目录
1、 引言:AI与自动驾驶的革命性融合
2、五大领先多模态模型解析
2.1 Qwen2.5-Omni:全模态集大成者
2.2. LLaVA:视觉语言理解专家
2.3. Qwen2-VL:长视频理解能手
2.4. X-InstructBLIP:跨模态理解框架
2.5. MiniCPM-V:端侧轻量优化
2.6. Florence2:易集成视觉模型
3、多模态大模型集成策略:完整数据闭环
3.1.多模态数据采集与预处理
3.2.多模态内容理解与特征提取
3.3.精准指令执行与推理
3.4.应用集成与高阶功能
3.5.数据闭环优化
4、单一模型 vs 多模型协同:自动驾驶的关键决策
4.1多模型组合的弊端
4.2单一模型的优势与局限
5、自动驾驶集成挑战与解决方案
5.1. 实时性要求
5.2. 模型协同机制
5.3. 车规级可靠性
6、实际应用案例
6.1.ADAS数据闭环系统
6.2.智能座舱-驾驶协同系统
7、推荐架构:分层协作模型
7.1.感知层:系统的"眼睛"
7.2.交互层:系统的"嘴巴"和"耳朵"
7.3.车用集成架构示例
8、未来发展趋势
9、结论
1、 引言:AI与自动驾驶的革命性融合
多模态AI模型与自动驾驶技术的融合代表了具有巨大潜力的新兴技术前沿。这种结合不仅提升了自动驾驶系统的感知、推理和决策能力,还为解决复杂道路场景的挑战创造了新机遇。本文将深入探讨多模态大模型在自动驾驶中的应用,对比领先模型的特性,并提供完整的集成策略及实践路径。

2、五大领先多模态模型解析
2.1 Qwen2.5-Omni:全模态集大成者
2025年3月27日,阿里通义千问团队发布了Qwen2.5-Omni,这是Qwen系列中全新的旗舰级多模态大模型,专为全面的多模式感知设计,可以无缝处理包括文本、图像、音频和视频的各种输入,同时支持流式的文本生成和自然语音合成输出。
核心创新:Thinker-Talker架构
- Thinker组件:负责处理和理解多模态输入,如同大脑
- Talker组件:负责流式输出语音,如同嘴巴
- TMRoPE技术:实现视频输入与音频时间戳的同步
Qwen2.5-Omni-7B开源了,采用Apache 2.0许可证,适合在资源受限环境(如车载设备)中部署。
自动驾驶数据闭环综述
2.2. LLaVA:视觉语言理解专家
LLaVA是通过端到端训练的多模态模型,整合视觉编码器和语言模型实现通用视觉语言理解。
LLaVA 1.6主要提升了视觉推理和光学字符识别(OCR)能力。虽然LLaVA 1.6本身主要针对图像输入进行了改进,但其架构设计使其具备处理视频输入的潜力。
LLaVA-NeXT-Video版本采用了AnyRes技术,将视频帧抽取并处理为视觉token序列,从而实现了对视频的有效处理。 CSDN Blog+3Zhihu Zhiwen+3Volcengine Developer Community+3
此外,Video-LLaVA模型进一步扩展了这一功能,通过将图像和视频的视觉表示统一到语言特征空间,使大型语言模型能够同时对图像和视频进行视觉推理。
2.3. Qwen2-VL:长视频理解能手
阿里云开发的第二代视觉语言模型,具备强大的视觉理解和跨模态推理能力。其核心特性包括超长视频理解(20分钟以上)、原生动态分辨率技术支持任意尺寸图像识别、多语言图像/视频文本理解能力和支持自主设备操作的视觉代理能力。
增强版本Qwen2.5-VL具有强化文本/图表/版式视觉识别、10分钟长视频处理与精准片段定位、通过边界框或坐标点生成实现视觉定位,以及支持表格表单结构化输出处理。
2.4. X-InstructBLIP:跨模态理解框架
Salesforce Research、香港科技大学和南洋理工大学联合开发的基于BLIP-2框架的跨模态理解模型,采用指令调优方法。核心特性包括使用Q-Former实现指令感知特征提取、支持图像/视频、音频、3D的跨模态框架、通过指令微调实现零样本泛化能力。
架构由图像编码器(ViT架构)、Q-Former(基于Bert架构)和LLM(FlanT5或Vicuna)组成。
2.5. MiniCPM-V:端侧轻量优化
深度求索与清华NLP实验室联合研发的端侧多模态模型系列,专为资源受限设备设计。核心特性包括轻量高效(最新MiniCPM-V 2.6仅8B参数)、卓越OCR能力(OCRBench 700+分数)、支持多图与视频流处理、通过RLAIF-V优化实现低幻觉率,以及支持30+种语言。
技术实现采用经典架构组合:视觉编码器(SigLIP-400M)、投影器(Perceiver Resampler结构)和语言模型(Qwen2-7B或Llama3-8B)。
2.6. Florence2:易集成视觉模型
微软推出的先进视觉语言模型,相比前代有显著改进,提供实用API和工具帮助开发者集成视觉理解能力。
3、多模态大模型集成策略:完整数据闭环
为有效整合这些模型,需要系统化的实施路径。以下是完整的数据闭环策略。
3.1.多模态数据采集与预处理
技术选型: MiniCPM-V + 定制化数据提取管道
实施要点包括利用MiniCPM-V轻量特性进行初步数据筛选标注、使用OCR能力提取文档/图像文本信息、设计数据质量评估指标与标准化流程,以及部署边缘计算架构实现采集端实时预处理。
3.2.多模态内容理解与特征提取
技术选型: Qwen2-VL + LLaVA + 特征融合框架
实施要点包括使用Qwen2-VL处理复杂图像/长视频提取高层语义特征、部署LLaVA实现细粒度图像理解与视觉问答、设计特征融合算法整合多模型输出,以及构建支持特征相似查询的向量检索系统。
3.3.精准指令执行与推理
技术选型: X-InstructBLIP + 任务路由系统
实施要点包括利用指令感知能力处理复杂多模态任务、设计任务路由系统分配不同类型请求、实现多轮对话中的视觉文本上下文管理,以及开发根据任务复杂度动态调整的推理路径。
3.4.应用集成与高阶功能
技术选型: Florence2 + 定制化服务框架
实施要点包括使用Florence2作为核心系统引擎整合各阶段输出、开发符合统一接口标准的API网关、实现支持可视化报告与数据可视化的多模态内容生成,以及构建收集模型使用数据的用户反馈机制。
3.5.数据闭环优化
技术选型: 自适应学习框架 + 评估指标系统
实施要点包括设计模型性能评估指标(准确率/时延/资源消耗)、开发持续模型评估的自动化测试流程、实现用于模型微调的高质量反馈数据筛选机制,以及构建验证优化效果的A/B测试框架。
4、单一模型 vs 多模型协同:自动驾驶的关键决策
在自动驾驶领域,关于是使用单一全能模型还是多个专精模型的讨论十分关键。
4.1多模型组合的弊端
多个模型串联处理可能导致总时延超标,多模型并行运行可能耗尽计算资源,模型间通信和结果融合需额外设计工作。
4.2单一模型的优势与局限
选择单一模型可以简化系统架构,降低时延和资源需求。然而,功能覆盖不足,难以同时满足感知、决策和交互的所有需求。
5、自动驾驶集成挑战与解决方案
5.1. 实时性要求
挑战:多模型串联可能导致驾驶决策时延超出可接受范围。
解决方案包括模型蒸馏技术实现大模型知识向轻量模型压缩、关键安全决策本地处理与复杂推理云端协同的异步架构,以及基于场景复杂度的动态计算资源调度。
5.2. 模型协同机制
挑战:不同模型输出格式与置信度差异。
解决方案包括管理模型间通信的中央协调器设计、不同模型结果的置信度加权融合,以及实现无缝信息交换的统一表示空间。
5.3. 车规级可靠性
挑战:量产车需要比原型系统更高的可靠性标准。
解决方案包括关键感知任务多模型并行处理的冗余机制、实时评估模型状态的健康监控系统,以及模型故障时保证基本功能的降级策略。
6、实际应用案例
6.1.ADAS数据闭环系统
完整的数据闭环包含:车辆路况数据采集 → MiniCPM-V边缘预处理 → 云端Qwen2-VL语义分析 → 异常场景识别 → X-InstructBLIP复杂场景推理 → 模型性能评估 → 针对性数据增强训练 → 优化模型更新 → OTA车队部署。
该闭环持续优化ADAS系统性能,特别是在复杂场景和边缘案例处理方面。
6.2.智能座舱-驾驶协同系统
整合驾驶员状态监控与环境感知:多模态人机交互 → MiniCPM-V实时意图理解 → Qwen2-VL环境感知融合 → X-InstructBLIP驾驶员状态分析 → Florence2个性化驾驶建议 → 用户反馈收集 → 模型优化。
7、推荐架构:分层协作模型
7.1.感知层:系统的"眼睛"
- 功能:从传感器数据中提取环境信息
- 主要任务:物体检测、场景理解、环境建模、运动估计
- 数据类型:处理图像、点云、雷达信号等低级原始数据
7.2.交互层:系统的"嘴巴"和"耳朵"
- 功能:负责与外部世界的沟通和互动
- 主要任务:人机交互、车车通信、车路通信、车云通信
- 数据类型:处理文本、语音、视觉信号等高级数据
7.3.车用集成架构示例
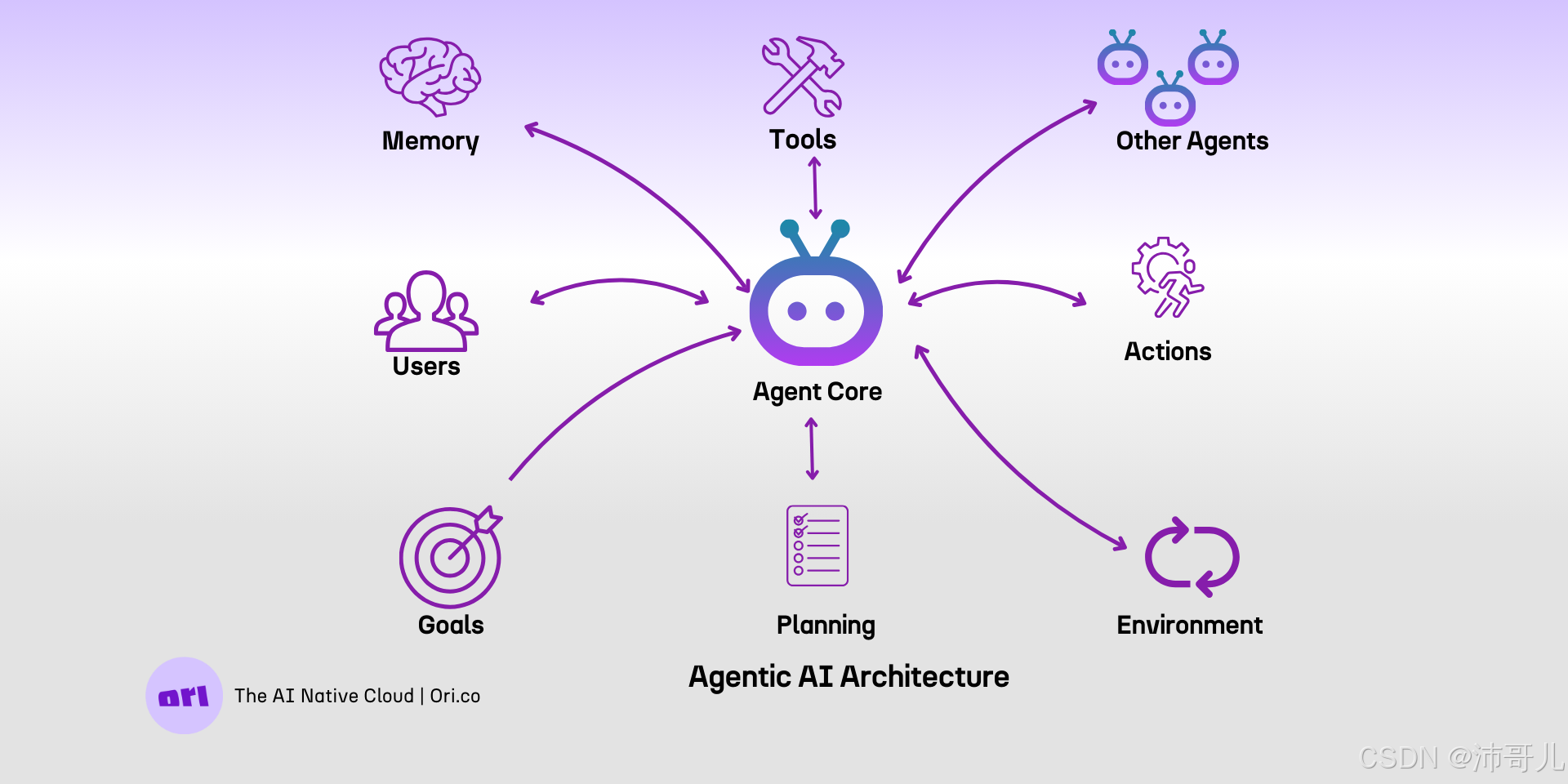
基于上述分析,最优的自动驾驶AI架构应采用多模型分层协作模式:
感知层:MiniCPM-V(高效端侧处理)或Qwen2-VL(复杂视觉任务)
决策层:X-InstructBLIP(多模态推理)
交互层:Qwen2.5-Omni(人机交互)
+------------------+ +------------------+ +------------------+
| 边缘感知层 | | 云端处理层 | | 决策规划层 |
| (MiniCPM-V) | -> | (Qwen2-VL+LLaVA) | -> | (X-InstructBLIP) |
+------------------+ +------------------+ +------------------+
^ ^ |
| | v
+------------------------------------------+ +------------------+
| 数据管理与优化层 | <- | 集成应用层 |
| (数据湖+特征存储+模型版本) | | (Florence2) |
+------------------------------------------+ +------------------+
^ |
| v
+------------------+ +------------------+ +------------------+
| 车队数据采集 | | 仿真数据生成 | | 应用服务层 |
| (传感器网络) | -> | (合成数据) | -> | (API+SDK) |
+------------------+ +------------------+ +------------------+
8、未来发展趋势
车规级模型优化:针对车载芯片优化的模型变体,平衡性能与能效 多车协同学习:利用车队数据实现隐私保护的分布式学习 场景自适应部署:根据场景动态调整模型组合 大模型辅助仿真:使用生成模型构建更真实的测试环境
9、结论
多模态大模型在自动驾驶中的应用代表了AI与汽车工业融合的前沿实践。通过构建完整的数据闭环系统实现多模型有机连接,可显著提升系统的感知能力、决策水平和用户体验。尽管单一模型(如Qwen2.5-Omni)具有简化系统架构的优势,但在高要求的自动驾驶场景中,多模型分层协作架构能更好地平衡性能、可靠性和功能覆盖。
随着技术发展,我们可以期待更为高效的模型蒸馏技术、混合部署策略和场景自适应能力,进一步推动自动驾驶向更高水平迈进。正如开源模型Qwen2.5-Omni所展示的那样,多模态AI不仅开放了代码,更开放了无限可能。
相关资源:
- Qwen2.5-Omni GitHub
- Qwen2.5-Omni 论文
- Qwen2.5-Omni 博客
- Qwen2.5-Omni 在线体验
你对多模态AI在自动驾驶中的应用有何看法?欢迎在评论区分享你的见解!