一、下载安装
1,网盘n519

2,环境依赖和模型整合包必须下载,各种风格的模型可选
3,解压模型整合包
4,双击启动器运行依赖这个可执行文件,安装一些环境,直接下一步即可
二、启动
1,进入sd-webui-aki-v4.2文件夹下,找到A启动器入口,双击即可
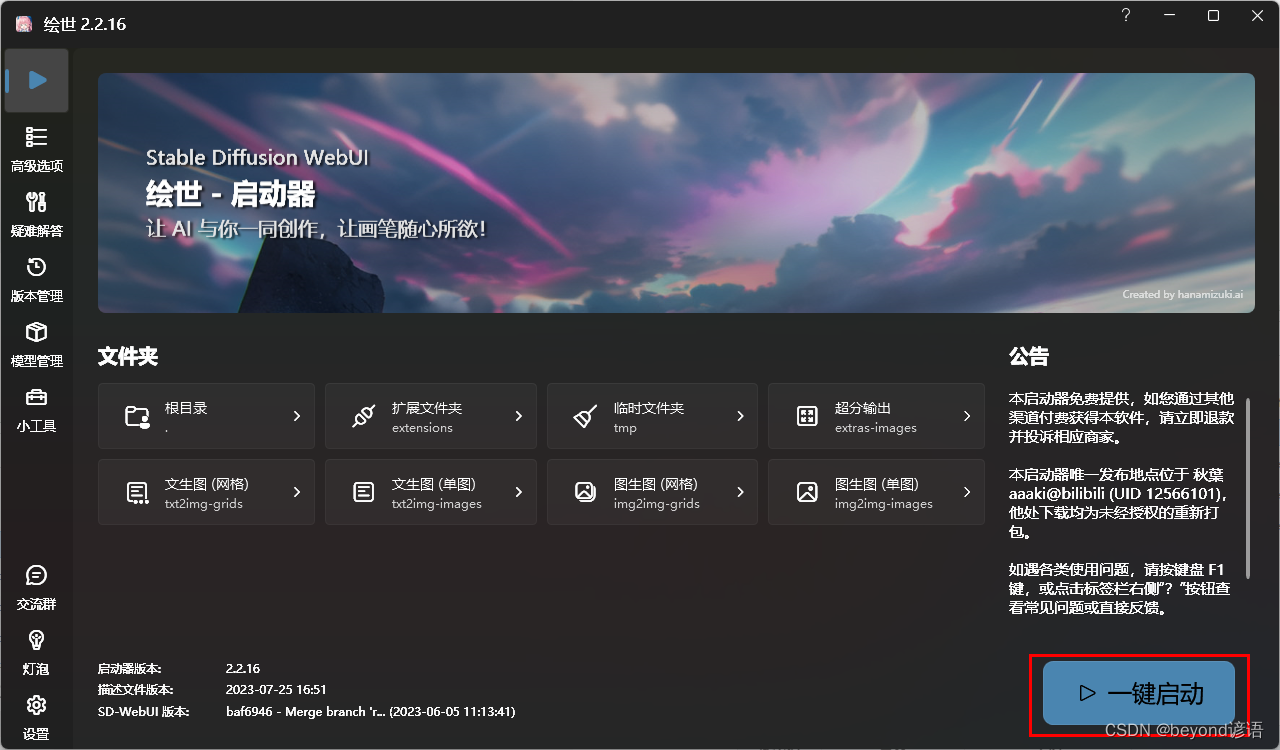
2,一键启动
稍等片刻
运行效果如下:
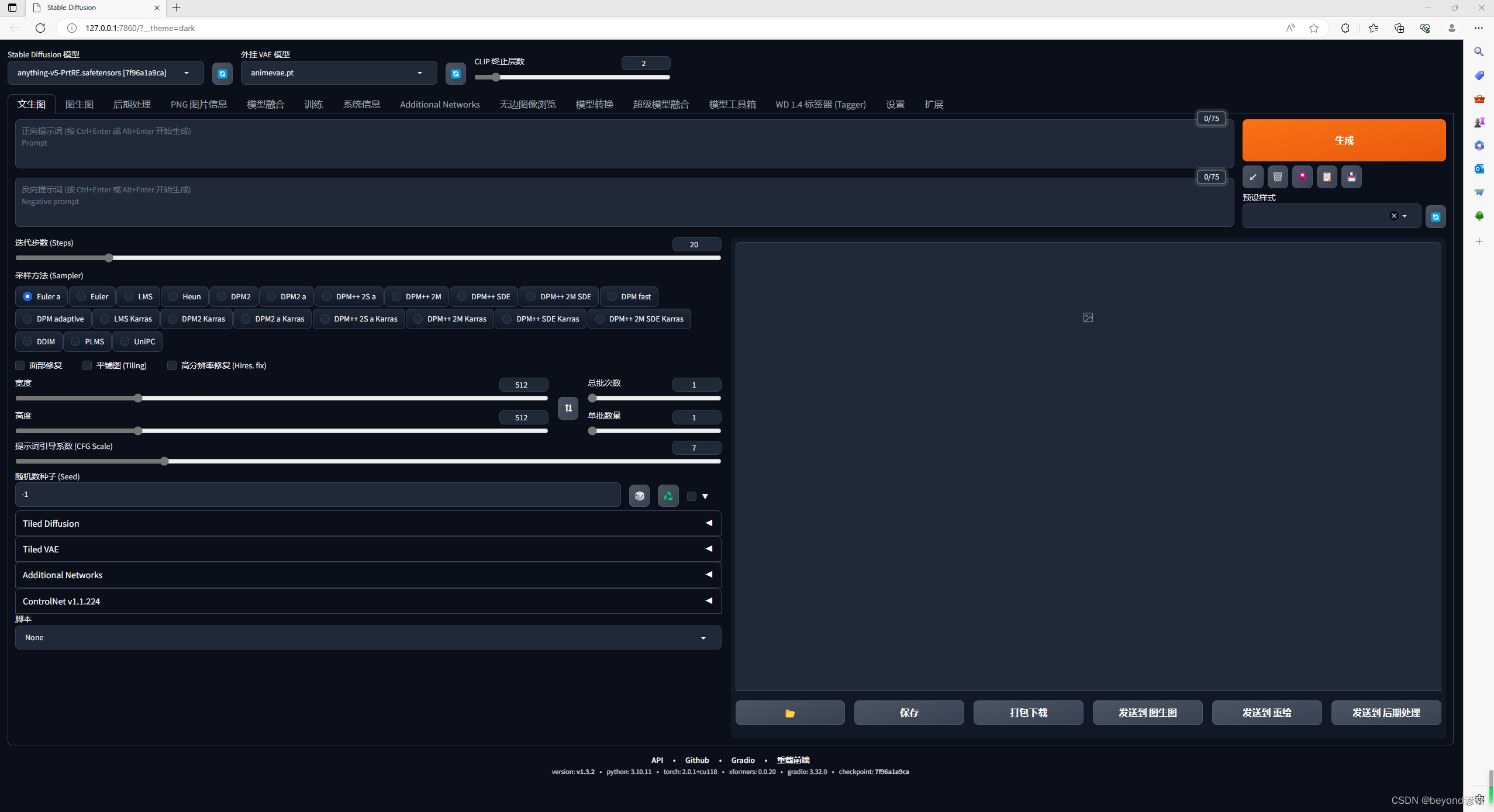
三、小测试
1,以文生图为例,输入一段描述,模型会根据描述信息生成一张图片
一个漂亮的小女孩在沙滩上漫步,看向镜头,特写,上半身
一个充满肌肉的小狗:A beautiful little girl is strolling on the beach, looking towards the camera, close-up, upper body,
希望出现的往正向提示词里面丢,不希望出现的往反向提示词里面丢
正向提示词:
(masterpiece:1,2),best quality,masterpiece,highres,original,extremely detailed wallpaper,perfect lighting,(extremely detremely detailed CG:1.2),drawing,paintbrush,
反向提示词:
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many dingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))),
这里的正向和反向prompts才是最为关键的因素所在,后续会进行讲解
点击生成即可,像这样

这不,老婆不就有了?
2,保持图片
方法一:选中照片右击,复制照片或者另存为即可
方法二:找到相关路径
以我的为例,主要在outputs下面,因为是文生图,故保存在了txt2img-images这个文件夹下
E:\stable_diffusion_web_ui\sd-webui-aki-v4.2\outputs\txt2img-images

四、模型功能
1,文生图(text2img)相关提示词(Prompts)用法
Ⅰ,prompts大致分类(都是英语描述哈,用英文逗号隔开)
①内容提示词
| 人物及主体特征 | 场景特征 | 环境光照 | 画幅视角 |
|---|---|---|---|
| 服饰穿搭:白色T恤 | 室内或者室外:室内 | 白天夜晚:夜晚 | 距离 |
| 发型发色:白色的长头发 | 大场景:海滩边 | 特定时段:日落 | 人物比例 |
| 五官特点:大大的眼睛 | 小细节:金黄色的向日葵 | 光环境:满天星辰 | 观察角度 |
| 面部表情:面带微笑 | 天空颜色:火烧云 | 镜头类型:超广角 | |
| 肢体动作:叉着腰 |
②画质、画风提示词
| 高画质、高分辨率 | 画风 |
|---|---|
| best quality, ultra-detailed, masterpiece,hires,8kk | 插画:illustration,painting,paintbrush |
| extremely detailed CG unity 8k wallpaper(超精细的8K Unity游戏CG) | 二次元:animecomic,game CG |
| unreal engine rendered (虚幻引擎渲染) | 写实系:photorealistic, realistic, photograph |
Ⅱ,prompts权重分配
①括号加数字
| 提示词 | 含义 | 举例 | 表达 |
|---|---|---|---|
| ( : ) | 改变权重倍数 | (yelloe dog:1.5), | 黄色的小狗的权重变为原来的1.5倍,也就是出现的概率更多了 |
②套括号
| 提示词 | 含义 | 举例 | 表达 |
|---|---|---|---|
| 小括号() | 每一层权重变为原来的1.1倍 | ((((big dog)))), | 大狗的权重变为原来的1.1*1.1*1.1*1.1倍 |
| 中括号[] | 每一层权重变为原来的0.9倍 | [[big dog]], | 大狗的权重变为原来的0.9*0.9倍 |
| 大括号{} | 每一层权重变为原来的1.05倍 | {{{big dog}}}, | 大狗的权重变为原来的1.05*1.05*1.05倍 |
③混合、迁移、迭代
| 提示词 | 含义 | 举例 | 表达 |
|---|---|---|---|
| 混合| | 对同一对象进行不同描述 | white | yellow flower, | 生成白色和黄色的混合花 |
| 迁移[] | 连续生成具有不同描述的对象 | [red|blue|green] flower, | 先生成红色的花,再生成蓝色的花,最后生成绿色的花 |
| 迭代 ( : ) | 一定阶段之后生成特定对象 | (red flower:bush:0.8) | 先生成红色的花,进程达到80%时,再生成灌木丛 |
2,图生图
图生图和文生图都类似,越往后学越简单。
主要就在于prompts提示词的书写,其他的都简单。
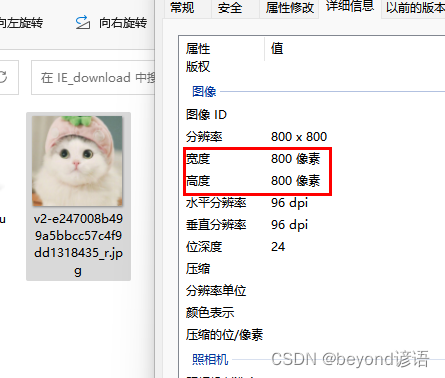
Ⅰ,上传图像
上传图片大小和参数的设置最好匹配,这里是800:800,一比一,也可以使用其他的比例,根据自己的电脑配置来
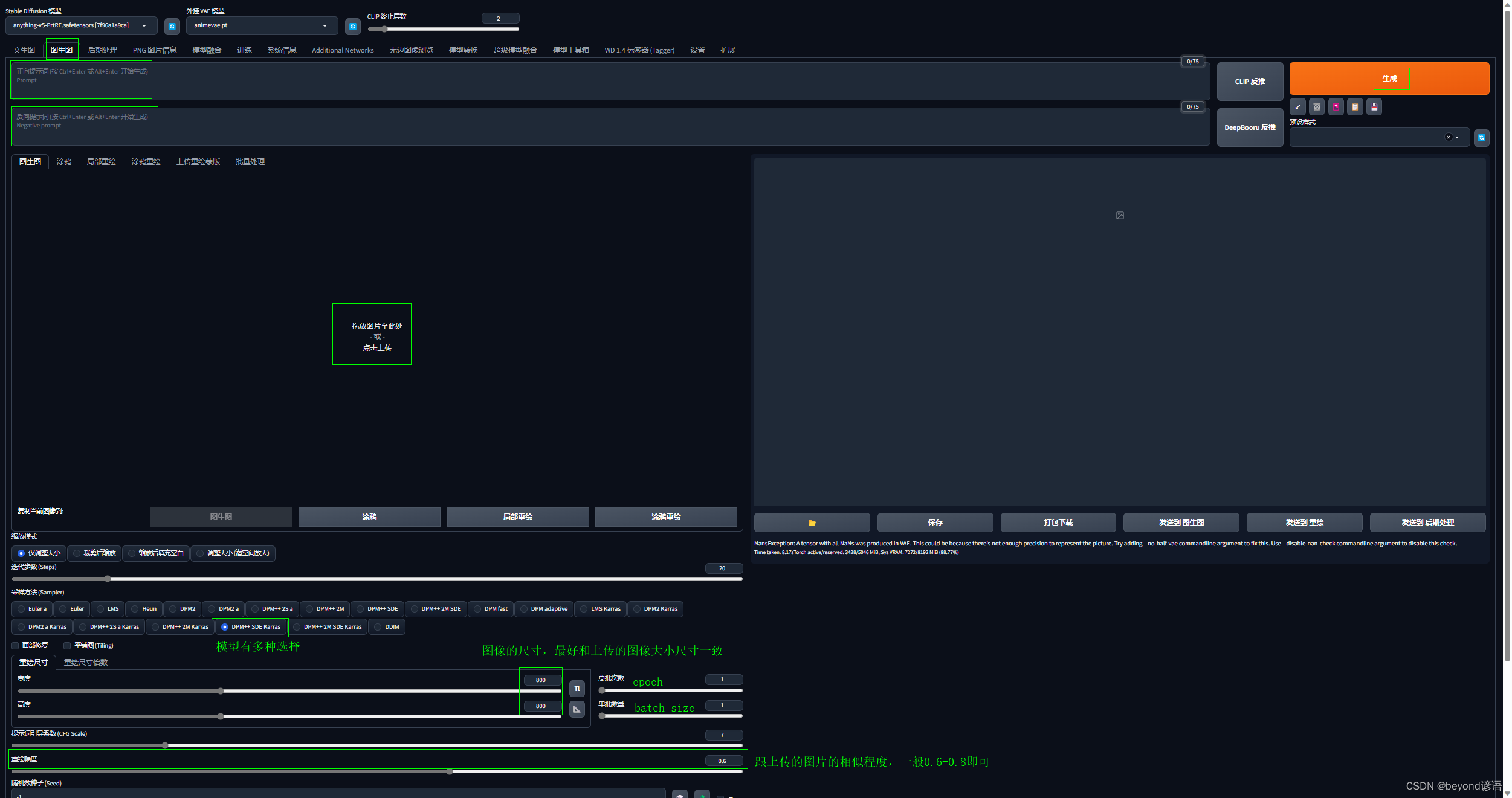
Ⅱ,书写prompts
书写prompts提示词,这里随便书写,正向、反向提示词使用文生图中的模板
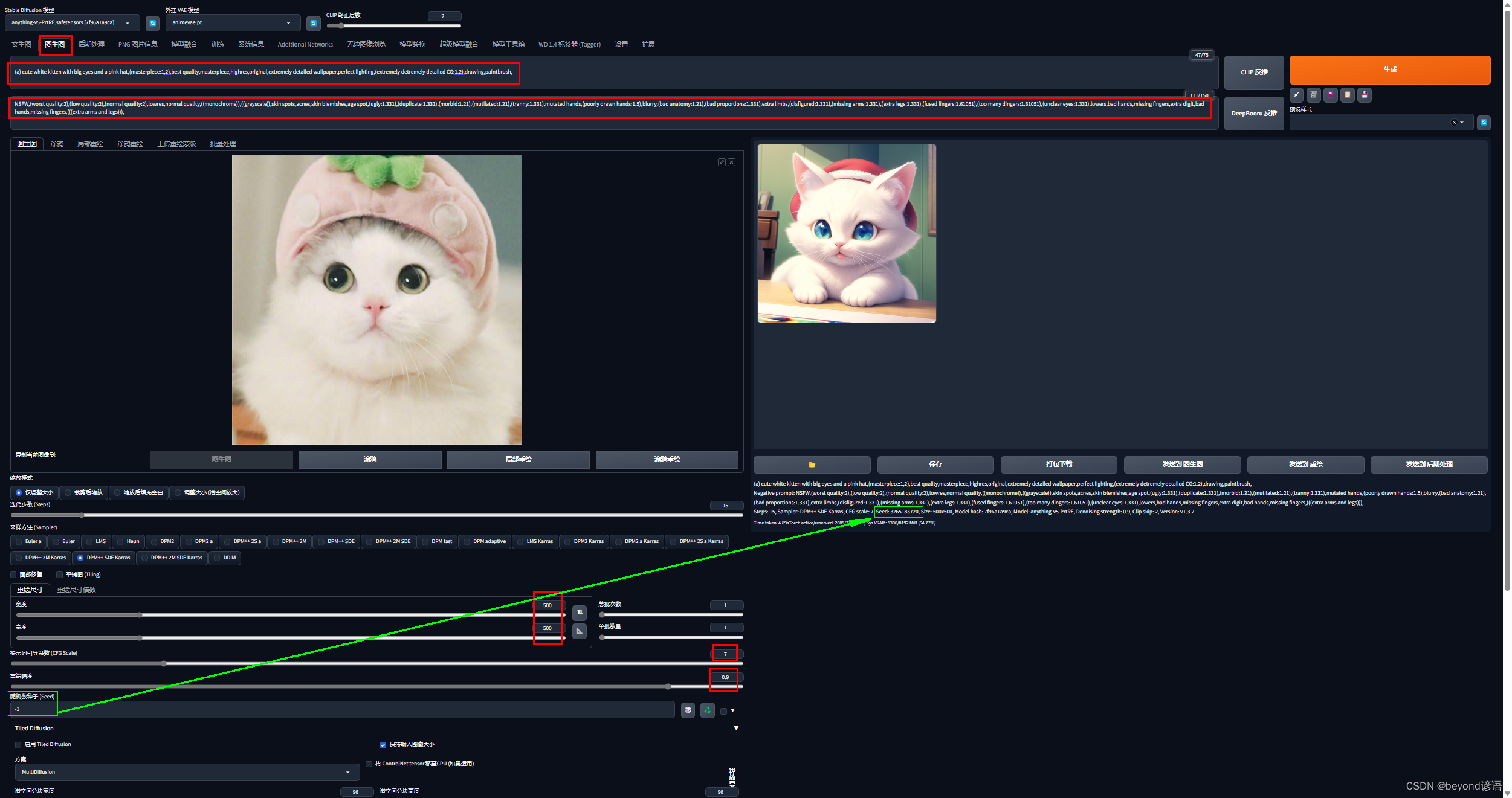
Ⅲ,图像生成
例如我的,这里的随机种子就可以理解成模型随机的风格,如果你就喜欢这样的风格,每次绘画的时候就可以输入这个随机种子即可
五、模型切换
模型路径
以我的为例:E:\stable_diffusion_web_ui\sd-webui-aki-v4.2\models\Stable-diffusion
这里就是存放模型的位置,发现好玩的模型下载复制到这里即可,models\Stable-diffusion,这些模型被称为Checkpoint
通常大模型的后缀为.ckpt,小模型的后缀为.safetensors
一些较好的模型下载:0522
二次元的深渊橘AbyssOrange等
我比较喜欢这个国风
像这样
左上角选择模型进行切换
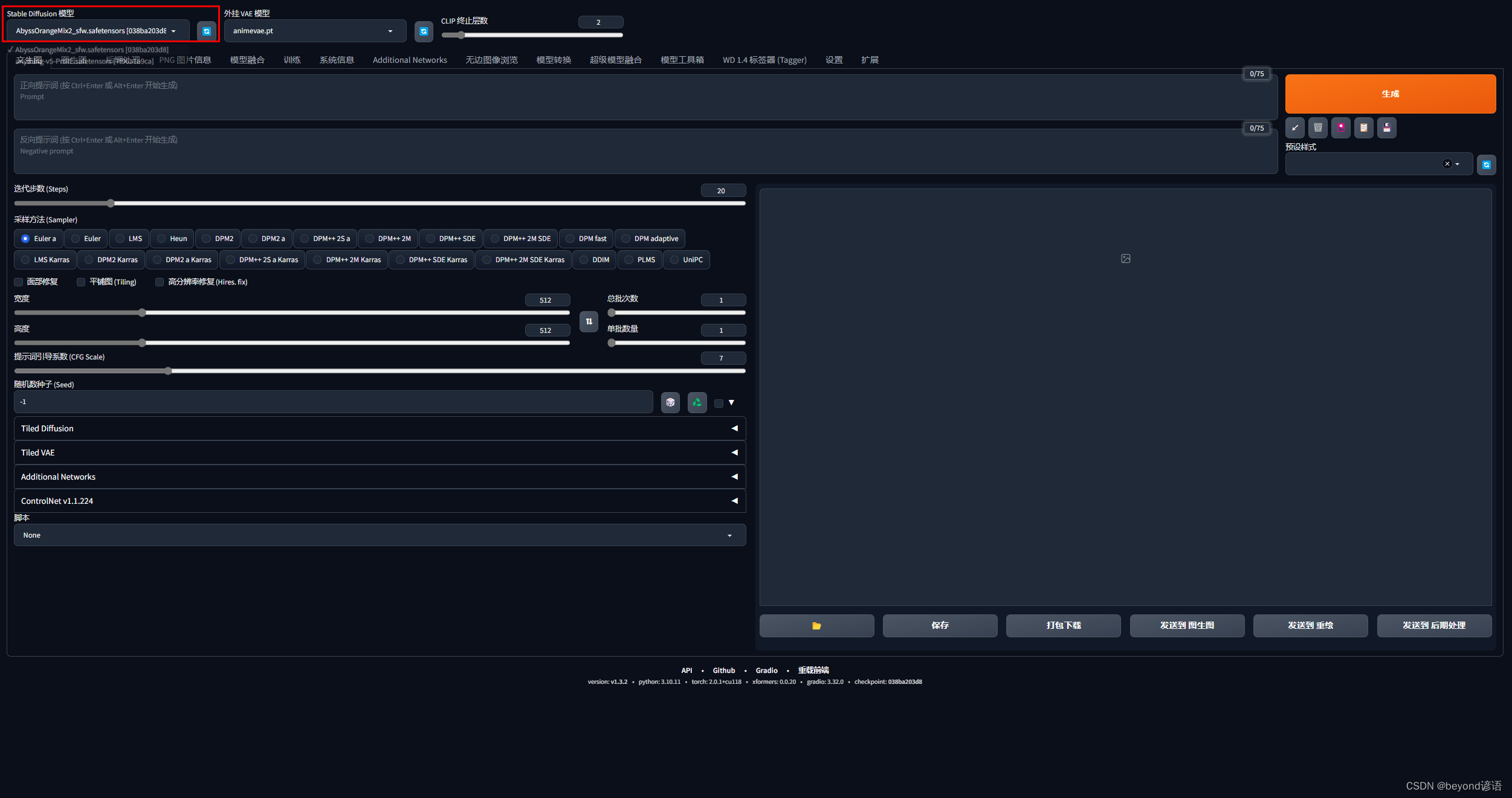
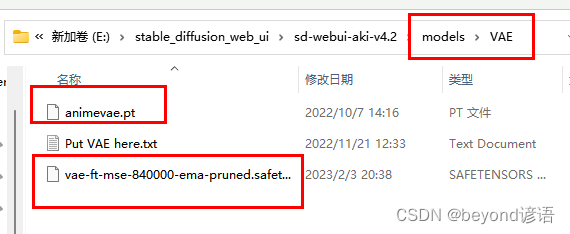
调整VAE模型,可以理解成滤镜模型,后缀通常为.pt或者.safetensor,其文件夹存放路径为:E:\stable_diffusion_web_ui\sd-webui-aki-v4.2\models\VAE

六、模型下载渠道
1,Hugging face
官网链接
搜索:stable diffusion
就可以直接下载模型
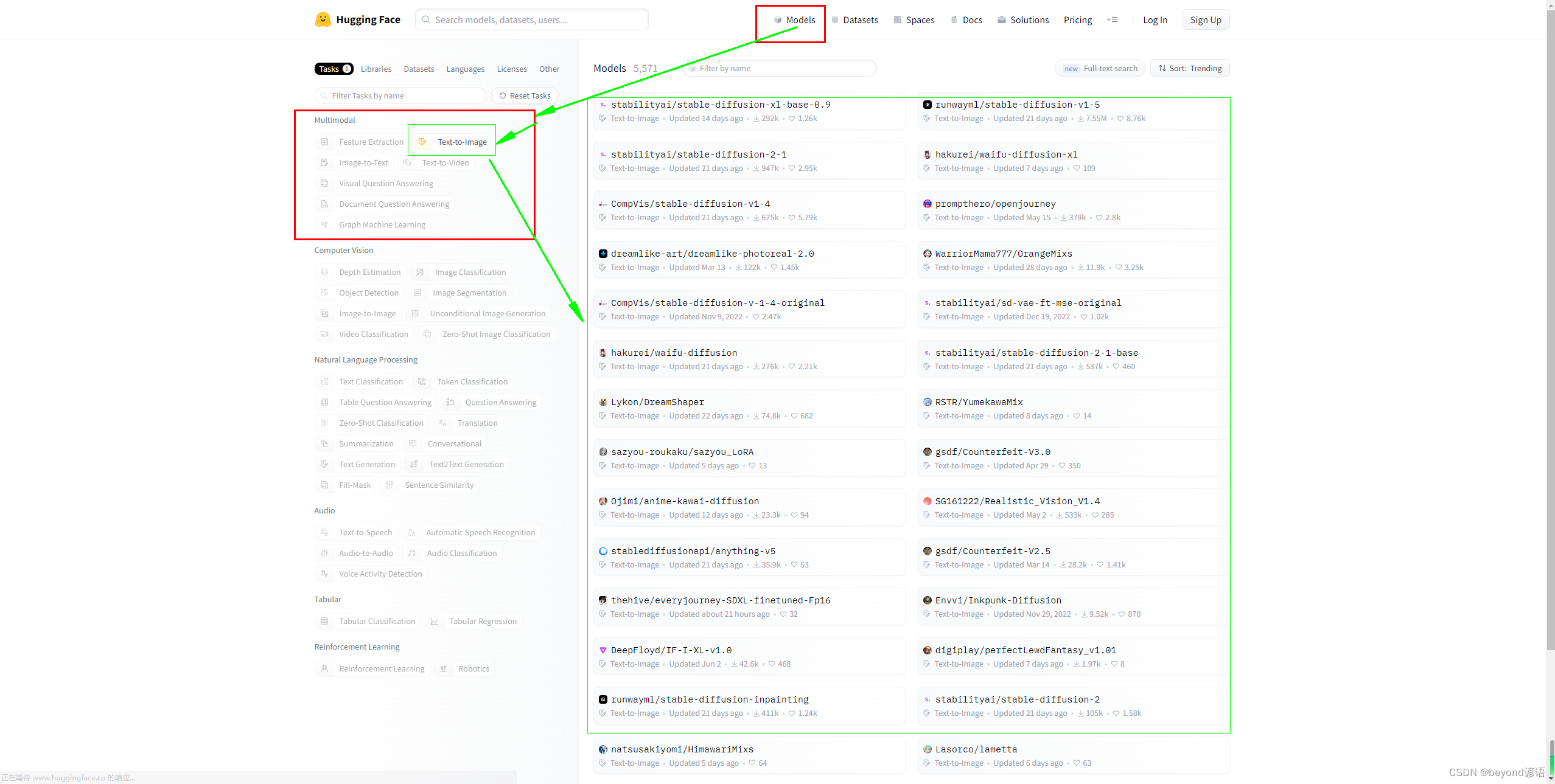
当然,点击 Models,选择Multimodal,例如Text-to-Image,就可以选择下载文生图模型了
这里以DreamShaper为例,点进去
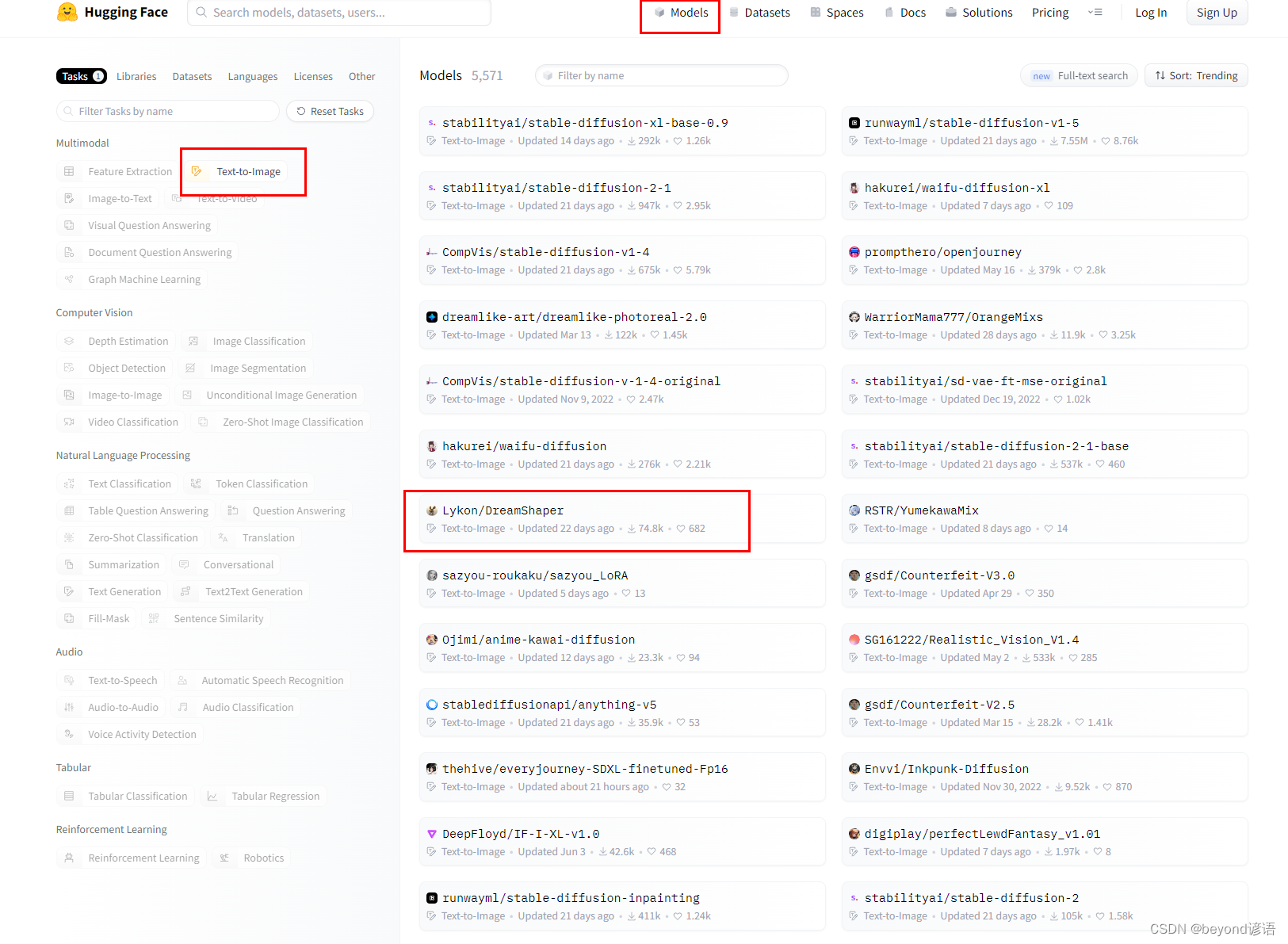
需要啥下载啥就行,下载好放到对应的文件夹下即可
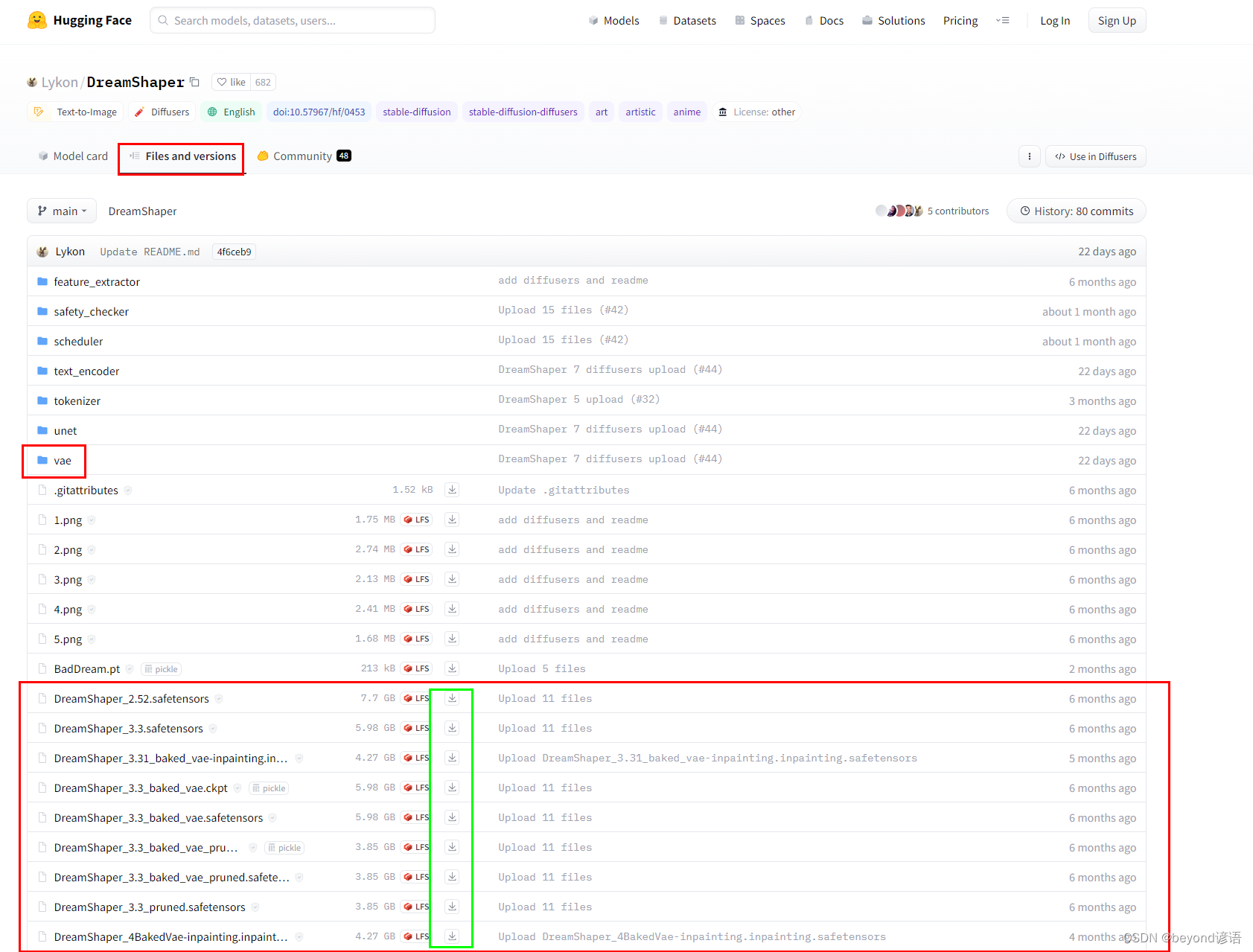
2,Civitai
网站链接,咳咳这个需要科学上网,你懂得
七、模型风格
1,二次元模型
关键词:illustration,painting,sketch,drawing,comic,anime,cartoon
模型推荐:万象熔炉Anything V5、Counterfeit V2.5、Dreamlike Diffusion
2,真实系模型
关键词:photography,photo,realistic,photorealistic.RAW photo
模型推荐:Deliberate、Realistic Vision、L.O.F.I
3,2.5D模型
关键词:3D,render,chibi,digital art,concept,{realistic}
模型推荐:never ending dream(NED)、Protogen(Realistic)、国风3(GuoFeng3)
八、Hi-Res Fix图片高清修复
1,文生图高清修复
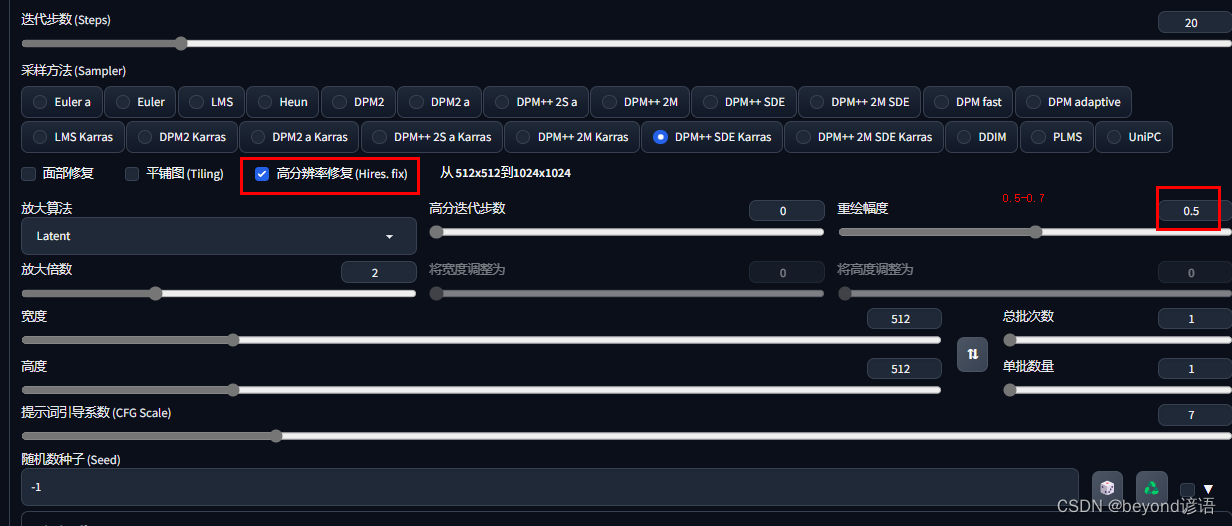
重绘幅度一般控制在0.5-0.7之间,其本质是将原始生成的低分辨率的图像重新进行绘制,变成高分辨率的图像
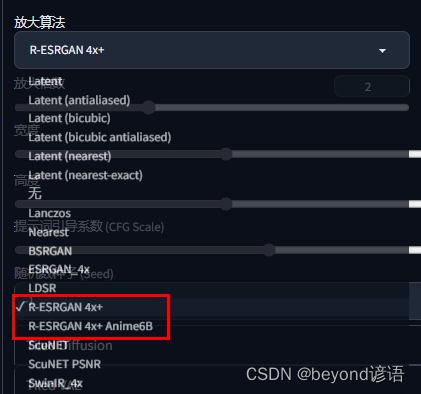
其中放大算法,无脑选择R-ESRGAN 4x+,若是二次元就选择R-ESRGAN 4x+ Anime6B,当然各种算法还是都有所差异的,需要尝试选择最符合自己喜欢的即可
最常用的操作:先通过文本描述prompts生成一张自己比较喜欢的图像,然后再勾选高清修复,采用相同的随机种子进行高分辨率重构即可
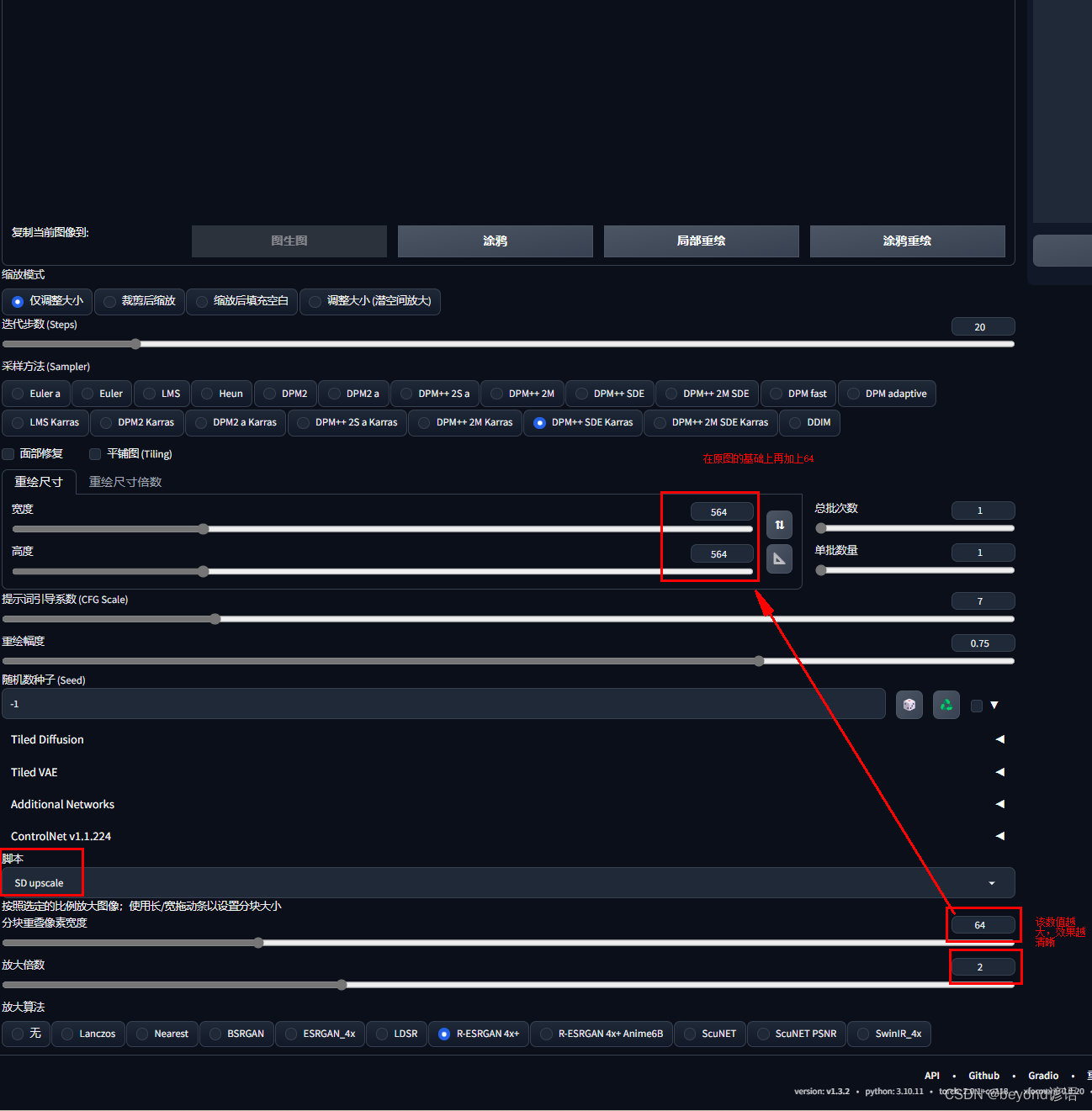
2,图生图放大
其本质就是裁剪多块,然后分别对这些小块进行放大,最后进行拼接即可实现放大
设置放大算法,记得点保存设置哈
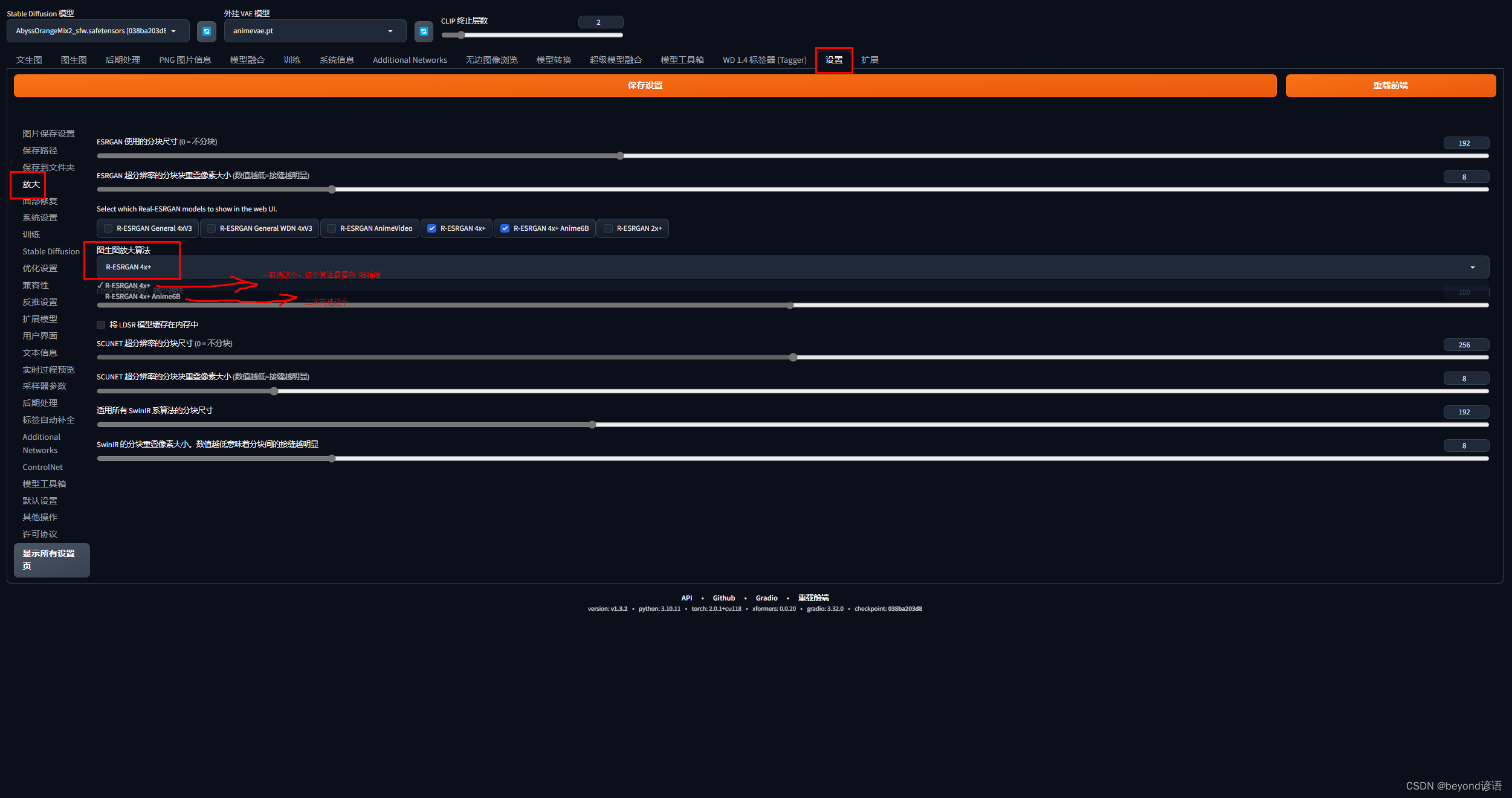
脚本选择SD upscale,分块重叠像素宽度越大效果越好,当然需要在原始照片基础上进行加上该值
放大算法还是像上述一样无脑选择R-ESRGAN 4x+ 该算法最复杂,若是二次元就选择R-ESRGAN 4x+ Anime6B,当然各种算法还是都有所差异的,需要尝试选择最符合自己喜欢的即可
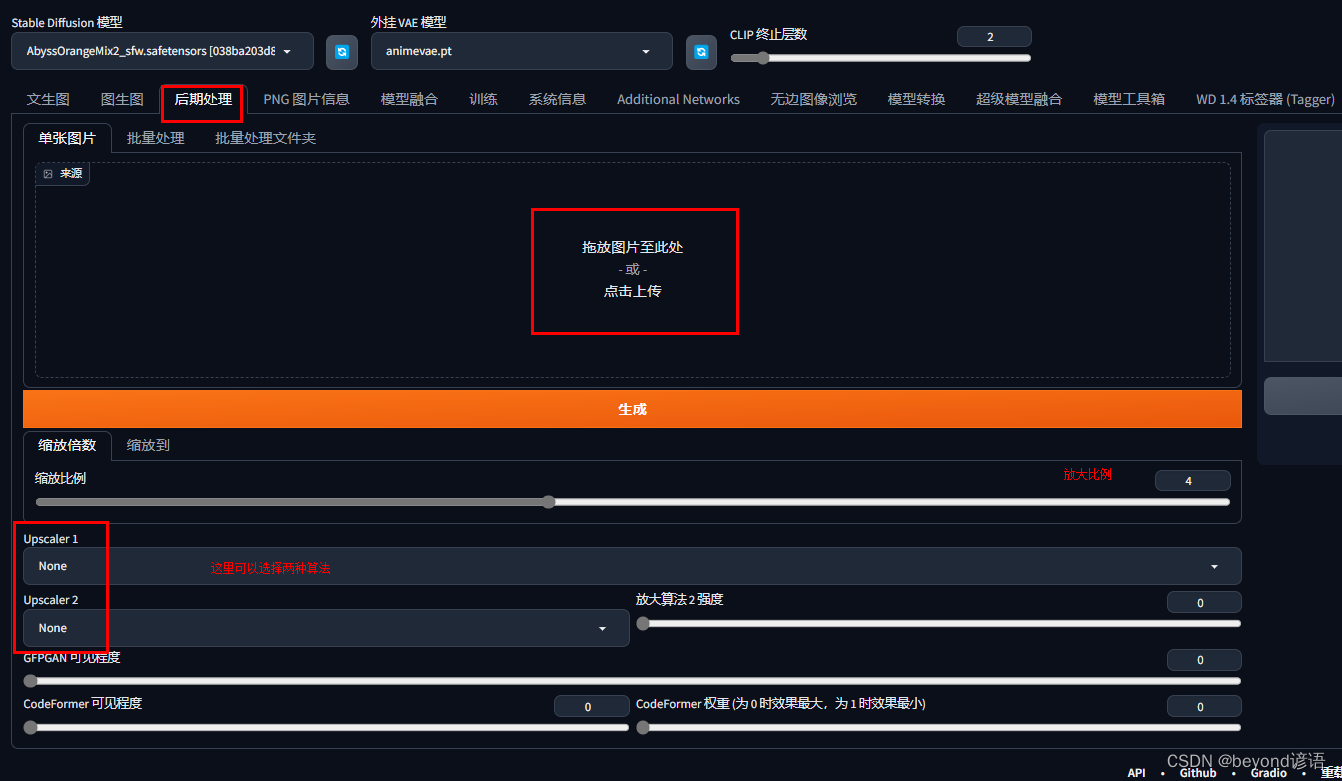
3,后期处理附加功能
速度快,但是效果相比于前两种方法而言比较差
这里可以选择两种不同的算法进行放大
九、经典模型介绍
1,Embeddings文本嵌入模型,又称Textual Inversion
Embeddings文件很小,一般几十KB大小
Checkpoint相当于大字典,Embeddings就相当于小书签
Embeddings不包含信息,只是一个标记而已,例如:绘制一个人鱼,人知道,鱼也知道,然后拼接人鱼就知道大概是啥了
Embeddings文件后缀一般为.pt
2,LoRa(Low-Rank Adaptation Models)低秩适应模型
3,Hypernetwork超网络模型
十、局部重绘
学习来源:
B站@秋葉aaaki@Nenly同学
本人只是在此基础上进行整合汇总而已