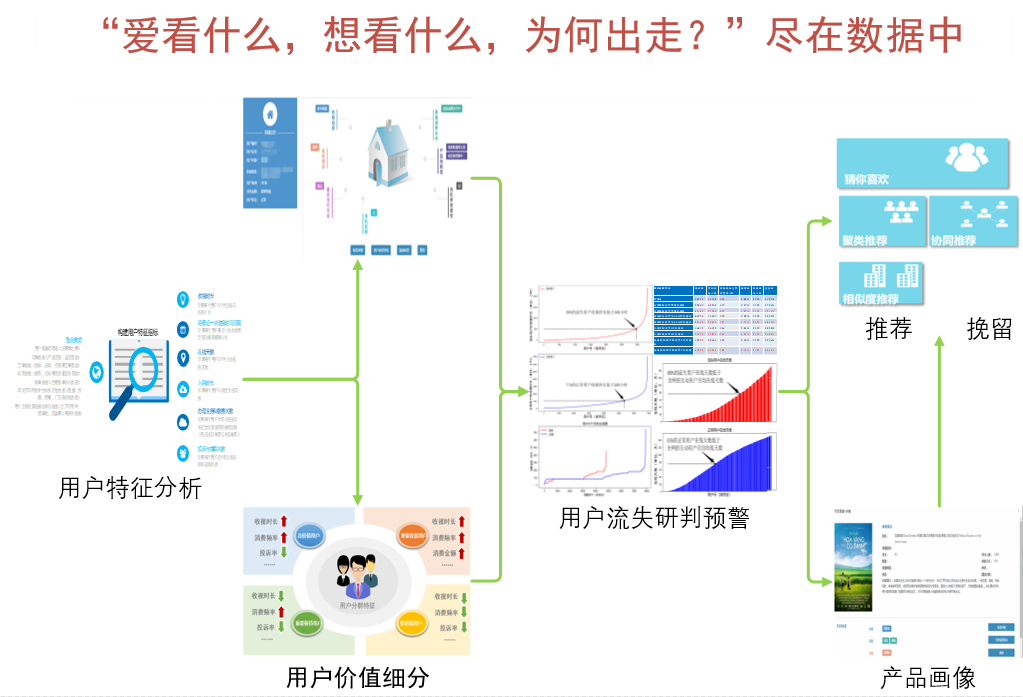
一、概述
1.为什么图形数据库?
生活在一个互联的世界中,大多数领域需要处理丰富的连接集以了解真正发生的事情。通常,我们发现项目之间的联系与项目本身一样重要。
虽然现有的关系数据库可以存储这些关系,但它们通过昂贵的JOIN操作或交叉查找来导航它们,通常与严格的模式相关联。事实证明,“关系”数据库处理关系的能力很差。在图形数据库中,没有 JOIN 或查找。关系以更灵活的格式与数据元素(节点)一起本地存储。系统的一切都针对快速遍历数据进行了优化;每个核心每秒数百万个连接。
图形数据库存储节点和关系而不是表或文档。数据的存储就像您在白板上勾画想法一样。您的数据的存储不会将其限制在预定义的模型中,从而允许以非常灵活的方式思考和使用它。
图数据库是以图结构的形式存储数据的数据库。 它以节点,关系和属性的形式存储应用程序的数据。 正如RDBMS以表的“行,列”的形式存储数据,GDBMS以图的形式存储数据。
图形数据库数据模型的主要构建块是:
-
节点
-
关系
-
属性

节点是图中的实体。
-
节点可以用labels 标记,代表它们在您的域中的不同角色。(例如,
Person)。 -
节点可以包含任意数量的键值对或 属性。(例如,
name) -
节点标签还可以将元数据(例如索引或约束信息)附加到某些节点。
关系在两个节点实体(例如,Person -> LOVES -> Person)之间提供定向的、命名的连接。
-
关系总是有方向、类型、开始节点和结束节点,并且它们可以有属性,就像节点一样。
-
在不牺牲性能的情况下,节点可以具有任意数量或类型的关系。
-
尽管关系总是定向的,但它们可以在任何方向上有效地导航。
对比其他数据库
关系型数据库对比
| 关系型数据库(RDBMS) | 图数据库 |
|---|---|
| 表 | 图 |
| 行 | 节点 |
| 列和数据 | 属性和数据 |
| 约束 | 关系 |
Nosql型数据库对比
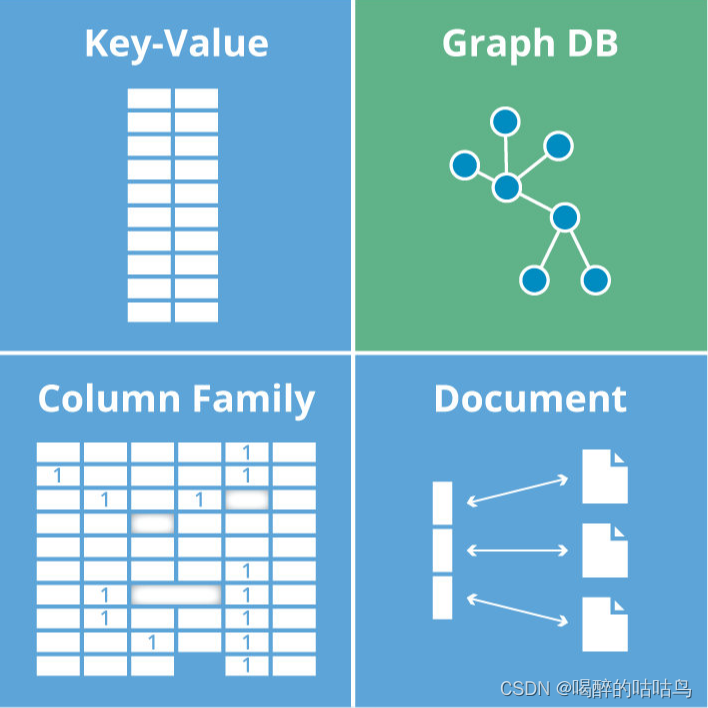
| 分类 | 数据模型 | 优势 | 劣势 | 举例 |
|---|---|---|---|---|
| 键值数据库 | 哈希表 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 | Redis |
| 列存储数据库 | 列式数据存储 | 查找速度快;支持分布横向扩展;数据压缩率高 | 功能相对受限 | HBase |
| 文档型数据库 | 键值对扩展 | 数据结构要求不严格;表结构可变;不需要预先定义表结构 | 查询性能不高,缺乏统一的查询语法 | MongoDB |
| 图数据库 | 节点和关系组成的图 | 利用图结构相关算法(最短路径、节点度关系查找等) | 可能需要对整个图做计算,不利于图数据分布存储 | Neo4j、JanusGraph |
2.什么是Neo4j?
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
- 是世界上最先进的图数据库之一 ,提供原生的图数据存储,检索和处理
- 采用属性图模型(Property graph model),极大的完善和丰富图数据模型
- 专属查询语言Cypher,直观、高效
Neo4j的特性:
- SQL就像简单的查询语言Neo4j CQL
- 它遵循属性图数据模型
- 它通过使用Apache Lucence支持索引
- 它支持UNIQUE约束
- 它包含一个用于执行CQL命令的UI:Neo4j数据浏览器
- 它支持完整的ACID(原子性,一致性,隔离性和持久性)规则
- 它采用原生图形库与本地GPE(图形处理引擎)
- 它支持查询的数据导出到SON和XLS格式
- 它提供了REST API,可以被任何编程语言(如ava, Spring, Scala等)访问
- 它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本
- 它支持两种ava API:Cypher API和Native Java API来开发Java应用程序
Neo4j的优点:
- 它很容易表示连接的数据
- 检索/遍历/导航更多的连接数据是非常容易和快速的
- 它非常容易地表示半结构化数据
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
- 使用简单而强大的数据模型
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引
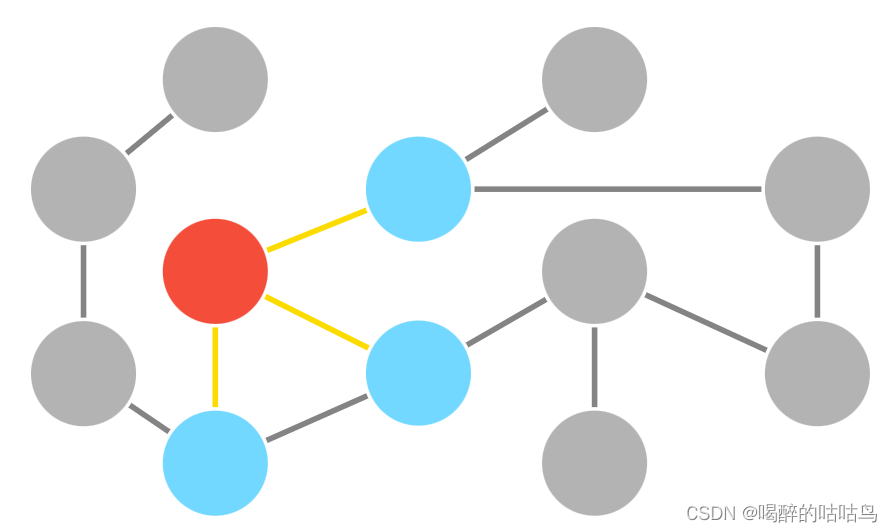
3.图形理论基础
图是一组节点和连接这些节点的关系。图形数据存储在节点和关系在属性的形式。属性是键值对表示数据。
图形是一组节点和连接这些节点的关系。 图形以属性的形式将数据存储在节点和关系中。 属性是用于表示数据的键值对。
在图形理论中,我们可以表示一个带有圆的节点,节点之间的关系用一个箭头标记表示。

节点和属性
节点和关系

复杂的节点关系

4.Neo4j数据模型
Neo4j图数据库主要有以下组成元素:
- 节点
- 属性
- 关系
- 标签
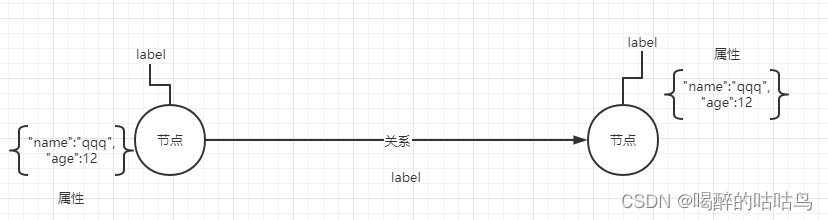
节点
节点(Node)是图数据库中的一个基本元素,来表示一个实体,在Neo4j中节点可以包含多个属性(Property)和多个标签(Label)。
- 节点通过关系连接到其他节点
- 节点可以具有一个或多个属性(即,存储为键/值对的属性)
- 节点有一个或多个标签,用于描述其在图表中的作用
属性
属性(Property)是用于描述图节点和关系的键值对
- 属性是命名值,其中名称(或键)是字符串
- 属性可以被索引和约束
- 可以从多个属性创建复合索引
关系
节点与节点连接起来构成图。关系也称为图论的边,其始端和末端都必须是节点,关系必须指向与节点,不能指向到空,开始与结束必须有节点。
关系和节点一样可以包含多个属性,但关系只能有一个类型(Type)。
- 关系连接两个节点
- 关系是方向性的
- 节点可以有多个甚至递归的关系
- 关系可以有一个或多个属性(即存储为键/值对的属性)
基于方向性,Neo4j关系被分为两种主要类型:
- 单向关系
- 双向关系
标签
标签(Label)用于描述节点和关系的补充属性,节点或关系可以包含一个或多个标签。
- 标签用于将节点分组
- 一个节点可以具有多个标签
- 对标签进行索引以加速在图中查找节点
5.使用场景









...............
二、安装
# 进入opt目录
cd opt
# 在opt目录下创建neo4j目录
mkdir neo4j
cd neo4j
# 在neo4j目录下创建data、logs、conf、import目录
mkdir data logs conf import
# 授权目录logs、data,次数如果不授权,启动容器后会报错
chmod 777 logs
chmod 777 data
# 查看neo4j镜像
docker search neo4j
# 拉取镜像
docker pull neo4j
# 启动neo4j容器
docker run -d --name neo4j --restart=always \
-p 7474:7474 -p 7687:7687 \
-v /opt/neo4j/data:/data \
-v /opt/neo4j/logs:/logs \
-v /opt/neo4j/conf:/var/lib/neo4j/conf \
-v /opt/neo4j/import:/var/lib/neo4j/import \
--env NEO4J_AUTH=neo4j/123456 neo4j# 查看启动日志
docker logs -f neo4j
# 进入配置文件目录
cd /opt/neo4j/conf
vim neo4j.conf# neo4j.conf配置内容如下
dbms.tx_log.rotation.retention_policy=100M sizedbms.memory.pagecache.size=512M
dbms.default_listen_address=0.0.0.0
dbms.connector.bolt.listen_address=0.0.0.0:7687
dbms.connector.http.listen_address=0.0.0.0:7474
dbms.directories.logs=/logs# 配置完后重启容器生效
docker restart neo4j

三、Neo4j 命令操作
Cypher语言是为处理图形数据而构建的,CQL代表Cypher查询语言。 像Mysql数据库具有查询语言SQL, Neo4j具有CQL作为查询语言。
- 它是Neo4j图形数据库的查询语言
- 它是一种声明性模式匹配语言
- 它遵循SQL语法。
- 它的语法是非常简单且人性化、可读的格式
| CQL命令 | 用法 |
|---|---|
| CREATE | 创建节点,关系和属性 |
| MATCH | 检索有关节点,关系和属性数据 |
| RETURN | 返回查询结果 |
| WHERE | 提供条件过滤检索数据 |
| DELETE | 删除节点和关系 |
| REMOVE | 删除节点和关系的属性 |
| ORDER BY | 排序检索数据 |
| SET | 添加或更新标签 |
| CQL数据类型 | |
|---|---|
| boolean | 用于表示布尔文字:true,false。 |
| byte | 用于表示8位整数。 |
| short | 用于表示16位整数。 |
| int | 用于表示32位整数。 |
| long | 用于表示64位整数。 |
| float | I用于表示32位浮点数。 |
| double | 用于表示64位浮点数。 |
| char | 用于表示16位字符。 |
| String | 用于表示字符串。 |
CQL描述实体之间的标签、属性、关系信息。如:

(a) <- [:knows] - (c) -[:knows] -> (b) -[:knows] -> (a)
1、基本命令
文档地址:Introduction - Neo4j Cypher Manual
CREATE创建
创建节点
CREATE (<node-name>:<label-name>)
语法说明
| 语法元素 | 描述 |
|---|---|
| CREATE | 它是一个Neo4j CQL命令。 |
| <node-name> | 它是我们要创建的节点名称。 |
| <label-name> | 它是一个节点标签名称 |
创建具有属性的节点
CREATE (
<node-name>:<label-name>
{
<Property1-name>:<Property1-Value>
........
<Propertyn-name>:<Propertyn-Value>
}
)
语法说明:
| 语法元素 | 描述 |
|---|---|
| <node-name> | 它是我们将要创建的节点名称。 |
| <label-name> | 它是一个节点标签名称 |
| <Property1-name>...<Propertyn-name> | 属性是键值对。 定义将分配给创建节点的属性的名称 |
| <Property1-value>...<Propertyn-value> | 属性是键值对。 定义将分配给创建节点的属性的值 |
创建关系
Neo4j图数据库遵循属性图模型来存储和管理其数据。
根据属性图模型,关系应该是定向的。否则, Neo4j将抛出一个错误消息。
基于方向性,Ne04j关系被分为两种主要类型。
- 单向关系
- 双向关系
新节点无属性关系
CREATE
(<node1-label-name>:<node1-name>)-
[<relationship-label-name>:<relationship-name>]->
(<node1-label-name>:<node1-name>)
RETURN <relationship-label-name>
语法说明:
| 语法元素 | 描述 |
|---|---|
| CREATE,RETURN | 他们是Neo4J CQL关键字。 |
| <node1-name> | 它用于创建关系的“From Node”的名称。 |
| <node1-label-name> | 它用于创建关系的“From Node”的标签名称。 |
| <node2-name> | 它用于创建关系的“To Node”的名称。 |
| <node2-label-name> | 它用于创建关系的“To Node”的标签名称。 |
| <relationship-name> | 这是一个关系的名称。 |
| <relationship-label-name> | 它是一个关系的标签名称。 |
注意 -
在此语法中,RETURN子句是可选的。
新节点与属性的关系
CREATE
(<node1-label-name>:<node1-name>{<define-properties-list>})-
[<relationship-label-name>:<relationship-name>{<define-properties-list>}]
->(<node1-label-name>:<node1-name>{<define-properties-list>})
RETURN <relationship-label-name>
<define-properties-list>语法
{
<property1-name>:<property1-value>,
<property2-name>:<property2-value>,
...
<propertyn-name>:<propertyn-value>
}
语法说明:
| 语法元素 | 描述 |
|---|---|
| CREATE,RETURN | 他们是Neo4J CQL关键字。 |
| <node1-name> | 它用于创建关系的“From Node”的名称。 |
| <node1-label-name> | 它用于创建关系的“From Node”的标签名称。 |
| <node2-name> | 它用于创建关系的“To Node”的名称。 |
| <node2-label-name> | 它用于创建关系的“To Node”的标签名称。 |
| <relationship-name> | 这是一个关系的名称。 |
| <relationship-label-name> | 它是一个关系的标签名称。 |
注意 -
在此语法中,RETURN子句是可选的。
CREATE (v1:TXVIDEO{title:"a",updated_by:"123",uploaded_date:"2022-12-09"})
-[movie:ACTION_MOVIES{rating:1}]->
(v2:TXVIDEO2{title:"b",updated_by:"456",uploaded_date:"2022-12-13"}) 使用已知节点创建带属性的关系
MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>)
CREATE
(<node1-label-name>)-[<relationship-label-name>:<relationship-name>
{<define-properties-list>}]->(<node2-label-name>)
RETURN <relationship-label-name>
语法说明:
| 语法元素 | 描述 |
|---|---|
| MATCH,CREATE,RETURN | 他们是Neo4J CQL关键词。 |
| <node1-name> | 它是用于创建关系的“From Node”的名称。 |
| <node1-label-name> | 它是用于创建关系的“From Node”的标签名称。 |
| <node2-name> | 它是用于创建关系的“To Node”的名称。 |
| <node2-label-name> | 它是用于创建关系的“To Node”的标签名称。 |
| <relationship-name> | 这是一个关系的名称。 |
| <relationship-label-name> | 它是一个关系的标签名称。 |
| <define-properties-list> | 它是分配给新创建关系的属性(名称 - 值对)的列表。 |
<define-properties-list>语法
{
<property1-name>:<property1-value>,
<property2-name>:<property2-value>,
...
<propertyn-name>:<propertyn-value>
}
| 语法元素 | 描述 |
|---|---|
| <propertyx-name> | 它是分配给新创建关系的属性的名称。 其中x是1,2,... n个值 |
| <propertyx-value> | 这是一个分配给新创建关系的Property的值。 其中x是1,2,... n个值 |
MATCH (c:Customer),(cc:CreditCard)
CREATE (c)-[r:DO_SHOPPING_WITH{price:55000}]->(cc)
RETURN r这里关系名称为“DO_SHOPPING_WITH” 关系标签为“r”。
shopdate和price是关系“r”的属性。
cust和Customer分别是客户节点的节点名称和节点标签名称。
cc和CreditCard分别是CreditCard节点的节点名和节点标签名。
没有属性的关系与现有节点
MATCH (<node1-label-name>:<nodel-name>),(<node2-label-name>:<node2-name>)
CREATE
(<node1-label-name>)-[<relationship-label-name>:<relationship-name>{<define-properties-list>}]->(<node2-label-name>)
RETURN <relationship-label-name>
语法说明:
| 语法元素 | 描述 |
|---|---|
| MATCH,CREATE,RETURN | 他们是Neo4J CQL关键字。 |
| <node1-name> | 它用于创建关系的“From Node”的名称。 |
| <node1-label-name> | 它用于创建关系的“From Node”的标签名称。 |
| <node2-name> | 它用于创建关系的“To Node”的名称。 |
| <node2-label-name> | 它用于创建关系的“To Node”的标签名称。 |
| <relationship-name> | 这是一个关系的名称。 |
| <relationship-label-name> | 它是一个关系的标签名称。 |
注意:
在此语法中,RETURN子句是可选的。
MATCH (e:Customer),(cc:CreditCard)
CREATE (e)-[r:DO_SHOPPING_WITH ]->(cc) 这里关系名称为“DO_SHOPPING_WITH”
关系标签为“r”。
e和Customer分别是客户节点的节点名称和节点标签名称。
cc和CreditCard分别是CreditCard节点的节点名和节点标签名。
创建标签
Label是Neo4j数据库中的节点或关系的名称或标识符。
单个标签到节点
CREATE (<node-name>:<label-name>)
多个标签到节点
CREATE (<node-name>:<label-name1>:<label-name2>.....:<label-namen>)
单个标签到关系
CREATE (<node1-name>:<label1-name>)-
[<relationship-name>:<relationship-label-name>]
->(<node2-name>:<label2-name>)
语法说明
| 语法元素 | 描述 |
|---|---|
| CREATE 创建 | 它是一个Neo4J CQL关键字。 |
| <node1-name> <节点1名> | 它是From节点的名称。 |
| <node2-name> <节点2名> | 它是To节点的名称。 |
| <label1-name> <LABEL1名称> | 它是From节点的标签名称 |
| <label2-name> <LABEL2名称> | 它是To节点的标签名称。 |
| <relationship-name> <关系名称> | 它是一个关系的名称。 |
| <relationship-label-name><相关标签名称> | 它是一个关系的标签名称。 |
CREATE (p1:Profile1)-[r1:LIKES]->(p2:Profile2)
这里p1和profile1是节点名称和节点标签名称“From Node”
p2和Profile2是“To Node”的节点名称和节点标签名称
r1是关系名称
LIKES是一个关系标签名称
MATCH查询
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某此属性
- 检索节点和关联关系的所有属性
MATCH (<node-name>:<label-name>)
| 语法元素 | 描述 |
|---|---|
| <node-name> | 这是我们要创建一个节点名称。 |
| <label-name> | 这是一个节点的标签名称 |
# 查询Dept下的内容
MATCH (dept:Dept) return dept
# 查询Employee标签下 id=123,name="Lokesh"的节点
MATCH (p:Employee {id:123,name:"Lokesh"}) RETURN p
## 查询Employee标签下name="Lokesh"的节点,使用(where命令)
MATCH (p:Employee)
WHERE p.name = "Lokesh"
RETURN pRETURN-返回
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
RETURN
<node-name>.<property1-name>,
........
<node-name>.<propertyn-name>
语法说明:
| 语法元素 | 描述 |
|---|---|
| <node-name> | 它是我们将要创建的节点名称。 |
| <Property1-name>...<Propertyn-name> | 属性是键值对。 <Property-name>定义要分配给创建节点的属性的名称 |
MATCH (dept: Dept)
RETURN dept.deptno,dept.dname,dept.locationWHERE子句
像SQL-样,Neo4j CQL在CQL MATCH命令中提供了WHERE子句来过滤MATCH查询的结果。
WHERE <condition>
WHERE <condition> <boolean-operator> <condition>
<condition>语法:
<property-name> <comparison-operator> <value>
语法说明:
| 语法元素 | 描述 |
|---|---|
| WHERE | 它是一个Neo4j CQL关键字。 |
| <property-name> <属性名称> | 它是节点或关系的属性名称。 |
| <comparison-operator> <比较运算符> | 它是Neo4j CQL比较运算符之一。 |
| <value> <值> | 它是一个字面值,如数字文字,字符串文字等。 |
布尔运算符
| 布尔运算符 | 描述 |
|---|---|
| AND | 它是一个支持AND操作的Neo4j CQL关键字。 |
| OR | 它是一个Neo4j CQL关键字来支持OR操作。 |
| NOT | 它是一个Neo4j CQL关键字支持NOT操作。 |
| XOR | 它是一个支持XOR操作的Neo4j CQL关键字。 |
比较运算符
| 布尔运算符 | 描述 |
|---|---|
| = | 它是Neo4j CQL“等于”运算符。 |
| <> | 它是一个Neo4j CQL“不等于”运算符。 |
| < | 它是一个Neo4j CQL“小于”运算符。 |
| > | 它是一个Neo4j CQL“大于”运算符。 |
| <= | 它是一个Neo4j CQL“小于或等于”运算符。 |
| >= | 它是一个Neo4j CQL“大于或等于”运算符。 |
MATCH (emp:Employee)
WHERE emp.name = 'Abc' OR emp.name = 'Xyz'
RETURN emp使用WHERE子句创建关系
MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>)
WHERE <condition>
CREATE (<node1-label-name>)-[<relationship-label-name>:<relationship-name>
{<relationship-properties>}]->(<node2-label-name>)
语法说明:
| 语法元素 | 描述 |
|---|---|
| MATCH,WHERE,CREATE | 他们是Neo4J CQL关键字。 |
| <node1-label-name> | 它是一个用于创建关系的节点一标签名称。 |
| <node1-name> | 它是一个用于创建关系的节点名称。 |
| <node2-label-name> | 它是一个用于创建关系的节点一标签名称。 |
| <node2-name> | 它是一个用于创建关系的节点名称。 |
| <condition> | 它是一个Neo4J CQL WHERE子句条件。 |
| <relationship-label-name> | 这是新创建的节点一和节点二之间的关系的标签名称。 |
| <relationship-name> | 这是新创建的节点1和节点2之间的关系的名称。 |
| <relationship-properties> | 这是一个新创建节点一和节点二之间关系的属性列表(键 - 值对)。 |
MATCH (cust:Customer),(cc:CreditCard)
WHERE cust.id = 11 AND cc.id= 23
CREATE (cust)-[r:DO_SHOPPING_WITH{price:55000}]->(cc)
RETURN rDELETE删除
Neo4j使用CQL DELETE子句
- 删除节点
- 删除节点及相关节点和关系。
删除节点(前提:节点不存在关系)
DELETE <node-name-list>
MATCH (e: Employee) DELETE e删除节点和关系
DELETE <node1-name>,<node2-name>,<relationship-name>
| 语法元素 | 描述 |
|---|---|
| DELETE | 它是一个Neo4j CQL关键字。 |
| <node1-name> | 它是用于创建关系<relationship-name>的一个结束节点名称。 |
| <node2-name> | 它是用于创建关系<relationship-name>的另一个节点名称。 |
| <relationship-name> | 它是一个关系名称,它在<node1-name>和<node2-name>之间创建。 |
MATCH (cc: CreditCard)-[rel]-(c:Customer)
DELETE cc,c,rel
REMOVE-删除
- 删除节点或关系的标签
- 删除节点或关系的属性
移除属性
REMOVE <property-name-list>
<property-name-list> <属性名称列表>语法
<node-name>.<property1-name>,
<node-name>.<property2-name>,
....
<node-name>.<propertyn-name>
CREATE (book:Book {id:122,title:"Neo4j Tutorial",pages:340,price:250})
MATCH (book : Book) RETURN book
MATCH (book { id:122 })
REMOVE book.price
RETURN book
移除标签
REMOVE <label-name-list>
<label-name-list>语法
<node-name>:<label2-name>,
....
<node-name>:<labeln-name>
新增一个节点,有多个标签
CREATE (n:Person:Director{born: 1222, name: "abci"})删除一个标签
MATCH (n:Person:Director{born: 1222, name: "abci"})
REMOVE n:Director
RETURN nSET子句
- 向现有节点或关系添加新属性
- 添加或更新属性值
SET <property-name-list>
<属性名称列表>语法:
<node-label-name>.<property1-name>,
<node-label-name>.<property2-name>,
....
<node-label-name>.<propertyn-name>
语法说明:
| 语法元素 | 描述 |
|---|---|
| <node-label-name> <节点标签名称> | 这是一个节点的标签名称。 |
| <property-name> <属性名称> | 它是一个节点的属性名。 |
MATCH (book:Book)
SET book.title = 'abc'
RETURN bookORDER BY排序
MATCH查询返回的结果进行升序或降序排序。默认情况下,它按升序对行进行排序。如果我们要按降序对它们进行排序, 我们需要使用DESC子句
ORDER BY <property-name-list> [DESC]
<property-name-list>语法:
<node-label-name>.<property1-name>,
<node-label-name>.<property2-name>,
....
<node-label-name>.<propertyn-name>
MATCH (emp:Employee)
RETURN emp.empid,emp.name,emp.salary,emp.deptno
ORDER BY emp.name DESCUNION合并
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
- UNION
- UNION ALL
UNION子句
它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
<MATCH Command1>
UNION
<MATCH Command2>
<MATCH Command1>
UNION ALL
<MATCH Command2>
MATCH (cc:CreditCard)
RETURN cc.id as id,cc.number as number,cc.name as name,
cc.valid_from as valid_from,cc.valid_to as valid_to
UNION
MATCH (dc:DebitCard)
RETURN dc.id as id,dc.number as number,dc.name as name,
dc.valid_from as valid_from,dc.valid_to as valid_toMATCH (cc:CreditCard)
RETURN cc.id as id,cc.number as number,cc.name as name,
cc.valid_from as valid_from,cc.valid_to as valid_to
UNION ALL
MATCH (dc:DebitCard)
RETURN dc.id as id,dc.number as number,dc.name as name,
dc.valid_from as valid_from,dc.valid_to as valid_toLIMIT和SKIP子句
过滤或限制查询返回的行数。LIMIT返回前几行,SKIP忽略前几行。
LIMIT <number>
SKIP <number>
前2行
MATCH (n)
RETURN n
LIMIT 2
忽略前2行
MATCH (n)
RETURN n SKIP 2
MERGE-合并
-
创建节点,关系和属性
-
为从数据库检索数据
MERGE命令是CREATE命令和MATCH命令的组合。
MERGE = CREATE + MATCH
如果存在,则返回结果,不存在,则创建新的节点/关系并返回结果。
MERGE (<node-name>:<label-name>
{
<Property1-name>:<Pro<rty1-Value>
.....
<Propertyn-name>:<Propertyn-Value>
})
语法说明:
| 语法元素 | 描述 |
|---|---|
| MERGE | 它是一个Neo4j CQL关键字。 |
| <node-name> | 它是节点或关系的名称。 |
| <label-name> | 它是节点或关系的标签名称。 |
| <property_name> | 它是节点或关系的属性名称。 |
| <property_value> | 它是节点或关系的属性值。 |
| : | 使用colon(:)运算符来分隔节点或关系的属性名称和值。 |
创建具有属性:Id,Name的Profile节点
MERGE (gp2:GoogleProfile2{ Id: 201402,Name:"Nokia"})
创建具有相同属性的同一个Profile节点:Id,Name。
MERGE (gp2:GoogleProfile2{ Id: 201402,Name:"Nokia"})
检索所有Profile节点详细信息并观察结果
MATCH (gp2:GoogleProfile2)
RETURN gp2.Id,gp2.Name
NULL值
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NUL属性值的新节点。
MATCH (e:Employee)
WHERE e.id IS NOT NULL
RETURN e.id,e.name,e.sal,e.deptnoIN操作符
与SQL一样,Neo4j CQL提供了一个IN运算符。 以便为CQL命令提供值的集合。
MATCH (n:Person)
WHERE n.name IN ["Carrie-Anne Moss", "Lilly Wachowski"]
RETURN n;
2、ID属性
在Neo4j中,“Id”是节点和关系的默认内部属性。 这意味着,当我们创建一个新的节点或关系时,Neo4j数据库服务器将为内部使用分配一个数字。 它会自动递增。相当于Mysql中的自动主键。
CREATE (tweet:Tweet{message:"Hello"})
MATCH (tweet:Tweet{message:"Hello"})
RETURN tweet
注意
- 节点的Id属性的最大值约为35亿。
- Id的最大值关系的属性的大约35亿。
索引
Neo4j SQL支持节点或关系属性上的索引,以提高应用程序的性能。
- Create Index 创建索引
- Drop Index 丢弃索引
创建索引
CREATE INDEX ON :<label_name> (<property_name>)
CREATE INDEX ON :Customer (name)丢弃索引
DROP INDEX ON :<label_name> (<property_name>)
DROP INDEX ON :Customer (name)UNIQUE约束
为了防止重复,设置唯一约束。
- 避免重复记录
- 强制执行数据完整性规则
CREATE CONSTRAINT ON (<label_name>)
ASSERT <property_name> IS UNIQUE
| 语法元素 | 描述 |
|---|---|
| CREATE CONSTRAINT ON | 它是一个Neo4j CQL关键字。 |
| <label_name> | 它是节点或关系的标签名称。 |
| ASSERT | 它是一个Neo4j CQL关键字。 |
| <property_name> | 它是节点或关系的属性名称。 |
| IS UNIQUE | 它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。 |
CREATE CONSTRAINT ON (cc:CreditCard) ASSERT cc.number IS UNIQUEDROP CONSTRAINT ON (<label_name>)
ASSERT <property_name> IS UNIQUE
| 语法元素 | 描述 |
|---|---|
| DROP CONSTRAINT ON | 它是一个Neo4j CQL关键字。 |
| <label_name> | 它是节点或关系的标签名称。 |
| ASSERT | 它是一个Neo4j CQL关键字。 |
| <property_name> | 它是节点或关系的属性名称。 |
| IS UNIQUE | 它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。 |
DROP CONSTRAINT ON (cc:CreditCard) ASSERT cc.number IS UNIQUEDISTINCT
像SQL中的distinct关键字,返回的是所有不同值。
MATCH (n:Person)
RETURN DISTINCT (n.name)
3、 常用函数
| 函数 | 用法 |
|---|---|
| String字符串 | 它们用于使用String字面量 |
| Aggregation聚合 | 它们用于对CQL查询结果执行一些聚合操作 |
| Relationship关系 | 他们用于获取关系的细节,如startnode, endnode等 |
字符串函数
| 功能 | 描述 |
|---|---|
| UPPER | 它用于将所有字母更改为大写字母 |
| LOWER | 它用于将所有字母改为小写字母 |
| SUBSTRING | 它用于获取给定String的子字符串 |
| REPLACE | 它用于替换一个字符串的子字符串 |
MATCH (e)
RETURN id(e), e.name, substring(e.name, 0, 2)
AGGREGATION-聚合
| 聚集功能 | 描述 |
|---|---|
| COUNT | 它返回由MATCH命令返回的行数 |
| MAX | 它从MATCH命令返回的一组行返回最大值 |
| MIN | 它返回由MATCH命令返回的一组行的最小值 |
| SUM | 它返回由MATCH命令返回的所有行的求和值 |
| AVG | 它返回由MATCH命令返回的所有行的平均值 |
MATCH (e:Employee) RETURN COUNT(*)
关系函数
| 功能 | 描述 |
|---|---|
| STARTNODE | 它用于知道关系的开始节点 |
| ENDNODE | 它用于知道关系的结束节点 |
| ID | 它用于知道关系的ID |
| TYPE | 它用于知道字符串表示中的一个关系的TYPE |
STARTNODE (<relationship-label-name>)
ENDNODE (<relationship-label-name>)
<relationship-label-name>可以是来自Neo4j数据库的节点或关系的属性名称。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN STARTNODE(movie)
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN ENDNODE(movie)ID和TYPE关系函数来检索关系的Id和类型详细信息。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN ID(movie),TYPE(movie)shortestPath 查询最短路径
应用理论:6层关系理论:任何两个事物之间的关系都不会超过6层 查询最短路径的必要性 allShortestPaths [*..n] 用于表示获取n层关系
match p = shortestpath((:hero{name:"孙尚香"})-[*..3]-(:hero{name:"武则天"})) return p
match p = allshortpath((:hero{name:"孙尚香"})-[*..3]-(:hero{name:"武则天"})) return p正则
(n)-->(m)
Relationship from n to m.
(n)-[*1..5]->(m)
Variable length path of between 1 and 5 relationships
from n to m.collect
查询如下3个表的全部内容:哪些公司卖哪些货?
MATCH (s:Supplier)-->(:Product)-->(c:Category)
RETURN s.companyName as Company, collect(distinct c.categoryName) as Categoriescollect(distinct c.categoryName) 单独对c.categoryName去重
4、数据库备份
docker neo4j备份与加载
5.导出与导入
1.数据库导出
neo4j-admin dump --database=<database> --to=<XX/XXX/XX.db.dump>
2.数据库导入
neo4j-admin load --from=<XX/XXX/XX.db.dump> --database=<database> [--force]
四、使用
一、原生API
<!-- 嵌入式模式 -->
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j</artifactId>
<version>3.5.5</version>
</dependency>
<!-- 服务器模式-->
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-ogm-bolt-driver</artifactId>
<version>3.2.14</version>
</dependency>package com.lean.neo4j.test;
import org.apache.commons.collections4.MapUtils;
import org.apache.commons.lang3.time.StopWatch;
import org.neo4j.driver.v1.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
// Neo4j Server(服务器模式)
//嵌入式模式
public class Neo4jServerMain {
private static final Integer DATA_SIZE = 10000;
public static void main(String[] args) {
// inertNeo4j();
queryData();
}
/**
* 查询
*/
public static void queryData(){
Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "123456"));
Session session = driver.session();
String cql = "MATCH p=shortestPath((n:backPerson {userName:$startName})-[*]-(n2:backPerson {userName:$endName} )) RETURN p";
// String cql = "MATCH (n1:backPerson)-[r]->(n2:backPerson) RETURN r, n1, n2 LIMIT 25";
StatementResult result = session.run(cql, Values.parameters("startName", "user1939", "endName", "user1921"));
// StatementResult result = session.run(cql);
while (result.hasNext()) {
Record record = result.next();
System.out.println(record.toString());
}
session.close();
driver.close();
}
/**
* 测试手动插入数据以及维护关系
*/
private static void inertNeo4j() {
// 构造数据, 数据和pg 库里面的数据一样
List<Map<String, Object>> datas = generateData();
Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "123456"));
Session session = driver.session();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 手动create to neo4j
String createCQLTemplate = "create (n:backPerson {cardNum: '$cardNum', userName: '$userName', transferCardNum: '$transferCardNum', transferAmount: '$transferAmount'})";
datas.forEach(data -> {
String createCQL = createCQLTemplate.replace("$cardNum", MapUtils.getString(data, "cardNum"))
.replace("$userName", MapUtils.getString(data, "userName"))
.replace("$transferCardNum", MapUtils.getString(data, "transferCardNum"))
.replace("$transferAmount", MapUtils.getString(data, "transferAmount"));
session.run(createCQL);
});
System.out.println("插入成功耗时: " + stopWatch.getTime() + " ms");
// 手动维护关系
String mergeCQLTemplate = "match (a:backPerson{cardNum: '$cardNum1'}), (b:backPerson{cardNum: '$cardNum2'}) MERGE(a)-[:TRANSFER{transferAmount: '$transferAmount'}]->(b)";
datas.forEach(data -> {
String mergeCQL = mergeCQLTemplate.replace("$cardNum1", MapUtils.getString(data, "cardNum"))
.replace("$cardNum2", MapUtils.getString(data, "transferCardNum"))
.replace("$transferAmount", MapUtils.getString(data, "transferAmount"));
session.run(mergeCQL);
});
stopWatch.stop();
System.out.println("转换关系成功,耗时: " + stopWatch.getTime() + " ms");
// close resource
session.close();
driver.close();
}
private static List<Map<String, Object>> generateData() {
List<Map<String, Object>> datas = new ArrayList<>(DATA_SIZE);
Map<String, Object> tmpMap = null;
for (int i = 0; i < DATA_SIZE; i++) {
tmpMap = new HashMap<>();
datas.add(tmpMap);
tmpMap.put("cardNum", i);
tmpMap.put("userName", "user" + i);
tmpMap.put("transferCardNum", (i + 1) % 10000);
tmpMap.put("transferAmount", i);
}
return datas;
}
}
二、SpringBoot整合Neo4j
文档地址:Spring Data Neo4j
springboot 2.7 Neo4j
pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
添加配置
spring:
neo4j:
uri: bolt://localhost:7687
authentication:
username: neo4j
password: 123456
#database: yourDatabase注解
@Node:应用于类级别以指示此类是映射到数据库的候选者。
@Id:应用于字段级别以标记用于标识目的的字段。
@GeneratedValue:在字段级别应用,@Id以指定应如何生成唯一标识符。
@Property:应用于字段级别以修改从属性到特性的映射。
@CompositeProperty:在字段级别应用于应作为复合读回的 Map 类型的属性。请参阅复合属性。
@Relationship:应用于字段级别以指定关系的详细信息。
@DynamicLabels:应用于字段级别以指定动态标签的来源。
@RelationshipProperties:应用于类级别以指示此类作为关系属性的目标。
@TargetNode: 应用在注解为 的类的某个字段上@RelationshipProperties,从另一端的角度来标记该关系的目标。
package com.lean.neo4j.entity;
import lombok.Data;
import org.springframework.data.annotation.Version;
import org.springframework.data.neo4j.core.schema.*;
import org.springframework.data.neo4j.core.support.UUIDStringGenerator;
import java.util.ArrayList;
import java.util.List;
@Data
@Node("Movie")
public class Movie {
@Id
@GeneratedValue
// @GeneratedValue(UUIDStringGenerator.class)
private Long id;
//支持乐观锁定
//判断这个实体是新的还是之前已经持久化过。
//@Version
private String title;
//映射属性
@Property("tagline")
private String description;
//INCOMING 指向自己
//OUTGOING 指向别人
//动态关系 指向自己
@Relationship(type = "ACTED_IN", direction = Relationship.Direction.INCOMING)
private List<Roles> actorsAndRoles = new ArrayList<>();
//关系 指向别人
@Relationship(type = "DIRECTED", direction = Relationship.Direction.INCOMING)
private List<Person> directors = new ArrayList<>();
public Movie(String title, String description) {
this.title = title;
this.description = description;
}
}
package com.lean.neo4j.entity;
import lombok.Data;
import org.springframework.data.neo4j.core.schema.GeneratedValue;
import org.springframework.data.neo4j.core.schema.Id;
import org.springframework.data.neo4j.core.schema.Node;
@Data
@Node("Person")
public class Person {
@Id
@GeneratedValue
// @GeneratedValue(value = MyIdGenerator2.class)
// @GeneratedValue(generatorRef = "myIdGenerator")
private Long id;
private String name;
private Integer born;
public Person(Integer born, String name) {
this.born = born;
this.name = name;
}
public Integer getBorn() {
return born;
}
public String getName() {
return name;
}
}
package com.lean.neo4j.entity;
import lombok.Data;
import org.springframework.data.neo4j.core.schema.RelationshipId;
import org.springframework.data.neo4j.core.schema.RelationshipProperties;
import org.springframework.data.neo4j.core.schema.TargetNode;
import java.util.List;
@Data
@RelationshipProperties
public class Roles {
@RelationshipId
private Long id;
private final List<String> roles;
@TargetNode
private Person person;
public Roles(Person person, List<String> roles) {
this.person = person;
this.roles = roles;
}
public List<String> getRoles() {
return roles;
}
}
package com.lean.neo4j.entity;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.data.neo4j.core.schema.IdGenerator;
import org.springframework.stereotype.Component;
/**
* Neo4jClient based ID generator
*/
@Component
class MyIdGenerator implements IdGenerator<String> {
private final Neo4jClient neo4jClient;
public MyIdGenerator(Neo4jClient neo4jClient) {
this.neo4jClient = neo4jClient;
}
@Override
public String generateId(String primaryLabel, Object entity) {
return neo4jClient.query("YOUR CYPHER QUERY FOR THE NEXT ID")
.fetchAs(String.class).one().get();
}
}
package com.lean.neo4j.entity;
import org.springframework.data.neo4j.core.schema.IdGenerator;
import org.springframework.util.StringUtils;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 自定义自增主键
*/
public class MyIdGenerator2 implements IdGenerator<String> {
private final AtomicInteger sequence = new AtomicInteger(0);
@Override
public String generateId(String primaryLabel, Object entity) {
return StringUtils.uncapitalize(primaryLabel) +
"-" + sequence.incrementAndGet();
}
}
package com.lean.neo4j.entity;
import org.springframework.data.neo4j.core.schema.GeneratedValue;
import org.springframework.data.neo4j.core.schema.Id;
import org.springframework.data.neo4j.core.schema.Node;
@Node
public class SystemEntity {
@Id
@GeneratedValue
private Long id;
private String name;
public SystemEntity() {
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
1.Neo4jTemplate 操作
@Autowired
private Neo4jTemplate neo4jTemplate;
@Test
void TestNoRepository() {
// 删除所有节点和关系(删除节点会响应删除关联关系),避免后续创建节点重复影响
neo4jTemplate.deleteAll(Movie.class);
neo4jTemplate.deleteAll(Person.class);
// 创建节点
Movie movie = new Movie("流浪地球", "是由中国电影股份有限公司、北京京西文化旅游股份有限公司、郭帆文化传媒(北京)有限公司、北京登峰国际文化传播有限公司联合出品,由郭帆执导,吴京特别出演、屈楚萧、赵今麦、李光洁、吴孟达等领衔主演的科幻冒险电影");
// 添加关系
movie.getActorsAndRoles().add(new Roles(new Person(1994, "刘启"), Collections.singletonList("初级驾驶员")));
movie.getActorsAndRoles().add(new Roles(new Person(2002, "刘培强"), Collections.singletonList("中国航天员")));
movie.getActorsAndRoles().add(new Roles(new Person(1952, "韩子昂"), Collections.singletonList("高级驾驶员")));
movie.getActorsAndRoles().add(new Roles(new Person(2002, "韩朵朵"), Collections.singletonList("初中生")));
movie.getActorsAndRoles().add(new Roles(new Person(1981, "王磊"), Collections.singletonList("救援队队长")));
movie.getActorsAndRoles().add(new Roles(new Person(1991, "李一一"), Collections.singletonList("技术观察员")));
movie.getActorsAndRoles().add(new Roles(new Person(1974, "何连科"), Collections.singletonList("救援队队员")));
movie.getActorsAndRoles().add(new Roles(new Person(1991, "Tim"), Collections.singletonList("中美混血儿")));
movie.getDirectors().add(new Person(1974, "吴京"));
// 存入图数据库持久化
neo4jTemplate.save(movie);
// 查询 操作 两种方式
// 1.手写cypherQuery toExecutableQuery
// 2.调用neo4jTemplate提供的方法.
List<Person> personList = neo4jTemplate.findAll(Person.class);
System.out.println(personList);
Map<String, Object> map = new HashMap<>();
map.put("usedName", "王磊");
QueryFragmentsAndParameters parameters = new QueryFragmentsAndParameters("MATCH (n:Person) where n.name = $usedName return n",map);
Person person = neo4jTemplate.toExecutableQuery(Person.class, parameters).getSingleResult().get();
System.out.println(person);
// 3. 通过属性关系查询节点
map = new HashMap<>();
map.put("roles",Collections.singletonList("救援队队员"));
// 方法1.使用toExecutableQuery查询
parameters = new QueryFragmentsAndParameters("MATCH (n:Person) -[relation:ACTED_IN]-> (m:Movie) WHERE relation.roles = $roles RETURN n",map);
Optional<Person> role = neo4jTemplate.toExecutableQuery(Person.class, parameters).getSingleResult();
System.out.println(role);
// 方法2.使用findOne查询
role = neo4jTemplate.findOne("MATCH (person:Person) -[relation:ACTED_IN]-> (movie:Movie) WHERE relation.roles = $roles RETURN person",map,Person.class);
System.out.println(role);
Long userId = person.getId();
// 更新
person.setName("王磊2");
neo4jTemplate.save(person);
Optional<Person> person2 = neo4jTemplate.findById(userId, Person.class);
System.out.println(person2);
}
2.继承Neo4jRepository
@Repository
public interface MovieRepository extends Neo4jRepository<Movie, Long> {
//@Query("MATCH (n:Movie) WHERE id = $0 RETURN n")
Movie findMovieById(Long id);
Movie findMovieByTitle(String title);
}
import com.lean.neo4j.entity.Person;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface PersonRepository extends Neo4jRepository<Person, Long> {
Person findPersonEntityByName(String name);
}
package com.lean.neo4j.mapper;
import com.lean.neo4j.entity.SystemEntity;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.stereotype.Repository;
@Repository
public interface SystemRepository extends Neo4jRepository<SystemEntity, Long> {
@Query("MATCH (a),(b) WHERE id(a)=$from and id(b)=$to MERGE (a)-[:invoke]->(b)")
void addInvokeRelation(@Param("from") Long from, @Param("to") Long to);
@Query("MATCH (a),(b) WHERE id(a)=$from and id(b)=$to MERGE (a)-[:consume]->(b)")
void addConsumeRelation(@Param("from") Long from, @Param("to") Long to);
@Query("MATCH (a),(b) WHERE id(a)=$from and id(b)=$to MERGE (a)-[:produce]->(b)")
void addProduceRelation(@Param("from") Long from, @Param("to") Long to);
@Query("MATCH (n:SystemEntity) where id=$id RETURN n")
SystemEntity findSystemById(@Param("id") Long id);
//等价写法@Query("MATCH (n:SystemEntity {name: $name}) RETURN n")
@Query("MATCH (n:SystemEntity) where n.name=$name RETURN n")
SystemEntity findSystemByName(@Param("name") String name);
@Query("MATCH (a:SystemEntity{id:$from})-[r:invoke]-(b:SystemEntity{id:$to}) DELETE r")
void deleteConsumeRelation(@Param("from") Long from, @Param("to") Long to);
}
@Autowired
private MovieRepository movieRepository;
@Autowired
private PersonRepository personRepository;
/**
* 使用repository操作图数据
*/
@Test
void testByRepository() {
// 删除所有节点和关系(删除节点会响应删除关联关系),避免后续创建节点重复影响
movieRepository.deleteAll();
personRepository.deleteAll();
// 创建节点
Movie movie = new Movie("流浪地球", "是由中国电影股份有限公司、北京京西文化旅游股份有限公司、郭帆文化传媒(北京)有限公司、北京登峰国际文化传播有限公司联合出品,由郭帆执导,吴京特别出演、屈楚萧、赵今麦、李光洁、吴孟达等领衔主演的科幻冒险电影");
// 添加关系
movie.getActorsAndRoles().add(new Roles(new Person(1994, "刘启"), Collections.singletonList("初级驾驶员")));
movie.getActorsAndRoles().add(new Roles(new Person(2002, "刘培强"), Collections.singletonList("中国航天员")));
movie.getActorsAndRoles().add(new Roles(new Person(1952, "韩子昂"), Collections.singletonList("高级驾驶员")));
movie.getActorsAndRoles().add(new Roles(new Person(2002, "韩朵朵"), Collections.singletonList("初中生")));
movie.getActorsAndRoles().add(new Roles(new Person(1981, "王磊"), Collections.singletonList("救援队队长")));
movie.getActorsAndRoles().add(new Roles(new Person(1991, "李一一"), Collections.singletonList("技术观察员")));
movie.getActorsAndRoles().add(new Roles(new Person(1974, "何连科"), Collections.singletonList("救援队队员")));
movie.getActorsAndRoles().add(new Roles(new Person(1991, "Tim"), Collections.singletonList("中美混血儿")));
movie.getDirectors().add(new Person(1974, "吴京"));
// 存入图数据库持久化
neo4jTemplate.save(movie);
// 查询
Person person = personRepository.findPersonEntityByName("刘启");
System.out.println(JSON.toJSONString(person));
Movie movie1 = movieRepository.findMovieByTitle("流浪地球");
System.out.println(JSON.toJSONString(movie1));
Movie movie2 = movieRepository.findMovieById(movie.getId());
System.out.println(JSON.toJSONString(movie2));
// 注意:repository的save方法【对应的实体若id一致】则为修改,否则为新建。
person.setBorn(1997);
personRepository.save(person);
person = personRepository.findPersonEntityByName("刘启");
System.out.println(person);
}
@Autowired
private SystemRepository systemRepository;
@Test
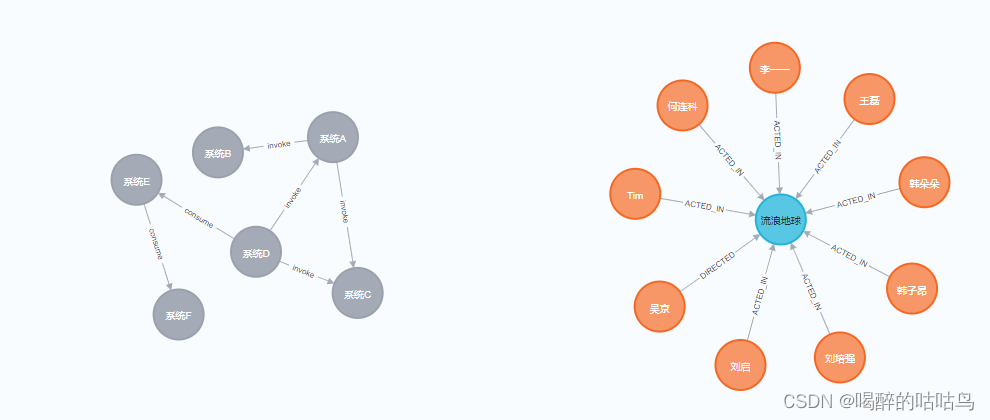
public void addSystemNode() {
systemRepository.deleteAll();
SystemEntity systemEntity = new SystemEntity();
systemEntity.setName("系统A"); // 45
systemRepository.save(systemEntity);
System.out.println("系统A" + "----------" + systemEntity.getId());
SystemEntity systemEntity1 = new SystemEntity();
systemEntity1.setName("系统B");// 46
systemRepository.save(systemEntity1);
System.out.println("系统B" + "----------" + systemEntity1.getId());
SystemEntity systemEntity2 = new SystemEntity();
systemEntity2.setName("系统C");// 47
systemRepository.save(systemEntity2);
System.out.println("系统C" + "----------" + systemEntity2.getId());
SystemEntity systemEntity3 = new SystemEntity();
systemEntity3.setName("系统D");// 48
systemRepository.save(systemEntity3);
System.out.println("系统D" + "----------" + systemEntity3.getId());
SystemEntity systemEntity4 = new SystemEntity();
systemEntity4.setName("系统E");// 49
systemRepository.save(systemEntity4);
System.out.println("系统E" + "----------" + systemEntity4.getId());
SystemEntity systemEntity5 = new SystemEntity();
systemEntity5.setName("系统F");// 50
systemRepository.save(systemEntity5);
System.out.println("系统F" + "----------" + systemEntity5.getId());
}
@Test
public void addInvokeRelation() {
systemRepository.addInvokeRelation(45L, 46L);
systemRepository.addInvokeRelation(45L, 47L);
systemRepository.addInvokeRelation(48L, 45L);
systemRepository.addInvokeRelation(48L, 47L);
systemRepository.addInvokeRelation(48L, 47L);
}
@Test
public void addConsumeRelation() {
systemRepository.addConsumeRelation(49L, 50L);
systemRepository.addConsumeRelation(48L, 49L);
}
/**
* 删除指定节点直接的关系 DELETE <node1-name>,<node2-name>,<relationship-name>
*/
@Test
public void deleteConsumeRelation2() {
Long from = 48L, to = 45L;
systemRepository.deleteConsumeRelation(from, to);
}
@Test
public void addProduceRelation() {
Long from = 45L, to = 50L;
systemRepository.addProduceRelation(from, to);
}
@Test
public void findSystemById() {
Long id = 45L;
SystemEntity systemEntity = systemRepository.findSystemById(id);
System.out.println(JSON.toJSONString(systemEntity));
}
@Test
public void getAllSystemNode() {
Iterable<SystemEntity> systemEntities = systemRepository.findAll();
for (SystemEntity systemEntity : systemEntities) {
System.out.println("查询所有的节点为:" + JSON.toJSONString(systemEntity));
System.out.println(JSON.toJSONString(systemEntity));
}
}
参考来源:官方网址







![[附源码]计算机毕业设计Python的专业技能认证系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/fb47cbf6cac747f984ae706338b0607a.png)