl(url):
r = requests.get(url)
print(r.text)
t1 = Thread(target=crawl, args=('url1',))
t2 = Thread(target=crawl, args=('url2',))
t1.start()
t2.start()
多进程
- 原理:导入multiprocessing模块,用Process类创建进程。进程有独立内存空间,需要通过Queue、Pipe等方式通信。
- 实例:
from multiprocessing import Process, Queue
def crawler(q):
data = crawl_page()
q.put(data)
q = Queue()
p1 = Process(target=crawler, args=(q,))
p2 = Process(target=crawler, args=(q,))
p1.start()
p2.start()
协程异步I/O
- 原理:使用async/await语法,进行异步编程。遇await切换到其他协程,不阻塞程序执行。
- 实例:
import asyncio
async def fetch(url):
print('fetching')
return await aiohttp.get(url)
async def main():
await fetch(url1)
await fetch(url2)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
数据存储
CSV
- CSV适合存储表格化数据,如电商订单、用户信息等
- 可以用Excel等软件方便编辑和查看数据
- 支持数据交换,可以导入到数据库或其他系统
- Python中常用csv模块操作
import csv
# 写入CSV文件
with open('data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# 写入标题行
writer.writerow(['ID', 'Name', 'Age'])
# 写入数据行
writer.writerow(['1', '张三', 20])
writer.writerow(['2', '李四', 25])
# 读取CSV文件
with open('data.csv', 'r') as csvfile:
reader = csv.reader(csvfile)
# 读取标题
headers = next(reader)
# 读取每行数据
for row in reader:
print(row)
- 字典写入CSV
import csv
with open('data.csv', 'w', newline='') as f:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id': 1, 'name': '张三', 'age': 20})
writer.writerow({'id': 2, 'name': '李四', 'age': 25})
- Pandas读写CSV并存入Excel
import pandas as pd
df = pd.read_csv('data.csv')
df.to_csv('new_data.csv', index=False)
df.to_excel( "hehe.xls", header=False,index=False)
csv本质是文本文件
f = open("data.csv", modew" , encoding="utf-8")f.write("1")
f.write(" , ")
f.write("张三")
f.write(" , ")
f.write( '"张,三"')
f.write(" , ")
f.write("5000")
f.write(" \n ")
f.write(" , ")
f.write("张四")
f.write(" , ")
f.write( '"张,四"')
f.write(" , ")
f.write("5030")
f.write(" \n ")
import pandas
r = pandas.read_csv ( "data.csv " , sep="," , headen=None)
print(r)
r.to_excel( "hehe.xls", header=False,index=False)
MySQL
- 数据类型:整型、字符串、日期时间等,设置符合存储需求的字段类型
- 查询语句:SELECT与WHERE过滤数据,ORDER BY排序,LIMIT分页
- 联表查询:INNER JOIN,LEFT/RIGHT JOIN 等方式联结多个表GetData
- 事务处理:START TRANSACTION到COMMIT,处理包含多条SQL语句的事务
- Python中操作:
import pymysql
# 连接数据库
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='test')
# 插入数据
cursor = conn.cursor()
cursor.execute("INSERT INTO tb_user VALUES (NULL, '张三', 25)")
conn.commit()
# 查询数据
cursor.execute("SELECT * FROM tb_user")
result = cursor.fetchall()
print(result)
MongoDB
- 文档存储:JSON格式灵活存储数据
- 数据模式自由,无需定义表结构
- 丰富的查询语言:正则匹配、树形查询、地理位置查询等
- Python中操作:
from pymongo import MongoClient
# 连接Mongodb
client = MongoClient('localhost', 27017)
collection = client['testdb']['user']
# 插入文档
data = {'name': '张三', 'age': 25}
collection.insert_one(data)
# 查询文档
results = collection.find({'age': {'$gt': 20}})
for result in results:
print(result)
Redis
- 键值对存储,value支持多种数据结构
- 提供字符串、哈希、列表、集合、有序集合5种数据结构操作
- 支持事务,具有原子性
- 丰富的功能:发布订阅、LRU过期等
- Python中操作:
import redis
# 连接Redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 字符串操作
r.set('username', '张三')
# 散列操作
r.hset('user', 'name', '张三')
# 列表操作
r.lpush('list', 1,2,3)
面向对象编程
编程思想的转变
目前我们编写的代码属于面向过程:
- 获取页面源代码
- 解析页面源代码
- 存储数据
面向过程注重步骤,按照顺序一步步实现功能。
类似我要喝可乐的过程:
- 从沙发上起来
- 走到冰箱门前
- 拿出可乐
- 喝一口
- 关上冰箱门
面向对象思维
面向对象编程核心在于思维方式的转变:
- 你要操纵对象,让对象给你干活
- 最终结果都是能喝到可乐
- 让对象去操作
要实现面向对象需要:
- 定义对象
- 让对象会进行操作
程序员可以自由构思创造对象,然后定义对象的属性和方法。
创建对象
在Python中通过类(Class)可以创建对象,类是对象的模板,包含对象的属性和方法。
定义一个类:
class Cat:
def __init__(self, name, age):
self.name = name
self.age = age
def meow(self):
print("喵喵喵")
tom = Cat("汤姆", 3)
tom.meow()
面向对象编程可以提高代码的封装性、继承性和可维护性。需要转换编程思维方式,主要关注对象和类的设计。
总结
本文全面介绍了网页加载、数据处理和存储的关键概念和技术。无论是初学者还是有一定经验的开发者,都能从中受益匪浅。通过掌握这些技能,读者可以更有效地收集和处理网络数据,为各种应用场景提供有力支持。无论是进行数据分析、信息收集、还是网站开发,本文提供了重要的基础知识和实用技巧。希望读者能够积极学习和实践,不断提升自己的技能水平。
特别声明:
此教程为纯技术分享!本教程的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本教程的目的记录分享学习技术的过程