集合
Java集合是Java中用于存储和管理一组对象的工具。Java集合提供了相应的方法,用于用户对集合内数据的操作。
Java集合类提供了许多不同的数据结构,如列表、队列、栈、集合和映射,以满足不同类型的编程需求。
程序中如何存储大批量同类型的数据呢?使用数组是没有在学习集合时唯一的办法,数组确实好用,但是有一个缺陷就是数组是固定长度,不管是在定义时设置的长度,还是申请空间时设置的长度,都是有一个长度限制的,存储的数据超过了这个长度,那么就会产生数组下标越界异常。
那么如果在申请内存时,干脆就申请一块很大的空间呢?那不就可以了?但是如果这样申请内存的话,极易造成空间浪费,有可能你申请很大的一块内存,但是只需要使用其中的一点,又或者需要使用的空间还是超过了你申请的空间大小,那么使用起来还是非常的不方便。
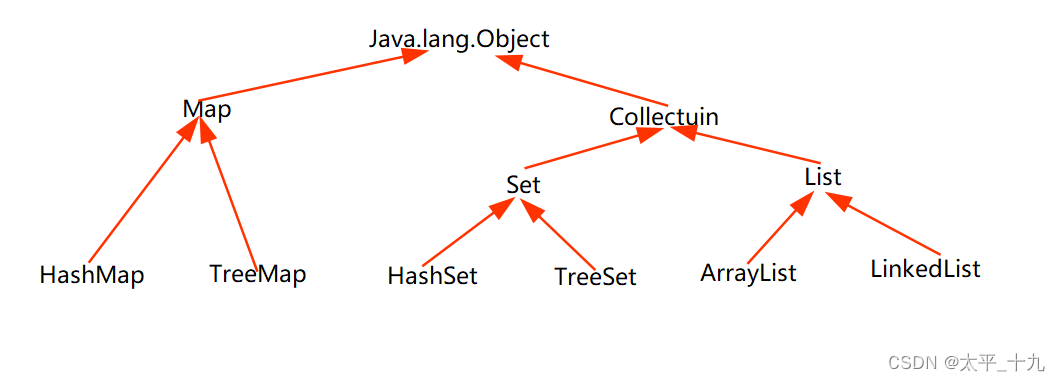
这个时候 集合 就出现了,集合的长度是可变的,内存空间随着数据得存入而逐渐得变大,能够很方便使用者,而不同的集合还有着不同的特点方法,对应不同的需要只需要选取不同的集合即可。以下是常见集合之间的继承关系图。
Collection 接口
collection接口作为LIst与Set集合的父类接口,提供很多的通用方法供两个集合进行使用,以下就是此接口提供的方法。方向详细自行查看JavaAPI。

以上的方法,List与Set接口都是可以使用的。
List集合
List接口继承了Collection接口,因此包含了Collection接口的所有方法,此外还定义了两个重要的方法:
- get(int index) : 获得指定索引的元素。
- set(int index,Object obj) : 将指定索引位置的元素对象,修改为obj。
List接口,下面的继承类的底层实现一般分为两种:
- 以ArrarList为代表的继承类,底层实现为动态数组。有下标,查询元素方便,插入、删除元素复杂。
- 以LinkedList为代表的继承类,底层实现为链表。无下标,查询元素复杂,插入、删除元素简单。
ArrayList类
ArrayList是Java中的一种数据结构,属于java.util包。它实现了List接口,并提供了用于操作数据的方法。ArrarList的底层代码实现是使用数组实现的,所以可以通过下标来找到指定元素。
主要特性:
- 动态数组:ArrayList是一个动态数组,这意味着它可以在运行时增长和收缩。当你添加元素并且已经达到了当前的容量时,ArrayList会自动增长其容量。
- 索引:ArrayList中的每个元素都有一个索引,可以通过这个索引快速访问元素。
- 线程不安全:ArrayList不是线程安全的,这意味着多个线程同时修改ArrayList可能会导致问题。如果需要在多线程环境中使用,可以考虑使用Collections.synchronizedList()来包装它。
- null元素:ArrayList允许存储null元素。
- 性能:ArrayList通常比LinkedList更快,因为它使用更少的内存,并且缓存了数组的长度。然而,如果你需要频繁地在列表的开头或中间插入或删除元素,那么LinkedList可能是一个更好的选择。
常用方法:
- add(E e): 将指定的元素追加到此列表的末尾。
- add(int index, E element): 在此列表中的指定位置插入指定的元素。
- get(int index): 返回此列表中指定位置的元素。
- remove(int index): 从此列表中移除指定位置的元素。
- size(): 返回此列表中的元素数。
- isEmpty(): 如果此列表中没有元素,则返回true。
- clear(): 从此列表中移除所有元素。
- contains(Object o): 如果此列表包含指定的元素,则返回true。 如果此列表包含指定的元素,则返回true。
示例:
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
// 创建一个ArrayList对象
ArrayList<String> list = new ArrayList<String>();
// 添加元素到ArrayList
list.add("Element 1");
list.add("Element 2");
list.add("Element 3");
// 输出ArrayList的元素
for (String element : list) {
System.out.println(element);
}
}
}
Set集合
在Java中,Set是一种集合,它用于存储不重复元素的集合。Set集合中的每个元素都是唯一的,它们按照自然顺序或者自定义顺序进行排序。 由于Set集合的底层实现是通过哈希表实现的,简略来说就是,由于哈希表在添加数据时,会通过哈希函数计算出哈希值,而哈希值是唯一的,而将哈希值作为该元素的下标,将元素存储在对应的位置下,那么如果添加两个重新的元素时,由于哈希值是一样的,那么该位置就会有元素存储,那么第二个元素就不能存储进哈希表中,以此来保证数据的唯一性。
Java中提供了几个实现Set接口的类,包括:
- HashSet: HashSet是基于哈希表的Set实现。它不保证元素的顺序,允许null元素,但不允许null作为键。
- TreeSet: TreeSet是基于红黑树的Set实现。它按照元素的自然顺序或者自定义顺序进行排序,不允许null元素。
- LinkedHashSet: LinkedHashSet是基于哈希表和链表的Set实现。它按照元素的插入顺序进行排序,允许null元素。
- EnumSet: EnumSet是基于枚举类型的Set实现。它不允许null元素,但允许枚举类型的元素。
基本方法: 这些类都实现了Set接口,因此它们都具有Set的基本操作方法。
包括:
1、添加元素:使用add()方法将元素添加到Set集合中。
2、删除元素:使用remove()方法将元素从Set集合中删除。
3、包含元素:使用contains()方法检查Set集合是否包含指定元素。
4、获取元素数量:使用size()方法获取Set集合中元素的数量。
5、遍历元素:使用iterator()方法获取Set集合的迭代器,并使用迭代器遍历集合中的元素。
需要注意的是,由于Set集合中的元素是唯一的,因此如果尝试添加已经存在的元素,该操作将不会有任何效果。
HashSet集合
HashSet类是Set接口的一个实现类,它使用哈希表(HashMap)来存储集合中的元素。HashSet类不保证集合中元素的顺序。此类允许使用null元素。
HashSet集合中的元素是无序的,即它们不会按照任何特定的顺序进行排列。
特性:
- 不允许重复元素:HashSet集合中的每个元素都是唯一的,不会存储重复的元素。如果尝试向集合中添加已存在的元素,该操作将不会有任何影响。
- 无序集合:HashSet集合中的元素没有固定的顺序。这意味着无法预测或依赖于元素的迭代顺序。
- 允许null元素:HashSet集合中可以包含一个null元素。
- 线程不安全:HashSet类不是线程安全的。如果多个线程同时修改HashSet集合,可能会导致不可预测的结果。如果需要在多线程环境中使用HashSet,可以考虑使用Collections.synchronizedSet()方法来获取一个同步的集合。
- 性能:HashSet的性能通常优于ArrayList和LinkedList,特别是在添加和查询元素时。这是因为它基于HashMap实现,而HashMap的查找和插入操作的时间复杂度都是O(1)。
示例
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
// 创建一个新的HashSet集合
HashSet<String> set = new HashSet<>();
// 向集合中添加元素
set.add("Apple");
set.add("Banana");
set.add("Orange");
// 打印集合的内容
System.out.println("Set: " + set);
// 检查集合是否包含某个元素
System.out.println("Contains 'Apple': " + set.contains("Apple"));
// 删除一个元素
set.remove("Banana");
System.out.println("Set after removing 'Banana': " + set);
// 遍历集合
for (String item : set) {
System.out.println("Item: " + item);
}
}
}
注意:由于HashSet是无序的,因此每次迭代输出的顺序可能会不同。
TreeSet集合
Java的TreeSet是一种基于TreeMap实现的类,它是一个有序的、不包含重复元素的集合。TreeSet中的元素可以是任何排序的对象,例如Integer、String或自定义对象。自定义对象需要自定义排序方法。
特性 :
- 元素的排序:TreeSet中的元素默认按照自然排序(升序)进行排列。例如,数字默认按照升序排列,字符串按照字典顺序排列。
- 元素的排序:TreeSet中的元素默认按照自然排序(升序)进行排列。例如,数字默认按照升序排列,字符串按照字典顺序排列。
- 元素的添加:你可以使用add()方法向TreeSet中添加元素。
- 元素的删除:你可以使用remove()方法从TreeSet中删除元素。
- 查找元素:你可以使用contains()方法检查TreeSet中是否包含某个元素。
- 遍历元素:你可以使用迭代器或增强for循环遍历TreeSet中的元素。
示例:
import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
// 创建一个新的TreeSet集合
TreeSet<Integer> set = new TreeSet<>();
// 向集合中添加元素
set.add(5);
set.add(3);
set.add(8);
set.add(1);
set.add(9);
// 打印集合的内容
System.out.println("Set: " + set);
// 检查集合是否包含某个元素
System.out.println("Contains 3: " + set.contains(3));
// 删除一个元素
set.remove(5);
System.out.println("Set after removing 5: " + set);
}
}
Map集合
Java中的Map接口是一个关联数组,可以存储键-值对,其中键是唯一的。Map接口在java.util包中。
它的实现类包括HashMap、TreeMap、LinkedHashMap等。
Map接口内的常用方法:
- size():返回Map中的键-值对的数量。
- isEmpty():判断Map是否为空。
- containsKey(Object key):判断Map中是否包含指定的键。
- containsValue(Object value):判断Map中是否包含指定的值。
- get(Object key):根据指定的键获取对应的值,如果键不存在则返回null。
- put(K key, V value):将指定的键-值对添加到Map中。
- remove(Object key):根据指定的键删除Map中的键-值对,并返回被删除的值。
- clear():清空Map中的所有键-值对。
只要实现了Map接口的类,那么以上的方法都是可以使用的。
HashMap
HashMap是Java中Map接口的一种常用实现,它可以存储键值对,其中键是唯一的。
HashMap类在java.util包中。
常用方法:
- 允许使用null键和null值。
- isEmpty():判断HashMap是否为空。
- containsKey(Object key):判断HashMap中是否包含指定的键。
- containsValue(Object value):判断HashMap中是否包含指定的值。
- get(Object key):根据指定的键获取对应的值,如果键不存在则返回null。
- put(K key, V value):将指定的键值对添加到HashMap中。
- remove(Object key):根据指定的键删除HashMap中的键值对,并返回被删除的值。
- remove(Object key):根据指定的键删除HashMap中的键值对,并返回被删除的值。
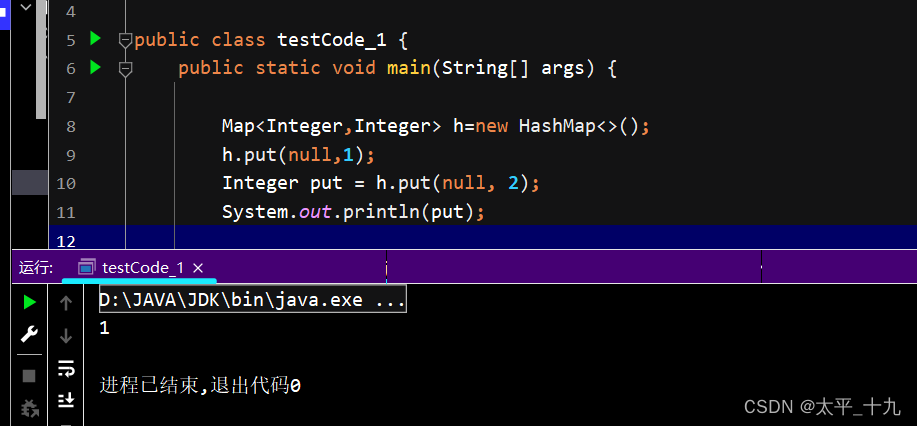
小细节: 在HashMap的put方法添加新的键值对时,如果此时的键已经在HashMap中存在,那么put方法还是会执行成功,且将键值对的值进行替换,将旧的值返回,将新的值覆盖之前的值。
TreeMap
TreeMap是Java中Map接口的一种实现,它可以存储键值对,其中键是唯一的。TreeMap类在java.util包中。
TreeMap的底层实现是红黑树(Red-Black Tree),这是一种自平衡的二叉搜索树。
特点:
- TreeMap中的键必须实现Comparable接口,或者提供一个Comparator对象作为构造函数的参数,用于指定键的排序顺序。
- TreeMap中的键值对是按照键的排序顺序进行存储的,因此可以根据键的顺序遍历TreeMap中的元素。
- 不允许使用null键和null值。
- 线程不同步,即不是线程安全的。如果需要多个线程同时访问TreeMap,需要使用Collections.synchronizedMap()方法来获取线程安全的Map。
- 底层实现是红黑树(Red-Black Tree),查询、插入和删除操作的时间复杂度都是O(log n)。
常用方法:
- size():返回TreeMap中的键值对数量。
- isEmpty():判断TreeMap是否为空。
- containsKey(Object key):判断TreeMap中是否包含指定的键。
- containsValue(Object value):判断TreeMap中是否包含指定的值。
- get(Object key):根据指定的键获取对应的值,如果键不存在则返回null。
- put(K key, V value):将指定的键值对添加到TreeMap中。
- remove(Object key):根据指定的键删除TreeMap中的键值对,并返回被删除的值。
- clear():清空TreeMap中的所有键值对。
双列集合的选用:如果不需要键值对排序的话,使用HashMap的效率会比TreeMap的效率高,如果需要排序的话,那么使用TreeMap的效果会更好。