入门人工智能 ——使用 tensorflow 训练一个新闻分类模型(6)
- 入门人工智能 ——使用 tensorflow 训练一个新闻分类模型
- 使用 tensorflow 训练一个新闻分类模型
- 1. 安装TensorFlow和所需的依赖项。
- 2. 打开收集的新闻数据集
- 构建模型
- 模型训练
- 模型评估
- 保存模型
- 完整构建训练模型的代码
- 使用模型输出结果
入门人工智能 ——使用 tensorflow 训练一个新闻分类模型
人工智能(AI)和机器学习(ML)是密切相关但又有着明显区别的概念。人工智能旨在使机器或计算机表现出智能行为的能力,通常通过模拟人类的思维和行为方式来实现。与此不同,机器学习是使用算法和技术来训练机器或计算机,使其能够自动从数据中学习和改进自身的行为。
在构建一个新闻分类模型时,TensorFlow是一个常用的工具,用于开发和训练机器学习模型。TensorFlow是一个广泛使用的开源机器学习框架,可用于构建各种类型的模型,包括神经网络、决策树和深度学习模型等。通过使用TensorFlow,我们可以将收集到的新闻数据转化为一个预测模型,以协助自动识别新闻类别。
在构建新闻分类模型时,使用TensorFlow来开发和训练神经网络模型是非常常见的方法。神经网络模型类似于人类大脑的神经元,因此在进行新闻分类时,我们可以将新闻数据输入神经网络中,然后通过计算得到分类预测结果。
本文将介绍如何使用TensorFlow来训练一个新闻分类模型。我们将从数据准备开始,逐步构建模型,最后进行模型的训练和评估。
使用 tensorflow 训练一个新闻分类模型
由于新闻分类太多了,我这里用证券和非证券两种形式来训练

1. 安装TensorFlow和所需的依赖项。
pip install tensorflow
2. 打开收集的新闻数据集
收集数据也要注意法律问题,不建议去使用爬虫爬取一些非法的数据。
# 第一部分:准备数据和环境
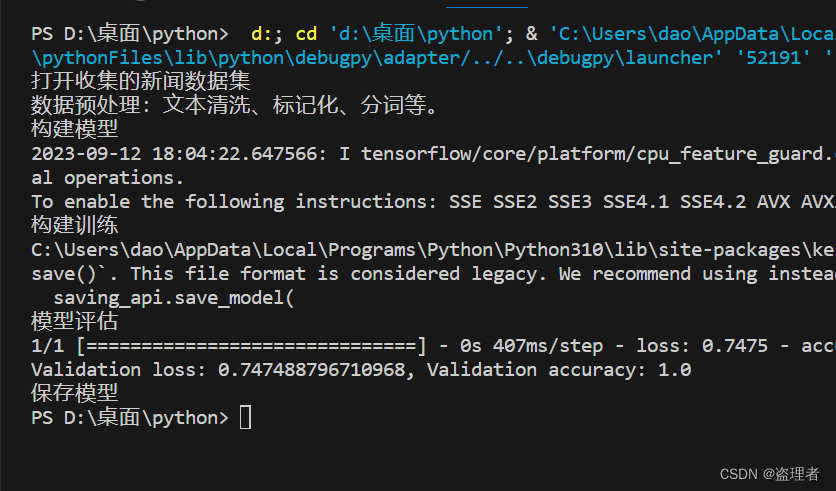
print("打开收集的新闻数据集")
# 打开一个存有数据的文件,里面是尽可能的去收集多一些的新闻数据
file = open("news.txt", "r", encoding="utf-8") # "r" 表示只读模式
# 读取整个文件内容
content = file.read()
- 数据预处理
数据预处理(Data preprocessing)的目的是为了使原始数据经过一系列的转换和处理后,能够更加方便地被存储、分析和应用。在机器学习和深度学习领域,数据预处理是非常重要的一环。
通常包括以下几个方面:
- 文本清洗:对原始数据中的文本进行去除无关信息、去除停用词、去除标点符号、去除数字和特殊字符等操作,以提高后续处理的效果。
- 标记化:将原始数据中的类别信息转换为二进制编码,例如使用 one-hot 编码,使得类别信息能够被存储为数值型数据。
- 分词:将文本数据按照一定规则进行划分,将文本切分成一个个单独的词汇,以便后续的文本分析和处理。
- 词嵌入:将词汇转换为数值型数据,使得不同词汇之间能够进行加权比较。常用的词嵌入方法有 Word2Vec、GloVe 等。
- 数据增强:通过对原始数据进行一定程度的变换,使得模型在训练过程中能够从不同角度和形式的数据中学习到知识,提高模型的泛化能力。
- 数据合并:将多个数据集合并为一个数据集,使得模型在训练过程中能够从不同数据集的联合训练中学习到知识。
- 数据规范化:将数据缩放、归一化等操作,使得不同特征之间具有相似的尺度和范围,提高模型训练效果。
- 数据融合:将不同类型的数据进行融合,例如文本数据、图像数据、音频数据等,使得模型能够从不同领域和角度学习到知识。
本次重在基础学习,就没有做那么多,就是做一个数据的分割
print("数据预处理")
labels = []
texts =[]
datas = content.split("\n")
for data in datas:
data = data.split("[fenge内容fenge]")
labels.append(data[0])
texts.append(data[1])
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
X = pad_sequences(sequences)
y = tf.keras.utils.to_categorical(labels)
构建模型
- 选择适当的神经网络架构。
Sequential()是Keras中的一个API,它用于创建一个神经网络模型,它将一个或多多个神经元连接到一起,然后将这些神经元连接到一起形成一个神经网络。Sequential()的API提供了多种不同的神经网络架构,包括简单的线性神经网络、多层感知器、自定义层等。
model = Sequential()
- 构建文本分类模型的输入层和隐藏层。
model.add(Embedding(input_dim=len(word_index) + 1, output_dim=100, input_length=X.shape[1]))
model.add(LSTM(128))
- 添加输出层,选择适当的激活函数。
model.add(Dense(len(y[0]), activation='softmax'))
- 编译模型:选择损失函数、优化器和性能指标。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
模型训练
- 划分数据集为训练集、验证集和测试集。
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
- 使用TensorFlow的数据管道来加载和预处理数据。
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train)).batch(64)
val_dataset = tf.data.Dataset.from_tensor_slices((X_val, y_val)).batch(64)
- 定义训练循环,包括批量训练和模型保存。
epochs = 10
for epoch in range(epochs):
for batch_data, batch_labels in train_dataset:
history = model.train_on_batch(batch_data, batch_labels)
# 保存模型
model.save('my_news_classification_model_tf.h5')
模型评估
- 使用验证集评估模型性能,包括准确度、精确度、召回率等指标。
val_loss, val_accuracy = model.evaluate(val_dataset)
print(f'Validation loss: {val_loss}, Validation accuracy: {val_accuracy}')
保存模型
- 将模型保存为可部署的格式。
model.save('my_news_classification_model_tf.h5')
完整构建训练模型的代码
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from sklearn.model_selection import train_test_split
# 第一部分:准备数据和环境
print("打开收集的新闻数据集")
# 打开一个存有数据的文件,里面是尽可能的去收集多一些的新闻数据
file = open("news.txt", "r", encoding="utf-8") # "r" 表示只读模式
# 读取整个文件内容
content = file.read()
print("数据预处理:文本清洗、标记化、分词等。")
labels = []
texts =[]
datas = content.split("\n")
for data in datas:
data = data.split("[fenge内容fenge]")
labels.append(data[0])
texts.append(data[1])
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
X = pad_sequences(sequences)
y = tf.keras.utils.to_categorical(labels)
print("构建模型")
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1, output_dim=100, input_length=X.shape[1]))
model.add(LSTM(128))
model.add(Dense(len(y[0]), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print("构建训练")
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train)).batch(64)
val_dataset = tf.data.Dataset.from_tensor_slices((X_val, y_val)).batch(64)
epochs = 10
for epoch in range(epochs):
for batch_data, batch_labels in train_dataset:
history = model.train_on_batch(batch_data, batch_labels)
# 保存模型
model.save('my_news_classification_model_tf.h5')
print("模型评估")
val_loss, val_accuracy = model.evaluate(val_dataset)
print(f'Validation loss: {val_loss}, Validation accuracy: {val_accuracy}')
print("保存模型")
# 保存模型
model.save('news_classification_model_tf.h5')
如果遇到需要安装的包就安装就行了。
训练结束后我们使用一下
使用模型输出结果
-
导入必要的库:
tensorflow:用于创建和训练深度学习模型。load_model:从磁盘加载已保存的Keras模型。Tokenizer:用于将文本数据转化为序列化的工具。pad_sequences:用于将不同长度的文本序列填充到相同的长度。
-
加载预训练模型:使用
load_model函数加载事先训练好的文本分类模型(假设已保存为’news_classification_model_tf.h5’文件)。 -
创建 Tokenizer 对象:创建一个Tokenizer对象,用于将文本数据转化为序列化的格式,以便输入模型。
-
准备新闻文本数据:定义了一个新的文本数据
new_text,这是您希望进行分类的文本。 -
对新文本进行预处理:首先,使用Tokenizer对象将新闻文本转化为整数序列(tokenization)。然后,使用
pad_sequences函数将序列填充为模型所需的固定长度。 -
进行分类预测:使用加载的模型对新文本数据进行分类预测。
model.predict返回一个概率分布,其中每个类别对应一个概率。 -
处理预测结果:在多类别分类问题中,通常会选择具有最高概率的类别作为预测类别。在这里,使用
np.argmax找到具有最高概率的类别的索引。 -
输出预测结果:打印出预测的类别编号。
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# 加载已保存的模型
model = load_model('news_classification_model_tf.h5')
# 创建 Tokenizer 对象并进行文本序列化
tokenizer = Tokenizer()
# 准备需要进行分类的新闻文本数据
new_text = "近日,摩根大通提高了对减肥药的销售额预期,预计到2030年,在诺和诺德和礼来制药的“双寡头”控制下,GLP-1受体激动剂相关药物的年销售额将超过1000亿美元。同时,摩根大通还预测,中国减重药物市场规模有望于2030年达到149亿美元。肥胖问题越来越受到人们的关注。根据《中国肥胖患病率及相关并发症:1580万成年人的横断面真实世界研究》报告指出,按照我国超重和肥胖的BMI分类标准,1580万成年受试者中超重人群占比34.8%,肥胖人群占比14.1%。假设按照目前中国14.2亿人口估算,约有4.94亿人超重,2亿人属于肥胖。而肥胖会引发高血压、高血脂等一系列疾病。国联证券表示,肥胖问题已经成为世界范围内的健康挑战,根据弗若斯特沙利文的统计数据显示,中国乃至全球的肥胖人数呈现持续增长的趋势。近年来全球减肥药市场规模年复合增长率达到10.7%,随着肥胖人数的增多以及居民的体重管理的意识的增强,减肥药市场潜在发展空间广阔。"
# 对新文本进行预处理,以使其与模型输入格式匹配
new_sequences = tokenizer.texts_to_sequences([new_text])
new_padded = pad_sequences(new_sequences, maxlen=len(new_sequences))
# 进行分类预测
predicted_probabilities = model.predict(new_padded)
# 对于多类别分类,您可能需要进一步处理输出
# 例如,取概率最高的类别作为预测类别
predicted_class = np.argmax(predicted_probabilities)
# 根据需要处理预测结果
print(f"预测类别编号:{predicted_class}")
**如果结果预测不准确,就需要扩大数据,训练更强的模型**