大家好,我是邵奈一,一个不务正业的程序猿、正儿八经的斜杠青年。
1、世人称我为:被代码耽误的诗人、没天赋的书法家、五音不全的歌手、专业跑龙套演员、不合格的运动员…
2、这几年,我整理了很多IT技术相关的教程给大家,爱生活、爱分享。
3、如果您觉得文章有用,请收藏,转发,评论,并关注我,谢谢!
博客导航跳转(请收藏):邵奈一的技术博客导航
| 公众号 | 微信 | CSDN | 掘金 | 51CTO | 简书 | 微博 |
教程目录
- 0x00 教程内容
- 1. 引入相关依赖的包
- 2. 构建房价数据集并可视化
- 3. 数据预处理
- 4. 数据拟合
- 5. 数据预测
- 0xFF 总结
0x00 教程内容
背景说明:假设有一些租房相关的信息,是中介带了很多客户看了很多房子后,记录下来的数据。现在你也有个房子,假设是10平方,准备租2500元,不知道是否能租出去?所以你想预测一下。接下来我们将会做这样的一件事。
1. 引入相关依赖的包
# 从sklearn.preprocessing里导入StandardScaler。
from sklearn.preprocessing import StandardScaler
# 从sklearn.linear_model里导入LogisticRegression
from sklearn.linear_model import LogisticRegression
2. 构建房价数据集并可视化
# X:每一项表示租金和面积
# y:表示是否租赁该房间(0:不租,1:租)
X=[[2200,15],[2750,20],[5000,40],[4000,20],[3300,20],[2000,10],[2500,12],[12000,80],
[2880,10],[2300,15],[1500,10],[3000,8],[2000,14],[2000,10],[2150,8],[3400,20],
[5000,20],[4000,10],[3300,15],[2000,12],[2500,14],[10000,100],[3150,10],
[2950,15],[1500,5],[3000,18],[8000,12],[2220,14],[6000,100],[3050,10]
]
y=[1,1,0,0,1,1,1,1,0,1,1,0,1,1,0,1,0,0,0,1,1,1,0,1,0,1,0,1,1,0]
3. 数据预处理
标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导。
ss = StandardScaler()
X_train = ss.fit_transform(X)
print(X_train)
执行后,结果为:
[[-0.60583897 -0.29313058]
[-0.37682768 -0.09050576]
[ 0.56003671 0.71999355]
[ 0.14365254 -0.09050576]
[-0.14781638 -0.09050576]
[-0.68911581 -0.49575541]
[-0.48092372 -0.41470548]
[ 3.47472592 2.34099218]
[-0.32269773 -0.49575541]
[-0.56420055 -0.29313058]
[-0.89730789 -0.49575541]
[-0.27273163 -0.57680534]
[-0.68911581 -0.33365555]
[-0.68911581 -0.49575541]
[-0.62665818 -0.57680534]
[-0.10617796 -0.09050576]
[ 0.56003671 -0.09050576]
[ 0.14365254 -0.49575541]
[-0.14781638 -0.29313058]
[-0.68911581 -0.41470548]
[-0.48092372 -0.33365555]
[ 2.64195758 3.15149149]
[-0.21027401 -0.49575541]
[-0.29355084 -0.29313058]
[-0.89730789 -0.69838024]
[-0.27273163 -0.17155569]
[ 1.80918923 -0.41470548]
[-0.59751129 -0.33365555]
[ 0.97642089 3.15149149]
[-0.25191242 -0.49575541]]
4. 数据拟合
#调用Lr中的fit模块训练模型参数
lr = LogisticRegression()
lr.fit(X_train, y)
5. 数据预测
testX = [[2500,10]]
X_test = ss.transform(testX)
print("待预测的值:",X_test)
label = lr.predict(X_test)
print("predicted label = ", label)
#输出预测概率
prob = lr.predict_proba(X_test)
print("probability = ",prob)
输出:
待预测的值: [[-0.48092372 -0.49575541]]
predicted label = [1]
probability = [[0.43698672 0.56301328]]
由此可以知道,10平方的房子,想要租2500,能租出去的概率是0.56301328,租不出去的概率是0.43698672。
假设房东现在有一间10平方的房子,初步定价是2500元,但是房东不太清楚这个定价被租出去的概率有多大?如果你不用机器学习,你会怎么做呢?或者说,你会怎么去判断。按照我们的正常想法,肯定是要看一下这个价格、这个面积,租出去的概率有多大。如果有类似的面积和类似的价格,都被租出去了,那说明这个定价肯定是很容易被租出去的。
所以,接下来我们可以回过头去看之前提供的数据:
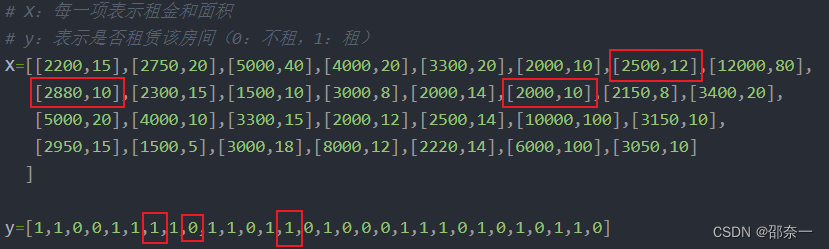
此处可以先找3组与[2500,10]相近的数据,看看情况怎么样,然后看看什么情况。比如[2500,12]、[2880,10]、[2000,10]这三组数据的情况分别是租出去,租不出去,租出去。
2500元,12平是可以租出去,但是小一点,2500元,10平租不租得出去呢?可以再看[2880,10]这组,发现2880元,10平是没租出去的,所以看到这里,还是没法确定2500元,10平是否能被租出去。此时,此时可以再看2000元,10平看能否被租出去,发现这个2000元,10平,可以租出去。2000比2500少了500块,被租出去也理所当然。
看到这里,同学们可能有点奔溃了,如果没有机器学习,我们就要手动算、手动判断,太麻烦了,所以…让这些事情交给机器学习吧!
0xFF 总结
- 同学们可以继续修改租金跟面积,租金不变,面积变大,看看概率是多少,租金变多,面积不变,看看概率是多少。
- 请继续关注我,我将更新更多使用教程。
邵奈一 原创不易,如转载请标明出处,教育是一生的事业。