文章目录
- 传送门
- 汇编程序开发
- 汇编代码初步实践
- dos虚拟机与挂载
- 实模式Hello World
- 代码解析
- 汇编
- 链接
- 重新汇编与批处理
- 反汇编与debug
- 保护模式Hello World
- VS2017+masm32环境配置
- 汇编基础
- 语言概述
- 汇编环境
- 汇编语言语句格式
- 常用伪指令
- 数据定义
- 符号定义
- 操作符
- \$
- OFFSET
- 算术操作符
- 逻辑操作符
- 关系操作符
- 框架定义伪指令
- 汇编语言程序格式
- 用户界面
- 控制台界面
- 模式定义
- 库文件以及函数声明
- 数据部分
- 代码部分
- Windows界面
- 输入输出相关API
- 分支与循环程序设计
- 分支
- 仅if
- if-else
- 分支综合:折半查找
- switch
- 循环
- loop指令
- 单层循环:do while、while、for
- 嵌套循环
- 浮点运算
- 浮点数与浮点寄存器栈
- 示例代码1
- 浮点数据/指令细究
- 数据定义
- 寻址方式
- 指令
- 示例代码2
- 性能优化
- 时间优化
- 空间优化
- 子程序设计
- 子程序基本知识
- 子程序定义
- 堆栈
- 子程序的返回地址
- 参数传递
- C语言函数的传参方式
- 汇编子程序传参方式
- 带参数子程序定义
- 子程序中局部变量
- 子程序特殊应用
- 子程序嵌套
- 子程序递归
- 缓冲区溢出
- 堆栈溢出
- 数据区溢出
- 杀毒软件原理
- 子程序模块化设计与通信
- C语言反汇编(重点)
- 基本框架与栈帧
- 选择结构
- 循环结构
- 变量定义
- 指针
- 函数
- C语言汇编混合编程
- 北京理工大学汇编大作业:坦克大战魔改版
传送门
北京理工大学2022年大三上学期开了一门《汇编语言与接口技术》,本文为系列笔记中的一篇。
为什么要先学计组知识呢,因为汇编是和硬件紧密结合的语言,没有硬件,哪来汇编?所以先学一些硬件非常有助于汇编的学习。
汇编语言笔记——微机结构基础、汇编指令基础
汇编语言笔记——汇编程序开发、汇编大作业
汇编语言笔记——接口技术与编程
汇编程序开发
(1)【重点讲解】汇编语言编程基本知识、Windows汇编语言程序设计
(2)【重点讲解】分支与循环程序设计、浮点运算
(3)【一般性讲解】程序优化
汇编代码初步实践
dos虚拟机与挂载
实模式比较危险,所以用虚拟机。
首先准备dos box工具,这个相当于在我们电脑上新建一个dos模拟器。
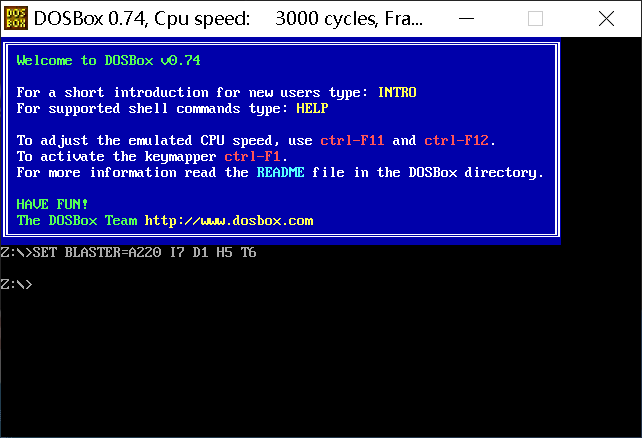
准备好工作目录,建议不要用中文路径,我已经把路径名修改成英文的了,说不准会出什么问题:
先把计算机中的工作目录挂载到dos虚拟机中,挂载点为虚拟机的C盘。
说白了就是把实际计算机的文件导入到虚拟机中。
mount c D:\assembly-tool\real

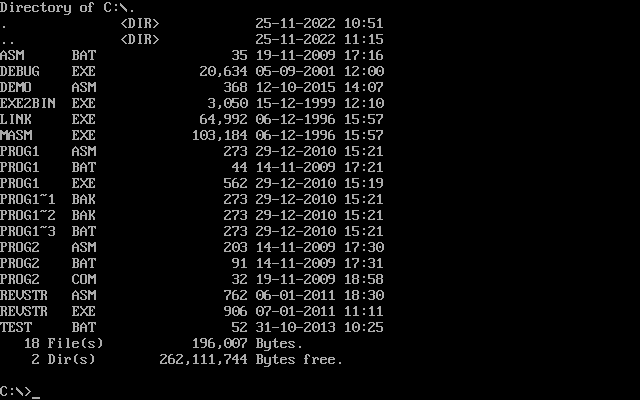
之后切到虚拟机C盘,dir列出目录看一下,导入成功:
C:
dir
实模式Hello World
代码解析
目录中,PROG1.asm就是我们的第一个汇编程序,现在主机中用记事本或者vscode打开,先看看代码是怎么写的:
其实程序架构还是比较固定的,SEGMENT与ENDS中间的代码表示这是一段。
DATA就是数据段:
- 从MSG标签开始的内存里,排列了Byte型的若干数据
CODE就是代码段,代码段先做出假设(ASSUME),把CS和CODE关联起来,然后再把DS与DATA段关联起来。
代码段里目前只有一个主函数MAIN。至于MAIN PROC FAR这个写法是什么意义暂且不谈:
- 先把DATA(数据段地址)送到AX中,再把AX送到DS中。这两步不能合并
- 配置AX,配置DX,其中DX储存了要打印信息的首地址
- INT命令调用21号中断,参数就是前面的寄存器。
- 之后再次配置,再次调用

汇编
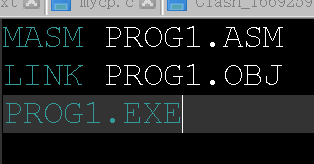
现在相当于编好了程序,我们来汇编一下:
- masm是汇编命令,只需要指定源代码即可
- 之后会问你三个问题:
- 目标代码名字,默认与源码一样
- lst中间文件,默认不生成,这里我们改名让他生成
- crf中间文件,默认不生成,这里我们让她生成
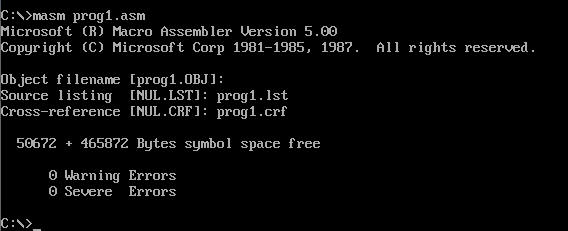
看一眼lst文件,可见,这个文件显示了汇编的详细信息
crf不用看了,没什么可用信息。
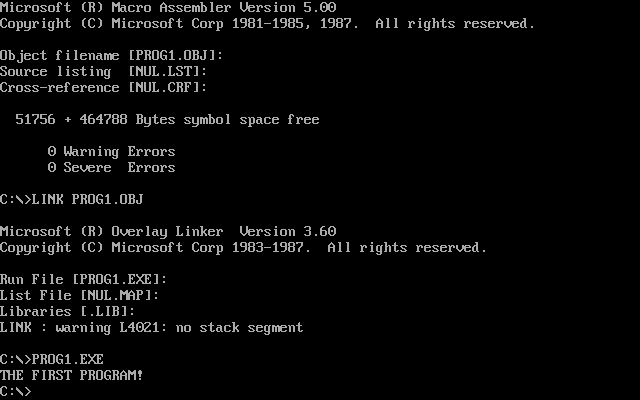
Microsoft (R) Macro Assembler Version 5.00 11/25/22 12:02:35
Page 1-1
1 0000 DATA SEGMENT
2 0000 54 48 45 20 46 49 52 MES DB 'THE FIRS$T PROGRAM!','$'
3 53 24 54 20 50 52 4F
4 47 52 41 4D 21 24
5 0014 DATA ENDS
6
7 0000 CODE SEGMENT
8 ASSUME CS:CODE,DS:DATA
9 0000 MAIN PROC FAR
10 0000 B8 ---- R MOV AX,DATA
11 0003 8E D8 MOV DS,AX
12 ;MOV DS,DATA
13
14 0005 B0 AB MOV AL,0ABH
15 0007 B4 09 MOV AH,09H
16 0009 8D 16 0000 R LEA DX,MES
17 000D CD 21 INT 21H
18
19 000F B8 4C00 MOV AX,4c00H
20 0012 CD 21 INT 21H
21 0014 MAIN ENDP
22 0014 CODE ENDS
23 END MAIN
Microsoft (R) Macro Assembler Version 5.00 11/25/22 12:02:35
Symbols-1
Segments and Groups:
N a m e Length Align Combine Class
CODE . . . . . . . . . . . . . . 0014 PARA NONE
DATA . . . . . . . . . . . . . . 0014 PARA NONE
Symbols:
N a m e Type Value Attr
MAIN . . . . . . . . . . . . . . F PROC 0000 CODE Length = 0014
MES . . . . . . . . . . . . . . L BYTE 0000 DATA
@FILENAME . . . . . . . . . . . TEXT prog1
21 Source Lines
21 Total Lines
6 Symbols
50672 + 465872 Bytes symbol space free
0 Warning Errors
0 Severe Errors
链接
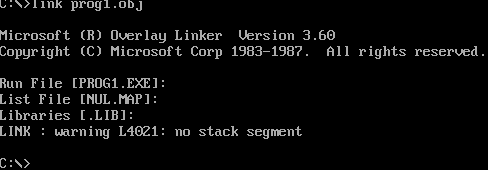
现在我们有obj文件,要把他变成exe文件,就要链接。
同样是默认默认默认。
不过这里有个warning,说没定义堆栈段,虽然我们这里不用堆栈,但是规范的代码应该定义。
去windows主机上找到prog1.exe,双击运行,跑不了。很正常,因为这是在16位虚拟机上汇编出来的,平台不同。

在虚拟机里跑一下看看结果:
结果有点奇怪是不是,我们当时定义的可比这个长多了,为什么截止了?
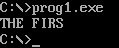
一看代码,里面有$符号,在汇编中,这个符号是字符串结束的表示,类似于C语言中的\0,所以删去中间的符号即可完全打印。
注意,$是21号中断的输出截止符,而\0是字符串的截止符,和$不是一个东西。
# MES DB 'THE FIRS$T PROGRAM!','$'
MES DB 'THE FIRST PROGRAM!','$'
但是问题来了,我们又要跑一次流程,挺麻烦的,有没有一次性输入一大堆命令的工具呢?就是批处理
重新汇编与批处理
BAT文件是批处理文件,用于批量输入规定好的命令,也就是所谓的批量处理。
打开prog1.BAT文件就可以看到之前的编译命令。
运行批处理文件,然后一个劲按回车就可以直接走完全部流程,可以看到我们完全打印出来了结果:
反汇编与debug
将代码修改一下,增加一些数据,ABC三个数,目标是用A+B算出C,之后我们用反汇编玩一玩这些数据:
有一个注意点:
- 实模式是16位的,所以要用DW,AX
DATA SEGMENT
MES DB 'THE FIRST PROGRAM!','$'
A DW 123
B DW 456
C DW ? ;先啥都不放,后面算出来放过来
DATA ENDS
CODE SEGMENT
ASSUME CS:CODE,DS:DATA
MAIN PROC FAR
MOV AX,DATA
MOV DS,AX
;MOV DS,DATA
MOV AL,0ABH
MOV AH,09H
LEA DX,MES
INT 21H
MOV AX,A ;计算C=A+B
ADD AX,B
MOV C,AX
MOV AX,4c00H
INT 21H
MAIN ENDP
CODE ENDS
END MAIN
如果你直接执行,会发现和前面那个没啥区别,这是因为,我们压根就没输出,想输出就调用21号中断,但是我们debug更多地是用debug工具去跟踪调试。
对一个exe文件使用debug命令进入分析模式:
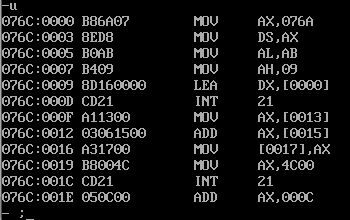
u命令列出等待执行的所有指令,执行完的指令不会出现在列表里:
可以看到:
- ABC这三个VAR变量,其实就是直接寻址。
- 所有label都已经被变成了地址,比如DS变成了076AH。
- 指令中的立即数是小端记法
t命令执行一条指令,并且打印出执行后的各种寄存器,状态位,以及下一条待执行指令:
可以看到,AX已经变成了076AH(DATA)
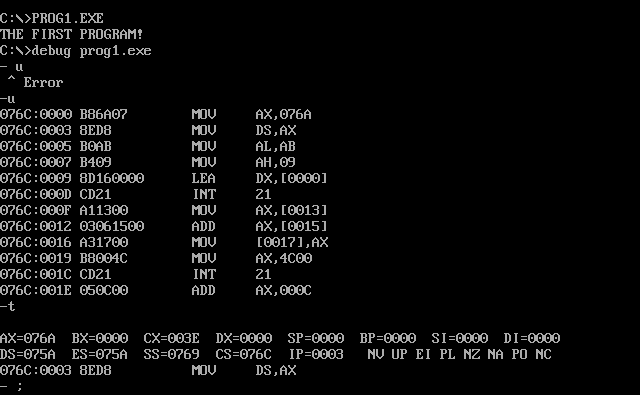
再执行一步,就可以看到DS已经被赋值。
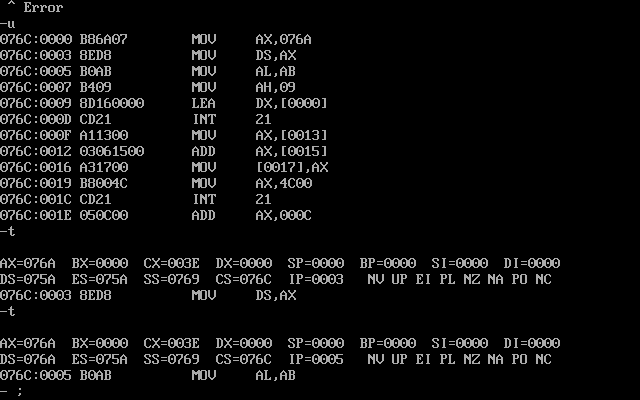
后面的代码就是打印一句话,对我们的调试没啥用,我们关心的是ABC数据,所以我们先把ABC打印出来。
d命令,给定地址(段基址:偏移),打印从该地址开始的一系列内容。我们把数据段地址给他,他会把数据段内容打印出来:
- 首先是一串问候语
- 24就是$,代表字符串结尾
- 7B 00其实就是007BH,即123,C8 01其实就是01C8H,即456。后面的C是00 00,其实就是?
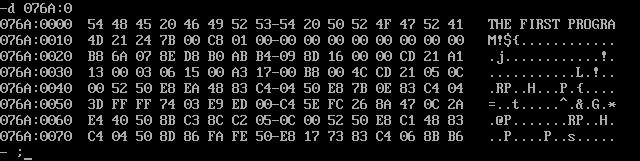
看完数据以后,建议直接跳过21号中断,不然可能跟踪地太深入出不来
g命令就是goto,跳转到目标指令:
调试会一次性执行完中间的部分,跳到我们的目标位置。
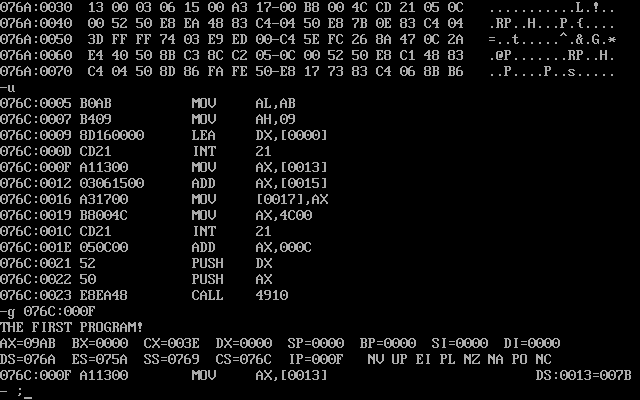
从现在开始计算C=A+B,连走三步,看看过程:
指令里都出现了立即数寻址,默认段寄存器是DS:
- 指令先把DS:013H的数丢到AX中
- 之后把DS:015H的数加到AX中
- 最后把AX赋给DS:017H。
如果你感觉这三个数字比较奇怪,那你可以在数据段中数字节,A就是13,14字节,B是15,16,C是17,18。
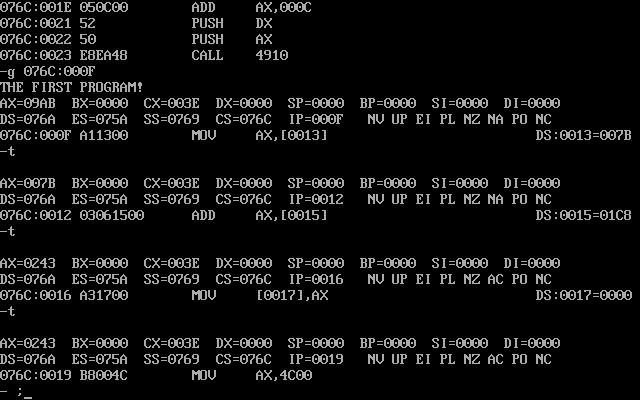
用d命令看看运算结果:
可以看到,C的位置已经被43 02填充,转换成数字就是0243H=007BH+01C8H,即579=123+456。
完美。
保护模式Hello World
保护模式在protect目录中,保护模式可以直接在windows上跑。因为保护模式对地址有一些隐蔽,所以更加简单一些。而实模式要跟踪地址,费心费力。
我们的知识点基本都是实模式的,比较好讲,但是实际开发都是保护模式,效率比较高,省心。
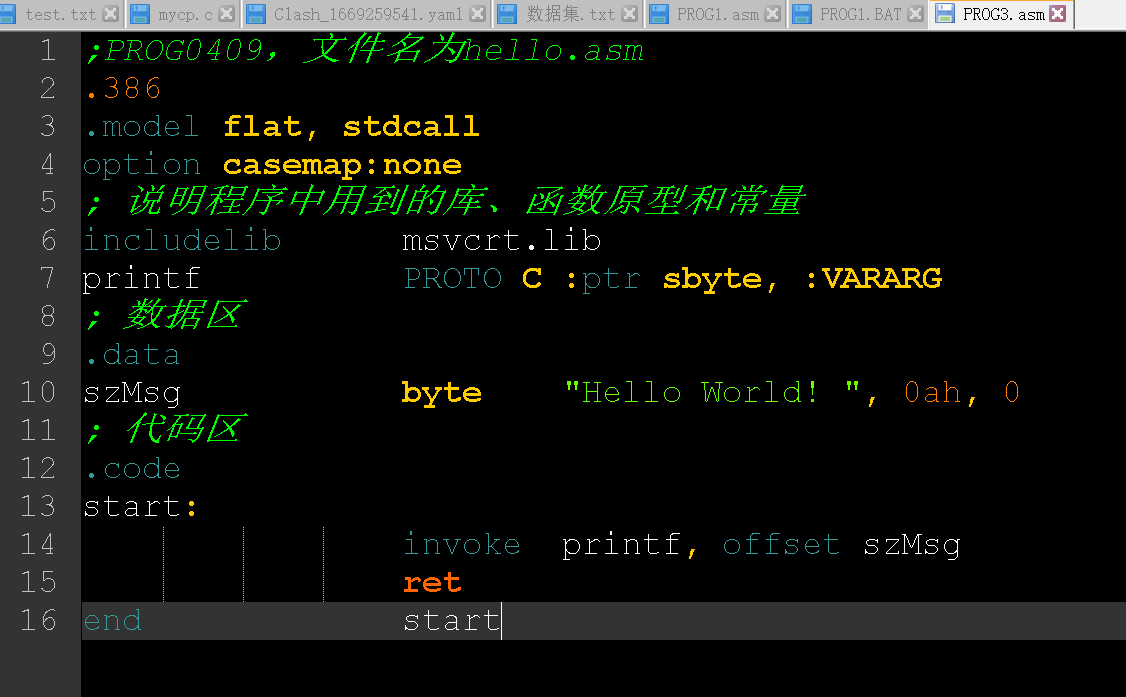
保护模式下的prog3.asm:
- .386是伪指令,告诉你这是在386CPU上跑
- option可选项,casemap:none代表不区分大小写
- includelib是导入汇编库
- printf这一句定义了其函数原型(参数列表)
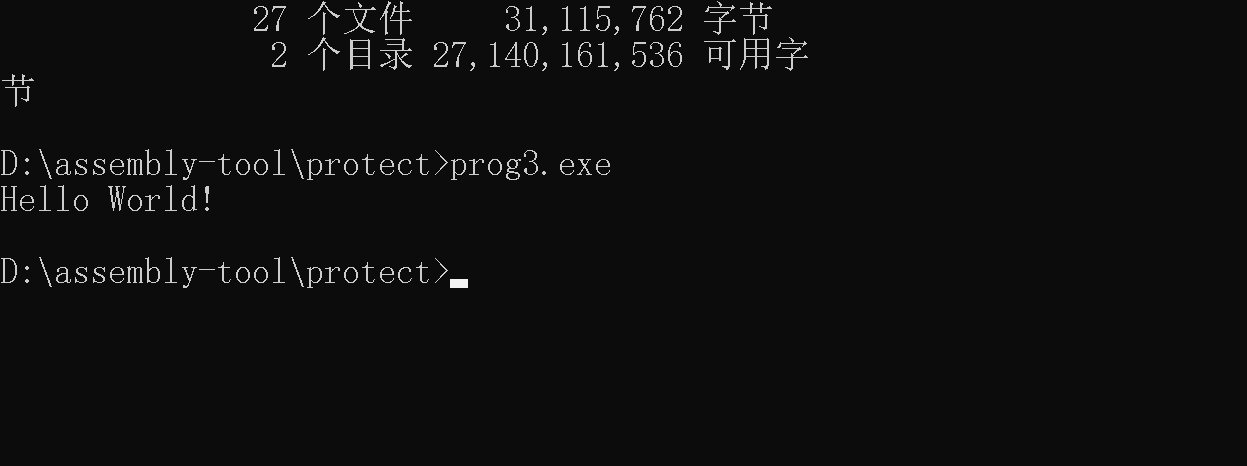
看一下执行这段代码的批处理文件写法:
汇编和链接环节是一样的,只不过用的命令不一样,参数写法也不一样。

最后cmd进入目录执行一下,注意要用cmd,直接点的话他不会保持控制台输出。
VS2017+masm32环境配置
详见课本的附录,或者自行去搜索TODO
汇编基础
语言概述
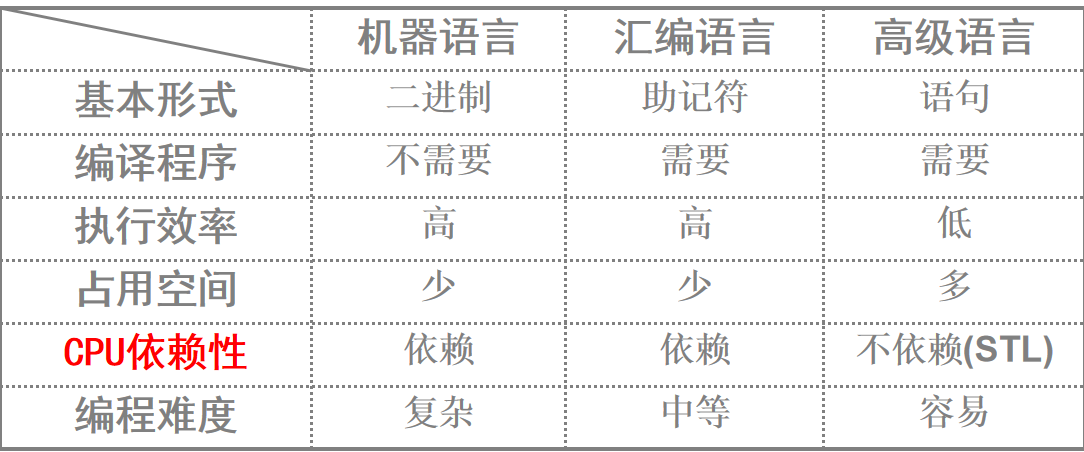
机器语言是二进制的命令,汇编是机器语言的符号化表示,高级语言建立在汇编之上,更像人类语言。
C语言最开始出名是其可移植性(STL标准库),后面和其他高级语言对比才显现出其速度优势。
汇编环境

平 台:
Intel 80X86/Pentium
DOS/虚拟8086模式(V86)
Windows/保护模式
MASM5.1 MASM6.11 MASM32
实模式:
上机过程:masm→link→.exe / .com
编辑:temp.asm
汇编:masm temp.asm→temp.obj
连接:link temp.obj→temp.exe
调试方式:Debug
保护模式(VS集成开发环境)
上机过程:ml→link
编辑:temp.asm
汇编:ml /c /coff hello.asm→hello.obj
连接:link /subsystem:console[windows] hello.obj→hello.exe
调试方式:WinDebug
汇编语言语句格式
汇编语句分为三种:
- 指令: 实际的指令。每条指令语句都生成机器代码,各对应一种CPU操作,在程序运行时执行。
- 伪指令: 汇编期间计算的指令。伪指令语句由汇编程序在汇编过程中执行,数据定义语句分配存储空间,其它伪指令不生成目标码。
- 宏指令: 宏替换的指令。宏指令是用户按照宏定义格式编写的一段程序,可以包含指令、伪指令、甚至其他宏指令。
汇编语言的4个成分:
- 名字:其实就是label,是以符号形式储存的地址,起名格式类似于变量名,用的时候也有一种变量名的感觉,但是似是而非,并不等同。
- 助记符:指令固定的名字,比如MOV,SUB

常用伪指令
数据定义
格式:[变量名] 助记符 操作数
功能:为变量分配单元,并为其初始化或者只预留空间。
类似于声明一个变量,这是唯一分配空间的伪指令。
- 变量名:实际上是一个地址,用于引用数据。当然也可以没有,因为还可以通过其他变量名(标签)引用这个数据。这和C语言的变量名就很不相同,本质上来说,是因为我们这里的数据是顺序排列的,而且变量名的地址配合偏移可以访问任意数据。
- 助记符:声明数据类型,即一个数据的空间。DB,DW,DD,DQ最常用
- 操作数:形式很多。
- 数字常量,数值表达式。默认10进制,其他进制要加后缀
- 字符串常量。汇编不区分字符和字符串,统一用单引号。每个字符占1字节空间
- 地址表达式。如果变量储存地址表达式,那这个变量实际就是个指针。需要注意的是,如果只储存偏移,就用DW,如果还要储存段基址,就用DD。offset+标签很神奇,他会根据你的数据类型自动转换出对应长度的地址。比如VAR DW offset LAB就是只有偏移量的情况。VAR DD offset LAB就是偏移量和基址的情况。
- ?代表不确定,只预留空间,但是不赋初值。
- <n> dup(重复内容),将重复内容重复n次。dup可以嵌套
下面举例:
- M1:除了字符串和DUP以外,其他的,每用逗号分割就是一个数,只要不越界,就会占用一个空间
- M2,M4:立即数是反序的,符合小端法表示,但是字符串是正序的(因为一次储存一个字节,不会有反序问题),而且字符串也不存在越界问题。字符串的助记符一般固定为DB,不需要考虑特殊情况。
- M5:DUP重复

定义了数据,如何使用?关键在于认识到标签的本质是VAR型变量,储存的是地址。
LEA DX, M4+2 LEA计算地址,DX储存的就是M4本身的值+2(地址)
MOV CX, M4+2 MOV这里使用内存直接寻址方法,CX储存的是M4+2对应的空间。这里看起来和变量用法一样,但是注意这里本质上是直接寻址。
给出例子:
可直接通过变量名引用变量(立即寻址),但要注意类型匹配。例如以下程序片段:
MOV AL,M1 ;(AL)= 15
MOV BX,M3 ;(BX)= 20
ADD M3,6 ;(M3)= 26 ;这里M3是一个DW PTR
MOV AL,M2 ;(AL)=’1’=31H
MOV BL,M2+2 ;(BL)=’A’=41H
MOV M1+3,BL ;(M1+3)= 41H
关于空间的讨论,这里给出例题:

符号定义
等值EQU伪指令
格式:符号名 EQU 表达式
功能:用符号名代表表达式或表达式的值。
说明:表达式可以是任何有效的操作数格式。例如常数、数值表达式、另一符号名或助记符。
注意:用EQU定义的符号在同一个程序中不能再定义,比如下图就是错的

效果上来说,我感觉这个就是汇编期间的计算+符号宏替换。有些操作是直接计算,尤其是加了运算伪指令的(下面的msg例子),也有的是直接替换,比如那个B操作,直接替换成了[BP+6]
例.
CR EQU 0DH ;回车符的ASCII值
LF EQU 0AH ;换行符的ASCII值
BEL EQU 07H ;响铃符的ASCII值
PORT_B EQU 61H ;定义PORT_ B端口
B EQU [BP+6] ;[BP+6]用B表示
程序中可以通过符号引用这些值,例如:
MOV AL,CR ;等价于 MOV AL, 0DH
ADD BL,B ;等价于 ADD BL,[BP+6])
OUT PORT_B,AL ;输出到61H端口
EQU还可以用于计算字符串长度(注意是在汇编期间),$的含义是当前语句的首地址,所以$-msg就是字符串的空间长度。假设中间是DW的几个数据,那就写($-msg)/2,总之可以在汇编期间计算出长度。
MSG DB ‘This is first string.’
Count equ $-msg
Mov cl,count ;(CL)=MSG的串长=21
等号(=)伪指令
格式:符号名 = 数值表达式
功能:用符号名代替数值表达式的值
等号伪指令与EQU伪指令功能相似,其区别:
- 等号伪指令的表达式只能是常数或数值表达式。
- 可以再定义。通常在程序中用“=”定义常数。
DPL1 = 20H ;只能是常数
K = 1
K = K+1 ;可以反复定义
操作符
操作符伪指令也有+,-,AND,OR。和真正的指令区别在于,操作符伪指令是汇编期间计算的,而真正的操作符指令是运算时期计算的。
操作符伪指令可以嵌入到data和code段。
$
给出当前语句的首地址
MSG DB ‘This is first string.’
Count equ $-msg
Mov cl,count ;(CL)=MSG的串长=21
wVar WORD 0102h, 1000, 100*100
BYTESOFWVAR EQU $-wVar ;值等于6
MOV EAX, $ ;将伪指令嵌入code段
OFFSET
平时要是想取出一个地址赋值到寄存器,需要用LEA命令。用伪指令修饰的OFFSET VAR提供了另一种直接用地址的方法
格式:offset [变量|标号]
功能:offset操作符用来取出变量或标号的地址(在段中的偏移量)。在32位编程环境中,地址是一个32位的数。
MOV EBX, dVar2 ;直接寻址
MOV EBX, offset dVar2 ;将地址送到EBX,相当于LEA
LEA EBX, dVar2 ;等价
算术操作符
+、-、*、/和MOD,可以用在数值表达式或地址表达式中。
例.
X DW 12,34,56
CT EQU ($-X)/2
MOV CX ,CT ;(CX)= 3
MOV AX ,X
ADD AX ,X+2 ;(AX)= 46
逻辑操作符
逻辑操作符包括AND、OR、XOR和NOT。逻辑操作符是按位操作的,它只能用在数值表达式中。 仍然是汇编期间计算,汇编后是看不到这些伪指令的。
PORT EQU 0FH
AND DL,PORT AND 0FEH
汇编后: AND DL,0EH
关系操作符
关系操作符包括EQ、NE、LT、LE、GT、GE。其操作结果为一个逻辑值,若关系成立结果为真(全1),否则结果为假(0)。
注意是全1,比如0FFH。
例.指令 MOV AL,CH LT 20的汇编结果:
MOV AL,0FFH ;当CH<20时
或:MOV AL,0 ;当CH≥20时
框架定义伪指令
框架定义了汇编程序运行的环境,处理器,以及程序框架。
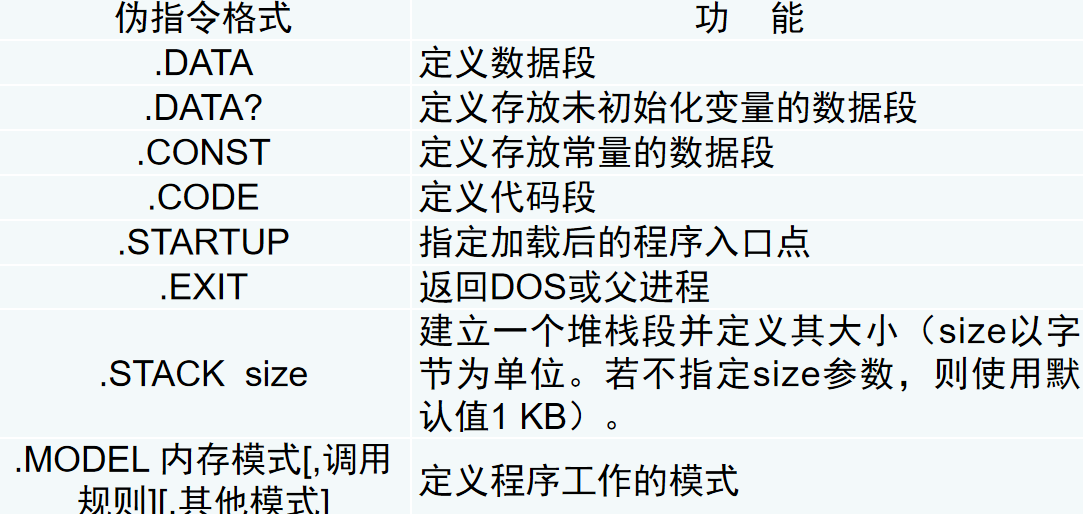
比较重要的伪指令有model指令和stack指令。

TINY和FLAT都是将代码和数据放在一个段中,只不过TINY是16位空间,FALT是32位空间。


汇编语言程序格式

用户界面
分为CUI和GUI:
- C:character
- G:graph
这里不介绍,重点还是在控制台界面。
控制台界面
这是一段非常经典的框架,要求背会,烂熟,可以直接手写的那种。具体的,会在后面逐一解释。
.386
.model flat, stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :ptr sbyte,:VARARG
.data
szMsg byte “Hello World! %c”,0ah,0
a byte 'Y'
b byte "hello"
.code
start:
invoke printf,offset szMsg,a
invoke printf,offset szMsg,offset b
ret
end start
上面的程序,符合下面的框架,以后写的时候基本也按照这个方法写就行。

模式定义
.386
.model flat,stdcall
option casemap:none
386指的是程序用386指令集,并不代表我们的电脑就是386的。
.model定义储存模型,TINY和FLAT都是将代码和数据放在一个段中,只不过TINY是16位空间,FALT是32位空间。
最后,option代表可选项,win32中需要定义casemap,用于说明程序中的变量和子程序名是否对大小写敏感(数据对大小写敏感)
option中还有language,segment等选项。
库文件以及函数声明
include类似于C语言中的include。今天的汇编比以前强很多,可以调用很多的库,甚至是open-GL这种大型库。
include 的都是.inc文件
includelib 的都是.lib文件
include语句格式:include 文件名
include kernel32.inc
include user32.inc
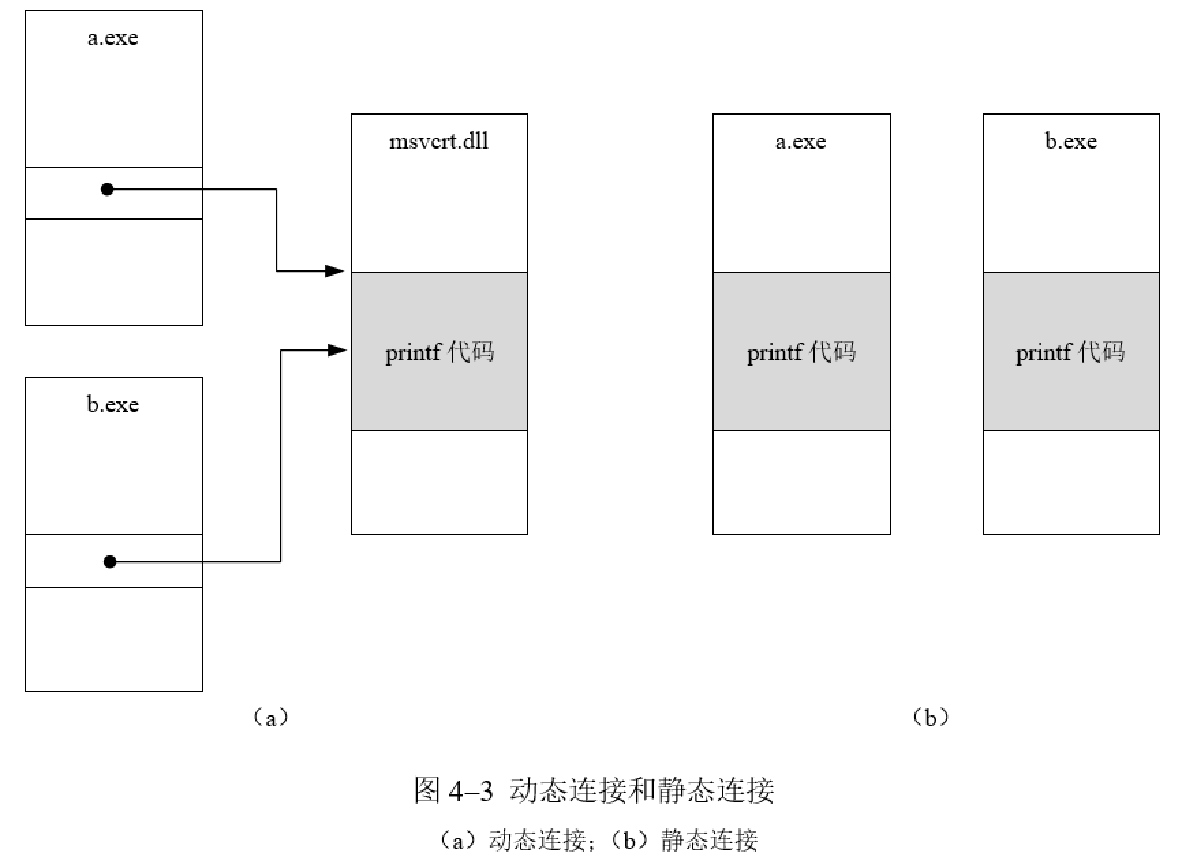
导入库后有两种连接方式,比如导入了msvcrt(micro soft visual c++ runtime)库,动态链接就会在执行的时候将msvcrt.dll导入内存,而静态链接在链接过程中直接把代码的指令封入可执行文件。
动态链接效率较高,静态链接保密性较好,不容易出问题。
函数名称 PROTO [调用规则] :[第一个参数类型] [,:后续参数类型]
在汇编语言中,用ptr sbyte代表const char *
printf PROTO C :ptr sbyte, :VARARG
函数声明后,就可以用INVOKE伪指令来调用
数据部分
从.data开始。
常规数据都放在这里,有一些不会被修改的常量可以放在code段里,但是大家还是习惯于放在数据段中。

代码部分
从.code开始。所有真正的指令必须写在code段里(但是伪指令可以出现在不同的地方)。
code段比较神奇的一点是end。在code段里会看到:
start:
;代码
end start
这个end是程序的结束,但是跟在end后的标签其实是程序的入口,记录了装载第一条指令的地址。
invoke是一个伪指令,起到call的作用,但是还兼顾参数传递和清理的功能。invoke指令可能会比较长,一般是因为调用函数参数过多,可以用反斜杠换行:
invoke MessageBox, \
NULL,\ ;HWND hWnd
offset szMsg,\ ;LPCSTR lpText
offset szTitle,\ ;LPCSTR lpCaption
MB_OK ;UINT uType
Windows界面
Windows界面和控制台界面差不多只是增加了一些图像相关的库和调用。
.386
.model flat, stdcall
option casemap:none
MessageBoxA PROTO :dword, :dword, :dword, :dword
MessageBox equ <MessageBoxA>
Includelib user32.lib
NULL equ 0
MB_OK equ 0
.stack 4096
.data
SzTitle byte 'Hi!', 0
SzMsg byte 'Hello World!' ,0
.code
start:
invoke MessageBox,
NULL, ; HWND hWnd
offset szMsg, ; LPCSTR lpText
offset szTitle, ; LPCSTR lpCaption
MB_OK ; UINT uType
ret
end start
输入输出相关API
printf
includelib msvcrt.lib
printf PROTO C :ptr sbyte,:vararg
printf PROTO C :dword,:vararg
dword和ptr sbyte都是一样长度,所以可以互用。不过,sbyte信息更多,代表了有符号。
还有就是,调用的时候,送入的参数是数据段里的,甚至第一个参数也要在数据段中定义。
这个和我们的习惯略有不同,我们在C语言中,这种字符串都是类似于立即数的东西,而在汇编中,需要先在数据段定义用于匹配输出的字符串。
举个例子,szOut就需要提前在数据段定义,而我们C语言一般都是直接写的。
.data
szOut byte 'x=%d n=%d x(n)=%d', 0ah, 0
.code
invoke printf, offset szOut, x, n, p
我又寻思了一下,貌似C语言也可以这么写,可以理解为C语言的常量字符串在底层上会先存在数据段。
scanf
includelib msvcrt.lib
scanf PROTO C :dword,:vararg
MessageBox
includelib user32.lib
MessageBoxA PROTO :DWORD, :DWORD, :DWORD, :DWORD
这里有一个很重要的区别,就是MessageBoxA的PROTO后没有C。
printf和scanf都是CDEC声明(C decline)
MessageBoxA是STDCALL声明
具体的区别后面会讲。
分支与循环程序设计
分支和循环全部使用jxx和jmp跳转实现,对于if else ,switch,for ,while等操作,汇编中的写法是有套路的,本节直接通过代码分析这些套路。
分支
if结构有两种,一种是只有if,另一种是if+else结构。
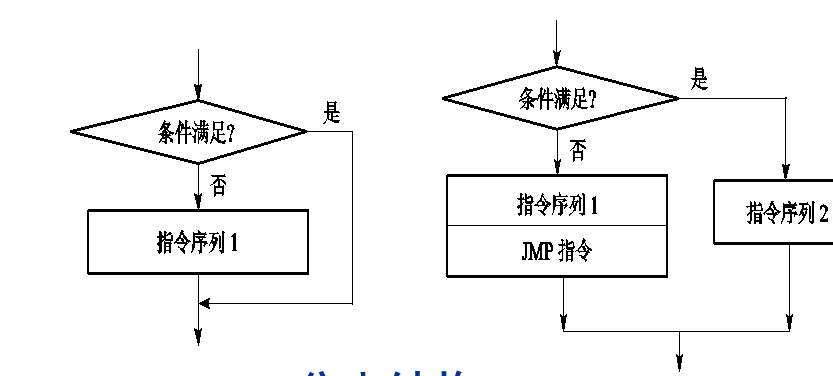
仅if
if伪代码:
cmp条件判断
jxx here,此处和if要反写
if里的代码
jmp here ;可有可无,写了更直观
here:
熟悉C语言的人可能会一下反应不过来,理论上应该是满足条件才执行目标代码,而不是满足条件就跳过目标代码。非也,此条件只是jxx的判断条件,并不是你if里写的条件,实际上,这个jxx和你if的条件是反过来的,如果jxx满足,也就意味着if条件不满足,所以就要跳过。
if-else
那if-else怎么写呢?看下面伪代码,如果jxx判断正确,就会跳到else,如果失败,就会顺序执行if部分代码,执行完if后要用jmp here跳到分支结尾。
需要注意的是,建议在每个分支的执行语句最后加上jmp here这种指令,here代表分支判断结束,要继续执行顺序语句的那个起点。
if-else伪代码:
cmp比较指令
jxx label
if部分指令
jmp here ;if-else二选一,执行完if后要跳到结尾
label:
else部分指令
jmp here ;可有可无,写了就比较规范
here:
这是一个真实的if-else if-else的三分支例子,求带符号数x的符号,如果大于0,就给SIGNX赋值1,等于0就赋值0,小于0就赋值-1。
- 程序中,x是有符号的双字-45,SIGNX是有符号但是未知值的双字。
- 首先清零SIGNX初始化,之后用X和0比较,注意JGE是针对有符号数的,JA是针对无符号数的
- 如果X≥0,就跳到XisPositive标签,否则(x<0)就顺序执行,把SIGNX赋值-1,赋值结束后要jmp到HERE,HERE就是分支结束的位置
- x≥0的时候,还要继续分支,所以又进行cmp和JE,如果x=0,跳转到XisZero部分赋0,否则就说明x>0,就赋1,赋值后jmp HERE跳转到分支结束位置。
- 理论上,为了最好的视觉效果,在XisZero部分也应该加jmp HERE,但是人们为了方便和效率,常常是不加的,反正下一步也就执行完了。
;PROG0503
数据:
X SDWORD -45
SIGNX SDWORD ?
指令:
MOV SIGNX, 0
CMP X, 0
JGE XisPostive ; X≥0,跳转
MOV SIGNX, -1
JMP HERE ; 分支结束
XisPostive:
CMP X,0
JE XisZero
MOV SIGNX, 1
JMP HERE ;分支结束
XisZero:
MOV SIGNX,0
JMP HERE ;可有可无,分支结束
HERE:
分支综合:折半查找
二分查找的原理很直观,就是通过移动上下界不断分割区间,直到搜索到目标数为止:
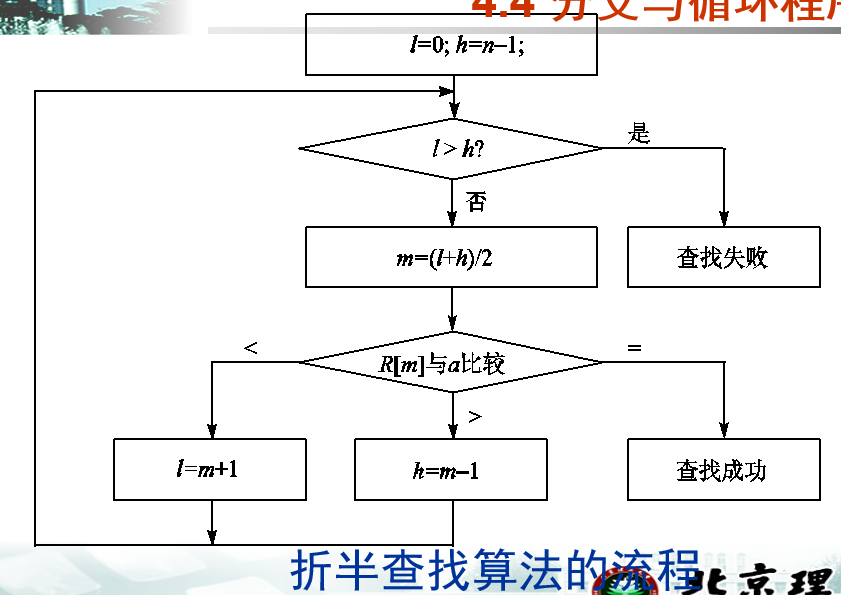
在这个流程图中没有出现循环,便于我们在汇编中实现。
PROG0505
这个程序使用了一点技巧,他专门开了一个Compare段用于执行各种各样的跳转比较,执行if elseif的多分支结构。
由此可得,在汇编中,if else(if else)这种嵌套结构和if-else if-else的实现思路还是不同的。在if–else if-else结构中,不论你开多少个分支,只需要一个Compare以及在每个分支结尾加上对应的分支结束指令即可完成任意数量的if-else if-else分支结构。
分支结束指令有两种,一种是jmp here这种写法,一般用于跳转到分支末尾。另一种是jmp compare这种写法,这其实已经是循环了。
switch
PROG0507

这个程序,先打印出提示信息,等你输入。
如果输入不在1-5之间,就非法,提示重新输入,如果在1-5之间,就用输入-1得到对应功能的索引,然后用比例变址法计算出跳转表中储存对应label的地址。然后通过内存寻址获取label值,这样就获取了对应功能的入口地址,直接jmp过去。可以合二为一,直接jmp+内存寻址。
从C语言的角度来说,跳转表其实就是一个指针数组,跳转表的label就是一个二级指针。第一次访问跳转表是获得了目标代码的label,也就是获取了一个指针,第二次用jmp去跳到label,即跳到这个指针指向的位置,这才真正执行了case的代码。
由此可得,switch本质上就是将功能编号,放到跳转表中,我们通过输入的case计算出编号,就可以直接通过switch跳转。其实中断表就是一种switch。
回顾c语言的switch,要求必须是整数或者字符,实际上,正因为switch底层要用case做跳转表索引,所以只能是整数或者字符这种离散有序的表达。
再宏观一点,其实这种跳转表的思路是被应用到很多的地方的,比如插件就对应一个插件表,环境变量PATH其实也是一个跳转表,多级寻址也是跳转表。再往深理解一点,跳转表本质上还是指针的应用,此指针并不是指C语言的指针,而是一种地址+寻址的理念,指针可以说是计算机领域乃至其他领域的灵魂,是一种哲学。
循环
loop指令
汇编中有现成的循环指令。通过loop来实现for循环。
loop示例:
mov ecx,10 ;循环10次
label:
循环体
loop label;
需要注意的是,loop会先-1,再判断结果是否等于0,等于0则不再跳转到开头。如果你ecx初始值为0,那么就会出现溢出,导致执行大量的循环。所以用loop的时候,一定要保证ecx大于0。
这里给出阶乘的程序,PROG0507
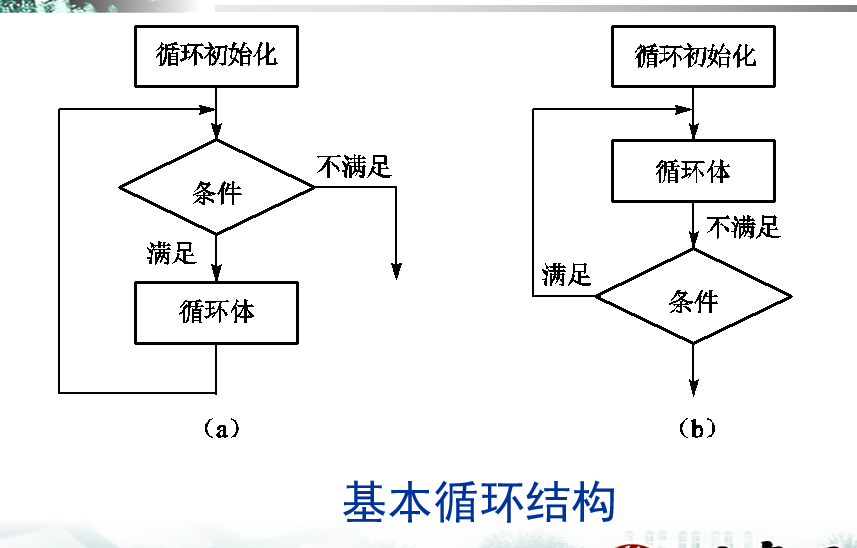
单层循环:do while、while、for
虽然有现成的指令,但是一些复杂的情况还是需要自己编写循环。
do while是最简单的循环结构:
do-while结构
start:
循环体
cmp判断
jxx start;如果满足条件,就继续跳回start部分
while通过do while修改而来。do while的执行流程是 do-判断-do-判断。如果在最开始前加一个判断,就变成了判断-do-判断-do-判断-do-判断,这就是典型的while。为了实现while,有两种思路:
- 跳过第一次do,直接跳到第一次cmp
- 在第一次do前加cmp
while ,跳到cmp例子:
jmp test
start:
do循环体
test:
cmp判断
jxx start
here:
另一种就是提前加判断:
while ,提前加判断:
cmp判断
jxx here ;这个jxx和test里的jxx要反着写
start:
do循环体
cmp判断
jxx start
here:
for循环通过while修改而得。for和while的区别就在于,for额外多了初始化和自增:
for例子:
mov ecx,4
jmp test
start:
do
自增
test:
cmp判断
jxx start
here:
嵌套循环
单层循环解决不了的事情,就用多层循环。多层循环不同于函数调用,没有默认的寄存器保护机制,自然也就没有所谓的局部变量了。所以多层循环关键在于,不能互相干扰。
为此,嵌套循环一般内层用loop,外层全部用单独的寄存器作为变量。例子如下,内层用cx+loop,外层用BL。每次进入循环之前都要先初始化循环次数:
两层循环函数DELAY:
DELAY PROC
MOV BL,20 ;置外循环次数
DELAY10:
MOV CX,2801 ;置内循环次数
WT:
;内循环执行部分
LOOP WT ;loop判断
DEC BL ;修改外循环次数
JNZ DELAY10 ;外循环控制
RET
DELAY ENDP
如果外层也用LOOP,就会出现严重问题:当内存LOOP结束,此时cx=0,然后外层loop先-1再判断,就又会跳到DELAY10处,将cx初始化,又是一轮内循环,由此就永不停歇。
如果实在想用两个cx,那就手动书写push和pop的寄存器保护即可。
浮点运算
浮点数与浮点寄存器栈

浮点数的表达是老生常谈了,有单精度1+8+32,双精度1+11+52,扩展精度1+15+63,就此略过。
在此之前,我们都是用的整数。其实浮点数运算和整数运算没太大区别,毕竟数据在计算机中的储存原理都是一样的,只是我们解释的不同罢了,你把它当浮点数,就给他用浮点数空间(4,8,10字节),以及对应的浮点数指令。
说白了,数据无非就是的储存与处理两大方面,储存就是规定了他的空间大小,处理就是使用的指令。
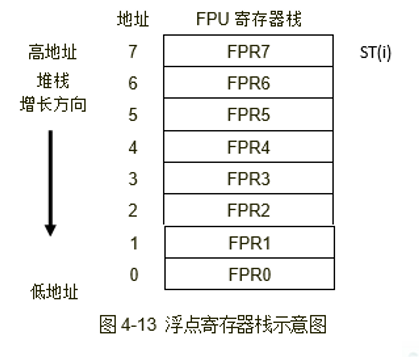
说完共性,该说特性了。浮点数有专用的寄存器,而且是排成一排的,所以又叫浮点数寄存器栈FPU。访问的时候用st(i)就相当于使用索引为i的寄存器。需要注意的是,这是一个栈,而不是数组,比如你st(0)储存了1.2,此时你再push进来一个数2.3,则1.2就会被挤到st(1)的位置,而st(0)永远代表栈顶。
示例代码1
给一个示例代码,计算表达式f=a+b*m,具体解析放在注释里。
这个程序大体展示了如何使用浮点寄存器栈,以及栈的运行规则,还有一些浮点指令。
;PROG0409.asm
.586
.model flat, stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :ptr sbyte, :VARARG
.data
szMsg byte "%f", 0ah, 0
a real8 3.2 ;real8代表8字节的浮点数,也就是double,如果是float,就用real4,扩展精度就是real10
b real8 2.6
m real8 7.1
f real8 ?
.code
start:
finit ;finit为FPU栈寄存器的初始化
fld m ;fld为浮点值入栈
fld b
fmul st(0),st(1) ;fmul为浮点数相乘,结果保存在目标操作数中
fld a
fadd st(0),st(1) ;,注意,此时a已经变成了st(0),其余两个被挤到上面去一位。fmul为浮点数相加,结果保存在目标操作数中
fst f ;fst将栈顶数据保存到内存单元
invoke printf, offset szMsg, f
ret
end start
浮点数据/指令细究
数据定义
realx中的x代表你要用的位数,也就是float还是double又或者扩展80位的浮点数。后面的立即数有多种写法,和c语言的写法基本类似。
那问题来了,real8和qword有啥区别呢?都是8字节。使用了realx,那就一定会以浮点数格式储存,但是qword不带有类型信息,怎么储存取决于你后面的立即数写法,如果是3,那就是正数,如果是3.0(3.),那就是浮点数。
a real8 3.2 ;定义64位浮点数变量a,初始化为3.2
b real10 100.25e9 ;定义80位浮点数变量b,初始化为100.25e9
c qword 3. ;定义64位浮点数变量c,初始化为3.0
d qword 3 ;定义64位整型变量d,初始化为3
寻址方式
浮点数使用浮点寄存器栈,也可以使用内存寻址。
指令
首先是数据传送。
- FLD与FST。入栈用FLD(load),出栈用FST(store)。
- FSTP。FST不等同于pop,只是将数据store到内存,并没有pop操作,所以FSTP相当于FST+POP。
- FLDPI。数据传送有一种特殊的情况,就是我们要将一些特殊常数传入栈中,比如π,我们肯定不能手写,必须用特殊指令:FLDPI加载到栈中。还有一些类似的无理数,略过。
其次是算数运算指令。
指令看起来很复杂,其实就是加减乘除4大类二元运算,就是在整数指令前加个F,每一类有5种写法:
- FADD dst,src。这是最常用的,相加,送到dst中。
- FADD src。这是次常用的,默认将结果送到s(0)中
- FADD和FADDP。这两个都会执行pop,将新的结果送到栈顶,也就是原来的st(1)
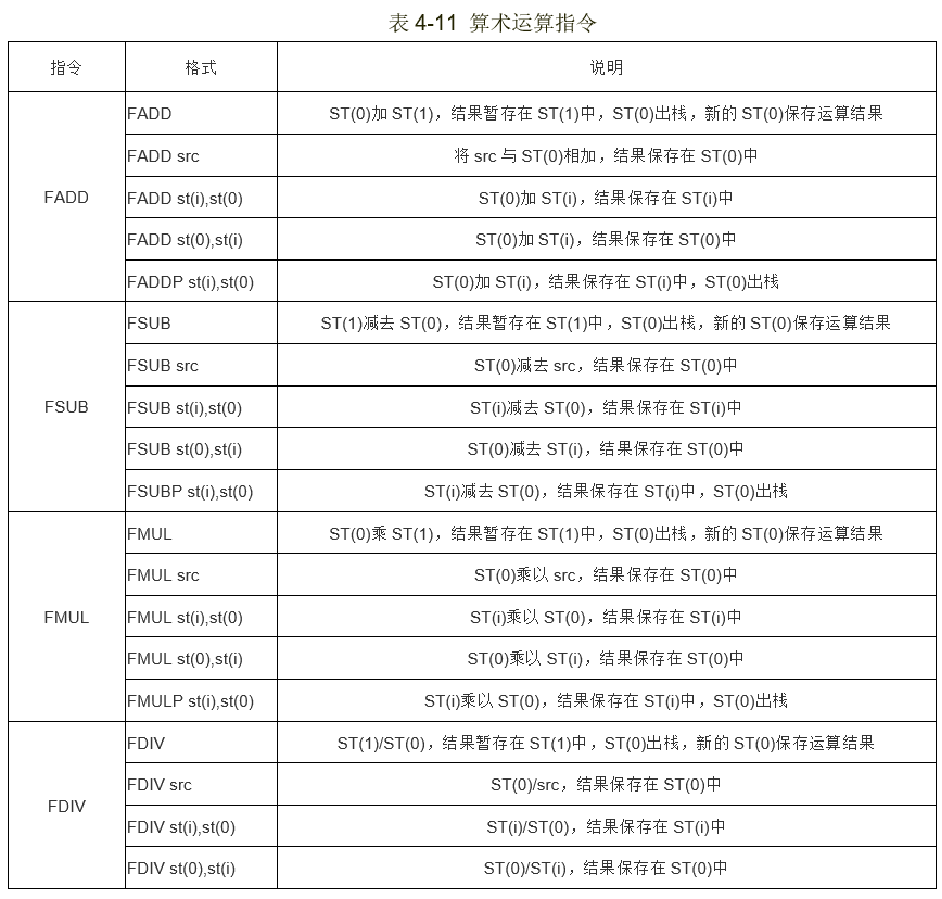
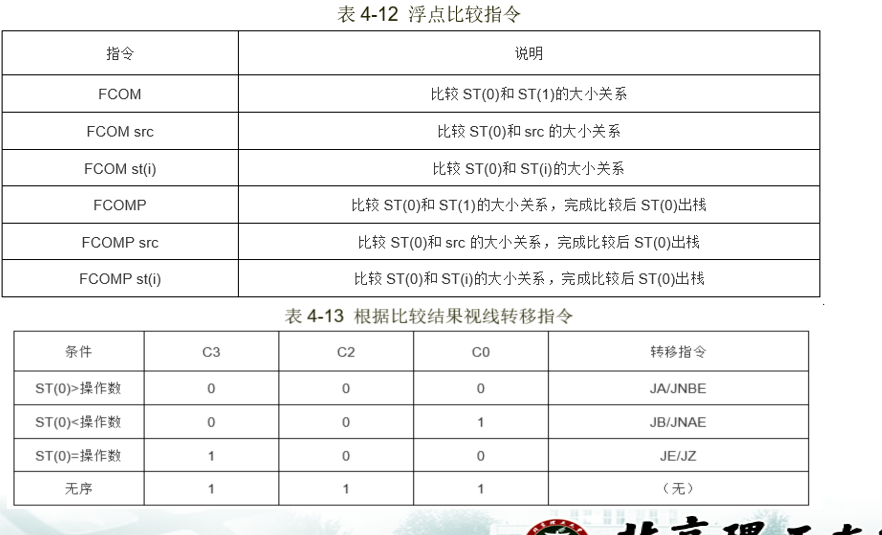
比较指令,FCOM,类似于cmp,略过。
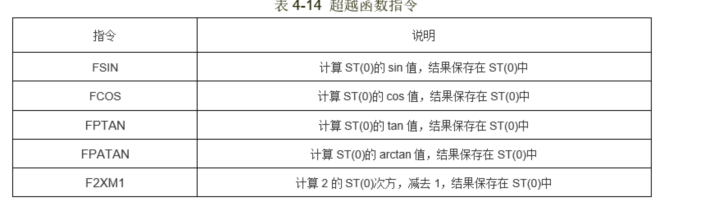
最后就是超越函数指令,其可以将st(0)变成sin(st(0)),sin,cos,tan,atan写法都一样。
示例代码2
学完指令以后,再重新做道题,思路如下:
- finit初始化
- 获取r到内存
- 将两个r压入栈,之后用fmulp,计算r方,pop掉一个r,结果存在st(0)中
- 压入一个pi,之后用fmulp,pop掉r方,将结果存在st(0)中
- fst,将结果送到内存中,之后输出。
; PROG0410.asm例4.37 输入圆的半径,计算圆面积。
.data
szMsg1 byte "%lf", 0 ;要储存到double中,所以要用lf读。
szMsg2 byte "%lf", 0ah, 0
r real8 ?;圆半径
S real8 ?;圆面积
.code
start:
finit; finit为FPU栈寄存器的初始化
invoke scanf, offset szMsg1, offset r
fld r
fld r
fmulp st(1), st(0)
fldpi
fmulp st(1), st(0)
fst S;fst将栈顶数据保存到内存单元
invoke printf, offset szMsg2, S
ret
end start
性能优化
仅做了解,不考。
时间优化
- 将费时指令转换为省时指令。比如用移位代替一部分乘法
- 分支优化。将分支转换为非分支,或者条件传送,防止流水线中出现bubble
- 提高cache命中率。尽量减少内外存交换,比如写循环的时候,外i内j比外j内i好。
空间优化
- 使用短指令。让目标代码更短。
- 使用联合。减少内存空间的占用。
子程序设计

子程序设计是手写汇编和看懂汇编结构的核心。
子程序基本知识
子程序定义
这是最基本的定义方式,这种声明仅仅告诉你这是一个子程序,并没有直接传入参数。想要传参,就要通过寄存器传参。
过程名 PROC
…
过程名 ENDP
实际上,完整的定义如下:
子程序名 PROC [C | stdcall] :[第一个参数类型] [,:后续参数类型]
- PROC表示你这是一个过程定义(声明是PROTO)
- C/STDCALL涉及到传参与清理参数
- 定义参数类型后,汇编语言就会以更加自动化的方式管理传入的参数
我们最开始仅仅是用初始定义,以便学习概念,尤其是堆栈的变化。现代程序使用的数据越来越多,传参和局部变量等等基本都是用堆栈储存,所以时刻注意堆栈的push与pop平衡是非常重要的。
实际场景中,我们定义子程序是用完整方式定义的,这就使得很多管理都是由汇编语言自动实现的,这也就是说,汇编其实相比于指令来说还是有一些抽象的,并不完全与指令一对一。我们也不会那么费劲地就用最原始方式书写。
最后,要养成时刻打注释的好习惯,包括在子程序开始也要加上功能,参数,返回的说明。
堆栈
堆栈用处很多,主要是进行先进后出的储存,其有三大特点:
- 临时性。push后pop,可见是临时储存
- 动态扩展性。push就是动态扩展,只要不爆栈,就可以一直扩展
- 快速性。?
具体到场景,堆栈有如下用途:
- 子程序调用时传递参数。现代程序基本都通过堆栈传参。
- 子程序调用和返回,保护和恢复调用现场。比如call的时候,push返回地址,刚进入子程序还要压入被调用者保护的寄存器值。子程序调用结束后,恢复被调用者保护寄存器,然后将返回地址pop到IP指针。
- 子程序局部变量,临时数据的储存。程序刚开始,处理完1,2的事情后,会再开一些空间,将局部变量放进去。
总的来说,这三个用途,归根结底就是子程序调用过程中的事情,理解堆栈与理解子程序调用是同步的。
举个例子,说明一下临时数据的用途,这个程序要求将十进制数字转换为字符串。比如8192变成“8192”。程序的思路是先对8192不断除10,取余数,这样就可以把一个数拆成4个数,按2918的顺序压入栈中,然后出栈的时候就是8192,只需要将每一次出栈的数字+'0’就可以变成字符,将这些字符依次放入szStr即可。
- szStr是存放结果的地方
- 初始化数据:8192存在eax里,先清零edx,ecx,再把ebx赋值10,这是每次除法的除数
- 入栈:每次用EDX:EAX除以EBX,EDX是余数,直接push,同时给ECX自增,记录压入几个数。之后清理一下EDX,同时判断一下是否已经除尽,如果不尽就继续除,直到商=0。将szStr地址存入EDI备用。
- 出栈:ECX已经记录了数的个数,直接用LOOP指令。每次pop,都把一个数取到EAX中,加上’0’,送到EDI中。之后EDI移动一个字节,如此循环。最后再补个\0结尾。
.data
szStr BYTE 10 DUP (0)
.code
MOV EAX, 8192
XOR EDX, EDX
XOR ECX, ECX
MOV EBX, 10
a10:
DIV EBX ;EDX:EAX除以10
PUSH EDX ;余数在EDX中, EDX压栈
INC ECX ;ECX表示压栈的次数
XOR EDX, EDX ;EDX:EAX=下一次除法的被除数
CMP EAX, EDX ;被除数=0?
JNZ a10 ;如果被除数为0,不再循环
MOV EDI, OFFSET szStr
a20:
POP EAX ;从堆栈中取出商
ADD AL, '0' ;转换为ASCII码
MOV [EDI], AL ;保存在szStr中
INC EDI
LOOP a20 ;循环处理
MOV BYTE PTR [EDI], 0
子程序的返回地址
前面说到,在栈帧构造过程(调用子程序的时候)中,先传入参数,再压入返回地址,之后进行被调用者保护,最后放入局部变量。其中,返回地址值得探讨。
到底是压入几个字节呢?这个比较玄学,下面有个调用程序,虽然是程序内调用,但是返回地址占用4字节,有两种可能,一种是EIP,另一种是CS:IP。这个不需要太注意,因为后面这些不需要你自己手动维护的。
参数传递
参数可以通过寄存器传递,也可以通过数据区的变量传递,但是,现在主流的方式已经变成了堆栈传递。
C语言函数的传参方式
从C语言这种高级语言开始,传参就都是从堆栈传递了。(在此之前,有一种做法是6个参数通过寄存器,超出的部分通过堆栈)
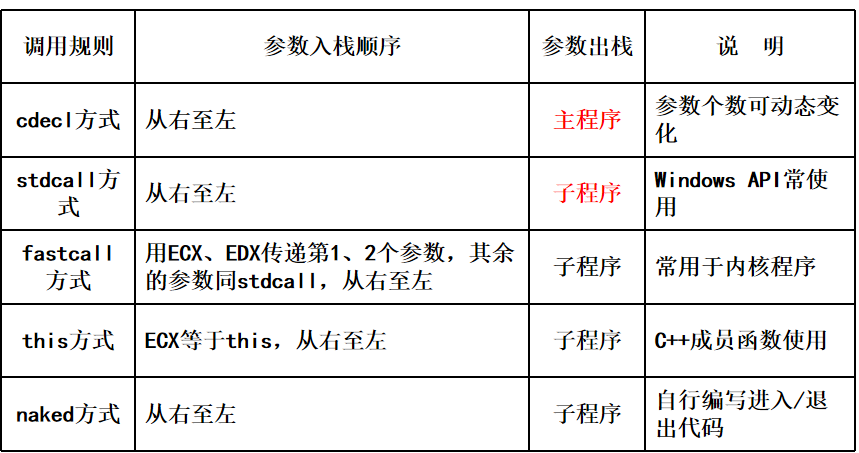
这张图给出了五种调用方式:
- 参数入栈顺序:都是从右到左送入,这样我们从栈上取参数的时候,就可以顺序取了
- 参数出栈:cdecl由调用者清理参数,子程序直接ret即可,主程序会移动esp清理栈,其他的都是子程序清理栈,经典的写法需要用ret n
- 三种特殊调用:5种调用,最主要的就是cdecl和stdcall,其他三种中:
- fastcall用两个寄存器传参,速度更快
- this调用将this指针用ECX传入
- naked略。
至于如何在C语言中告诉编译器你使用什么方式调用,可以按如下方式声明:
int _stdcall subproc(int a,int b)
汇编子程序传参方式
本节用具体的代码解释一下cdecl和stacall的区别:
;第一个子程序,使用cdecl方式调用
SubProc1 proc ;使用堆栈传递参数
push ebp
mov ebp,esp
mov eax,dword ptr [ebp+8] ;取出第1个参数
sub eax,dword ptr [ebp+12] ;取出第2个参数
pop ebp
ret
SubProc1 endp
;第二个子程序,使用stdcall方式调用
SubProc2 proc ;使用堆栈传递参数
push ebp
mov ebp,esp
mov eax,dword ptr [ebp+8] ;取出第1个参数
sub eax,dword ptr [ebp+12] ;取出第2个参数
pop ebp
ret 8 ;平衡主程序的堆栈
SubProc2 endp
start:
push 10 ;第2个参数入栈
push 20 ;第1个参数入栈
call SubProc1 ;调用子程序
add esp, 8 ;cdecl方式清理堆栈
push 100 ;第2个参数入栈
push 200 ;第1个参数入栈
call SubProc2 ;调用子程序
;stdcall方式不需要主程序清理堆栈
ret
end start
以上是cdecl的调用模式,在子程序里直接ret,在主程序中对esp进行add操作。如果是stdcall,经典写法是在子程序中ret n;主程序不进行操作。n取决于你压入栈中的参数,n最终要将压入的参数恰好清理完。如果是2个dword,那就是n=8。
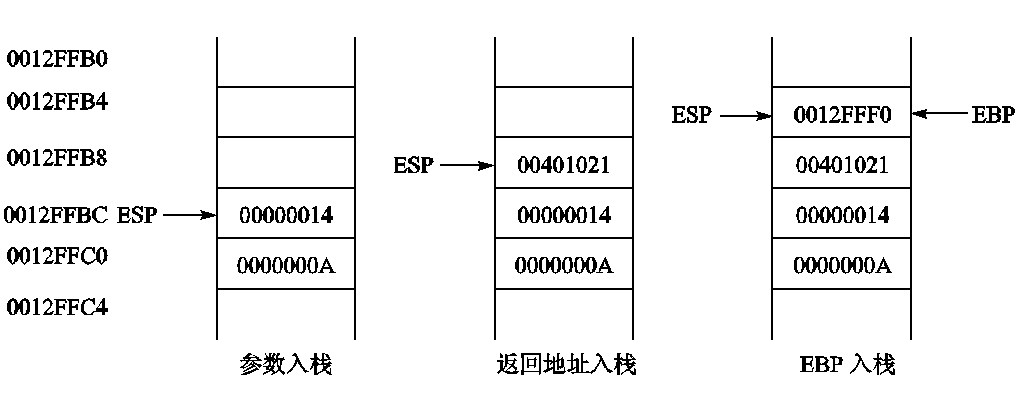
下图展示了调用过程的栈变化,先是参数压栈,之后是返回地址ESP入栈,之后是EBP的被调用者保护以及EBP重新赋值,因为没用局部变量,所以就没有再开内存了。
再给一个大点的程序,文件是.c,所以生成的汇编代码会默认使用cdecl模式调用,注释比较清楚:
//PROG0502.c
int subproc(int a, int b)
{
return a-b;
}
int r,s;
int main( )
{
r=subproc(30, 20);
s=subproc(r, -1);
}
生成的汇编代码如下:
;子程序subproc
00401000 PUSH EBP ;被调用者保护
00401001 MOV EBP,ESP ;EBP保存ESP没开局部变量内存时的初始值,后面的操作都用EBP,ESP不会轻易使用
00401003 MOV EAX,DWORD PTR [EBP+8] ;调用第一个参数需要+8,EBP占用4字节,说明返回地址占用了4字节。
00401006 SUB EAX,DWORD PTR [EBP+0CH] ;第一个参数的区间是ebp+8到ebp+11,第二个参数的区间是ebp+12到ebp+15,两个参数都是DWORD类型
00401009 POP EBP ;恢复被调用者保护
0040100A RET ;注意,直接ret只能说cdecl的可能性更大,其他调用在一定情况下也可以直接ret
;主程序
0040100B PUSH EBP ;被调用者保护
0040100C MOV EBP,ESP
0040100E PUSH 14H ;传参,默认占用4字节,int型
00401010 PUSH 1EH ;传参
00401012 CALL 00401000
00401017 ADD ESP,8 ;调用者清理栈,cdecl实锤
0040101A MOV [00405428],EAX ;r存到数据区
0040101F PUSH 0FFFFFFFFH ;压栈传参,-1
00401021 MOV EAX,[00405428]
00401026 PUSH EAX ;压栈传参
00401027 CALL 00401000
0040102C ADD ESP,8 ;清理栈
0040102F MOV [0040542C],EAX ;s存到数据区
00401034 POP EBP ;恢复被调用者保护
00401035 RET
你可能会感觉这么写很麻烦,不用担心,实际中你会通过更加高级的写法书写,编译器会自动给你生成进入(被调用者保护)和退出代码(恢复保护和ret n)。你要是就想手写,那就naked调用(这名字起的真形象)
带参数子程序定义
这一步是跨越性的。
前面说了,编译器会自动生成ret n的代码,但是你会看到,程序中还有00401003 MOV EAX,DWORD PTR [EBP+8]这种写法,这种写法也非常的费脑子,有没有一种更简单的方式呢?就是给子程序也带参数。看下面代码:
- 首先看到stacall和cdecl都是直接用ret的,不必惊讶stdcall为啥没ret n,最后汇编成指令后,SubProc2会自动变成ret n的形式。
- 其次,用了a:dword,b:dword的写法,用了这两个写法以后,子程序就不用再在esp上用偏移寻找参数了,a和b已经将栈上的参数地址记住了,a和b本质上就是var变量,对应前面的内存直接寻址法。而且子程序中也不需要写保护了,最后会自动生成指令
- 最后,主程序中也不需要你去push参数,不需要add esp了,这些维护通通在汇编后会自动生成。
可以看到,程序变得非常间接,一大堆流程用一个invoke统统搞定,而我们前面看到的那些很复杂的其实都是反汇编出来的最底层的指令。
SubProc1 proc C a:dword, b:dword ; 使用C规则
mov eax, a ; 取出第1个参数
sub eax, b ; 取出第2个参数
ret ; 返回值=a-b
SubProc1 endp
SubProc2 proc stdcall a:dword, b:dword ; 使用stdcall规则
mov eax, a ; 取出第1个参数
sub eax, b ; 取出第2个参数
ret ; 返回值=a-b
SubProc2 endp
start:
invoke SubProc1, 20, 10 ;这一步,包括了参数压栈,被调用保护,子程序处理,恢复被调用,返回,清理参数
invoke printf, offset szMsgOut, 20, 10, eax
invoke SubProc2, 200, 100
invoke printf, offset szMsgOut, 200, 100, eax
ret
end start
子程序中局部变量
这一步同样是自动化。
曾经,我们在子程序之初,需要在栈上开空间,最后还要清理局部变量,这些都需要你手动计算
现在,有了局部变量声明,我们就可以把地址的偏移直接转换成var变量的用法
LOCAL变量名1[重复数量][:类型], 变量名2[重复数量][:类型]……
LOCAL TEMP[3]:DWORD
LOCAL TEMP1, TEMP2:DWORD
注意,LOCAL伪指令必须紧接在子程序定义的伪指令PROC之后,也就是在程序之初就声明要用多少局部变量。回想C语言,我们是可以在任意地方创建局部变量的,其实这些局部变量都会被编译器转化成local声明,统一放在PROC之后。
下面程序使用了上一节的参数声明,并且使用了局部变量。
可以看到,堆栈传参和放局部变量全都变成了自动维护的情况,a,b其实在堆栈上,temp1,temp2也是堆栈上,但是他们用起来和C中的局部变量几乎一样。
注意,参数和局部变量都是栈上的,所以他们本质上还是内存寻址,所以[a]这种用法是错误的,不可以嵌套内存直接寻址,代码中先赋给eax,才能[eax]
swap proc C a:ptr dword, b:ptr dword ;使用堆栈传递参数
local temp1,temp2:dword
mov eax, a
mov ecx, [eax]
mov temp1, ecx ;temp1=*a
mov ebx, b
mov edx, [ebx]
mov temp2, edx ;temp2=*b
mov ecx, temp2
mov eax, a
mov [eax], ecx ;*a=temp2
mov ebx, b
mov edx, temp1
mov [ebx], edx ;*b=temp1
ret
swap endp
start proc
invoke printf, offset szMsgOut, r, s
invoke swap, offset r, offset s
invoke printf, offset szMsgOut, r, s
ret
start endp
end start
子程序特殊应用
子程序嵌套
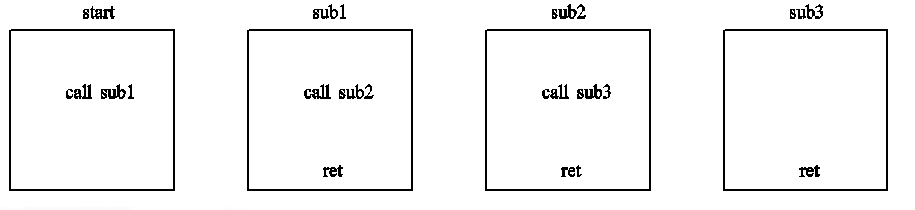
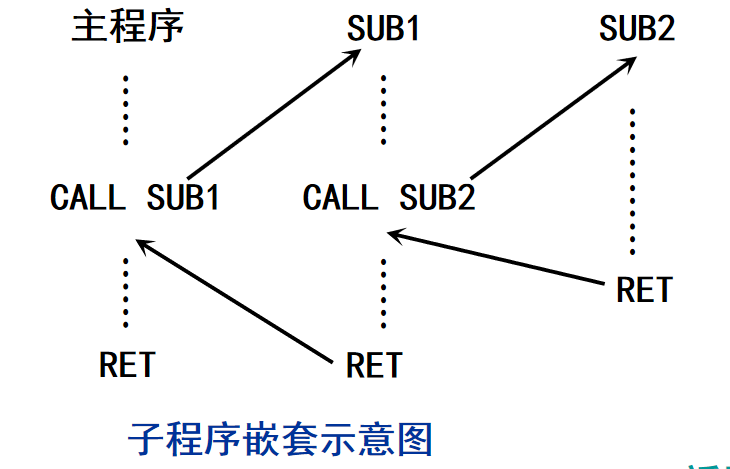
在我们使用了最简洁的写法后,子程序嵌套变得十分容易,基本和C语言一模一样,只要不爆栈,就可以随便嵌套。
子程序递归
下面的程序展示了如何实现阶乘,注意,不可以invoke factorial,n-1,因为指令中不能嵌套计算,你得先送到ebx中进行减法,再invoke。
在递归过程中,栈不断加深,直到n=1,此时赋值eax=1,然后开始回退,每次都用当前层次的n×EAX,最后的EAX就是结果。
factorial proc C n:dword
cmp n, 1
jbe exitrecurse
mov ebx, n ;EBX=n
dec ebx ;EBX=n-1
invoke factorial, ebx ;EAX=(n-1)!
imul n ;EAX=EAX * n
ret ;=(n-1)! * n=n!
exitrecurse:
mov eax, 1 ;n=1时, n!=1
ret
factorial endp
start proc
local n,f:dword
mov n, 5
invoke factorial,n;EAX=n!
mov f, eax
invoke printf, offset szOut, n, f
ret
start endp
缓冲区溢出
缓冲区溢出是最常见的安全问题,本节展示一下如何利用缓冲区溢出获得系统的控制权,总的来说,核心就是修改堆栈上的返回地址。
堆栈溢出
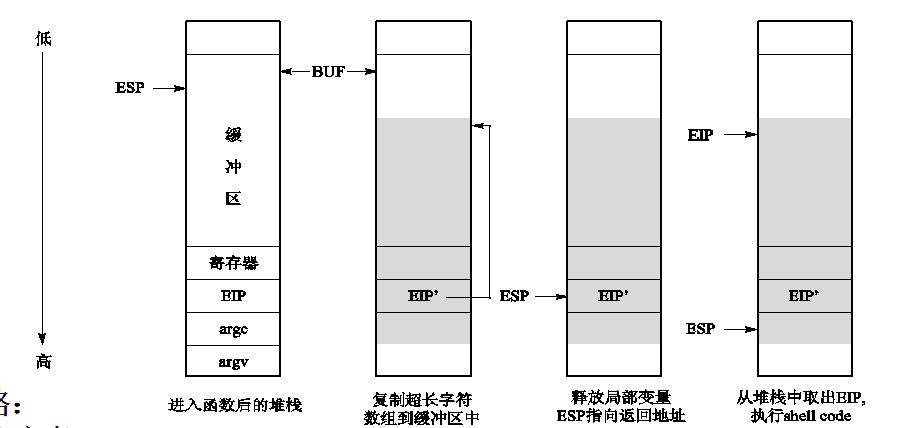
回顾一下堆栈结构,最开始是参数,然后是返回地址,之后是寄存器保护,然后就是局部变量,看这个程序:
int main(int argc, char **argv)
{
char buf [80];
strcpy(buf, argv[1]);
}
这个程序将argv[1]对应的字符串送入缓冲区中,缓冲区大小是80,假设寄存器保护的是EBP,占4字节,也就是说,ESP+84就是栈上EIP的位置。
如果我构造一个长度为88的字符串,前84个随意,最后4字节自定义一个返回地址,我此时用strcpy方法将这个字符串写入堆栈的局部变量区,前80字节会把缓冲区填满,4字节覆盖EBP,最后4字节覆盖EIP。
关键来了,在这个子程序结束后,子程序理论上应该返回调用者,但是这个EIP已经被我们篡改了,我们可以直接跳转到我们自己写的攻击程序入口,相当于我们接管了这个程序。
数据区溢出
请记住,数据溢出的核心目标就是修改EIP。看下面的程序,里面有一个call dword ptr[fn],fn本来储存的是函数f的地址,如果我们把fn那片地址空间修改了,是不是相当于把call的目标地址改成我们自己的函数了。
具体来说,scanf读取字符串送到buf里,buf有40字节,我们可以构造一个44字节的字符串。前40字节将buf覆盖,剩下的4字节用我们自己的函数的地址,这样就可以将fn覆盖掉。
;PROG0508.asm
.386
.model flat,stdcall
includelib msvcrt.lib
printf PROTO C:dword,:vararg
scanf PROTO C:dword,:vararg
.data
szMsg byte 'f is called. buf=%s', 0ah, 0
szFormat byte '%s', 0
buf byte 40 dup (0)
fn dword offset f
.code
f proc
invoke printf, offset szMsg, offset buf
ret
f endp
start:
invoke scanf, offset szFormat, offset buf
call dword ptr [fn]
invalidarg:
ret
end start
杀毒软件原理
杀毒软件有多种策略,其中杀毒软件主动防御策略如下:
将计就计用虚拟环境跑病毒,如果程序试图获取电脑控制权,就会造成虚拟环境失控。当主环境检测到虚拟环境失控,就会判定为软件是病毒。
子程序模块化设计与通信
实际中,肯定不会用一个源文件把所有代码都写了,一定是分模块的。模块之间分别编译,最后链接成一个可执行文件。
如图所示,系统由模块A、模块B、模块C组成,而模块B中的部分功能又可以进一步分解成为模块D、模块E,整个系统包括了5个模块。模块中的代码设计为子程序,能够相互进行调用。
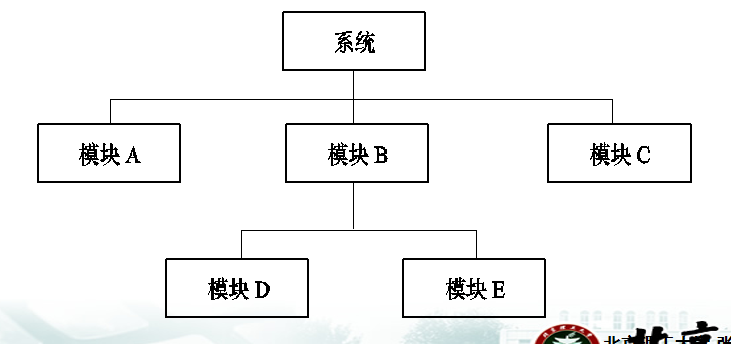
模块之间如何通信?早期是用文件,全局变量通信,这种通信很容易被干扰,破坏,现在都是用public和extrn方法通信,于此对应的,要区分定义和声明。
- 定义。规定了一个程序或者一个数据具体是什么,怎么执行的
- 声明。表明我要用某种类型的程序,但是程序在不在我这里无所谓。
public和extrn写法:
PUBLIC 名字[,…]
EXTRN 变量名:类型[,…]
子程序名 PROTO [C | stdcall] :[第一个参数类型] [,:后续参数类型]
- public和extrn必须在data区之前就写好。
- public可以对变量和函数使用,都不需要带类型。注意,变量必须是data区里的变量(有点像c语言中的全局变量),绝对不能是子程序里的局部变量
- extern只能对变量使用,不能用于函数(是不能还是像C语言一样默认extrn?TODO)
- 如果想调用其他文件的函数,就是用PROTO方法声明。注意,声明用PROTO(函数原型),定义用PROC。
回顾一下C语言的extern用法,和汇编进行对比,总的来说,C语言更开放,默认项目内所有文件全局,而汇编比较封闭,你不声明public,就只是默认文件内全局:
- c语言中没有public,但是你把数据放到全局变量区就相当于public,函数是默认public的
- 使用外部数据:C语言在其他程序中,想用全局变量就用extern声明,函数不需要用extern声明。
- 使用外部函数:汇编同C语言一样,函数声明只需要给出参数类型即可,不用写参数名字。
- 文件内全局变量:使用static声明的C语言变量,相当于汇编中data区不主动声明public的变量,仅在一个文件中具有全局特性。
下面给个例子,两个程序,一个用另一个的result数据,另一个用前一个的SubProc函数:
;PROG0509.asm
.386
.model flat,stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :dword,:vararg
SubProc PROTO stdcall :dword, :dword ; SubProc位于其他模块中
public result ;允许其他模块使用result
.data
szOutputFmtStr byte '%d?%d=%d', 0ah, 0 ;输出结果
oprd1 dword 70 ;被减数
oprd2 dword 40 ;减数
result dword ? ;差
.code
main proc C argc, argv
invoke SubProc, oprd1, oprd2 ;调用其他模块中的函数
invoke printf, offset szOutputFmtStr, \ ;输出结果
oprd1, \
oprd2, \
result ;result由SubProc设置
ret
main endp
end
;PROG0510.asm
.386
.model flat,stdcall
public SubProc ;允许其他模块调用SubProc
extrn result:dword ;result位于其他模块中
.data
.code
SubProc proc stdcall a, b ;减法函数, stdcall调用方式
mov eax, a ;参数为a,b
sub eax, b ;EAX=a-b
mov result, eax ;减法的结果保存在result中
ret 8 ;返回a-b
SubProc endp
end
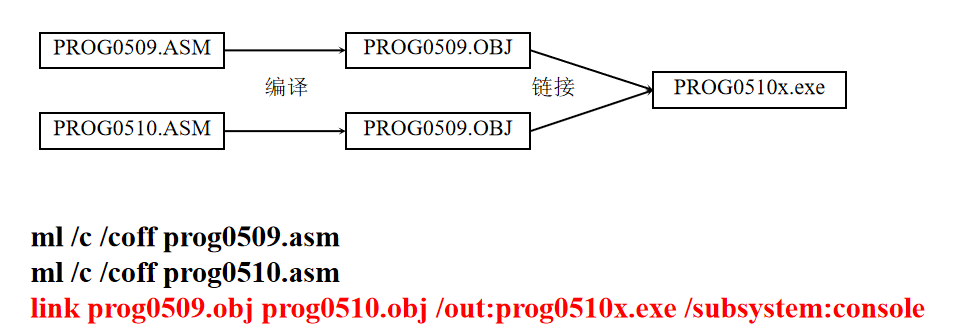
最后经过如下处理,就可以变成可执行文件。
C语言反汇编(重点)
这才是学汇编的最终目标:看懂反汇编代码。
C语言编译出来的,以及用高级方式写的汇编代码,都不是计算机最终的指令。经过汇编,变成可执行文件后,才是最终的指令,而反汇编过来的,就是这种最原始的指令结构。所以说,虽然我们不会用原始方式写汇编,但是一定要回看原始方式的汇编代码。
本节给出一些经典的汇编代码套路,其实前面的程序也给的差不多了,这里只是简单总结一下。
基本框架与栈帧
重点在于,重新审视栈帧与esp,ebp。我又打开CSAPP,从里面截了张图出来:

可以看到,栈帧构造,是先构造参数,之后压入返回地址,然后压入ebp与其他被调用者保护,最后开局部变量空间。
下图代码基本展示了这一过程。图中从29开始到36,这几句是栈上的局部变量区初始化过程。其他的就都是我们上面描述的。

最开始push ebp(被调用者保护)。需要特别注意的是那句mov ebp,esp,ebp是esp刚将ebp压入后的值,esp后面开了内存以后还会移动。我们在程序中,取参数,取局部变量都是要用ebp的,而不是esp,esp随着栈帧结构变化而变化。最后子程序结束,要恢复esp的时候会mov esp,ebp,将esp恢复到刚压入ebp的时候,之后再pop掉栈里的ebp(被调用者保护恢复)与返回。
如何用ebp取参数和局部变量呢?首先要明确栈的方向,地址减小方向是栈顶方向,也是局部变量方向。
- ebp+n是取参数,n越大,代表参数越靠后。注意,ebp取参数要跳过被调用保护寄存器和IP指针。在前面的很多程序中,IP指针一般是压EIP,占4字节,还有一个保护EBP,总计8字节,所以取的第一个参数通常是ebp+8。
- ebp-n是取局部变量。奇妙的是,局部变量也是n越大,代表声明顺序越靠后。
举个例子分析一下顺序问题:
假设有两个局部变量,两个参数,都是DWORD,那么第一个参数就是ebp+8到ebp+11,第二个参数是ebp+12到ebp+15。第一个局部变量是ebp-4到ebp-1,第二个局部变量是。ebp-8到ebp-5。总之就是,越靠近ebp的,就越是先定义的,绝。
选择结构
这个就是典型的if-else结构,判断条件反写,如果满足反写条件,就跳转到else部分,否则执行if部分,在if部分结尾添加jmp here跳到分支结尾。
这个程序在每个分支都要调用一下函数,invoke伪指令翻译过来变成底层代码就是push+call+清理栈空间。

循环结构
i是局部变量,存在栈中ebp-4的位置,区间为ebp-4到ebp-1。
这个for循环是基于while循环的,while循环采用了直接跳转到测试部分的方案,绿色部分第一句就是跳转到cmp部分。绿色部分剩下三句执行的是i++操作,需要先取出来,自增,再放回内存。
理论上,这三句可以直接用add dword ptr [ebp-4],1合并,立即数+内存的组合是符合流水线要求的。

变量定义
这一部分对应前面的模块间通信。其中提到三类变量,C语言和汇编中是一一对应的:
- 全局。C语言直接声明,汇编中用_i1这种带下划线的标号,且要public声明
- 静态全局。C语言中加static,汇编中用i2这种正常标号,放在程序data段
- 局部变量。C语言中在函数中声明,汇编中使用ebp进行偏移寻址。
可以看到,静态全局和全局变量的位置并不是连续的。

指针
汇编中的指针和变量没什么区别,只不过是储存了地址的变量罢了。
下面的程序中,有两个局部变量,一个是a,另一个是p。a因为声明在后,所以是ebp-8(n比较大),p声明较早,所以是ebp-4。变量赋值是mov,指针赋值要取地址,所以用lea(理论上也可以用offset,但是底层汇编代码是没有offset这种伪指令的)
这里就比较有意思了,指针竟然只有4个字节,我们C语言里指针不是8字节吗?不必惊讶,指针储存地址,而地址空间本身就和计算机密切相关,在32位机器里,指针长度就是4字节,64位机器(我们现在都是)里就是8字节。你的C语言是跑在64位机器上的,所以指针是8字节,而你的汇编是跑在masm32保护模式下的,所以是4字节。

函数
这是一段主程序,可以一眼看到有两个call,call后还有add esp,8。说明传入了8字节的参数,而且是cdecl调用。
在调用之前会有两个push,所以我们也可以很轻松的算出传入的参数是多少。

跟着地址看一眼子程序,一般看到ebp+8这种,你就知道这是在取参数了,所以大概率就是一个子程序的初始部分。

最后看看输出部分的汇编代码。可以看到,三个参数是从右往左倒着push的。
最后add esp,0ch。12对应三个4字节参数。

C语言汇编混合编程
一路学下来,你会感觉到C语言非常底层,在某些方面往往和汇编有着非常接近的对应关系。因此,C语言和汇编能混合编程也就不足为奇了。
- 当C语言需要更有效率的优化,或者要求直接控制硬件,就需要加汇编
- 当汇编需要完成一些复杂的任务,就需要调用更高级的C语言
这一部分在实践中有用,但是这里仅做了解:
- C中加汇编——内联嵌入。使用_asm{汇编代码}直接嵌入
- 互相调用。C函数和汇编子程序可以互相用对方的变量,函数
- C++与汇编联合编程。略
北京理工大学汇编大作业:坦克大战魔改版
汇编要做游戏,我们想了很多游戏,有的像贪吃蛇,2048这种,都已经被做烂了,就算了,有的游戏有点脑残,也算了,后面机缘巧合,一边讨论游戏,一边扯犊子,我突然想到是不是可以做坦克大战,一搜,果然做的人很少,于是就开始搞坦克大战了。
我们做的相对比较基础,为了追求挑战性,没有采用诸如invoke之类的伪指令,而是通过栈来进行参数传递。可以说,这个坦克大战非常有意思,扩展性很强,可以加各种规则,后续甚至可以考虑替换资源,做成Q版泡泡堂。还可以把指令改成invoke型的,拆分多个文件,提高可读性。
TODO:详见github。