目录
一:XML文件格式
二:ElementTree解析XML文件
三:Element之查找
四:Element之修改
五:Element之删除
六:Element之增加
xml是一种固有的分层数据格式,最自然的表示方式是解析成树状,在配置文件中很多采用xml的形式进行配置存储。在xml的日常维护中,经常会涉及到对xml文件的增删改查,如果从零开始对xml进行硬解析也是一件很麻烦的事情。
Python3内置了xml处理模块xml.etree.ElementTree 可以帮助我们去解析xml,并支持对xml的增删改查。下面我们对该模块从增删改查四个方面进行探索
一:XML文件格式
xml总体看上去就是一个树状的分层结构,下面给出一个xml文件的样例,后面针对xml的增删改查操作就以该xml为例:
<?xml version="1.0" encoding="utf-8"?>
<addr_info id="中国">
<R1 type="上海">
<device_type>黄埔区</device_type>
<username>admin</username>
<people_num>一百万</people_num>
<company>zte.com.cn</company>
</R1>
<SW3 type="南京">
<device_type>江宁区</device_type>
<username>admin</username>
<people_num>两百万</people_num>
<company>baidu.com.cn</company>
</SW3>
</addr_info>二:ElementTree解析XML文件
我们用ElementTree去解析上面的xml文件,具体用法如下:
import xml.etree.ElementTree as ET
tree = ET.parse('eg.xml')#直接读取xml文件,形成ElementTree结构
root = tree.getroot() # 获取root tag
print('tag:',root.tag) # 打印root的tag
print('attrib:',root.attrib) # 打印root的attrib
# 使用root索引访问标签的值,[0]是R1标签,[0]是R1标签中的第一个标签device_type, .text是取这个标签的值,自然值就是cisco_ios
print(root[0][0].text)
for child in root: # 打印root的child层的tag和attrib
print(child.tag, child.attrib)运行结果:
tag: addr_info
attrib: {'id': '中国', 'topic': 'ftz'}
黄埔区
R1 {'type': '上海'}
SW3 {'type': '南京'}我们可以通过dir来查看root支持的属性
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__delitem__',
'__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__getitem__', '__getstate__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__len__', '__lt__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__',
'__setstate__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'attrib',
'clear', 'extend', 'find', 'findall', 'findtext', 'get', 'getchildren',
'getiterator', 'insert', 'items', 'iter', 'iterfind', 'itertext', 'keys',
'makeelement', 'remove', 'set', 'tag', 'tail', 'text']
三:Element之查找
Element有很丰富的查找方法,总结如下:
iter(tag=None) 遍历Element的child,可以指定tag精确查找
findall(match) 查找当前元素tag或path能匹配的child节点
find(match) 查找当前元素tag或path能匹配的第一个child节点
get(key, default=None) 获取元素指定key对应的attrib,如果没有attrib,返回default。
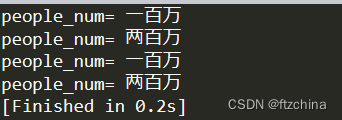
我们用iter和findall为例来查找上述例子中的人口
import xml.etree.ElementTree as ET
tree = ET.parse('eg.xml')
root = tree.getroot()
#iter查找
for addr in root.iter():
if addr.tag == 'people_num':
print("people_num=",addr.text)
#findall查找
for people in root.findall('R1'):
peopleNum = people.find('people_num').text
print("people_num=",peopleNum)
for people in root.findall('SW3'):
peopleNum = people.find('people_num').text
print("people_num=",peopleNum)运行结果:
四:Element之修改
Element的修改方法如下:
Element.text 直接修改字段
Element.remove() 删除字段
Element.set() 添加或修改属性attrib
with Element.append() 添加新的child
我们将上海黄浦区的人口数从一百万改成一千万
import xml.etree.ElementTree as ET
tree = ET.parse('eg.xml')
root = tree.getroot()
for addr in root.iter('R1'):
addr.find('people_num').text = '一千万'
tree.write('./eg2.xml',encoding='utf-8')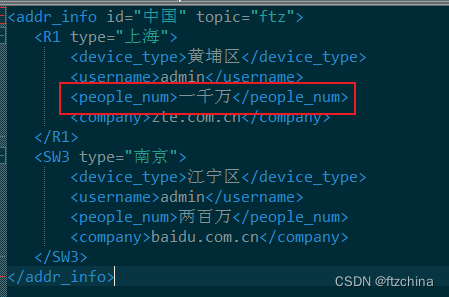
确认修改完毕后,可以使用ElementTree.write()方法写入
五:Element之删除
Element的删除方法如下:
remove 移除节点我们还是以上面为例,删除整个SW3节点
import xml.etree.ElementTree as ET
tree = ET.parse('eg.xml')
root = tree.getroot()
for addr in root.findall('SW3'):
root.remove(addr)
tree.write('./eg2.xml',encoding='utf-8')
那如果我想删除R1节点的子节点username呢,还没摸索出来,后续更新
六:Element之增加
Element的增加节点方法如下:
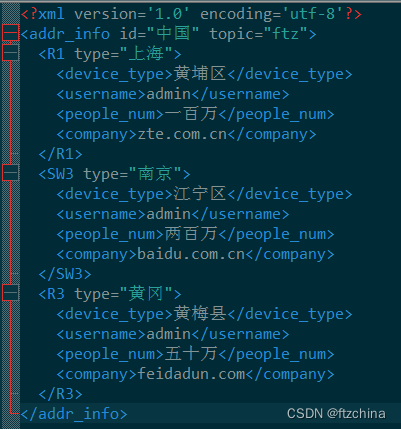
ET.SubElement我们新增一个节点黄冈的节点,还有节点下面的子节点,方法如下:
import xml.etree.ElementTree as ET
xmlParse = ET.parse('eg.xml')
root = xmlParse.getroot()
tree = ET.ElementTree(root)
#增加R3节点
hubeiNode = ET.SubElement(root,'R3')
hubeiNode.attrib = {'type':'黄冈'}
#增加R3节点的子节点
huanggang = ET.SubElement(hubeiNode,'device_type')
huanggang.text = '黄梅县'
huanggang2 = ET.SubElement(hubeiNode,'username')
huanggang2.text = 'admin'
huanggang3 = ET.SubElement(hubeiNode,'people_num')
huanggang3.text = '五十万'
huanggang4 = ET.SubElement(hubeiNode,'company')
huanggang4.text = 'feidadun.com'
tree.write('./eg2.xml', encoding='utf-8', xml_declaration=True, short_empty_elements=True) 虽然达到了我们的目的,但是写入后都挤到一行了,不方便看,用下面的函数进行美化
虽然达到了我们的目的,但是写入后都挤到一行了,不方便看,用下面的函数进行美化
def pretty_xml(element, indent, newline, level=0): # elemnt为传进来的Elment类,参数indent用于缩进,newline用于换行
if element: # 判断element是否有子元素
if (element.text is None) or element.text.isspace(): # 如果element的text没有内容
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
# else: # 此处两行如果把注释去掉,Element的text也会另起一行
# element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * level
temp = list(element) # 将element转成list
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1): # 如果不是list的最后一个元素,说明下一个行是同级别元素的起始,缩进应一致
subelement.tail = newline + indent * (level + 1)
else: # 如果是list的最后一个元素, 说明下一行是母元素的结束,缩进应该少一个
subelement.tail = newline + indent * level
pretty_xml(subelement, indent, newline, level=level + 1) # 对子元素进行递归操作最后的效果如下:
附上全部代码:
import xml.etree.ElementTree as ET
def pretty_xml(element, indent, newline, level=0): # elemnt为传进来的Elment类,参数indent用于缩进,newline用于换行
if element: # 判断element是否有子元素
if (element.text is None) or element.text.isspace(): # 如果element的text没有内容
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
# else: # 此处两行如果把注释去掉,Element的text也会另起一行
# element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * level
temp = list(element) # 将element转成list
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1): # 如果不是list的最后一个元素,说明下一个行是同级别元素的起始,缩进应一致
subelement.tail = newline + indent * (level + 1)
else: # 如果是list的最后一个元素, 说明下一行是母元素的结束,缩进应该少一个
subelement.tail = newline + indent * level
pretty_xml(subelement, indent, newline, level=level + 1) # 对子元素进行递归操作
xmlParse = ET.parse('eg.xml')
root = xmlParse.getroot()
tree = ET.ElementTree(root)
#增加R3节点
hubeiNode = ET.SubElement(root,'R3')
hubeiNode.attrib = {'type':'黄冈'}
#增加R3节点的子节点
huanggang = ET.SubElement(hubeiNode,'device_type')
huanggang.text = '黄梅县'
huanggang2 = ET.SubElement(hubeiNode,'username')
huanggang2.text = 'admin'
huanggang3 = ET.SubElement(hubeiNode,'people_num')
huanggang3.text = '五十万'
huanggang4 = ET.SubElement(hubeiNode,'company')
huanggang4.text = 'feidadun.com'
pretty_xml(root, ' ', '\n') # 执行美化方法 缩进为两个空格,'\n'换行
tree.write('./eg2.xml', encoding='utf-8', xml_declaration=True, short_empty_elements=True)