切片
# # 切片
# s = 'hello word'
# # 下标索引为0的
# print(s[0]) #h
# # 左闭右开 (左是下标开始的,右是几个索引值)例如从0开始算 4个索引值
# print(s[0:4]) #hell
# # 更改起始值的开始位置
# print(s[1:]) #ello word
# # 下标结束位置
# print(s[:5]) #hello
# #从下标为0的位匿开始到下标为6的位置结束每次增长2个长度
# print(s[0:6:2]) #hlo
字典 遍历 删除 添加 修改 查询
# 字典查询
# preson = {'name':'周阿狗' ,'age':18}
# # 查询方式
# print(preson['name']) #周阿狗 直接打印name的值
# print(preson.get('age')) #18 可以使用get获取值
# # print(preson["sex"]) #报错 因为没有sex KeyError: 'sex'
# 字典修改 preson['name'] 选的有的数据进行修改 没有的就是添加 有的就是修改
# preson = {'name':'周阿狗' ,'age':18}
# print(preson) #{'name': '周阿狗', 'age': 18}
# preson['name'] = '张三'
# print(preson) #{'name': '张三', 'age': 18}
# # 字典添加 preson['sex']没有的进行添加 没有的就是添加 有的就是修改
# preson = {'name':'周阿狗' ,'age':18}
# print(preson) #{'name': '周阿狗', 'age': 18}
# preson['sex'] = '男'
# print(preson) #{'name': '周阿狗', 'age': 18, 'sex': '男'}
# preson['name'] = '张三'
# print(preson) #{'name': '张三', 'age': 18, 'sex': '男'}
# # 字典删除 del不可以删除对象(preson) clear 删除全部但是保留对象(括号)
# preson = {'name':'周阿狗' ,'age':18}
# print(preson) #{'name': '周阿狗', 'age': 18}
# del preson['age']
# print(preson) #{'name': '周阿狗'}
#
# preson.clear() #删除全部但是保留括号
# print(preson) #{}
# # 字典遍历数据
# preson = {'name':'周阿狗' ,'age':18}
# print(preson) #{'name': '周阿狗', 'age': 18}
# # 遍历preson 的所有key值
# for key in preson.keys():
# print(key) # name age
# # 遍历preson 的所有value值
# for value in preson.values():
# print(value) # 周阿狗 18
# # 遍历preson 的所有key value值
# for key,value in preson.items():
# print(key,value) # name 周阿狗 age 18
# # 遍历preson 的所有项值
# for item in preson.items():
# print(item) #('name', '周阿狗') ('age', 18)
定义函数
# # 定义函数
# # 练习1
# def f1():
# print('nihao')
# print('woshixiaozhou')
# # 调用函数
# f1()
# # 练习2
# def sun():
# a = 1
# b = 2
# c = a+b
# print(c)
# sun()
# # 练习3
# def sun(a,b): #(形参)
# c = a+b
# print(c)
# # 实参
# sun(100,20)
函数返回值
# 函数返回值
# # 练习1
# def sun():
# return '冰淇淋'
#
# # 把sun的返回值 赋值给food
# food = sun()
# # 打印的两种形式
# print(food)
# print(sun())
# # 练习2
# def sun(a,b): #(形参)
# c = a+b
# return c
# # 把sun的返回值 赋值给food 要么赋值 输出新值
# food = sun(10,50)
# # 打印的两种形式
# print(food)
# # 或者输出带值
# print(sun(10,50))
作用域
# 作用域
# 全局作用域
# a = 100
# def sun():
# print(a)
#
# sun()
#局部作用域
# def sun():
# a = 120
# print(a)
# sun()
序列化
异常报错
# 异常提示写法
# try:
# 可能出现的异常
# except 异常类型
# 友好提示
# try:
# fp = open('text.txt','r') #打开这个文件
# fp.read() #读取
# except FileNotFoundError:
# print('没有这个')
urllib使用
# 引入 urllib
import urllib.request
# 定义路径
url = 'https://baike.baidu.com/'
# 模拟器像服务器端发送请求
response = urllib.request.urlopen(url)
#(3)获取响应中的页面的源码content 内容的意思
# #read方法返回的是字书形式的二进制数据
# 故我们要孵=进制的数据转换为字符串
#二进制--》字符串 解码 decode('编码的格式')
# 获取相应源码
content = response.read().decode('utf-8')
# 打印数据
print(content)
一个类型六个方法
# 一个类型和六个方法
# import urllib.request
# # 定义路径
# url = 'https://baike.baidu.com/'
#
# response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response 是 HTTPResponse
# print(type(response)) #<class 'http.client.HTTPResponse'>
# 按照一个字节一个字节的读 读取全部字节
# content = response.read()
# print(content)
# 按照一个字节一个字节的读 read()可以写你要读取多少字节
# content = response.read(4)
# print(content) #b'<!DO'
# # 按照一个字节一个字节的读 readline()只能读取一行
# content = response.readline()
# print(content) #b'<!DOCTYPE html>\n'
# # 按照一个字节一个字节的读 readlines()读取全部
# content = response.readlines()
# print(content) #b'<!DOCTYPE html>\n'
# # 返回状态码 200就是成功返回
# print(response.getcode()) #200
# # 返回路径
# print(response.geturl()) #https://baike.baidu.com/
# # 获取状态信息
# print(response.getheaders()) #[('Content-Type', 'text/html; charset=UTF-8'),
下载 视频 音频 图片
# 下载
# import urllib.request
# 下载网页
# 定义路径
# url = 'https://baike.baidu.com/'
# urllib.request.urlretrieve(url,'baike.html')
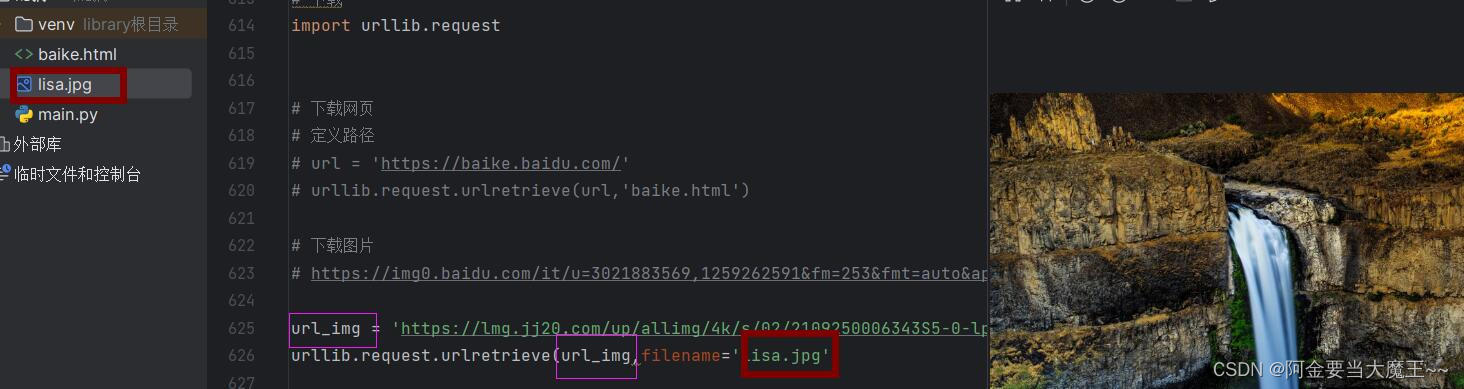
# 下载图片
# https://img0.baidu.com/it/u=3021883569,1259262591&fm=253&fmt=auto&app=120&f=JPEG?w=1140&h=641
# url_img = 'https://lmg.jj20.com/up/allimg/4k/s/02/2109250006343S5-0-lp.jpg'
# urllib.request.urlretrieve(url_img,filename='lisa.jpg')
# 下载视频
# https://vd2.bdstatic.com/mda-picyuf5c6sekhy5c/720p/h264/1694646650126259454/mda-picyuf5c6sekhy5c.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1694690882-0-0-275f5e093e7c5d6af95b829765e00417&bcevod_channel=searchbox_feed&pd=1&cr=2&cd=0&pt=3&logid=1682821669&vid=1074113355220740733&klogid=1682821669&abtest=112751_3
# url_v = 'https://vd2.bdstatic.com/mda-picyuf5c6sekhy5c/720p/h264/1694646650126259454/mda-picyuf5c6sekhy5c.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1694690882-0-0-275f5e093e7c5d6af95b829765e00417&bcevod_channel=searchbox_feed&pd=1&cr=2&cd=0&pt=3&logid=1682821669&vid=1074113355220740733&klogid=1682821669&abtest=112751_3'
# urllib.request.urlretrieve(url_v,'video.mp4')
图片
视频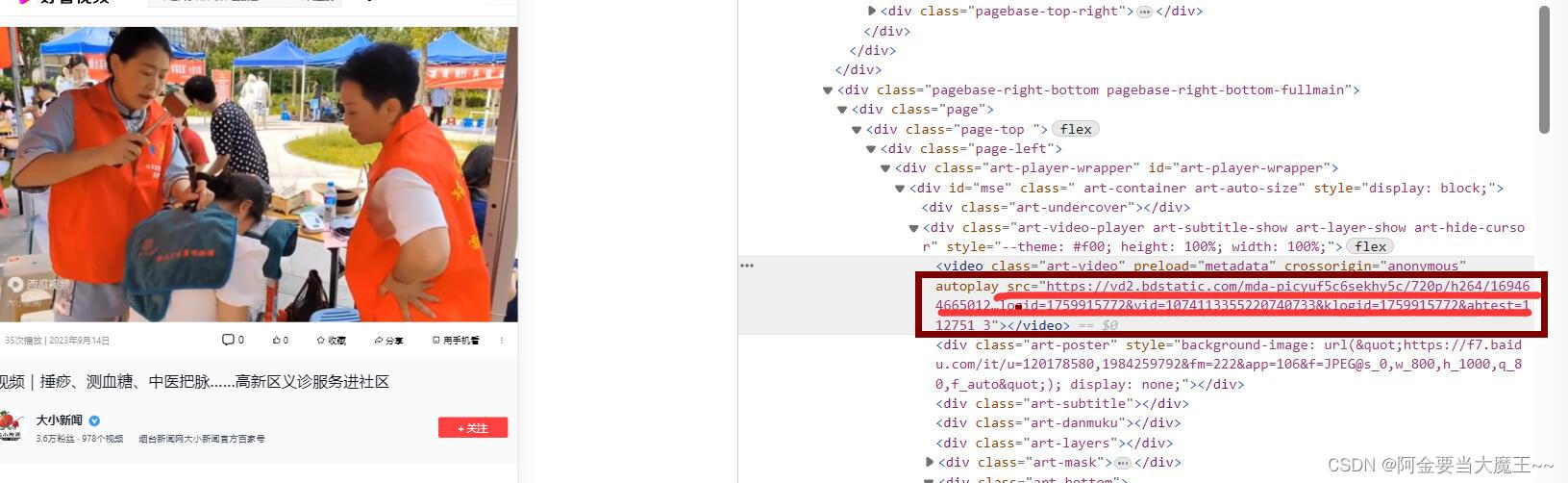

网页
定制请求对象 是为了防止反爬
# 定制请求对象
import urllib.request
# 定义路径
url = 'https://baike.baidu.com/'
# ua 请求头
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"}
# 并因为urlopen.方法中不能存储字典两以headers不能传递进去#请求对象的定刹
# #注意因为参数顺序的问题不能疸接写url 和headers中间还有data所以我们需要关键字传参
# 防止反爬 就要携带请求头
request = urllib.request.Request(url = url ,headers = headers)
# 模拟服务器发送请求
response = urllib.request.urlopen(request)
# 读取html页面数据 获取相应源码
content = response.read().decode("utf8")
print(content)

请求quote
import urllib.request
import urllib.parse
# 定义路径
url = 'https://baike.baidu.com/'
#请求头
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36 Edg/116.0.0.0"
}
#要搜索的对象
name = urllib.parse.quote('百度')
#拼接路径
url = url + name
request = urllib.request.Request(url=url,headers=headers)
# 模拟服务器发送请求
response = urllib.request.urlopen(request)
# 读取html页面数据 获取相应源码
content = response.read().decode("utf8")
print(content)