文章目录
- 大数据组件之Flink
- 一.Flink简介
- Flink是什么?
- Flink的特点
- Flink框架处理流程
- Flink发展时间线
- Flink在企业中的应用
- Flink的应用场景
- 为什么选择Flink?
- 传统数据处理架构
- 有状态的流式处理(第一代流式处理架构)
- 流处理的演变(第二代流式处理架构)
- 新一代流处理器——Flink(第三代分布式流处理器)
- 流处理的应用场景
- Flink的分层 API
- Flink vs Spark
- 二.快速上手Flink
- API 简介
- 环境准备
- 导入依赖
- 日志配置
- 提供数据
- 批处理 Word Count
- 流处理 Word Count
- 读取文本流 Work Count
- 三.部署Flink
大数据组件之Flink

一.Flink简介
Flink是什么?
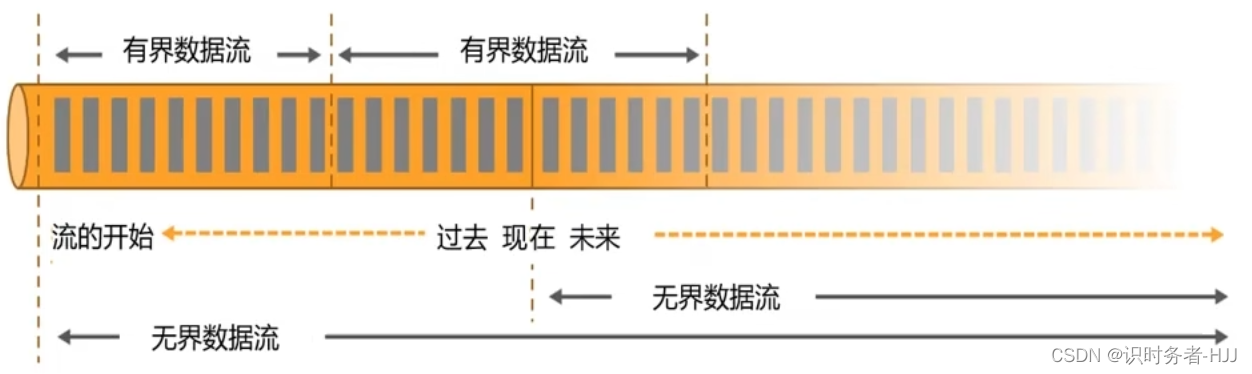
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
Flink官网:https://flink.apache.org
Flink的特点
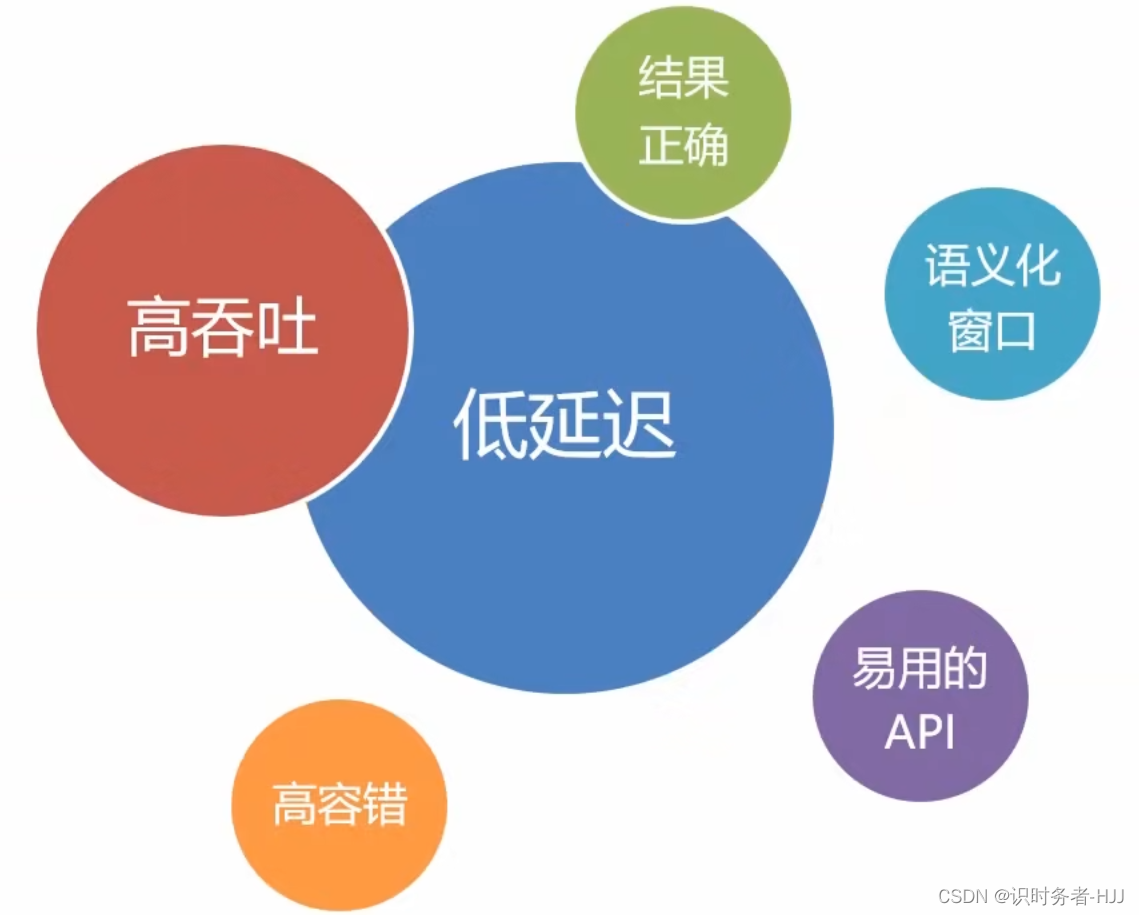
Flink框架处理流程

Flink发展时间线

Flink在企业中的应用

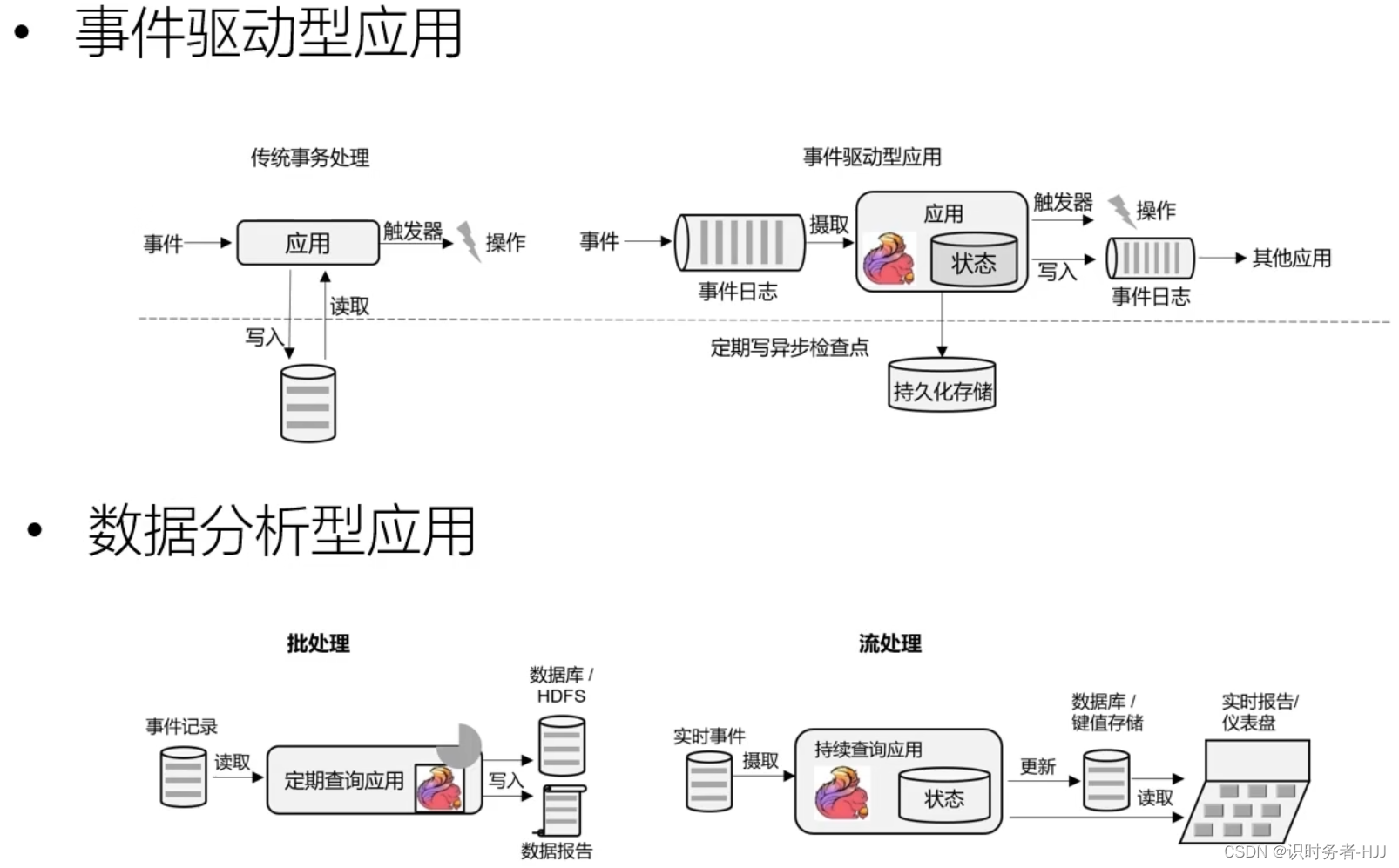
Flink的应用场景
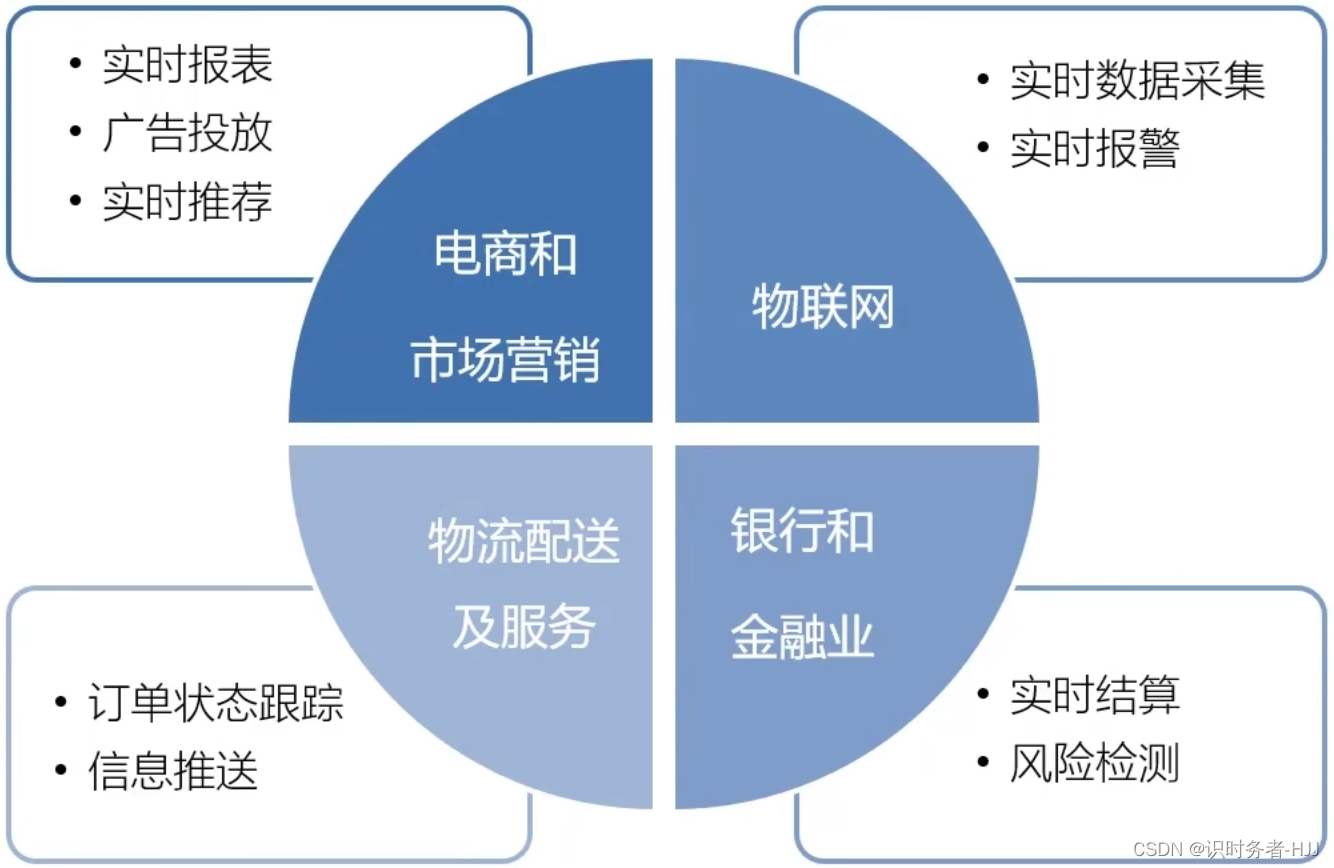
为什么选择Flink?

传统数据处理架构
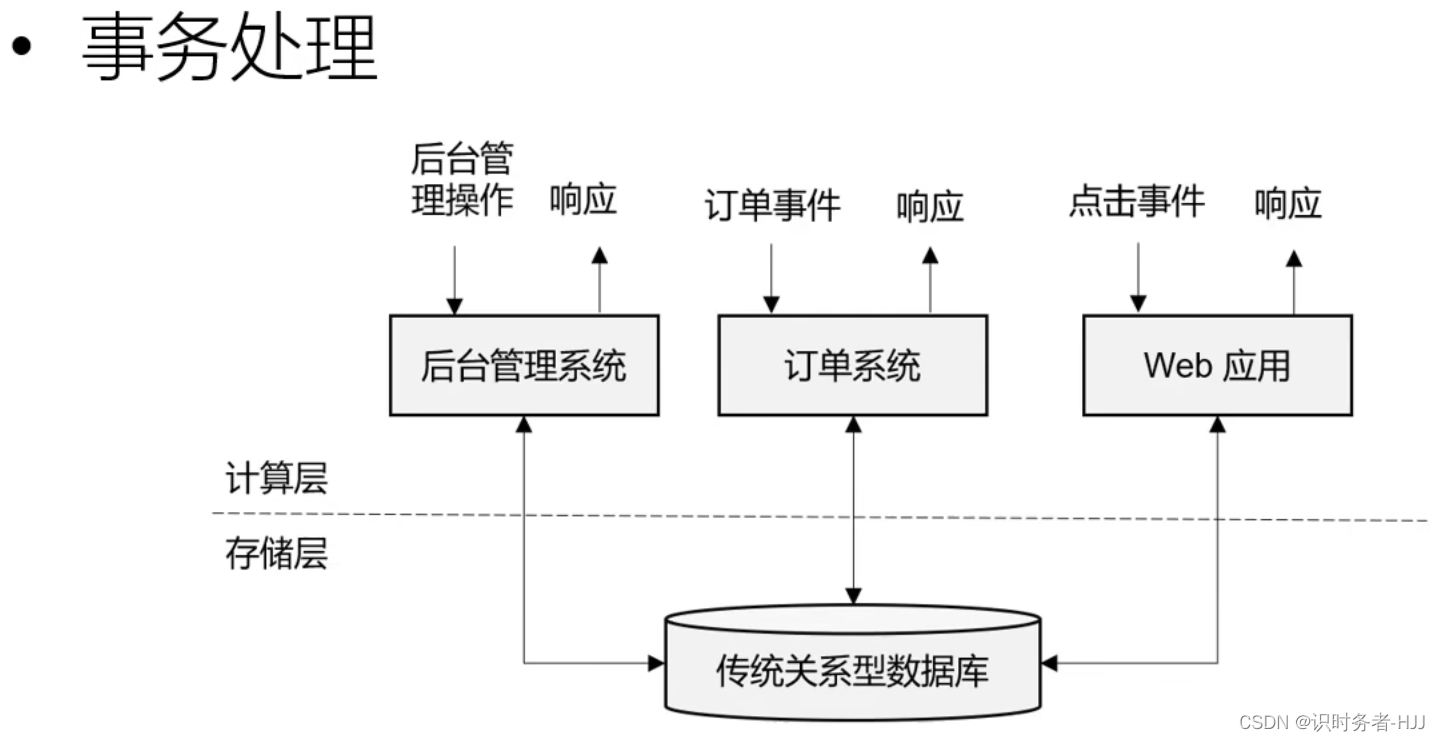
关系型数据库的性能瓶颈,无法支撑大数据下的数据计算。
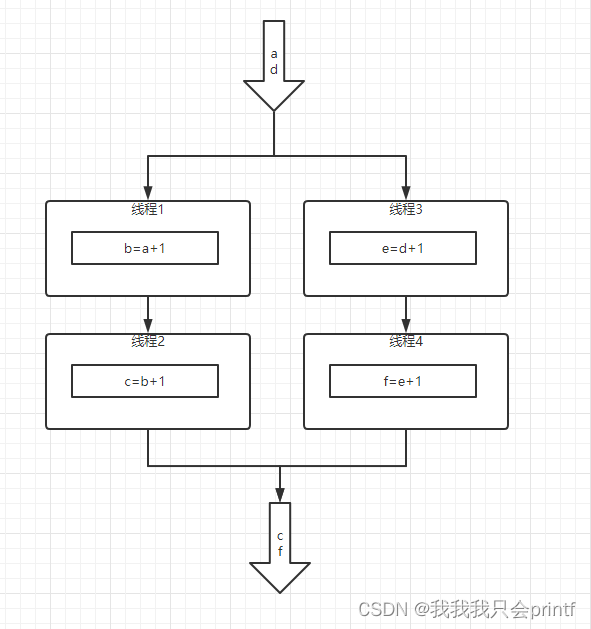
有状态的流式处理(第一代流式处理架构)
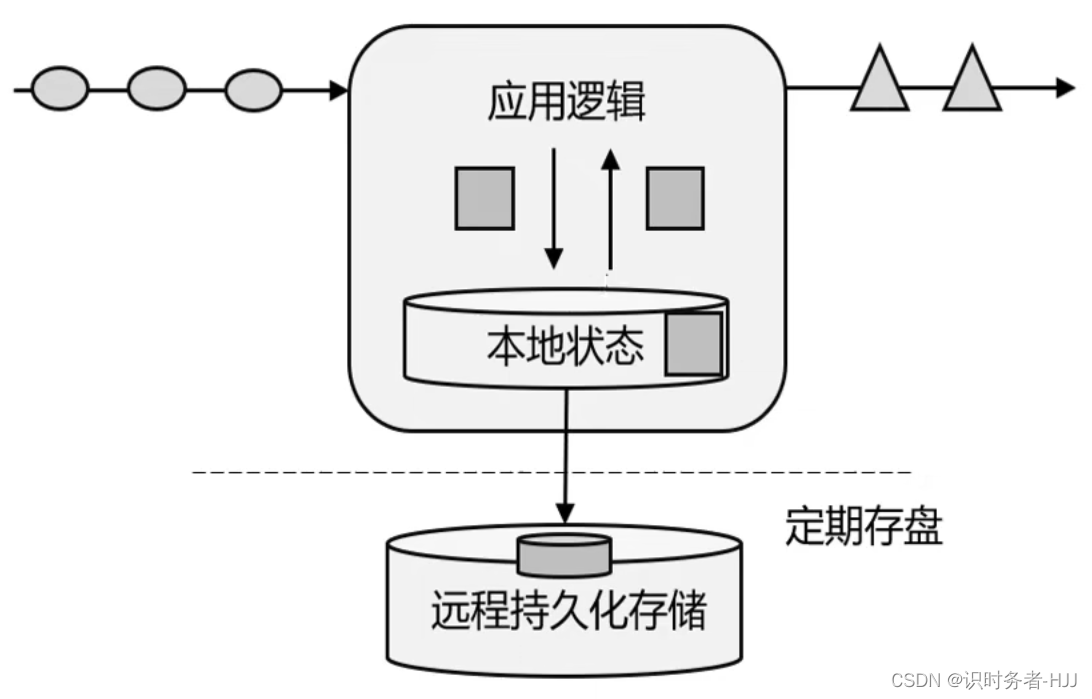 基于传统数据处理架构,使用本地状态存在内存中,定期存盘,发生故障可以从持久化存储中恢复数据。
基于传统数据处理架构,使用本地状态存在内存中,定期存盘,发生故障可以从持久化存储中恢复数据。
但当数据量很大时,使用集群模式,不同的应用有不同的本地状态,各自处理各自的数据,互不干扰。在分布式处理架构中,数据在传输和处理的过程中,时间是不确定的,数据可能会产生乱序,当需要进行数据汇总时,无法保证之前数据处理的顺序,导致结果不准确。
流处理的演变(第二代流式处理架构)
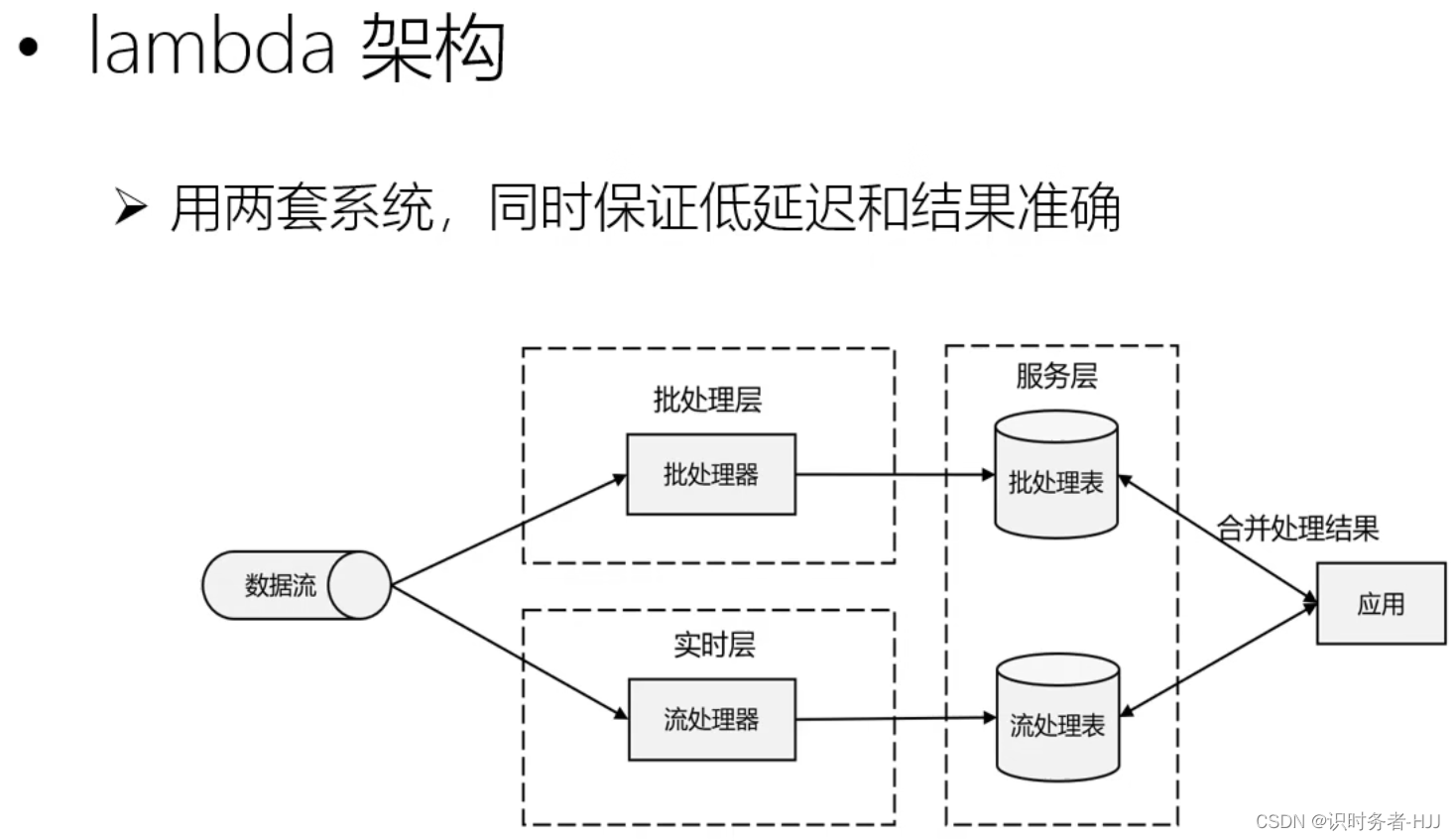 流处理器确保数据处理的低延迟,批处理器确保数据处理的准确性。但系统过于复杂,实现一个需求,同时要维护两套系统,开发及维护成本过高。
流处理器确保数据处理的低延迟,批处理器确保数据处理的准确性。但系统过于复杂,实现一个需求,同时要维护两套系统,开发及维护成本过高。
新一代流处理器——Flink(第三代分布式流处理器)
 Flink使用一套系统实现 lambda 架构中的两套功能,对于Flink而言,每秒钟能处理百万个事件,毫秒级的延迟并且可以保证结果的准确性。
Flink使用一套系统实现 lambda 架构中的两套功能,对于Flink而言,每秒钟能处理百万个事件,毫秒级的延迟并且可以保证结果的准确性。
流处理的应用场景
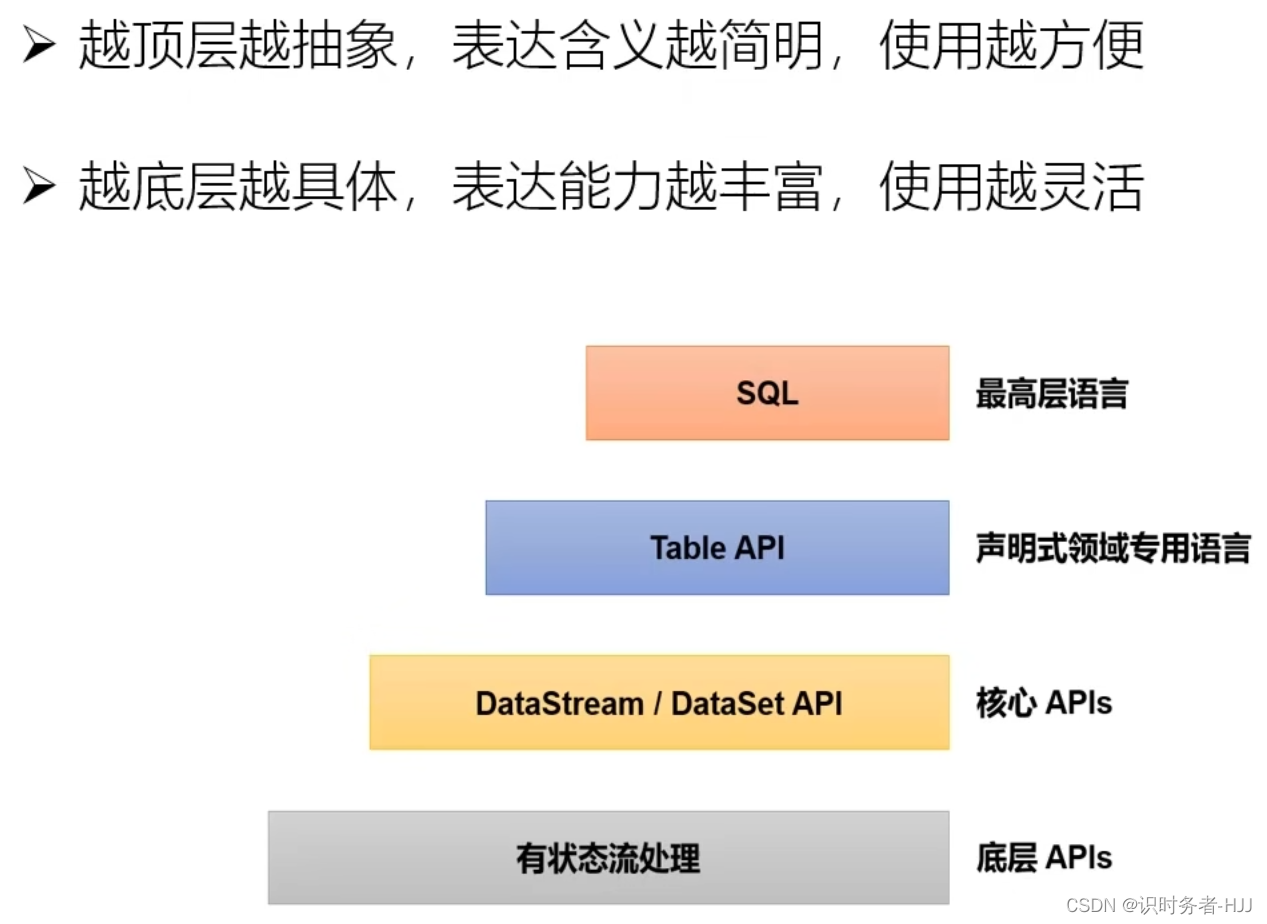
Flink的分层 API
Flink vs Spark
Flink数据处理架构:
Spark数据处理架构:
 数据模型:
数据模型:
 运行时架构:
运行时架构:

二.快速上手Flink
API 简介
Flink底层是以Java编写的,并为开发人员同时提供了完整的Java和Scala API,在具体项目应用中,可以根据需要选择合适语言的 API 进行开发。
环境准备
- Win 11
- JDK 1.8
- Maven
- IDEA
- Git
导入依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<flink.version>1.13.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
日志配置
在 resources 下创建 log4j.properties 文件
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
提供数据
在项目下创建 input 文件夹,在此文件夹下创建 words.txt 文件,内容为:
hello world
hello flink
hello java
批处理 Word Count
新建 BatchWordCount.java
package com.handsome.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @ClassName BatchWordCount
* @Author Handsome
* @Date 2022/12/19 14:37
* @Description 批处理 Word Count
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2.从文件读取数据(使用的是 DataSet API)
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
// 3.将每行数据进行分词,转换成二元组类型(line 行数据 Collector 收集器)
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
// 5.分组内进行聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
// 6.打印结果
sum.print();
}
}
打印结果
(flink,1)
(world,1)
(hello,3)
(java,1)
流处理 Word Count
新建 BoundedStreamWordCount.java
package com.handsome.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName BoundedStreamWordCount
* @Author Handsome
* @Date 2022/12/19 15:26
* @Description 流处理 Word Count
*/
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.从文件读取数据(使用的是 DataStream API)
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
// 3.将每行数据进行分词,转换成二元组类型(line 行数据 Collector 收集器)
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5.分组内进行聚合统计
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6.打印结果
sum.print();
// 7.启动执行
env.execute();
}
}
打印结果
9> (world,1)
3> (java,1)
13> (flink,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
IDEA使用多线程模拟了Flink集群,因此每次输出的结果可能都不相同,前面的数字为线程的编号,未设置并行度则默认为电脑最大核数。
读取文本流 Work Count
新建 StreamWorkCount.java
package com.handsome.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName StreamWorkCount
* @Author Handsome
* @Date 2022/12/19 17:24
* @Description 读取文本流 Work Count
*/
public class StreamWorkCount {
public static void main(String[] args) throws Exception {
// 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从参数中提取主机名和端口号
//ParameterTool parameterTool = ParameterTool.fromArgs(args);
//String host = parameterTool.get("host");
//int port = parameterTool.getInt("port");
//DataStreamSource<String> lineDataStream = env.socketTextStream(host, port);
// 2.读取文本流
DataStreamSource<String> lineDataStream = env.socketTextStream("8.142.157.59", 6666);
// 3.将每行数据进行分词,转换成二元组类型(line 行数据 Collector 收集器)
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5.分组内进行聚合统计
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6.打印结果
sum.print();
// 7.启动执行
env.execute();
}
}
8.142.157.59 为 Linux 服务器 IP 地址,需要根据不同的 Linux 服务器,填写不同的 IP 地址,6666 为 Linux 服务监听的端口号。
在 Linux 中执行 nc -lk 6666 监听 6666 端口
启动 StreamWorkCount.java
在 Linux 中输入要计算的数据
 打印结果
打印结果
5> (hello,1)
11> (handsome,1)
9> (world,1)
5> (hello,2)
13> (flink,1)
5> (hello,3)
3> (java,1)
5> (hello,4)
三.部署Flink
视频链接:https://www.bilibili.com/video/BV133411s7Sa