参考引用
- UNIX 环境高级编程 (第3版)
- 黑马程序员-Linux 系统编程
1. UNIX 基础知识
1.1 UNIX 体系结构(下图所示)
- 从严格意义上说,可将操作系统定义为一种软件,它控制计算机硬件资源,提供程序运行环境,通常将这种软件称为内核 (kernel),因为它相对较小,而且位于环境的核心
- 内核的接口被称为系统调用 (system call,下图中的阴影部分)
- 公用函数库构建在系统调用接口之上,应用程序既可使用公用函数库,也可使用系统调用
- shell 是一个特殊的应用程序,为运行其他应用程序提供了一个接口

1.2 文件和目录
1.2.1 文件系统
- UNIX 文件系统是目录和文件的一种层次结构,所有东西的起点是称为根 (root) 的目录,这个目录的名称是一个字符 “/”
- 目录 (directory) 是一个包含目录项的文件。在逻辑上,可认为每个目录项都包含一个文件名以及说明该文件属性的信息
- 文件属性是指文件类型 (是普通文件还是目录等) 、文件大小、文件所有者、文件权限 (其他用户能否访问该文件) 以及文件最后的修改时间等
- stat 和 fstat 函数返回包含所有文件属性的一个信息结构
1.2.2 文件名
- 目录中的各个名字称为文件名 (flename)
- 只有斜线 (/) 和空字符这两个字符不能出现在文件名中
- 斜线用来分隔构成路径名的各文件名,空字符则用来终止一个路径名
- 为了可移植性,POSIX.1 推荐将文件名限制在以下字符集之内: 字母 (a~z、A~Z)、数字 (0~9)、句点 (.)、短横线 (-) 和下划线 (_)
- 创建新目录时会自动创建了两个文件名:. (称为点) 和 …(称为点点)
- 点指向当前目录,点点指向父目录
- 在最高层次的根目录中,点点与点相同
1.2.3 路径名
- 由斜线分隔的一个或多个文件名组成的序列 (也可以斜线开头) 成路径名 (pathmamme)
- 以斜线开头的路径名称为绝对路径名,否则称为相对路径名,相对路径名指向相对于当前目录的文件
- 文件系统根的名字 (/) 是一个特殊的绝对路径名,它不包含文件名
1.2.4 工作目录
- 每个进程都有一个工作目录 (working directory),有时称其为当前工作目录 (curent working directory),所有相对路径名都从工作目录开始解释,进程可以用 chdir 函数更改其工作目录
- 相对路径名 doc/memo/joe 指的是当前工作目录中的 doc 目录中的 memo 目录中的文件 (或目录) joe
- 从该路径名可以看出,doc 和 memo 都应当是目录,但是却不能分辨 joe 是文件还是目录
- 路径名 /urs/lib/lint 是一个绝对路径名,它指的是根目录中的 usr 目录中的 lib 目录中的文件 (或目录) lint
1.3 输入和输出
1.3.1 文件描述符
- 文件描述符 (file descriptor) 通常是一个小的非负整数,内核用以标识一个特定进程正在访问的文件。当内核打开一个现有文件或创建一个新文件时,它都返回一个文件描述符
1.3.2 标准输入、标准输出和标准错误
- 每当运行一个新程序时,所有的 shell 都为其打开 3 个文件描述符,即标准输入、标准输出以及标准错误
1.3.3 不带缓冲的 I/O
- 函数 open、read、write、lseek 以及 close 提供了不带缓冲的 I/O,这些函数都使用文件描述符
1.3.4 标准 I/O
- 标准 I/O 函数为那些不带缓冲的 I/O 函数提供了一个带缓冲的接口,最熟悉的标准 I/O 函数是 printf
1.4 程序和进程
1.4.1 程序
- 程序 (program) 是一个存储在磁盘上某个目录中的可执行文件。内核使用 exec 函数,将程序读入内存,并执行程序
1.4.2 进程和进程 ID
- 程序的执行实例被称为进程 (process),某些操作系统用任务 (task) 表示正在被执行的程序
- UNIX 系统确保每个进程都有一个唯一的数字标识符,称为进程 (process ID)。进程 ID 总是一个非负整数
1.4.3 进程控制
- 有 3 个用于进程控制的主要函数:fork、exec 和 waitpid(exec 函数有 7 种变体,但经常把它们统称为 exec 函数)
1.4.4 线程和线程 ID
- 通常,一个进程 (process) 只有一个控制线程 (thread):某一时刻执行的一组机器指令。对于某些问题,如果有多个控制线程分别作用于它的不同部分,那么解决起来就容易得多。另外,多个控制线程也可以充分利用多处理器系统的并行能力
- 一个进程内的所有线程共享同一地址空间、文件描述符、栈以及与进程相关的属性。因为它们能访问同一存储区,所以各线程在访问共享数据时需要采取同步措施以避免不一致性
- 与进程相同,线程也用 ID 标识。但是,线程只在它所属的进程内起作用。一个进程中的线程 ID 在另一个进程中没有意义。当在一进程中对某个特定线程进行处理时,可以使用该线程的 ID 引用它
1.5 出错处理
- 当 UNIX 系统函数出错时,通常会返回一个负值,而且整型变量 errno 通常被设置为具有特定信息的值。而有些函数对于出错则使用另一种约定而不是返回负值。例如,大多数返回指向对象指针的函数,在出错时会返回一个 null 指针
- POSIX.1 和 ISO C 将 errno 定义为一个符号,它扩展成为一个可修改的整形左值
- 它可以是一个包含出错编号的整数,也可以是一个返回出错编号指针的函数
- 在支持线程的环境中,多个线程共享进程地址空间,每个线程都有属于它自己的局部 errno 以避免一个线程干扰另一个线程
- 对于 errno 应当注意两条规则
- 第一:如果没有出错,其值不会被例程清除。因此,仅当函数的返回值指明出错时,才检验其值
- 第二:任何函数都不会将 errno 值设置为 0,而且在 <errno.h> 中定义的所有常量都不为 0
1.6 用户标识
1.6.1 用户 ID
- 口令文件登录项中的用户 ID (user ID) 是一个数值,它向系统标识各个不同的用户。系统管理员在确定一个用户的登录名的同时,确定其用户 ID。用户不能更改其用户 ID,通常每个用户有一个唯一的用户 ID
- 用户 ID 为 0 的用户为根用户 (root) 或超级用户 (superuser)。在口令文件中,通常有一个登录项,其登录名为 root,称这种用户的特权为超级用户特权。某些操作系统功能只向超级用户提供,超级用户对系统有自由的支配权
1.6.2 组 ID
- 口令文件登录项也包括用户的组 ID (group ID),它是一个数值。组 ID 也是由系统管理员在指定用户登录名时分配的。一般来说,在口令文件中有多个登录项具有相同的组 ID。组被用于将若干用户集合到项目或部门中去。这种机制允许同组的各个成员之间共享资源
- 组文件将组名映射为数值的组 ID,组文件通常是 /etc/group
- 对于磁盘上的每个文件,文件系统都存储该文件所有者的用户 ID 和组 ID。存储这两个值只需 4 个字节 (假定每个都以双字节的整型值存放)。在检验权限期间,比较字符串较之比较整型数更消耗时间
- 但是对于用户而言,使用名字比使用数值方便,所以口令文件包含了登录名和用户 ID 之间的映射关系,而组文件则包含了组名和组 D 之间的映射关系
1.7 信号
-
信号 (signal) 用于通知进程发生了某种情况。例如,若某一进程执行除法操作,其除数为 0,则将名为 SIGEPE (浮点异常) 的信号发送给该进程。进程有以下 3 种处理信号的方式
- (1) 忽略信号。有些信号表示硬件异常,例如,除以 0 或访问进程地址空间以外的存储单元等,因为这些异常产生的后果不确定,所以不推荐使用这种处理方式
- (2) 按系统默认方式处理。对于除数为 0,系统默认方式是终止该进程
- (3) 提供一个函数,信号发生时调用该函数,这被称为捕捉该信号。通过提供自编的函数就能知道什么时候产生了信号,并按期望的方式处理它
-
很多情况都会产生信号。终端键盘上有两种产生信号的方法
- 中断键 (通常是 Delete 键或 Crl+C) 和退出键 (通常是 Ctrl+\),它们被用于中断当前运行的进程
- 调用 kill 函数。在一个进程中调用此函数就可向另一个进程发送一个信号。当然这样做也有些限制:当向一个进程发送信号时,必须是那个进程的所有者或者是超级用户
1.8 时间值
- UNIX 系统使用过两种不同的时间值
- (1) 日历时间。该值是自协调世界时 (Coordinated Universal Time,UTC) 1970 年 1 月 1 日 00:00:00 这个特定时间以来所经过的秒数累计值 (早期的手册称UTC 为格林尼治标准时间)。这些时间值可用于记录文件最近一次的修改时间等
- 系统基本数据类型 time_t 用于保存这种时间值
- (2) 进程时间。也被称为 CPU 时间,用以度量进程使用的中央处理器资源。进程时间以时钟滴答计算。每秒钟曾经取为 50、60 或 100 个时钟滴答
- 系统基本数据类型 clock_t 保存这种时间值
- (1) 日历时间。该值是自协调世界时 (Coordinated Universal Time,UTC) 1970 年 1 月 1 日 00:00:00 这个特定时间以来所经过的秒数累计值 (早期的手册称UTC 为格林尼治标准时间)。这些时间值可用于记录文件最近一次的修改时间等
- 当度量一个进程的执行时间时,UNIX 系统为一个进程维护了 3 个进程时间值
- 时钟时间
- 时钟时间又称为墙上时钟时间 (wall clock time),它是进程运行的时间总量,其值与系统中同时运行的进程数有关
- 用户 CPU 时间
- 用户 CPU 时间是执行用户指今所用的时间量
- 系统 CPU 时间
- 系统 CPU 时间是为该进程执行内核程序所经历的时间
- 用户 CPU 时间和系统 CPU 时间之和常被称为 CPU 时间
- 时钟时间
1.9 系统调用和库函数
-
什么是系统调用?
- 由操作系统实现并提供给外部应用程序的编程接口 (Application Programming Interface,API),是应用程序同系统之间数据交互的桥梁
- 所有的操作系统都提供多种服务的入口点,由此程序向内核请求服务。各种版本的 UNIX 实现都提供良好定义、数量有限、直接进入内核的入口点,这些入口点被称为系统调用 (system call)
-
通用库函数可能会调用一个或多个内核的系统调用,但是它们并不是内核的入口点
- 例如,printf 函数会调用 write 系统调用以输出一个字符串
- 但函数 strcpy (复制一个字符串) 和 atoi (将 ASCII 转换为整数) 并不使用任何内核的系统调用
-
系统调用和库函数都以 C 函数的形式出现,两者都为应用程序提供服务
- 可以替换库函数,但系统调用通常是不能被替换的
- 系统调用通常提供一种最小接口,而库函数通常提供比较复杂的功能
-
C 标准库函数和系统函数/调用关系:一个 “hello” 如何打印到屏幕的案例
- 其中系统调用相当于对系统函数(man page 中的函数)进行了一个浅封装

2. UNIX 标准及实现
2.1 UNIX 标准化
2.1.1 IOS C
- ISO C 标准现在由 ISO/TEC 的 C 程序设计语言国际标准工作组维护和开发该工作组称为 ISO/IEC JTC1/SC22/WG14,简称 WG14。ISO C 标准的意图是提供 C 程序的可移植性,使其能适合于大量不同的操作系统,而不只是适合 UNIX 系统
- ISO C 标准定义的头文件

2.1.2 IEEE POSIX.1
- POSIX.1 是一个最初由 IEEE(Institute of Electricaland Electronics Engineers,电气和电子工程师学会) 制订的标准族。POSIX.1 指的是可移植操作系统接口 (Portable Operating System Interface)。它原来指的只是 IEEE 标准 1003.1-1988 (操作系统接口),后来则扩展成包括很多记为 1003 的标准及标准草案,如 shell 和实用程序 (1003.2,本教程使用 1003.1)
- 由于 1003.1 标准说明了一个接口而不是一种实现,所以并不区分系统调用和库函数,所有在标准中的例程都被称为函数
- POSIX.1 标准定义的必需的头文件

2.2 UNIX 系统实现
2.2.1 4.4 BSD
- BSD (Berkeley Sofware Distibution) 是由加州大学伯克利分校的计算机系统研究组研究开发和分发的,4.2BSD 于 1983 年问世,4.3BSD 则于 1986 年发布,4.4BSD 于 1994 年发布
2.2.2 FreeBSD
- FreeBSD 基于 4.4BSD-Lite 操作系统。在加州大学伯克分校的计算机系统研究组决定终止其在 UNIX 操作系统的 BSD 版本的研发工作,而且 386BSD 项目被忽视很长时间之后,为了继续坚持 BSD 系列,形成了 FreeBSD 项目
2.2.3 Linux
- Linux 是由 Linus Torvalds 在 1991 年为替代 MNIX 而研发的
- Linux 是一种提供类似于UNIX 的丰富编程环境的操作系统,在 GNU 公用许可证的指导下 Linux 是免费使用的
2.2.4 Mac OS X
- 与其以前的版本相比,Mac OS X 使用了完全不同的技术。其核心操作系统称为 “Darwin”,基于 Mach 内核、FreeBSD 操作系统以及具有面向对象框架的驱动和其他内核扩展的结合
2.2.5 Solaris
- Solaris 是由 Sun Microsystems (现为 Oracle) 开发的 UNIX 系统版本
2.3 基本系统数据类型
-
头文件 <sys/types.h> 中定义了某些与实现有关的数据类型,它们被称为基本系统数据类型
-
一些常用的基本系统数据类型

3. 文件 I/O
3.1 引言
- 可用的文件 I/O 函数:打开(open)文件、读(read)文件、写(write)文件等
- UNIX 系统中的大多数文件 I/O 只需用到 5 个函数:open、read、write、lseek 以及close
本章描述的函数经常被称为不带缓冲的 I/O (unbuffered I/O,与标准 I/O 函数相对照)
- 不带缓冲指的是每个 read 和 write 都调用内核中的一个系统调用
- 这些不带缓冲的 I/O 函数不是 ISO C 的组成部分,但它们是 POSIX1 的组成部分
3.2 文件描述符
-
对内核而言,所有打开的文件都通过文件描述符引用
- 文件描述符是一个非负整数
- 当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符
- 当读、写一个文件时使用 open 或 creat 返回的文件描述符标识该文件,将其作为参数传送给 read 或 write
-
按照惯例,UNIX 系统 shell 把
- 文件描述符 0 与进程的标准输入关联
- 文件描述符 1 与进程的标准输出关联
- 文件描述符 2 与进程的标准错误关联
-
在符合 POSIX.1 的应用程序中,幻数 0、1、2 虽然已被标准化,但应当把它们替换成符号常量 STDIN_FILENO、STDOUT_FILENO 和 STDERR_FILENO 以提高可读性。这些常量都在头文件 <unistd.h> 中定义
文件描述符是指向一个文件结构体的指针
PCB 进程控制块:本质是结构体,成员是文件描述符表

3.3 函数 open 和 openat(打开或创建一个文件)
3.3.1 函数 open 和 openat 参数解析
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> // 定义 flags 参数
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode); // 仅当创建新文件时才使用第三个参数,表明文件权限
int openat(int dirfd, const char *pathname, int flags);
int openat(int dirfd, const char *pathname, int flags, mode_t mode);
- pathname:要打开或创建文件的路径名
- flags:用来说明此函数的多个选项,用以下一个或多个常量进行 “或” 运算构成 flags 参数
- O_RDONLY(只读打开)、O_WRONLY(只写打开)、O_RDWR(读、写打开)、O_EXEC(只执行打开)、O_SEARCH(只搜索打开,用于目录)
- O_APPEND(每次写时都追加到文件末尾)
- O_CREAT(若此文件不存在则创建它,与第三个参数 mode 同时使用)
- O_EXCL(如果同时指定了 O_CREAT,而文件已经存在,则出错)
- O_NONBLOCK(为文件的本次打开操作和后续的 I/O 操作设置非阻塞方式)
- O_TRUNC(如果此文件存在,而且为只写或读-写成功打开,则将其长度截断为 0)
- 函数返回值
- 若成功,返回文件描述符
- 若出错,返回 -1
- dirfd 参数把 open 和 openat 函数区分开,共有 3 种可能性
- path 参数指定的是绝对路径名,在这种情况下,dirfd 参数被忽略,openat 函数就相当于 open 函数
- path 参数指定的是相对路径名,dirfd 参数指出了相对路径名在文件系统中的开始地址,dirfd 参数是通过打开相对路径名所在的目录来获取
- path 参数指定了相对路径名,dirfd 参数具有特殊值 AT_FDCWD。在这种情况下,路径名在当前工作目录中获取,openat 函数在操作上与 open 函数类似
- openat 函数是 POSIX.1 最新版本中新增的一类函数之一,希望解决两个问题
- 第一,让线程可以使用相对路径名打开目录中的文件,而不再只能打开当前工作目录
- 同一进程中的所有线程共享相同的当前工作目录,因此很难让同一进程的多个不同线程在同一时间工作在不同的目录中
- 第二,可以避免 time-of-check-to-time-of-use (TOCTTOU) 错误
- TOCTTOU 错误的基本思想是:如果有两个基于文件的函数调用,其中第二个调用依赖于第一个调用的结果,那么程序是脆弱的。因为两个调用并不是原子操作,在两个函数调用之间文件可能改变了,这样也就造成了第一个调用的结果就不再有效,使得程序最终的结果是错误的
- 第一,让线程可以使用相对路径名打开目录中的文件,而不再只能打开当前工作目录
3.3.2 文件名和路径名截断
- 在 POSIX.1 中常量 _POSIX_NO_TRUNC 决定是要截断过长的文件名或路径名,还是返回一个出错。根据文件系统的类型,此值可以变化。可以用 fpathconf 或 pathconf 来查询目录具体支持何种行为,到底是截断过长的文件名还是返回出错
- 若 _POSIX_NO_TRUNC 有效,则在整个路径名超过 PATH_MAX,或路径名中的任一文件名超过 NAME_MAX 时,出错返回,并将 errno 设置为 ENAMETOOLONG
3.4 函数 close(关闭一个打开文件)
#include <unistd.h>
int close(int fd);
-
函数返回值
- 若成功,返回 0
- 若出错,返回 -1
-
关闭一个文件时还会释放该进程加在该文件上的所有记录锁
-
当一个进程终止时,内核自动关闭它所有的打开文件。很多程序都利用了这一功能而不显式地用 close 关闭打开文件
3.5 函数 creat(创建一个新文件)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int creat(const char *pathname, mode_t mode);
-
函数返回值
- 若成功,返回为只写打开的文件描述符
- 若出错,返回 -1
-
此函数等效于
open(path, O_WRONLY | O_CREAT | O_TRUNC, mode)
creat 的一个不足之处是它以只写方式打开所创建的文件。在提供 open 的新版本之前,如果要创建一个临时文件,并要先写该文件,然后又读该文件,则必须先调用 creat、close,然后再调用 open。现在则可用上述方式调用 open 实现
3.3-3.5 案例
案例 1
// open.c
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
int fd;
fd = open("./AUTHORS.txt", O_RDONLY);
printf("fd = %d\n", fd);
close(fd);
return 0;
}
$ gcc open.c -o open
$ ./open
# 输出如下,表示文件存在并正确打开
fd = 3
案例 2
// open2.c
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
int fd;
fd = open("./AUTHORS.cp", O_RDONLY | O_CREAT, 0644); // rw-r--r--
printf("fd = %d\n", fd);
close(fd);
return 0;
}
$ gcc open2.c -o open2
$ ./open2
fd = 3
$ ll
# 创建了一个新文件 AUTHORS.cp,且文件权限对应于 0644
-rw-r--r-- 1 yue yue 0 9月 10 22:19 AUTHORS.cp
案例 3
// open3.c
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
int fd;
// 如果文件存在,以只读方式打开并且截断为 0
// 如果文件不存在,则把这个文件创建出来并指定权限为 0644
fd = open("./AUTHORS.cp", O_RDONLY | O_CREAT | O_TRUNC, 0644); // rw-r--r--
printf("fd = %d\n", fd);
close(fd);
return 0;
}
$ gcc open3.c -o open3
$ ./open3
# 输出如下,表示文件存在并正确打开
fd = 3
$ ll
# 首先在 AUTHORS.cp 文件中输入内容,然后经过 O_TRUNC 截断后为 0
-rw-r--r-- 1 yue yue 0 9月 10 22:19 AUTHORS.cp
案例 4
- 创建文件时,指定文件访问权限 mode,权限同时受 umask 影响。结论为
- 文件权限 = mode & ~umask
$ umask
0002 # 表明默认创建文件权限为 ~umask = 775(第一个 0 表示八进制)
// open4.c
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
int fd;
fd = open("./AUTHORS.cp2", O_RDONLY | O_CREAT | O_TRUNC, 0777); // rwxrwxrwx
printf("fd = %d\n", fd);
close(fd);
return 0;
}
$ gcc open4.c -o open4
$ ./open4
fd = 3
$ ll
# 创建了一个新文件 AUTHORS.cp2,且文件权限为 mode & ~umask = 775(rwxrwxr-x)
-rwxrwxr-x 1 yue yue 0 9月 10 22:38 AUTHORS.cp2*
案例 5
- open 函数常见错误
- 打开文件不存在
// open5.c #include <unistd.h> #include <fcntl.h> #include <stdio.h> #include <errno.h> #include <string.h> int main(int argc, char *argv[]) { int fd; fd = open("./AUTHORS.cp4", O_RDONLY); printf("fd = %d, errno = %d : %s\n", fd, errno, strerror(errno)); close(fd); return 0; }$ gcc open5.c -o open5 $ ./open5 fd = -1, errno = 2 : No such file or directory- 以写方式打开只读文件(打开文件没有对应权限)
// open6.c #include <unistd.h> #include <fcntl.h> #include <stdio.h> #include <errno.h> #include <string.h> int main(int argc, char *argv[]) { int fd; fd = open("./AUTHORS.cp3", O_WRONLY); // AUTHORS.cp3 文件权限为只读 printf("fd = %d, errno = %d : %s\n", fd, errno, strerror(errno)); close(fd); return 0; }$ gcc open6.c -o open6 $ ./open6 fd = -1, errno = 13 : Permission denied- 以只写方式打开目录
$ mkdir mydir # 首先创建一个目录// open7.c #include <unistd.h> #include <fcntl.h> #include <stdio.h> #include <errno.h> #include <string.h> int main(int argc, char *argv[]) { int fd; fd = open("mydir", O_WRONLY); printf("fd = %d, errno = %d : %s\n", fd, errno, strerror(errno)); close(fd); return 0; }$ gcc open7.c -o open7 $ ./open7 fd = -1, errno = 21 : Is a directory
3.6 函数 lseek(显式的为一个打开文件设置偏移量)
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
-
每个打开文件都有一个与其相关联的 “当前文件偏移量”,通常是一个非负数,用以度量从文件开始处计算的字节数
-
lseek 中的 l 表示长整型
-
函数返回值
- 若成功,返回新的文件偏移量
- 若出错,返回 -1
-
按系统默认的情况,当打开一个文件时,除非指定 O_APPEND 选项,否则该偏移量被设置为 0
-
对参数 offset 的解释与参数 whence 的值有关
- 若 whence 是 SEEK_SET,则将该文件的偏移量设置为距文件开始处 offset 个字节
- SEEK_SET(0) 绝对偏移量
- 若 whence 是 SEEK_CUR,则将该文件的偏移量设置为其当前值加 offset,offset 可正可负
- SEEK_CUR(1) 相对于当前位置的偏移量
- 若 whence 是 SEEK_END,则将该文件的偏移量设置为文件长度加 offset,offset 可正可负
- SEEK_END(2) 相对文件尾端的偏移量
- 若 whence 是 SEEK_SET,则将该文件的偏移量设置为距文件开始处 offset 个字节
-
lseek 仅将当前的文件偏移量记录在内核中,它并不引起任何 I/O 操作。然后,该偏移量用于下一个读或写操作
-
文件偏移量可以大于文件的当前长度,在这种情况下,对该文件的下一次写将加长该文件,并在文件中构成一个空洞,这一点是允许的。位于文件中但没有写过的字节都被读为 0
案例 1
- 文件的读和写使用同一偏移位置
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main(void) { int fd, n; char msg[] = "It's a test for lseek\n"; char ch; fd = open("lseek.txt", O_RDWR | O_CREAT, 0644); if (fd < 0) { perror("open lseek.txt error"); exit(1); } // 使用 fd 对打开的文件进行写操作,读写位置位于文件结尾处 write(fd, msg, strlen(msg)); // 若注释下行代码,由于文件写完之后未关闭,读、写指针在文件末尾,所以不调节指针,直接读取不到内容 lseek(fd, 0, SEEK_SET); // 修改文件读写指针位置,位于文件开头 while ((n = read(fd, &ch, 1))) { if (n < 0) { perror("read error"); exit(1); } write(STDOUT_FILENO, &ch, n); // 将文件内容按字节读出,写出到屏幕 } close(fd); return 0; }
案例 2
- 使用 lseek 获取文件大小
// lseek_size.c #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main(int argc, char *argv[]) { int fd = open(argv[1], O_RDWR); if (fd == -1) { perror("open error"); exit(1); } int length = lseek(fd, 0, SEEK_END); printf("file size: %d\n", length); close(fd); return 0; }$ gcc lseek_size.c -o lseek_size $ ./lseek_size fcntl.c # fcntl.c 文件大小为 678 678
案例 3
- 使用 lseek 扩展文件大小
- 要想使文件大小真正扩展,必须引起 IO 操作
// 修改案例 2 中下行代码(扩展 111 大小) // 这样并不能真正扩展,使用 cat 命令查看文件大小未变化 int length = lseek(fd, 111, SEEK_END); // 在 printf 函数下行写如下代码(引起 IO 操作) write(fd, "\0", 1); // 结果便是在扩展的文件尾部追加文件空洞 - 可使用 truncate 函数直接扩展文件
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> int main(int argc, char*argv[]) { int ret = truncate("dict.cp", 250); printf("ret = %d\n", ret); return 0; }
lseek 读取的文件大小总是相对文件头部而言。用 lseek 读取文件大小实际用的是读写指针初、末位置的偏移差,一个新开文件,读、写指针初位置都在文件开头。如果用这个来扩展文件大小,必须引起 IO 才行,于是就至少要写入一个字符
3.7 函数 read(从打开文件中读数据)
#include <unistd.h>
// ssize_t 表示带符号整型;void* 表示通用指针
// 参数1:文件描述符;参数2:存数据的缓冲区;参数3:缓冲区大小
ssize_t read(int fd, void *buf, size_t count);
- 函数返回值
- 若 read 成功,则返回读到的字节数,若已到文件尾,返回 0
- 若出错,返回 -1
- 若返回 -1,并且 errno = EAGIN 或 EWOULDBLOCK,说明不是 read 失败,而是 read 在以非阻塞方式读一个设备文件/网络文件,并且文件无数据
- 有多种情况可使实际读到的字节数少于要求读的字节数
- 1、读普通文件时,在读到要求字节数之前已到达了文件尾端
- 例如,若在到达文件尾端之前有 30 个字节,而要求读 100 个字节,则 read 返 30。下一次再调用 read 时,它将返回 0 (文件尾端)
- 2、当从终端设备读时,通常一次最多读一行
- 3、当从网络读时,网络中的缓冲机制可能造成返回值小于所要求读的字节数
- 4、当从管道或 FIFO 读时,如若管道包含的字节少于所需的数量,那么 read 将只返回实际可用的字节数
- 5、当从某些面向记录的设备 (如磁带) 读时,一次最多返回一个记录
- 6、当一信号造成中断,而已经读了部分数据量时
- 1、读普通文件时,在读到要求字节数之前已到达了文件尾端
3.8 函数 write(向打开文件写数据)
#include <unistd.h>
// 参数1:文件描述符;参数2:待写出数据的缓冲区;参数3:数据大小
ssize_t write(int fd, const void *buf, size_t count);
-
函数返回值
- 若 write 成功,则返回已写的字节数(返回值通常与参数 count 值相同,否则表示出错)
- 若出错,返回 -1
-
write 出错的一个常见原因是:磁盘已写满,或者超过了一个给定进程的文件长度限制
-
对于普通文件,写操作从文件的当前偏移量处开始。如果在打开该文件时,指定了 O_APPEND 选项,则在每次写操作之前,将文件偏移量设置在文件的当前结尾处。在一次成功写之后,该文件偏移量增加实际写的字节数
阻塞和非阻塞
-
阻塞 (Block):当进程调用一个阻塞的系统函数时,该进程被置于睡眠 (Sleep) 状态,这时内核调度其它进程运行,直到该进程等待的事件发生了 (比如网络上接收到数据包,或者调用 sleep 指定的睡眠时间到了) 它才有可能继续运行。与睡眠状态相对的是运行 (Running) 状态,在 Linux 内核中,处于运行状态的进程分为两种情况
- 正在被调度执行。CPU 处于该进程的上下文环境中,程序计数器里保存着该进程的指令地址,通用寄存器里保存着该进程运算过程的中间结果,正在执行该进程的指令,正在读写该进程的地址空间
- 就绪状态。该进程不需要等待什么事件发生,随时都可以执行,但 CPU 暂时还在执行另一个进程,所以该进程在一个就绪队列中等待被内核调度
-
读常规文件是不会阻塞的,不管读多少字节,read 一定会在有限的时间内返回。从终端设备或网络读则不一定,如果从终端输入的数据没有换行符,调用 read 读终端设备就会阻塞,如果网络上没有接收到数据包,调用 read 从网络读就会阻塞,至于会阻塞多长时间也是不确定的,如果一直没有数据到达就一直阻塞在那里。同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定
- /dev/tty – 终端文件
阻塞读终端
// block_readtty.c
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(void) {
char buf[10];
int n;
n = read(STDIN_FILENO, buf, 10);
if (n < 0){
perror("read STDIN_FILENO");
exit(1);
}
write(STDOUT_FILENO, buf, n);
return 0;
}
$ gcc block_readtty.c -o block
$ ./block # 此时程序在阻塞等待输入,下面输入 hello 后回车即结束
hello
hello
非阻塞读终端
// nonblock_readtty.c
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#define MSG_TRY "try again\n"
#define MSG_TIMEOUT "time out\n"
int main(void) {
char buf[10];
int fd, n, i;
// 设置 /dev/tty 非阻塞状态(默认为阻塞状态)
fd = open("/dev/tty", O_RDONLY | O_NONBLOCK);
if(fd < 0) {
perror("open /dev/tty");
exit(1);
}
printf("open /dev/tty ok... %d\n", fd);
for (i = 0; i < 5; i++) {
n = read(fd, buf, 10);
if (n > 0) { // 说明读到了东西
break;
}
if (errno != EAGAIN) {
perror("read /dev/tty");
exit(1);
} else {
write(STDOUT_FILENO, MSG_TRY, strlen(MSG_TRY));
sleep(2);
}
}
if (i == 5) {
write(STDOUT_FILENO, MSG_TIMEOUT, strlen(MSG_TIMEOUT));
} else {
write(STDOUT_FILENO, buf, n);
}
close(fd);
return 0;
}
$ gcc block_readtty.c -o block
$ ./block # 此时程序在阻塞等待输入,下面输入 hello 后回车即结束
hello
hello
3.9 I/O 的效率
- 使用 read/write 函数实现文件拷贝
// 将一个文件的内容复制到另一个文件中:通过打开两个文件,循环读取第一个文件的内容并写入到第二个文件中
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
int main(int argc, char* argv[]) {
char buf[1]; // 定义一个大小为 1 的字符数组,用于存储读取或写入的数据
int n = 0;
// 打开第一个参数所表示的文件,以只读方式打开
int fd1 = open(argv[1], O_RDONLY);
if (fd1 == -1) {
perror("open argv1 error");
exit(1);
}
// 打开第二个参数所表示的文件,以可读写方式打开,如果文件不存在则创建,如果文件存在则将其清空
int fd2 = open(argv[2], O_RDWR | O_CREAT | O_TRUNC, 0664);
if (fd2 == -1) {
perror("open argv2 error");
exit(1);
}
// 循环读取第一个文件的内容,每次最多读取 1024 字节
// 将返回的实际读取字节数赋值给变量 n
while ((n = read(fd1, buf, 1024)) != 0) {
if (n < 0) {
perror("read error");
break;
}
// 将存储在 buf 数组中的数据写入文件描述符为 fd2 的文件
write(fd2, buf, n);
}
close(fd1);
close(fd2);
return 0;
}
- 使用 fputc/fgetc 函数实现文件拷贝
// 使用了 C 标准库中的文件操作函数 fopen()、fgetc() 和 fputc() 来实现文件的读取和写入
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
int main(int argc, char* argv[]) {
FILE *fp, *fp_out;
int n = 0;
fp = fopen("hello.c", "r");
if (fp == NULL) {
perror("fopen error");
exit(1);
}
fp_out = fopen("hello.cp", "w");
if (fp_out == NULL) {
perror("fopen error");
exit(1);
}
// 判断是否读取到文件结束符 EOF
while ((n = fgetc(fp)) != EOF) {
fputc(n, fp_out); // 将读取的字符写入输出文件
}
fclose(fp);
fclose(fp_out);
return 0;
}
- read/write:每次写一个字节,会不断的进行内核态和用户态的切换,所以非常耗时
- fgetc/fputc:有个 4096 缓冲区,所以不是一个字节一个字节地写,内核和用户切换就比较少(预读入缓输出机制)
系统函数并不一定比库函数快,能使用库函数的地方就使用库函数
标准 I/O 函数自带用户缓冲区,系统调用无用户级缓冲,系统缓冲区是都有的
- Linux 上用不同缓冲长度进行读操作的时间结果
- 大多数文件系统为改善性能都采用某种预读入 (read ahead) 缓输出技术。当检测到正进行顺序读取时,系统就试图读入比应用所要求的更多数据,并假想应用很快就会读这些数据。预读的效果可以从下图看出:缓冲区长度小至 32 字节时的时钟时间与拥有较大缓冲区长度时的时钟时间几乎一样

3.10 文件共享
-
UNIX 系统支持在不同进程间共享打开文件
-
内核使用 3 种数据结构表示打开文件,它们之间的关系决定了在文件共享方面一个进程对另一个进程可能产生的影响
- (1) 每个进程在进程表中都有一个记录项,记录项中包含一张打开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个文件描述符相关联的是:
- 文件描述符标志
- 指向一个文件表项的指针
- (2) 内核为所有打开文件维持一张文件表。每个文件表项包含
- 文件状态标志 (读、写、添写、同步和非阻塞等)
- 当前文件偏移量
- 指向该文件 v 节点表项的指针
- (3) 每个打开文件 (或设备) 都有一个 v 节点 (v-node) 结构。v 节点包含了文件类型和对此文件进行各种操作函数的指针。对于大多数文件,v 节点还包含了该文件的 i 节点 (i-node,索引节点)。这些信息是在打开文件时从磁盘上读入内存的,所以,文件的所有相关信息都是随时可用的
- (1) 每个进程在进程表中都有一个记录项,记录项中包含一张打开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个文件描述符相关联的是:
-
打开文件的内核数据结构

文件描述符标志和文件状态标志在作用范围方面的区别:前者只用于一个进程的一个描述符,而后者则应用于指向该给定文件表项的任何进程中的所有描述符
3.11 原子操作
一般而言,原子操作 (atomic operation) 指的是由多步组成的一个操作。如果该操作原子地执行,则要么执行完所有步骤,要么一步也不执行,不可能只执行所有步骤的一个子集
3.11.1 追加到一个文件
-
考虑一个进程,它要将数据追加到一个文件尾端
- 对单个进程,这段程序能正常工作,但若有多个进程同时使用这种方法将数据追加写到同一文件,则会产生问题
if(lseek(fd, OL, 2) < 0) err_sys("lseek error"); if(write(fd, buf, 100) != 100) err_sys("write error"); -
假定有两个独立的进程 A 和 B 都对同一文件进行追加写操作,每个进程都已打开该文件但未使用 O_APPEND 标志
- 此时,每个进程都有它自己的文件表项,但是共享一个 v 节点表项
- 假定进程 A 调用了 lseek,它将进程 A 的该文件当前偏移量设置为 1500 字节 (当前文件尾端处)
- 然后内核切换进程,进程 B 执行 lseek,也将其对该文件的当前偏移量设置为 1500 字节 (当前文件尾端处)
- 然后 B 调用 write,它将 B 的该文件当前文件偏移量增加至 1600。因为该文件的长度已经增加了,所以内核将 v 节点中的当前文件长度更新为 1600
- 然后,内核又进行进程切换,使进程 A 恢复运行。当 A 用 write 时就从其当前文件偏移量 (1500) 处开始将数据写入到文件,这样也就覆盖了进程 B 刚才写入到该文件中的数据
问题出在逻辑操作 “先定位到文件尾端,然后写”,它使用了两个分开的函数调用
- 解决方法:使这两个操作对于其他进程而言成为一个原子操作。任何要求多于一个函数调用的操作都不是原子操作,因为在两个函数调用之间,内核有可能会临时挂起进程
- UNIX 系统为这样的操作提供了一种原子操作方法,即在打开文件时设置 O_APPEND 标志。这样做使得内核在每次写操作之前,都将进程的当前偏移量设置到该文件的尾端处,于是在每次写之前就不再需要调用 lseek
3.11.2 函数 pread 和 pwrite
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
-
pread 函数返回值
- 若成功则返回读到的字节数,若已读到文件尾,返回 0
- 若出错,返回 -1
-
pwrite 函数返回值
- 若成功则返回已写的字节数
- 若出错,返回 -1
-
调用 pread 相当于调用 lseek 后调用 read,但是 pread 又与这种顺序调用有下列重要区别
- 调用 pread 时,无法中断其定位和读操作
- 不更新当前文件偏移量
3.12 函数 dup 和 dup2(复制一个现有的文件描述符)
#include <unistd.h>
int dup(int fd);
int dup2(int fd, int fd2);
-
函数返回值
- 若成功,返回新的文件描述符
- 若出错,返回 -1
-
由 dup 返回的新文件描述符一定是当前可用文件描述符中的最小数值
-
对于 dup2,可以用 fd2 参数指定新描述符的值
- 如果 fd2 已经打开,则先将其关闭
- 如果 fd = fd2,则 dup2 返回 fd2,而不关闭它
- 否则,fd2 的 FD_CLOEXEC 文描述符标志就被清除,这样 fd2 在进程调用 exec 时是打开状态
-
复制一个描述符的另一种方法是使用 fcntl 函数,以下函数调用等价
dup(fd); fcntl(fd, F_DUPFD, 0); // 以下情况并不完全等价 // (1) dup2 是一个原子操作,而 close 和 fcnt1 包括两个函数调用 // 有可能在 close 和 fcntl 之间调用了信号捕获函数,它可能修改文件描述符 // (2) dup2 和 fcntl 有一些不同的 errno dup2(fd, fd2); close(fd2); fcntl(fd, F_DUPFD, fd2);
3.13 函数 sync、fsync 和 fdatasync
- 传统的 UNIX 系统实现在内核中设有缓冲区高速缓存或页高速缓存,大多数磁盘 I/O 都通过缓冲区进行
- 向文件写入数据时,内核通常先将数据复制到缓冲区,然后排入队列,晚些时候再写入磁盘,这种方式被称为延写
- 通常,当内核需要重用缓冲区来存放其他磁盘块数据时,它会把所有延迟写数据块写入磁盘
- 为了保证磁盘上实际文件系统与缓冲区中内容的一致性,UNIX 系统提供了 sync、fsync 和 fdatasync 三个函数
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
void sync(void);
- 函数返回值
- 若成功,返回 0
- 若出错,返回 -1
- sync 只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束
- 称为 update 的系统守护进程周期性地调用 (一般每隔30秒) sync 函数,这就保证了定期冲洗内核的块缓冲区
- fsync 函数只对由文件描述符 fd 指定的一个文件起作用,并且等待写磁盘操作结束才返回
- fsync 可用于数据库这样的应用程序,这种应用程序需要确保修改过的块立即写到磁盘上
- fdatasync 函数类似于 fsync,但它只影响文件的数据部分
- 除数据外,fsync 还会同步更新文件的属性
3.14 函数 fcntl (改变已打开文件的属性)
#include <unistd.h>
#include <fcntl.h>
// 参数 3 可以是整数或指向一个结构的指针
int fcntl(int fd, int cmd, ... /* int arg */ );
- 函数返回值
- 若成功,则依赖于 cmd
- 复制一个已有的描述符:F_DUPFD 或 F_DUPFD_CLOEXEC,返回新的文件描述符
- 获取/设置文件描述符标志:F_GETFD 或 F_SETFD,返回相应的标志
- 获取/设置文件状态标志:F_GETFL 或 F_SETFL,返回相应的标志
- 获取/设置异步 I/O 所有权:F_GETOWN 或 F_SETOWN,返回一个正的进程 ID 或负的进程组 ID
- 获取/设置记录锁:F_GETLK、F_SETLK 或 F_SETLKW
- 若出错,返回 -1
- 若成功,则依赖于 cmd
案例
// 终端文件默认是阻塞读的,这里用 fcntl 将其更改为非阻塞读
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MSG_TRY "try again\n"
int main(void) {
char buf[10];
int flags, n;
flags = fcntl(STDIN_FILENO, F_GETFL);
if (flags == -1) {
perror("fcntl error");
exit(1);
}
flags |= O_NONBLOCK; // 与或操作,打开 flags
int ret = fcntl(STDIN_FILENO, F_SETFL, flags);
if (ret == -1) {
perror("fcntl error");
exit(1);
}
tryagain:
n = read(STDIN_FILENO, buf, 10);
if (n < 0) {
if (errno != EAGAIN) {
perror("read /dev/tty");
exit(1);
}
sleep(3);
write(STDOUT_FILENO, MSG_TRY, strlen(MSG_TRY));
goto tryagain;
}
write(STDOUT_FILENO, buf, n);
return 0;
}
3.15 函数 ioctl
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
- 函数返回值
- 若出错,返回 -1
- 若成功,返回其他值
- 对设备的 I/O 通道进行管理,控制设备特性(主要应用于设备驱动程序中)
- 通常用来获取文件的物理特性 (该特性,不同文件类型所含有的值各不相同)
3.16 传入、传出参数
#include <string.h>
char* strcpy(char* dest, const char* src);
char* strcpy(char* dest, const char* src, size_t n);
-
传入参数:src
- 指针作为函数参数
- 通常有 const 关键字修饰
- 指针指向有效区域,在函数内部做读操作
-
传出参数:dest
- 指针作为函数参数
- 在函数调用之前,指针指向的空间可以无意义,但必须有效
- 在函数内部做写操作
- 函数调用结束后,充当函数返回值
#include <string.h>
char* strtok(char* str, const char* delim);
char* strtok_r(char* str, const char* delim, char** saveptr);
- 传入传出参数:saveptr
- 指针作为函数参数
- 在函数调用之前,指针指向的空间有实际意义
- 在函数内部先做读、后做写操作
- 函数调用结束后,充当函数返回值
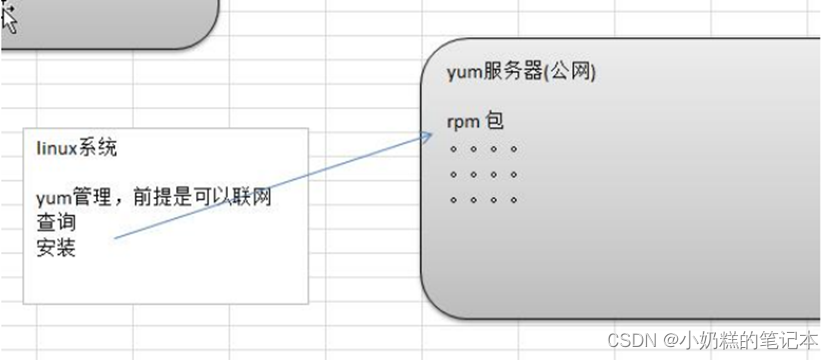







![[GWCTF 2019]我有一个数据库](https://img-blog.csdnimg.cn/218f913edfa54109b392bede748803b3.png)