概述
在《DDL的一生(上)》中,我们以添加全局二级索引为例,从DDL开发者的视角介绍了如何在DDL引擎框架下实现一个逻辑DDL。在本篇,作者将从DDL引擎的视角出发,向读者介绍DDL引擎的架构、实现,以及DDL引擎与DDL Job的交互逻辑。
在阅读本文之前,建议读者先阅读
- 《DDL的一生(上)》
- 《PolarDB-X DDL也要追求ACID?》
DDL引擎相关概念
DDL Job
DDL Job是DDL引擎中的概念,它用于描述一个逻辑DDL。DDL引擎中,一个DDL Job对应一个逻辑DDL,DDL Job内部包含了执行一个逻辑DDL需要的一系列动作,因此在DDL引擎框架下,开发者新支持一条逻辑DDL,实质就是定义一个新的DDL Job。
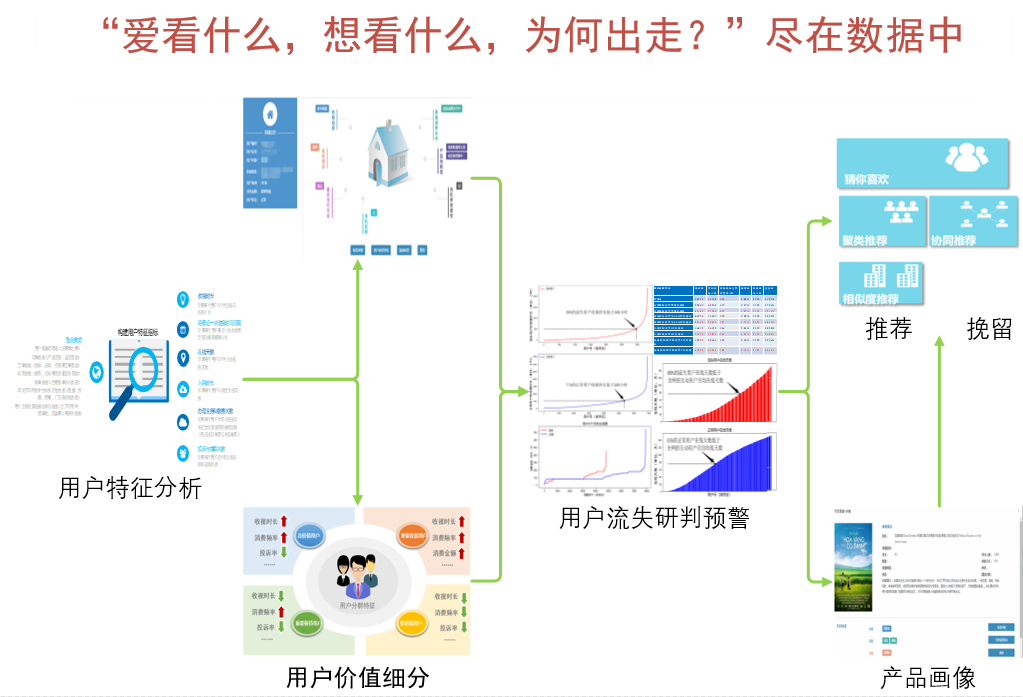
DDL开发者定义的是静态的DDL Job,然而,DDL Job在运行时,还拥有状态属性。这一属性主要由DDL引擎负责管理。当然,用户也可以执行有限的DDL运维指令以管理DDL Job的状态,实现对DDL执行过程的管理。下图是DDL Job的状态转移图,图中黑色加粗线框代表DDL Job执行的初态和终态,每个DDL Job状态之间的连线上的标注了可以执行的运维指令。

DDL Task
DDL Task是对DDL Job内部一系列行为的封装,如读写metaDb、在内存中计算、进程通信、向DN下发需执行的物理DDL等,这些行为都会被分别封装为DDL Task。因此一个DDL Job是由若干DDL Task构成的,这些Task需要按一定顺序被DDL引擎调度执行,DDL开发者可以使用Polardb-X的DDL引擎提供的DAG图框架描述Task之间的依赖关系和执行顺序。在DDL引擎框架下,开发者定义一个新的DDL Job,实质就是定义若干DDL Task,然后用DAG图把它们组合起来。
DDL Task是DDL引擎实现DDL近似原子性的重要工具,而DDL原子性是DDL引擎追求的目标。执行一条逻辑DDL涉及到一系列操作,原子性要求这些操作要么都全部生效,要么全都不生效。具体来说,DDL引擎要求每个DDL Task都是幂等的,每个Task必须有对应的反向幂等方法(此方法在回滚Task时被DDL引擎调用)。DDL引擎执行DDL之前,会为该DDL生成由DDL Task组成的DAG图,并将其持久化到MetaDb,这相当于保证DDL原子性的undo Log。DDL引擎按照DAG图依次执行Task直到整个DDL Job执行成功或者彻底回滚。
Worker和Leader
在DDL引擎的视角下,CN节点被分为Worker节点和Leader节点(在集群中唯一)。Worker节点负责接收用户发来的DDL请求,它将收到的请求进行简单的本地校验,然后把DDL转换成DDL Job并推送至MetaDb,最后通知Leader节点从MetaDb拉取DDL任务。
Leader节点负责DDL的执行,它从MetaDb拉取到DDL Job后,恢复成DAG图的形式,并对Job中的Task进行拓扑排序,然后按照一定的并行度进行调度、执行Task。
DDL 引擎源码目录
为了方面下文描述,本文先向读者说明DDL引擎源码的目录。PolarDB-X的DDL引擎的源码位于com.alibaba.polardbx.executor.ddl.newengine,各模块说明如下:
| 子目录或关键类 | 功能 |
| job | job和task对象的定义 |
| dag | 通用DAG及拓扑排序的实现,包括节点和图的定义、拓扑排序、DAG的维护和更新 |
| meta | 读写GMS中的持久化对象的接口,持久化对象包括job和task的状态、系统资源(持久化读写锁) |
| sync | 提供sync接口实现Leader节点和Follower节点之间的信息同步 |
| utils | 线程、线程间通信及线程池的封装 |
| serializable | job和task对象的序列化接口 |
| DdlEngineDagExecutor | job的执行器,包含Task调度、Task状态监测、异常处理的主要逻辑 |
| DdlEngineScheduler | job的调度器,将job置入执行队列并调用job的执行器 |
| DdlEngineRequester | ddl引擎处理ddl请求的入口,持久化ddl job并通知Leader节点处理ddl请求。 |
例子
下面,本文从DDL引擎的视角出发,向读者展示一条逻辑DDL是如何被DDL引擎调度并执行的。

DDL 任务调度
一条DDL语句由用户端的Mysql Client发出后,Worker节点接收到该DDL语句,经过简单的优化器解析后得到LogicalPlan,然后把该LogicalPlan分派到对应的DDL Handler,这个DDL Handler负责生成DDL Job。然后DDL Handler的公共基类的接口com.alibaba.polardbx.executor.handler.ddl.LogicalCommonDdlHandler#handleDdlRequest处理这个DDL请求,该函数调用com.alibaba.polardbx.executor.ddl.newengine.DdlEngineRequester#execute方法将之前生成的DDL Job及执行DDL所需的上下文写入MetaDB,并通知Leader节点处理。至此,Worker节点完成了自己的工作,如果该DDL是阻塞型的,Worker节点会等待Leader执行完DDL后,返回Response给用户端;如果该DDL是非阻塞型的,Worker节点会直接返回。
Leader节点上运行着com.alibaba.polardbx.executor.ddl.newengine.DdlEngineScheduler#ddlDispatcherThread和com.alibaba.polardbx.executor.ddl.newengine.DdlEngineScheduler#ddlSchedulerThread两个线程,它们分别对应着实例级别的DdlJobDispatcher和Schema级别的DdlJobScheduler。其中DdlJobDispatcher从全局唯一的Ddl Request 队列中取出Ddl Request,然后将其分配到Schema级别的Ddl Job队列。DdlJobScheduler是Schema级别的,它负责从Schema级别的Ddl Job队列中不断消费Ddl Job,这个过程中,DdlJobScheduler利用Schema级别的信号量对并行消费Ddl Job的并行度进行控制(同一Schema上的最大线程数为10)。DdlJobScheduler消费Ddl Job,实质上是从Schema级别的Ddl Job队列中取出Ddl Job,然后分派给DdlJobExecutor(Job级别),DdlJobExecutor负责将DDL Job转交给DdlEngineDagExecutor。至此,DDL Job正式进入DDL引擎中的执行器DdlEngineDagExecutor,由后者接管DDL Job的执行。
需要补充说明的是,从上文可以看出DDL引擎支持多个DDL并发执行,为保证需要相同资源的DDL之间互斥执行,DDL引擎提供了持久化的读写锁机制。作为DDL开发者,只需要在定义DDL Job的时候,提前声明该DDL所需的Schema、Table资源。当执行DDL的时候,DDL引擎会在com.alibaba.polardbx.executor.ddl.newengine.DdlEngineRequester#execute生成DDL Job并保存至MetaDB之前,先根据该DDL Job所需的资源进行读写锁的acquire。
DDL 任务执行
DdlEngineDagExecutor负责DDL任务的执行,它会调用restoreAndRun方法,从MetaDb中拉取并恢复DDL Job为DAG形式。然后调用run方法,根据DDL Job的当前状态执行相应的回调方法。
public class DdlEngineDagExecutor {
public static void restoreAndRun(String schemaName, Long jobId, ExecutionContext executionContext){
boolean restoreSuccess = DdlEngineDagExecutorMap.restore(schemaName, jobId, executionContext);
DdlEngineDagExecutor dag = DdlEngineDagExecutorMap.get(schemaName, jobId);
dag.run();
}
private void run() {
// Start the job state machine.
if (ddlContext.getState() == DdlState.QUEUED) {
onQueued();
}
if (ddlContext.getState() == DdlState.RUNNING) {
onRunning();
}
if (ddlContext.getState() == DdlState.ROLLBACK_RUNNING) {
onRollingBack();
}
// Handle the terminated states.
switch (ddlContext.getState()) {
case ROLLBACK_PAUSED:
case PAUSED:
onTerminated();
break;
case ROLLBACK_COMPLETED:
case COMPLETED:
onFinished();
break;
default:
break;
}
}
}com.alibaba.polardbx.executor.ddl.newengine.DdlEngineDagExecutor#run会根据DDL Job当前的状态,执行对应的回调方法,这本质上是一个在DDL Job的状态转移图上游走的过程。
DDL Job的初始状态一般为QUEUED,它表示当前被DDL引擎新调度到Schema级别队列。此时run方法会依据此状态调用onQueued()方法。onQueued()方法的作用是将DDL Job的状态修改为RUNNING。
当DDL Job当前的状态是RUNNING时,run方法就会调用onRunning回调方法,按照DAG图的依赖关系执行DDL Job内部的Task。
private void onRunning() {
while (true) {
if (hasFailureOnState(DdlState.RUNNING)) {
if (waitForAllTasksToStop(50L, TimeUnit.MILLISECONDS)) {
LOGGER.info(String.format("JobId:[%s], all tasks stopped", ddlContext.getJobId()));
return;
} else {
continue;
}
}
if (executingTaskScheduler.isAllTaskDone()) {
updateDdlState(DdlState.RUNNING, DdlState.COMPLETED);
return;
}
if (executingTaskScheduler.hasMoreExecutable()) {
// fetch & execute next batch
submitDdlTask(executingTaskScheduler.pollBatch(), true, executingTaskScheduler);
continue;
}
//get some rest
sleep(50L);
}onRunning的流程如下:
- 先检查当前DDL Job的状态是否为RUNNING,如果不是则直接返回。
- 检查当前DAG图上是否还有待执行的Task节点,如果没有,则更新Job状态为COMPLETED,然后返回。
- 如果当前DAG图上存在可以执行的Task,则用拓扑排序的方式,从DAG图上取出所有可执行的Task,按照并行度的限制,调用
submitDdlTask方法并发执行。注意,Task并不一定能执行成功,如果有Task执行失败,submitDdlTask方法会按照Task的开发者预先定义的失败策略,修改当前DDL Job的状态。最典型的,当有Task失败时,修改当前DDL Job状态为 PAUSED 或 ROLLBACK_RUNNING。详细的错误处理与恢复机制,将在下一小节介绍。
如果有DDL Job的状态为ROLLBACK_RUNNING,run方法就会调用onRollingBack()回调方法,实现DDL的回滚。相关代码如下
private void onRollingBack() {
if (!allowRollback()) {
updateDdlState(DdlState.ROLLBACK_RUNNING, DdlState.ROLLBACK_PAUSED);
return;
}
reverseTaskDagForRollback();
// Rollback the tasks.
while (true) {
if (hasFailureOnState(DdlState.ROLLBACK_RUNNING)) {
if (waitForAllTasksToStop(50L, TimeUnit.MILLISECONDS)) {
LOGGER.info(String.format("JobId:[%s], all tasks stoped", ddlContext.getJobId()));
return;
} else {
continue;
}
}
if (reveredTaskScheduler.isAllTaskDone()) {
updateDdlState(DdlState.ROLLBACK_RUNNING, DdlState.ROLLBACK_COMPLETED);
return;
}
if (reveredTaskScheduler.hasMoreExecutable()) {
// fetch & execute next batch
submitDdlTask(reveredTaskScheduler.pollBatch(), false, reveredTaskScheduler);
continue;
}
//get some rest
sleep(50L);
}
}onRollingBack的流程如下:
- 首先检查,在当前DAG图的执行进度下,是否允许回滚(一旦越过了fail point task,则不允许回滚)。如果不可回滚,则标记当前DDL Job的状态为PAUSED,然后退出。
- 当DDL Job的状态为ROLLBACK_RUNNING时,可能还存在其他正在执行中的Task。此时DDL引擎将不再允许新的Task开始执行,并且会等待正在执行中的Task成功或失败,此时该DDL Job就到达了一个一致性的状态。
- 达了一致性状态后可以开始回滚流程,首先逆转DAG图的所有有向边,使整个DDL Job的执行流程反过来。然后按照逆转后的DAG图进行拓扑排序,取出之前执行完毕或执行过但未完成的Task,执行它们的反向幂等方法。
- 当DAG图中没有可执行的Task节点时,标记DDL Job状态为ROLLBACK_COMPLETED,回滚成功。
其余状态的回调函数逻辑较为简单,这里不再赘述,请感兴趣的读者自行阅读代码。
错误处理与恢复
DDL引擎追求的目标之一是DDL的原子性,如果在执行DDL的过程中部分Task失败,DDL引擎需要采取适当措施让DDL Job变成完全未执行或执行成功的状态(即状态转移图中的终态)。DDL引擎采取的办法是给Task添加DdlExceptionAction属性,该属性用于指示DDL引擎执行Task出现异常时如何处置。DDL开发者可以在定义DDL Task的时候设置该属性。
DdlExceptionAction一共有4种取值
- TRY_RECOVERY_THEN_PAUSE:执行该Task出现异常后,重试3次,如果仍失败,则将Task对应的DDL Job状态设置为PAUSED。
- ROLLBACK:执行Task出现异常后,将该Task所在DDL Job状态设置为ROLLBACK_RUNNING,随后DDL引擎会根据该状态进行回滚DDL。
- TRY_RECOVERY_THEN_ROLLBACK:执行该Task出现异常后,重试3次,如果仍失败,将该Task所在DDL Job状态设置为ROLLBACK_RUNNING,随后由DDL引擎回滚该DDL。
- PAUSE:执行该Task出现异常后,将Task对应的DDL Job状态设置为PAUSED。
一般来说,PAUSED状态意味着该DDL Job没有达到终态,需要开发者介入处理,这常用于出现异常后无法恢复的Task,或者对外界产生了影响以致无法回滚的Task。前者举例,如drop table指令,一旦执行了删除元信息或删除物理表的Task,就无法再恢复到删除前的状态了,这时如果某Task失败且重试3次后仍失败,就会导致该DDL Job进入PAUSED状态;后者举例,如Polardb-X中大部分DDL Job都含有一个CDC打标的Task,用于对外生成bin log,该Task执行完成意味着外界已经可以获取相应DDL的bin log,因此无法回滚。
总结
本文从DDL引擎的视角,向读者介绍了DDL引擎的架构、实现,以及DDL引擎与DDL Job的交互逻辑。了解更多关于Polardb-X源码的解析,请持续关注我们后续发布的文章。
原文链接
本文为阿里云原创内容,未经允许不得转载。




![[附源码]计算机毕业设计Python的专业技能认证系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/fb47cbf6cac747f984ae706338b0607a.png)