介绍 plugin
插件系统是 Webpack 成功的一个关键性因素。在编译的整个生命周期中,Webpack 会触发许多事件钩子,Plugin 可以监听这些事件,根据需求在相应的时间点对打包内容进行定向的修改。
一个最简单的 plugin 是这样的:
class Plugin{
// 注册插件时,会调用 apply 方法
// apply 方法接收 compiler 对象
// 通过 compiler 上提供的 Api,可以对事件进行监听,执行相应的操作
apply(compiler){
// compilation 是监听每次编译循环
// 每次文件变化,都会生成新的 compilation 对象并触发该事件
compiler.plugin('compilation',function(compilation) {})
}
}
注册插件:
// webpack.config.js
module.export = {
plugins:[
new Plugin(options),
]
}
事件流机制:
Webpack 就像工厂中的一条产品流水线。原材料经过 Loader 与 Plugin 的一道道处理,最后输出结果。
- 通过链式调用,按顺序串起一个个 Loader;
- 通过事件流机制,让 Plugin 可以插入到整个生产过程中的每个步骤中;
Webpack 事件流编程范式的核心是基础类 Tapable,是一种 观察者模式 的实现事件的订阅与广播:
const { SyncHook } = require("tapable")
const hook = new SyncHook(['arg'])
// 订阅
hook.tap('event', (arg) => {
// 'event-hook'
console.log(arg)
})
// 广播
hook.call('event-hook')
Webpack中两个最重要的类Compiler与Compilation便是继承于Tapable,也拥有这样的事件流机制。
- Compiler : 可以简单的理解为 Webpack 实例,它包含了当前 Webpack 中的所有配置信息,如 options, loaders, plugins 等信息,全局唯一,只在启动时完成初始化创建,随着生命周期逐一传递;
Compilation: 可以称为 编译实例。当监听到文件发生改变时,Webpack 会创建一个新的 Compilation 对象,开始一次新的编译。它包含了当前的输入资源,输出资源,变化的文件等,同时通过它提供的 api,可以监听每次编译过程中触发的事件钩子;- 区别:
Compiler全局唯一,且从启动生存到结束;Compilation对应每次编译,每轮编译循环均会重新创建;
- 常用 Plugin:
- UglifyJsPlugin: 压缩、混淆代码;
- CommonsChunkPlugin: 代码分割;
- ProvidePlugin: 自动加载模块;
- html-webpack-plugin: 加载 html 文件,并引入 css / js 文件;
- extract-text-webpack-plugin / mini-css-extract-plugin: 抽离样式,生成 css 文件; DefinePlugin: 定义全局变量;
- optimize-css-assets-webpack-plugin: CSS 代码去重;
- webpack-bundle-analyzer: 代码分析;
- compression-webpack-plugin: 使用 gzip 压缩 js 和 css;
- happypack: 使用多进程,加速代码构建;
- EnvironmentPlugin: 定义环境变量;
- 调用插件
apply函数传入compiler对象 - 通过
compiler对象监听事件
loader和plugin有什么区别?
webapck默认只能打包JS和JOSN模块,要打包其它模块,需要借助loader,loader就可以让模块中的内容转化成webpack或其它laoder可以识别的内容。
loader就是模块转换化,或叫加载器。不同的文件,需要不同的loader来处理。plugin是插件,可以参与到整个webpack打包的流程中,不同的插件,在合适的时机,可以做不同的事件。
webpack中都有哪些插件,这些插件有什么作用?
html-webpack-plugin自动创建一个HTML文件,并把打包好的JS插入到HTML文件中clean-webpack-plugin在每一次打包之前,删除整个输出文件夹下所有的内容mini-css-extrcat-plugin抽离CSS代码,放到一个单独的文件中optimize-css-assets-plugin压缩css
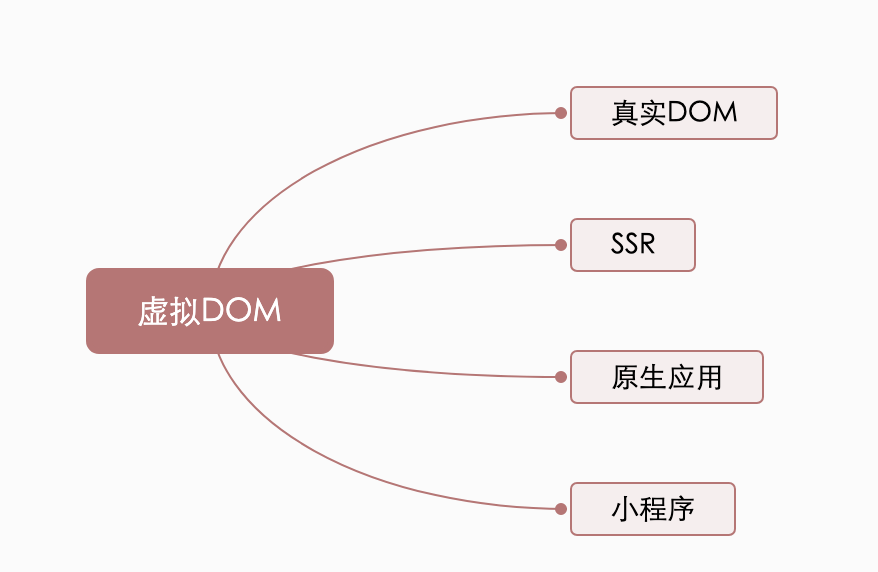
为什么使用 Virtual DOM
- 手动操作
DOM比较麻烦,还需要考虑浏览器兼容性问题,虽然有jQuery等库简化DOM操作,但是随着项目的复杂 DOM 操作复杂提升 - 为了简化
DOM的复杂操作于是出现了各种MVVM框架,MVVM框架解决了视图和状态的同步问题 - 为了简化视图的操作我们可以使用模板引擎,但是模板引擎没有解决跟踪状态变化的问题,于是
Virtual DOM出现了 Virtual DOM的好处是当状态改变时不需要立即更新 DOM,只需要创建一个虚拟树来描述DOM,Virtual DOM内部将弄清楚如何有效(diff)的更新DOM- 虚拟
DOM可以维护程序的状态,跟踪上一次的状态 - 通过比较前后两次状态的差异更新真实
DOM
虚拟 DOM 的作用
- 维护视图和状态的关系
- 复杂视图情况下提升渲染性能
- 除了渲染
DOM以外,还可以实现SSR(Nuxt.js/Next.js)、原生应用(Weex/React Native)、小程序(mpvue/uni-app)等
Generator
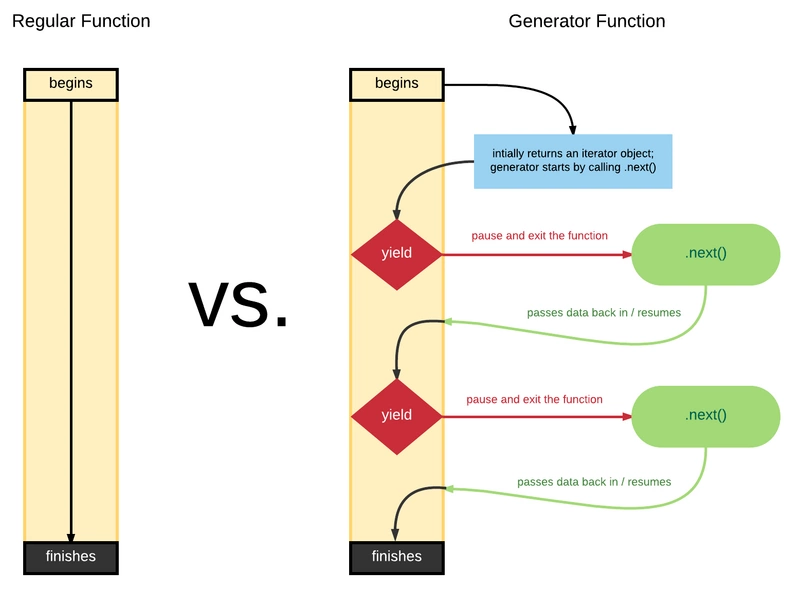
Generator是ES6中新增的语法,和Promise一样,都可以用来异步编程。Generator函数可以说是Iterator接口的具体实现方式。Generator 最大的特点就是可以控制函数的执行。
function*用来声明一个函数是生成器函数,它比普通的函数声明多了一个*,*的位置比较随意可以挨着function关键字,也可以挨着函数名yield产出的意思,这个关键字只能出现在生成器函数体内,但是生成器中也可以没有yield关键字,函数遇到yield的时候会暂停,并把yield后面的表达式结果抛出去next作用是将代码的控制权交还给生成器函数
function *foo(x) {
let y = 2 * (yield (x + 1))
let z = yield (y / 3)
return (x + y + z)
}
let it = foo(5)
console.log(it.next()) // => {value: 6, done: false}
console.log(it.next(12)) // => {value: 8, done: false}
console.log(it.next(13)) // => {value: 42, done: true}
上面这个示例就是一个Generator函数,我们来分析其执行过程:
- 首先 Generator 函数调用时它会返回一个迭代器
- 当执行第一次 next 时,传参会被忽略,并且函数暂停在 yield (x + 1) 处,所以返回 5 + 1 = 6
- 当执行第二次 next 时,传入的参数等于上一个 yield 的返回值,如果你不传参,yield 永远返回 undefined。此时 let y = 2 * 12,所以第二个 yield 等于 2 * 12 / 3 = 8
- 当执行第三次 next 时,传入的参数会传递给 z,所以 z = 13, x = 5, y = 24,相加等于 42
yield实际就是暂缓执行的标示,每执行一次next(),相当于指针移动到下一个yield位置
总结一下 ,
Generator函数是ES6提供的一种异步编程解决方案。通过yield标识位和next()方法调用,实现函数的分段执行
遍历器对象生成函数,最大的特点是可以交出函数的执行权
function关键字与函数名之间有一个星号;- 函数体内部使用
yield表达式,定义不同的内部状态; next指针移向下一个状态
这里你可以说说
Generator的异步编程,以及它的语法糖async和awiat,传统的异步编程。ES6之前,异步编程大致如下
- 回调函数
- 事件监听
- 发布/订阅
传统异步编程方案之一:协程,多个线程互相协作,完成异步任务。
// 使用 * 表示这是一个 Generator 函数
// 内部可以通过 yield 暂停代码
// 通过调用 next 恢复执行
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }
从以上代码可以发现,加上
*的函数执行后拥有了next函数,也就是说函数执行后返回了一个对象。每次调用next函数可以继续执行被暂停的代码。以下是Generator函数的简单实现
// cb 也就是编译过的 test 函数
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// 如果你使用 babel 编译后可以发现 test 函数变成了这样
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以发现通过 yield 将代码分割成几块
// 每次执行 next 函数就执行一块代码
// 并且表明下次需要执行哪块代码
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// 执行完毕
case 6:
case "end":
return _context.stop();
}
}
});
}
Vue 响应式原理
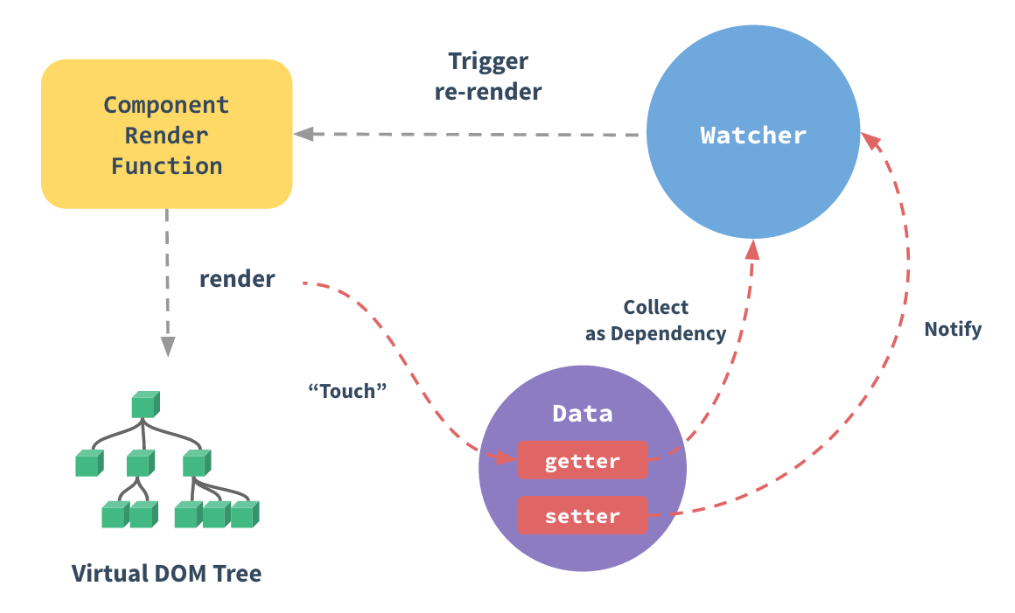
Vue 的响应式原理是核心是通过 ES5 的保护对象的
Object.defindeProperty中的访问器属性中的 get 和 set 方法,data 中声明的属性都被添加了访问器属性,当读取 data 中的数据时自动调用 get 方法,当修改 data 中的数据时,自动调用 set 方法,检测到数据的变化,会通知观察者 Wacher,观察者 Wacher自动触发重新render 当前组件(子组件不会重新渲染),生成新的虚拟 DOM 树,Vue 框架会遍历并对比新虚拟 DOM 树和旧虚拟 DOM 树中每个节点的差别,并记录下来,最后,加载操作,将所有记录的不同点,局部修改到真实 DOM树上。
- 虚拟DOM (Virtaul DOM): 用 js 对象模拟的,保存当前视图内所有 DOM 节点对象基本描述属性和节点间关系的树结构。用 js 对象,描述每个节点,及其父子关系,形成虚拟 DOM 对象树结构。
- 因为只要在
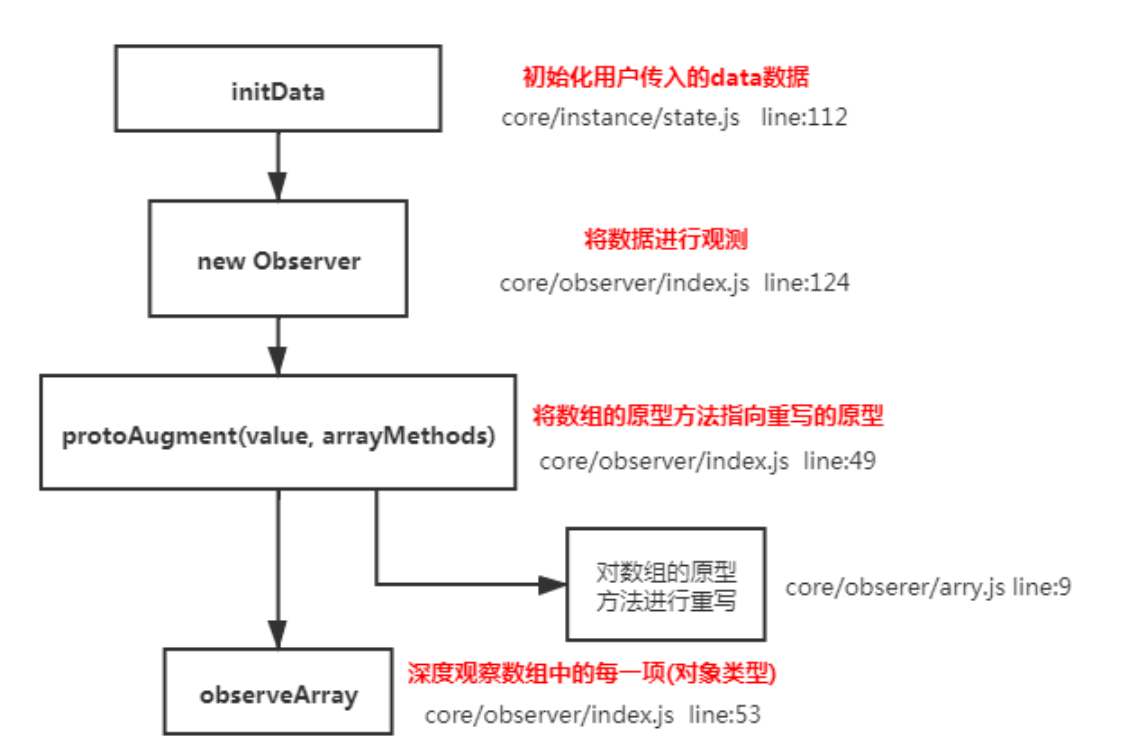
data中声明的基本数据类型的数据,基本不存在数据不响应问题,所以重点介绍数组和对象在vue中的数据响应问题,vue可以检测对象属性的修改,但无法监听数组的所有变动及对象的新增和删除,只能使用数组变异方法及$set方法。
可以看到,
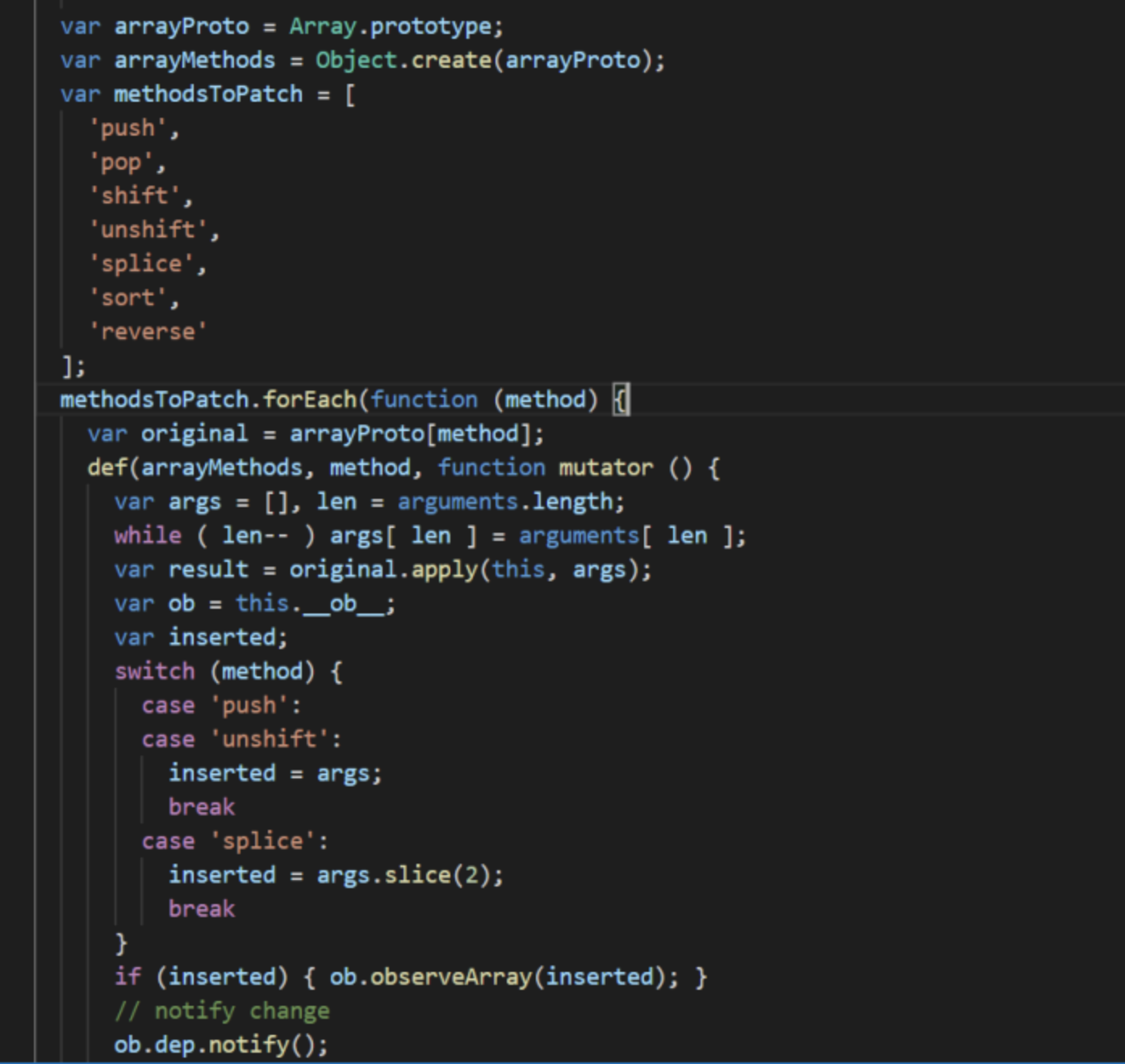
arrayMethods首先继承了Array,然后对数组中所有能改变数组自身的方法,如push、pop等这些方法进行重写。重写后的方法会先执行它们本身原有的逻辑,并对能增加数组长度的 3 个方法push、unshift、splice方法做了判断,获取到插入的值,然后把新添加的值变成一个响应式对象,并且再调用ob.dep.notify()手动触发依赖通知,这就很好地解释了用vm.items.splice(newLength) 方法可以检测到变化
总结:Vue 采用数据劫持结合发布—订阅模式的方法,通过
Object.defineProperty()来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
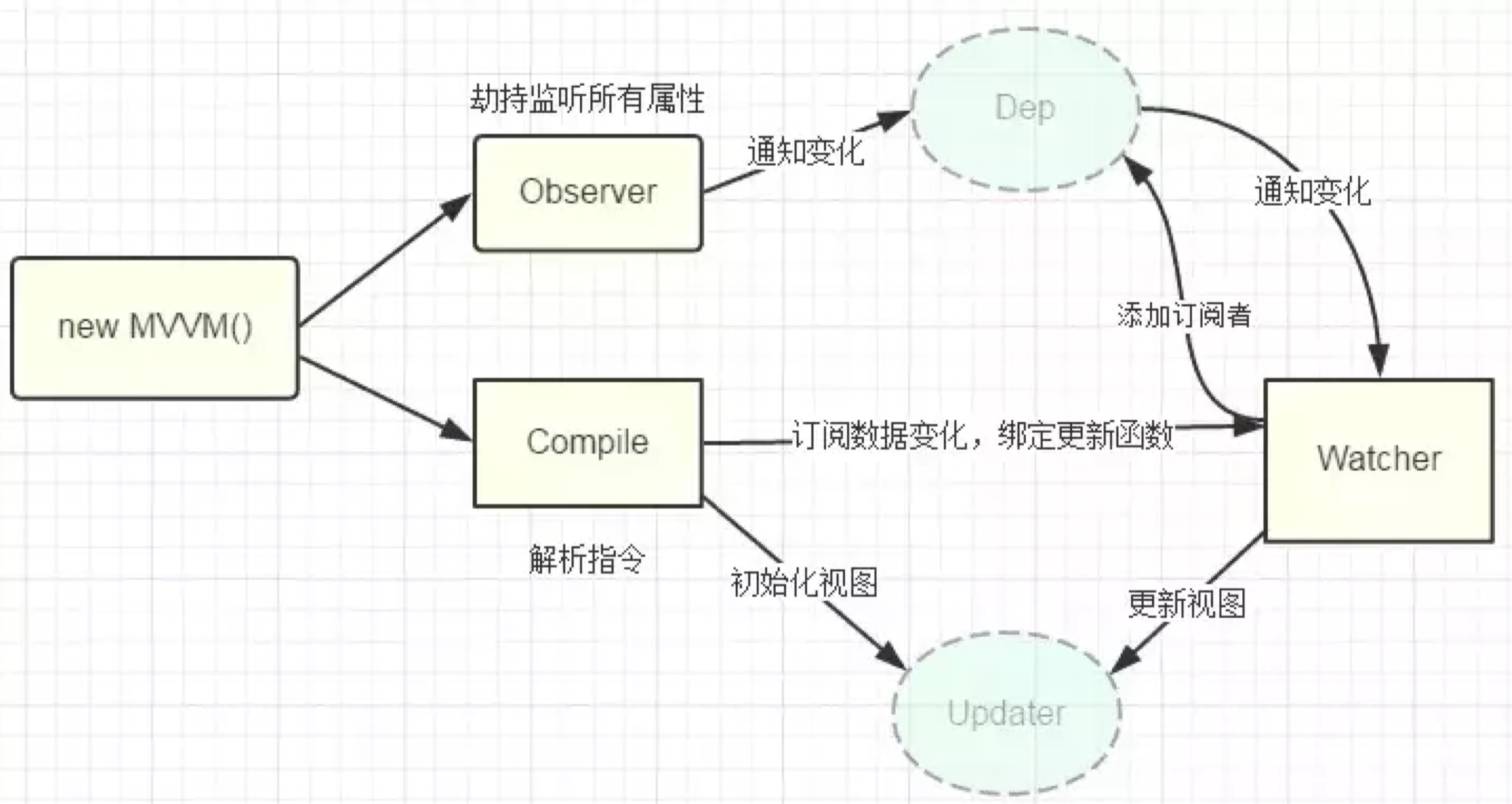
Observer遍历数据对象,给所有属性加上setter和getter,监听数据的变化compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情
- 在自身实例化时往属性订阅器 (
dep) 里面添加自己 - 待属性变动
dep.notice()通知时,调用自身的update()方法,并触发Compile中绑定的回调
Object.defineProperty() ,那么它的用法是什么,以及优缺点是什么呢?
- 可以检测对象中数据发生的修改
- 对于复杂的对象,层级很深的话,是不友好的,需要经行深度监听,这样子就需要递归到底,这也是它的缺点。
- 对于一个对象中,如果你新增加属性,删除属性,**Object.defineProperty()**是不能观测到的,那么应该如何解决呢?可以通过
Vue.set()和Vue.delete()来实现。
// 模拟 Vue 中的 data 选项
let data = {
msg: 'hello'
}
// 模拟 Vue 的实例
let vm = {}
// 数据劫持:当访问或者设置 vm 中的成员的时候,做一些干预操作
Object.defineProperty(vm, 'msg', {
// 可枚举(可遍历)
enumerable: true,
// 可配置(可以使用 delete 删除,可以通过 defineProperty 重新定义)
configurable: true,
// 当获取值的时候执行
get () {
console.log('get: ', data.msg)
return data.msg
},
// 当设置值的时候执行
set (newValue) {
console.log('set: ', newValue)
if (newValue === data.msg) {
return
}
data.msg = newValue
// 数据更改,更新 DOM 的值
document.querySelector('#app').textContent = data.msg
}
})
// 测试
vm.msg = 'Hello World'
console.log(vm.msg)
Vue3.x响应式数据原理
Vue3.x改用Proxy替代Object.defineProperty。因为Proxy可以直接监听对象和数组的变化,并且有多达13种拦截方法。并且作为新标准将受到浏览器厂商重点持续的性能优化。
Proxy只会代理对象的第一层,那么Vue3又是怎样处理这个问题的呢?
判断当前
Reflect.get的返回值是否为Object,如果是则再通过reactive方法做代理, 这样就实现了深度观测。
监测数组的时候可能触发多次get/set,那么如何防止触发多次呢?
我们可以判断
key是否为当前被代理对象target自身属性,也可以判断旧值与新值是否相等,只有满足以上两个条件之一时,才有可能执行trigger
// 模拟 Vue 中的 data 选项
let data = {
msg: 'hello',
count: 0
}
// 模拟 Vue 实例
let vm = new Proxy(data, {
// 当访问 vm 的成员会执行
get (target, key) {
console.log('get, key: ', key, target[key])
return target[key]
},
// 当设置 vm 的成员会执行
set (target, key, newValue) {
console.log('set, key: ', key, newValue)
if (target[key] === newValue) {
return
}
target[key] = newValue
document.querySelector('#app').textContent = target[key]
}
})
// 测试
vm.msg = 'Hello World'
console.log(vm.msg)
Proxy 相比于 defineProperty 的优势
- 数组变化也能监听到
- 不需要深度遍历监听
Proxy是ES6中新增的功能,可以用来自定义对象中的操作
let p = new Proxy(target, handler);
// `target` 代表需要添加代理的对象
// `handler` 用来自定义对象中的操作
// 可以很方便的使用 Proxy 来实现一个数据绑定和监听
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
总结

- Vue
- 记录传入的选项,设置
$data/$el - 把
data的成员注入到Vue实例 - 负责调用
Observer实现数据响应式处理(数据劫持) - 负责调用
Compiler编译指令/插值表达式等
- 记录传入的选项,设置
Observer- 数据劫持
- 负责把
data中的成员转换成getter/setter - 负责把多层属性转换成
getter/setter - 如果给属性赋值为新对象,把新对象的成员设置为
getter/setter
- 负责把
- 添加
Dep和Watcher的依赖关系 - 数据变化发送通知
- 数据劫持
Compiler- 负责编译模板,解析指令/插值表达式
- 负责页面的首次渲染过程
- 当数据变化后重新渲染
Dep- 收集依赖,添加订阅者(
watcher) - 通知所有订阅者
- 收集依赖,添加订阅者(
Watcher- 自身实例化的时候往
dep对象中添加自己 - 当数据变化
dep通知所有的Watcher实例更新视图
- 自身实例化的时候往
类型及检测方式
1. JS内置类型
JavaScript 的数据类型有下图所示

其中,前 7 种类型为基础类型,最后
1 种(Object)为引用类型,也是你需要重点关注的,因为它在日常工作中是使用得最频繁,也是需要关注最多技术细节的数据类型
JavaScript一共有8种数据类型,其中有7种基本数据类型:Undefined、Null、Boolean、Number、String、Symbol(es6新增,表示独一无二的值)和BigInt(es10新增);- 1种引用数据类型——
Object(Object本质上是由一组无序的名值对组成的)。里面包含function、Array、Date等。JavaScript不支持任何创建自定义类型的机制,而所有值最终都将是上述 8 种数据类型之一。- 引用数据类型: 对象
Object(包含普通对象-Object,数组对象-Array,正则对象-RegExp,日期对象-Date,数学函数-Math,函数对象-Function)
- 引用数据类型: 对象
在这里,我想先请你重点了解下面两点,因为各种 JavaScript 的数据类型最后都会在初始化之后放在不同的内存中,因此上面的数据类型大致可以分成两类来进行存储:
- 原始数据类型 :基础类型存储在栈内存,被引用或拷贝时,会创建一个完全相等的变量;占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储。
- 引用数据类型 :引用类型存储在堆内存,存储的是地址,多个引用指向同一个地址,这里会涉及一个“共享”的概念;占据空间大、大小不固定。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
JavaScript 中的数据是如何存储在内存中的?
在 JavaScript 中,原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址。
在 JavaScript 的执行过程中, 主要有三种类型内存空间,分别是代码空间、栈空间、堆空间。其中的代码空间主要是存储可执行代码的,原始类型(Number、String、Null、Undefined、Boolean、Symbol、BigInt)的数据值都是直接保存在“栈”中的,引用类型(Object)的值是存放在“堆”中的。因此在栈空间中(执行上下文),原始类型存储的是变量的值,而引用类型存储的是其在"堆空间"中的地址,当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。
在编译过程中,如果 JavaScript 引擎判断到一个闭包,也会在堆空间创建换一个“closure(fn)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存闭包中的变量。所以闭包中的变量是存储在“堆空间”中的。
JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。因此需要“栈”和“堆”两种空间。
题目一:初出茅庐
let a = {
name: 'lee',
age: 18
}
let b = a;
console.log(a.name); //第一个console
b.name = 'son';
console.log(a.name); //第二个console
console.log(b.name); //第三个console
这道题比较简单,我们可以看到第一个 console 打出来 name 是 ‘lee’,这应该没什么疑问;但是在执行了 b.name=‘son’ 之后,结果你会发现 a 和 b 的属性 name 都是 ‘son’,第二个和第三个打印结果是一样的,这里就体现了引用类型的“共享”的特性,即这两个值都存在同一块内存中共享,一个发生了改变,另外一个也随之跟着变化。
你可以直接在 Chrome 控制台敲一遍,深入理解一下这部分概念。下面我们再看一段代码,它是比题目一稍复杂一些的对象属性变化问题。
题目二:渐入佳境
let a = {
name: 'Julia',
age: 20
}
function change(o) {
o.age = 24;
o = {
name: 'Kath',
age: 30
}
return o;
}
let b = change(a); // 注意这里没有new,后面new相关会有专门文章讲解
console.log(b.age); // 第一个console
console.log(a.age); // 第二个console
这道题涉及了 function,你通过上述代码可以看到第一个 console 的结果是 30,b 最后打印结果是 {name: "Kath", age: 30};第二个 console 的返回结果是 24,而 a 最后的打印结果是 {name: "Julia", age: 24}。
是不是和你预想的有些区别?你要注意的是,这里的 function 和 return 带来了不一样的东西。
原因在于:函数传参进来的
o,传递的是对象在堆中的内存地址值,通过调用o.age = 24(第 7 行代码)确实改变了a对象的age属性;但是第 12 行代码的return却又把o变成了另一个内存地址,将{name: "Kath", age: 30}存入其中,最后返回b的值就变成了{name: "Kath", age: 30}。而如果把第 12 行去掉,那么b就会返回undefined
2. 数据类型检测
(1)typeof
typeof 对于原始类型来说,除了 null 都可以显示正确的类型
console.log(typeof 2); // number
console.log(typeof true); // boolean
console.log(typeof 'str'); // string
console.log(typeof []); // object []数组的数据类型在 typeof 中被解释为 object
console.log(typeof function(){}); // function
console.log(typeof {}); // object
console.log(typeof undefined); // undefined
console.log(typeof null); // object null 的数据类型被 typeof 解释为 object
typeof对于对象来说,除了函数都会显示object,所以说typeof并不能准确判断变量到底是什么类型,所以想判断一个对象的正确类型,这时候可以考虑使用instanceof
(2)instanceof
instanceof可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链中是不是能找到类型的prototype
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log('str' instanceof String); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); // true
// console.log(undefined instanceof Undefined);
// console.log(null instanceof Null);
instanceof可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型;- 而
typeof也存在弊端,它虽然可以判断基础数据类型(null除外),但是引用数据类型中,除了function类型以外,其他的也无法判断
// 我们也可以试着实现一下 instanceof
function _instanceof(left, right) {
// 由于instance要检测的是某对象,需要有一个前置判断条件
//基本数据类型直接返回false
if(typeof left !== 'object' || left === null) return false;
// 获得类型的原型
let prototype = right.prototype
// 获得对象的原型
left = left.__proto__
// 判断对象的类型是否等于类型的原型
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
console.log('test', _instanceof(null, Array)) // false
console.log('test', _instanceof([], Array)) // true
console.log('test', _instanceof('', Array)) // false
console.log('test', _instanceof({}, Object)) // true
(3)constructor
console.log((2).constructor === Number); // true
console.log((true).constructor === Boolean); // true
console.log(('str').constructor === String); // true
console.log(([]).constructor === Array); // true
console.log((function() {}).constructor === Function); // true
console.log(({}).constructor === Object); // true
这里有一个坑,如果我创建一个对象,更改它的原型,
constructor就会变得不可靠了
function Fn(){};
Fn.prototype=new Array();
var f=new Fn();
console.log(f.constructor===Fn); // false
console.log(f.constructor===Array); // true
(4)Object.prototype.toString.call()
toString()是Object的原型方法,调用该方法,可以统一返回格式为“[object Xxx]”的字符串,其中Xxx就是对象的类型。对于Object对象,直接调用toString()就能返回[object Object];而对于其他对象,则需要通过call来调用,才能返回正确的类型信息。我们来看一下代码。
Object.prototype.toString({}) // "[object Object]"
Object.prototype.toString.call({}) // 同上结果,加上call也ok
Object.prototype.toString.call(1) // "[object Number]"
Object.prototype.toString.call('1') // "[object String]"
Object.prototype.toString.call(true) // "[object Boolean]"
Object.prototype.toString.call(function(){}) // "[object Function]"
Object.prototype.toString.call(null) //"[object Null]"
Object.prototype.toString.call(undefined) //"[object Undefined]"
Object.prototype.toString.call(/123/g) //"[object RegExp]"
Object.prototype.toString.call(new Date()) //"[object Date]"
Object.prototype.toString.call([]) //"[object Array]"
Object.prototype.toString.call(document) //"[object HTMLDocument]"
Object.prototype.toString.call(window) //"[object Window]"
// 从上面这段代码可以看出,Object.prototype.toString.call() 可以很好地判断引用类型,甚至可以把 document 和 window 都区分开来。
实现一个全局通用的数据类型判断方法,来加深你的理解,代码如下
function getType(obj){
let type = typeof obj;
if (type !== "object") { // 先进行typeof判断,如果是基础数据类型,直接返回
return type;
}
// 对于typeof返回结果是object的,再进行如下的判断,正则返回结果
return Object.prototype.toString.call(obj).replace(/^\[object (\S+)\]$/, '$1'); // 注意正则中间有个空格
}
/* 代码验证,需要注意大小写,哪些是typeof判断,哪些是toString判断?思考下 */
getType([]) // "Array" typeof []是object,因此toString返回
getType('123') // "string" typeof 直接返回
getType(window) // "Window" toString返回
getType(null) // "Null"首字母大写,typeof null是object,需toString来判断
getType(undefined) // "undefined" typeof 直接返回
getType() // "undefined" typeof 直接返回
getType(function(){}) // "function" typeof能判断,因此首字母小写
getType(/123/g) //"RegExp" toString返回
小结
typeof- 直接在计算机底层基于数据类型的值(二进制)进行检测
typeof null为object原因是对象存在在计算机中,都是以000开始的二进制存储,所以检测出来的结果是对象typeof普通对象/数组对象/正则对象/日期对象 都是objecttypeof NaN === 'number'
instanceof- 检测当前实例是否属于这个类的
- 底层机制:只要当前类出现在实例的原型上,结果都是true
- 不能检测基本数据类型
constructor- 支持基本类型
- constructor可以随便改,也不准
Object.prototype.toString.call([val])- 返回当前实例所属类信息
判断
Target的类型,单单用typeof并无法完全满足,这其实并不是bug,本质原因是JS的万物皆对象的理论。因此要真正完美判断时,我们需要区分对待:
- 基本类型(
null): 使用String(null) - 基本类型(
string / number / boolean / undefined) +function: - 直接使用typeof即可 - 其余引用类型(
Array / Date / RegExp Error): 调用toString后根据[object XXX]进行判断
3. 数据类型转换
我们先看一段代码,了解下大致的情况。
'123' == 123 // false or true?
'' == null // false or true?
'' == 0 // false or true?
[] == 0 // false or true?
[] == '' // false or true?
[] == ![] // false or true?
null == undefined // false or true?
Number(null) // 返回什么?
Number('') // 返回什么?
parseInt(''); // 返回什么?
{}+10 // 返回什么?
let obj = {
[Symbol.toPrimitive]() {
return 200;
},
valueOf() {
return 300;
},
toString() {
return 'Hello';
}
}
console.log(obj + 200); // 这里打印出来是多少?
首先我们要知道,在
JS中类型转换只有三种情况,分别是:
- 转换为布尔值
- 转换为数字
- 转换为字符串
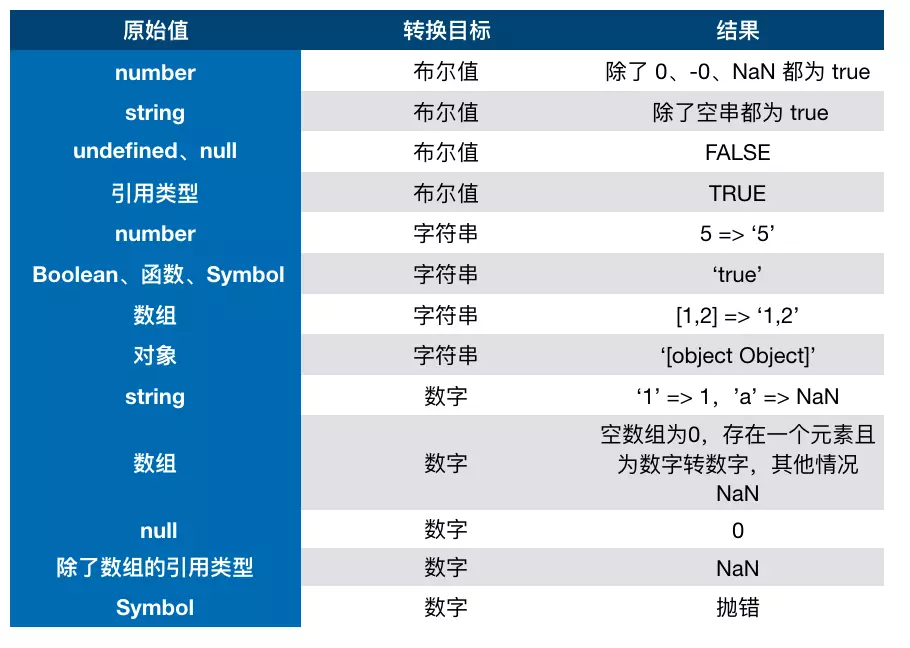
转Boolean
在条件判断时,除了
undefined,null,false,NaN,'',0,-0,其他所有值都转为true,包括所有对象
Boolean(0) //false
Boolean(null) //false
Boolean(undefined) //false
Boolean(NaN) //false
Boolean(1) //true
Boolean(13) //true
Boolean('12') //true
对象转原始类型
对象在转换类型的时候,会调用内置的
[[ToPrimitive]]函数,对于该函数来说,算法逻辑一般来说如下
- 如果已经是原始类型了,那就不需要转换了
- 调用
x.valueOf(),如果转换为基础类型,就返回转换的值 - 调用
x.toString(),如果转换为基础类型,就返回转换的值 - 如果都没有返回原始类型,就会报错
当然你也可以重写
Symbol.toPrimitive,该方法在转原始类型时调用优先级最高。
let a = {
valueOf() {
return 0
},
toString() {
return '1'
},
[Symbol.toPrimitive]() {
return 2
}
}
1 + a // => 3
四则运算符
它有以下几个特点:
- 运算中其中一方为字符串,那么就会把另一方也转换为字符串
- 如果一方不是字符串或者数字,那么会将它转换为数字或者字符串
1 + '1' // '11'
true + true // 2
4 + [1,2,3] // "41,2,3"
- 对于第一行代码来说,触发特点一,所以将数字
1转换为字符串,得到结果'11' - 对于第二行代码来说,触发特点二,所以将
true转为数字1 - 对于第三行代码来说,触发特点二,所以将数组通过
toString转为字符串1,2,3,得到结果41,2,3
另外对于加法还需要注意这个表达式
'a' + + 'b'
'a' + + 'b' // -> "aNaN"
- 因为
+ 'b'等于NaN,所以结果为"aNaN",你可能也会在一些代码中看到过+ '1'的形式来快速获取number类型。 - 那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字
4 * '3' // 12
4 * [] // 0
4 * [1, 2] // NaN
比较运算符
- 如果是对象,就通过
toPrimitive转换对象 - 如果是字符串,就通过
unicode字符索引来比较
let a = {
valueOf() {
return 0
},
toString() {
return '1'
}
}
a > -1 // true
在以上代码中,因为
a是对象,所以会通过valueOf转换为原始类型再比较值。
强制类型转换
强制类型转换方式包括
Number()、parseInt()、parseFloat()、toString()、String()、Boolean(),这几种方法都比较类似
Number()方法的强制转换规则- 如果是布尔值,
true和false分别被转换为1和0; - 如果是数字,返回自身;
- 如果是
null,返回0; - 如果是
undefined,返回NaN; - 如果是字符串,遵循以下规则:如果字符串中只包含数字(或者是
0X / 0x开头的十六进制数字字符串,允许包含正负号),则将其转换为十进制;如果字符串中包含有效的浮点格式,将其转换为浮点数值;如果是空字符串,将其转换为0;如果不是以上格式的字符串,均返回 NaN; - 如果是
Symbol,抛出错误; - 如果是对象,并且部署了
[Symbol.toPrimitive],那么调用此方法,否则调用对象的valueOf()方法,然后依据前面的规则转换返回的值;如果转换的结果是NaN,则调用对象的toString()方法,再次依照前面的顺序转换返回对应的值。
Number(true); // 1
Number(false); // 0
Number('0111'); //111
Number(null); //0
Number(''); //0
Number('1a'); //NaN
Number(-0X11); //-17
Number('0X11') //17
Object 的转换规则
对象转换的规则,会先调用内置的
[ToPrimitive]函数,其规则逻辑如下:
- 如果部署了
Symbol.toPrimitive方法,优先调用再返回; - 调用
valueOf(),如果转换为基础类型,则返回; - 调用
toString(),如果转换为基础类型,则返回; - 如果都没有返回基础类型,会报错。
var obj = {
value: 1,
valueOf() {
return 2;
},
toString() {
return '3'
},
[Symbol.toPrimitive]() {
return 4
}
}
console.log(obj + 1); // 输出5
// 因为有Symbol.toPrimitive,就优先执行这个;如果Symbol.toPrimitive这段代码删掉,则执行valueOf打印结果为3;如果valueOf也去掉,则调用toString返回'31'(字符串拼接)
// 再看两个特殊的case:
10 + {}
// "10[object Object]",注意:{}会默认调用valueOf是{},不是基础类型继续转换,调用toString,返回结果"[object Object]",于是和10进行'+'运算,按照字符串拼接规则来,参考'+'的规则C
[1,2,undefined,4,5] + 10
// "1,2,,4,510",注意[1,2,undefined,4,5]会默认先调用valueOf结果还是这个数组,不是基础数据类型继续转换,也还是调用toString,返回"1,2,,4,5",然后再和10进行运算,还是按照字符串拼接规则,参考'+'的第3条规则
‘==’ 的隐式类型转换规则
- 如果类型相同,无须进行类型转换;
- 如果其中一个操作值是
null或者undefined,那么另一个操作符必须为null或者undefined,才会返回true,否则都返回false; - 如果其中一个是
Symbol类型,那么返回false; - 两个操作值如果为
string和 number 类型,那么就会将字符串转换为number; - 如果一个操作值是
boolean,那么转换成number; - 如果一个操作值为
object且另一方为string、number或者symbol,就会把object转为原始类型再进行判断(调用object的valueOf/toString方法进行转换)。
null == undefined // true 规则2
null == 0 // false 规则2
'' == null // false 规则2
'' == 0 // true 规则4 字符串转隐式转换成Number之后再对比
'123' == 123 // true 规则4 字符串转隐式转换成Number之后再对比
0 == false // true e规则 布尔型隐式转换成Number之后再对比
1 == true // true e规则 布尔型隐式转换成Number之后再对比
var a = {
value: 0,
valueOf: function() {
this.value++;
return this.value;
}
};
// 注意这里a又可以等于1、2、3
console.log(a == 1 && a == 2 && a ==3); //true f规则 Object隐式转换
// 注:但是执行过3遍之后,再重新执行a==3或之前的数字就是false,因为value已经加上去了,这里需要注意一下
‘+’ 的隐式类型转换规则
‘+’ 号操作符,不仅可以用作数字相加,还可以用作字符串拼接。仅当 ‘+’ 号两边都是数字时,进行的是加法运算;如果两边都是字符串,则直接拼接,无须进行隐式类型转换。
- 如果其中有一个是字符串,另外一个是
undefined、null或布尔型,则调用toString()方法进行字符串拼接;如果是纯对象、数组、正则等,则默认调用对象的转换方法会存在优先级,然后再进行拼接。 - 如果其中有一个是数字,另外一个是
undefined、null、布尔型或数字,则会将其转换成数字进行加法运算,对象的情况还是参考上一条规则。 - 如果其中一个是字符串、一个是数字,则按照字符串规则进行拼接
1 + 2 // 3 常规情况
'1' + '2' // '12' 常规情况
// 下面看一下特殊情况
'1' + undefined // "1undefined" 规则1,undefined转换字符串
'1' + null // "1null" 规则1,null转换字符串
'1' + true // "1true" 规则1,true转换字符串
'1' + 1n // '11' 比较特殊字符串和BigInt相加,BigInt转换为字符串
1 + undefined // NaN 规则2,undefined转换数字相加NaN
1 + null // 1 规则2,null转换为0
1 + true // 2 规则2,true转换为1,二者相加为2
1 + 1n // 错误 不能把BigInt和Number类型直接混合相加
'1' + 3 // '13' 规则3,字符串拼接
整体来看,如果数据中有字符串,JavaScript 类型转换还是更倾向于转换成字符串,因为第三条规则中可以看到,在字符串和数字相加的过程中最后返回的还是字符串,这里需要关注一下
null 和 undefined 的区别?
- 首先
Undefined和Null都是基本数据类型,这两个基本数据类型分别都只有一个值,就是undefined和null。 undefined代表的含义是未定义,null代表的含义是空对象(其实不是真的对象,请看下面的注意!)。一般变量声明了但还没有定义的时候会返回undefined,null主要用于赋值给一些可能会返回对象的变量,作为初始化。
其实 null 不是对象,虽然 typeof null 会输出 object,但是这只是 JS 存在的一个悠久 Bug。在 JS 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断为 object 。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
- undefined 在 js 中不是一个保留字,这意味着我们可以使用
undefined来作为一个变量名,这样的做法是非常危险的,它会影响我们对 undefined 值的判断。但是我们可以通过一些方法获得安全的undefined值,比如说void 0。 - 当我们对两种类型使用 typeof 进行判断的时候,Null 类型化会返回 “object”,这是一个历史遗留的问题。当我们使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
meta 标签:自动刷新/跳转
假设要实现一个类似 PPT 自动播放的效果,你很可能会想到使用 JavaScript 定时器控制页面跳转来实现。但其实有更加简洁的实现方法,比如通过 meta 标签来实现:
<meta http-equiv="Refresh" content="5; URL=page2.html">
上面的代码会在 5s 之后自动跳转到同域下的 page2.html 页面。我们要实现 PPT 自动播放的功能,只需要在每个页面的 meta 标签内设置好下一个页面的地址即可。
另一种场景,比如每隔一分钟就需要刷新页面的大屏幕监控,也可以通过 meta 标签来实现,只需去掉后面的 URL 即可:
<meta http-equiv="Refresh" content="60">
meta viewport相关
<!DOCTYPE html> <!--H5标准声明,使用 HTML5 doctype,不区分大小写-->
<head lang=”en”> <!--标准的 lang 属性写法-->
<meta charset=’utf-8′> <!--声明文档使用的字符编码-->
<meta http-equiv=”X-UA-Compatible” content=”IE=edge,chrome=1″/> <!--优先使用 IE 最新版本和 Chrome-->
<meta name=”description” content=”不超过150个字符”/> <!--页面描述-->
<meta name=”keywords” content=””/> <!-- 页面关键词-->
<meta name=”author” content=”name, email@gmail.com”/> <!--网页作者-->
<meta name=”robots” content=”index,follow”/> <!--搜索引擎抓取-->
<meta name=”viewport” content=”initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no”> <!--为移动设备添加 viewport-->
<meta name=”apple-mobile-web-app-title” content=”标题”> <!--iOS 设备 begin-->
<meta name=”apple-mobile-web-app-capable” content=”yes”/> <!--添加到主屏后的标题(iOS 6 新增)
是否启用 WebApp 全屏模式,删除苹果默认的工具栏和菜单栏-->
<meta name=”apple-itunes-app” content=”app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL”>
<!--添加智能 App 广告条 Smart App Banner(iOS 6+ Safari)-->
<meta name=”apple-mobile-web-app-status-bar-style” content=”black”/>
<meta name=”format-detection” content=”telphone=no, email=no”/> <!--设置苹果工具栏颜色-->
<meta name=”renderer” content=”webkit”> <!-- 启用360浏览器的极速模式(webkit)-->
<meta http-equiv=”X-UA-Compatible” content=”IE=edge”> <!--避免IE使用兼容模式-->
<meta http-equiv=”Cache-Control” content=”no-siteapp” /> <!--不让百度转码-->
<meta name=”HandheldFriendly” content=”true”> <!--针对手持设备优化,主要是针对一些老的不识别viewport的浏览器,比如黑莓-->
<meta name=”MobileOptimized” content=”320″> <!--微软的老式浏览器-->
<meta name=”screen-orientation” content=”portrait”> <!--uc强制竖屏-->
<meta name=”x5-orientation” content=”portrait”> <!--QQ强制竖屏-->
<meta name=”full-screen” content=”yes”> <!--UC强制全屏-->
<meta name=”x5-fullscreen” content=”true”> <!--QQ强制全屏-->
<meta name=”browsermode” content=”application”> <!--UC应用模式-->
<meta name=”x5-page-mode” content=”app”> <!-- QQ应用模式-->
<meta name=”msapplication-tap-highlight” content=”no”> <!--windows phone 点击无高亮
设置页面不缓存-->
<meta http-equiv=”pragma” content=”no-cache”>
<meta http-equiv=”cache-control” content=”no-cache”>
<meta http-equiv=”expires” content=”0″>
参考 前端进阶面试题详细解答
对 WebSocket 的理解
WebSocket是HTML5提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接, 并进行双向数据传输。
WebSocket 的出现就解决了半双工通信的弊端。它最大的特点是:服务器可以向客户端主动推动消息,客户端也可以主动向服务器推送消息。
WebSocket原理:客户端向 WebSocket 服务器通知(notify)一个带有所有接收者ID(recipients IDs)的事件(event),服务器接收后立即通知所有活跃的(active)客户端,只有ID在接收者ID序列中的客户端才会处理这个事件。
WebSocket 特点的如下:
- 支持双向通信,实时性更强
- 可以发送文本,也可以发送二进制数据‘’
- 建立在TCP协议之上,服务端的实现比较容易
- 数据格式比较轻量,性能开销小,通信高效
- 没有同源限制,客户端可以与任意服务器通信
- 协议标识符是ws(如果加密,则为wss),服务器网址就是 URL
- 与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
Websocket的使用方法如下:
在客户端中:
// 在index.html中直接写WebSocket,设置服务端的端口号为 9999
let ws = new WebSocket('ws://localhost:9999');
// 在客户端与服务端建立连接后触发
ws.onopen = function() {
console.log("Connection open.");
ws.send('hello');
};
// 在服务端给客户端发来消息的时候触发
ws.onmessage = function(res) {
console.log(res); // 打印的是MessageEvent对象
console.log(res.data); // 打印的是收到的消息
};
// 在客户端与服务端建立关闭后触发
ws.onclose = function(evt) {
console.log("Connection closed.");
};
上下垂直居中方案
- 定高:
margin,position + margin(负值) - 不定高:
position+transform,flex,IFC + vertical-align:middle
/* 定高方案1 */
.center {
height: 100px;
margin: 50px 0;
}
/* 定高方案2 */
.center {
height: 100px;
position: absolute;
top: 50%;
margin-top: -25px;
}
/* 不定高方案1 */
.center {
position: absolute;
top: 50%;
transform: translateY(-50%);
}
/* 不定高方案2 */
.wrap {
display: flex;
align-items: center;
}
.center {
width: 100%;
}
/* 不定高方案3 */
/* 设置 inline-block 则会在外层产生 IFC,高度设为 100% 撑开 wrap 的高度 */
.wrap::before {
content: '';
height: 100%;
display: inline-block;
vertical-align: middle;
}
.wrap {
text-align: center;
}
.center {
display: inline-block;
vertical-align: middle;
}
TCP/IP五层协议
TCP/IP五层协议和OSI的七层协议对应关系如下:
- 应用层 (application layer):直接为应用进程提供服务。应用层协议定义的是应用进程间通讯和交互的规则,不同的应用有着不同的应用层协议,如 HTTP协议(万维网服务)、FTP协议(文件传输)、SMTP协议(电子邮件)、DNS(域名查询)等。
- 传输层 (transport layer):有时也译为运输层,它负责为两台主机中的进程提供通信服务。该层主要有以下两种协议:
- 传输控制协议 (Transmission Control Protocol,TCP):提供面向连接的、可靠的数据传输服务,数据传输的基本单位是报文段(segment);
- 用户数据报协议 (User Datagram Protocol,UDP):提供无连接的、尽最大努力的数据传输服务,但不保证数据传输的可靠性,数据传输的基本单位是用户数据报。
- 网络层 (internet layer):有时也译为网际层,它负责为两台主机提供通信服务,并通过选择合适的路由将数据传递到目标主机。
- 数据链路层 (data link layer):负责将网络层交下来的 IP 数据报封装成帧,并在链路的两个相邻节点间传送帧,每一帧都包含数据和必要的控制信息(如同步信息、地址信息、差错控制等)。
- 物理层 (physical Layer):确保数据可以在各种物理媒介上进行传输,为数据的传输提供可靠的环境。
从上图中可以看出,TCP/IP模型比OSI模型更加简洁,它把应用层/表示层/会话层全部整合为了应用层。
在每一层都工作着不同的设备,比如我们常用的交换机就工作在数据链路层的,一般的路由器是工作在网络层的。 在每一层实现的协议也各不同,即每一层的服务也不同,下图列出了每层主要的传输协议:
同样,TCP/IP五层协议的通信方式也是对等通信:
事件机制
涉及面试题:事件的触发过程是怎么样的?知道什么是事件代理嘛?
1. 简介
事件流是一个事件沿着特定数据结构传播的过程。冒泡和捕获是事件流在
DOM中两种不同的传播方法
事件流有三个阶段
- 事件捕获阶段
- 处于目标阶段
- 事件冒泡阶段
事件捕获
事件捕获(
event capturing):通俗的理解就是,当鼠标点击或者触发dom事件时,浏览器会从根节点开始由外到内进行事件传播,即点击了子元素,如果父元素通过事件捕获方式注册了对应的事件的话,会先触发父元素绑定的事件
事件冒泡
事件冒泡(dubbed bubbling):与事件捕获恰恰相反,事件冒泡顺序是由内到外进行事件传播,直到根节点
无论是事件捕获还是事件冒泡,它们都有一个共同的行为,就是事件传播
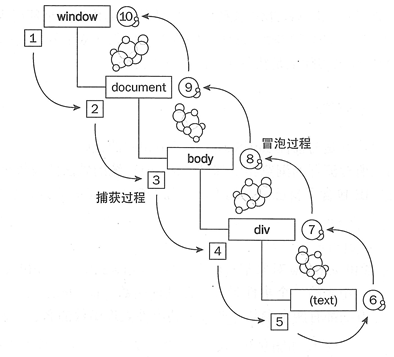
2. 捕获和冒泡
<div id="div1">
<div id="div2"></div>
</div>
<script>
let div1 = document.getElementById('div1');
let div2 = document.getElementById('div2');
div1.onClick = function(){
alert('1')
}
div2.onClick = function(){
alert('2');
}
</script>
当点击
div2时,会弹出两个弹出框。在ie8/9/10、chrome浏览器,会先弹出”2”再弹出“1”,这就是事件冒泡:事件从最底层的节点向上冒泡传播。事件捕获则跟事件冒泡相反
W3C的标准是先捕获再冒泡,
addEventListener的第三个参数决定把事件注册在捕获(true)还是冒泡(false)
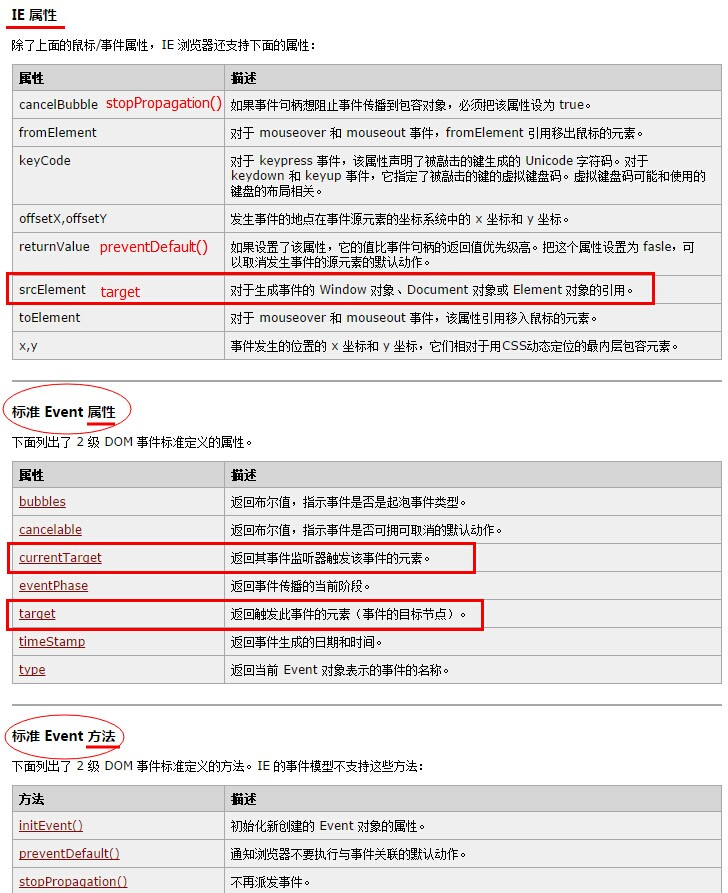
3. 事件对象
4. 事件流阻止
在一些情况下需要阻止事件流的传播,阻止默认动作的发生
event.preventDefault():取消事件对象的默认动作以及继续传播。event.stopPropagation()/ event.cancelBubble = true:阻止事件冒泡。
事件的阻止在不同浏览器有不同处理
- 在
IE下使用event.returnValue= false, - 在非
IE下则使用event.preventDefault()进行阻止
preventDefault与stopPropagation的区别
preventDefault告诉浏览器不用执行与事件相关联的默认动作(如表单提交)stopPropagation是停止事件继续冒泡,但是对IE9以下的浏览器无效
5. 事件注册
- 通常我们使用
addEventListener注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值useCapture参数来说,该参数默认值为false。useCapture决定了注册的事件是捕获事件还是冒泡事件 - 一般来说,我们只希望事件只触发在目标上,这时候可以使用
stopPropagation来阻止事件的进一步传播。通常我们认为stopPropagation是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。stopImmediatePropagation同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件
node.addEventListener('click',(event) =>{
event.stopImmediatePropagation()
console.log('冒泡')
},false);
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener('click',(event) => {
console.log('捕获 ')
},true)
6. 事件委托
- 在
js中性能优化的其中一个主要思想是减少dom操作。 - 节省内存
- 不需要给子节点注销事件
假设有
100个li,每个li有相同的点击事件。如果为每个Li都添加事件,则会造成dom访问次数过多,引起浏览器重绘与重排的次数过多,性能则会降低。 使用事件委托则可以解决这样的问题
原理
实现事件委托是利用了事件的冒泡原理实现的。当我们为最外层的节点添加点击事件,那么里面的
ul、li、a的点击事件都会冒泡到最外层节点上,委托它代为执行事件
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
<script>
window.onload = function(){
var ulEle = document.getElementById('ul');
ul.onclick = function(ev){
//兼容IE
ev = ev || window.event;
var target = ev.target || ev.srcElement;
if(target.nodeName.toLowerCase() == 'li'){
alert( target.innerHTML);
}
}
}
</script>
New的原理
常见考点
new做了那些事?new返回不同的类型时会有什么表现?- 手写 new 的实现过程
new 关键词的
主要作用就是执行一个构造函数、返回一个实例对象,在 new 的过程中,根据构造函数的情况,来确定是否可以接受参数的传递。下面我们通过一段代码来看一个简单的 new 的例子
function Person(){
this.name = 'Jack';
}
var p = new Person();
console.log(p.name) // Jack
这段代码比较容易理解,从输出结果可以看出,p 是一个通过 person 这个构造函数生成的一个实例对象,这个应该很容易理解。
new操作符可以帮助我们构建出一个实例,并且绑定上 this,内部执行步骤可大概分为以下几步:
- 创建一个新对象
- 对象连接到构造函数原型上,并绑定
this(this 指向新对象) - 执行构造函数代码(为这个新对象添加属性)
- 返回新对象
在第四步返回新对象这边有一个情况会例外:
那么问题来了,如果不用
new这个关键词,结合上面的代码改造一下,去掉new,会发生什么样的变化呢?我们再来看下面这段代码
function Person(){
this.name = 'Jack';
}
var p = Person();
console.log(p) // undefined
console.log(name) // Jack
console.log(p.name) // 'name' of undefined
- 从上面的代码中可以看到,我们没有使用
new这个关键词,返回的结果就是undefined。其中由于JavaScript代码在默认情况下this的指向是window,那么name的输出结果就为Jack,这是一种不存在new关键词的情况。 - 那么当构造函数中有
return一个对象的操作,结果又会是什么样子呢?我们再来看一段在上面的基础上改造过的代码。
function Person(){
this.name = 'Jack';
return {age: 18}
}
var p = new Person();
console.log(p) // {age: 18}
console.log(p.name) // undefined
console.log(p.age) // 18
通过这段代码又可以看出,当构造函数最后
return出来的是一个和this无关的对象时,new 命令会直接返回这个新对象,而不是通过 new 执行步骤生成的 this 对象
但是这里要求构造函数必须是返回一个对象,如果返回的不是对象,那么还是会按照 new 的实现步骤,返回新生成的对象。接下来还是在上面这段代码的基础之上稍微改动一下
function Person(){
this.name = 'Jack';
return 'tom';
}
var p = new Person();
console.log(p) // {name: 'Jack'}
console.log(p.name) // Jack
可以看出,当构造函数中 return 的不是一个对象时,那么它还是会根据 new 关键词的执行逻辑,生成一个新的对象(绑定了最新 this),最后返回出来
因此我们总结一下:
new 关键词执行之后总是会返回一个对象,要么是实例对象,要么是 return 语句指定的对象

手工实现New的过程
function create(fn, ...args) {
if(typeof fn !== 'function') {
throw 'fn must be a function';
}
// 1、用new Object() 的方式新建了一个对象obj
// var obj = new Object()
// 2、给该对象的__proto__赋值为fn.prototype,即设置原型链
// obj.__proto__ = fn.prototype
// 1、2步骤合并
// 创建一个空对象,且这个空对象继承构造函数的 prototype 属性
// 即实现 obj.__proto__ === constructor.prototype
var obj = Object.create(fn.prototype);
// 3、执行fn,并将obj作为内部this。使用 apply,改变构造函数 this 的指向到新建的对象,这样 obj 就可以访问到构造函数中的属性
var res = fn.apply(obj, args);
// 4、如果fn有返回值,则将其作为new操作返回内容,否则返回obj
return res instanceof Object ? res : obj;
};
- 使用
Object.create将obj 的proto指向为构造函数的原型; - 使用
apply方法,将构造函数内的this指向为obj; - 在
create返回时,使用三目运算符决定返回结果。
我们知道,构造函数如果有显式返回值,且返回值为对象类型,那么构造函数返回结果不再是目标实例
如下代码:
function Person(name) {
this.name = name
return {1: 1}
}
const person = new Person(Person, 'lucas')
console.log(person)
// {1: 1}
测试
//使用create代替new
function Person() {...}
// 使用内置函数new
var person = new Person(1,2)
// 使用手写的new,即create
var person = create(Person, 1,2)
new 被调用后大致做了哪几件事情
- 让实例可以访问到私有属性;
- 让实例可以访问构造函数原型(
constructor.prototype)所在原型链上的属性; - 构造函数返回的最后结果是引用数据类型。
模块化
js 中现在比较成熟的有四种模块加载方案:
- 第一种是 CommonJS 方案,它通过 require 来引入模块,通过 module.exports 定义模块的输出接口。这种模块加载方案是服务器端的解决方案,它是以同步的方式来引入模块的,因为在服务端文件都存储在本地磁盘,所以读取非常快,所以以同步的方式加载没有问题。但如果是在浏览器端,由于模块的加载是使用网络请求,因此使用异步加载的方式更加合适。
- 第二种是 AMD 方案,这种方案采用异步加载的方式来加载模块,模块的加载不影响后面语句的执行,所有依赖这个模块的语句都定义在一个回调函数里,等到加载完成后再执行回调函数。require.js 实现了 AMD 规范
- 第三种是 CMD 方案,这种方案和 AMD 方案都是为了解决异步模块加载的问题,sea.js 实现了 CMD 规范。它和require.js的区别在于模块定义时对依赖的处理不同和对依赖模块的执行时机的处理不同。
- 第四种方案是 ES6 提出的方案,使用 import 和 export 的形式来导入导出模块
在有
Babel的情况下,我们可以直接使用ES6的模块化
// file a.js
export function a() {}
export function b() {}
// file b.js
export default function() {}
import {a, b} from './a.js'
import XXX from './b.js'
CommonJS
CommonJs是Node独有的规范,浏览器中使用就需要用到Browserify解析了。
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
在上述代码中,
module.exports和exports很容易混淆,让我们来看看大致内部实现
var module = require('./a.js')
module.a
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了,
// 重要的是 module 这里,module 是 Node 独有的一个变量
module.exports = {
a: 1
}
// 基本实现
var module = {
exports: {} // exports 就是个空对象
}
// 这个是为什么 exports 和 module.exports 用法相似的原因
var exports = module.exports
var load = function (module) {
// 导出的东西
var a = 1
module.exports = a
return module.exports
};
再来说说
module.exports和exports,用法其实是相似的,但是不能对exports直接赋值,不会有任何效果。
对于
CommonJS和ES6中的模块化的两者区别是:
- 前者支持动态导入,也就是
require(${path}/xx.js),后者目前不支持,但是已有提案,前者是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。 - 而后者是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响
- 前者在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如果想更新值,必须重新导入一次。
- 但是后者采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化
- 后者会编译成
require/exports来执行的
AMD
AMD是由RequireJS提出的
AMD 和 CMD 规范的区别?
- 第一个方面是在模块定义时对依赖的处理不同。AMD推崇依赖前置,在定义模块的时候就要声明其依赖的模块。而 CMD 推崇就近依赖,只有在用到某个模块的时候再去 require。
- 第二个方面是对依赖模块的执行时机处理不同。首先 AMD 和 CMD 对于模块的加载方式都是异步加载,不过它们的区别在于模块的执行时机,AMD 在依赖模块加载完成后就直接执行依赖模块,依赖模块的执行顺序和我们书写的顺序不一定一致。而 CMD在依赖模块加载完成后并不执行,只是下载而已,等到所有的依赖模块都加载好后,进入回调函数逻辑,遇到 require 语句的时候才执行对应的模块,这样模块的执行顺序就和我们书写的顺序保持一致了。
// CMD
define(function(require, exports, module) {
var a = require("./a");
a.doSomething();
// 此处略去 100 行
var b = require("./b"); // 依赖可以就近书写
b.doSomething();
// ...
});
// AMD 默认推荐
define(["./a", "./b"], function(a, b) {
// 依赖必须一开始就写好
a.doSomething();
// 此处略去 100 行
b.doSomething();
// ...
})
- AMD :
requirejs在推广过程中对模块定义的规范化产出,提前执行,推崇依赖前置 - CMD :
seajs在推广过程中对模块定义的规范化产出,延迟执行,推崇依赖就近 - CommonJs :模块输出的是一个值的
copy,运行时加载,加载的是一个对象(module.exports属性),该对象只有在脚本运行完才会生成 - ES6 Module :模块输出的是一个值的引用,编译时输出接口,
ES6模块不是对象,它对外接口只是一种静态定义,在代码静态解析阶段就会生成。
谈谈对模块化开发的理解
- 我对模块的理解是,一个模块是实现一个特定功能的一组方法。在最开始的时候,js 只实现一些简单的功能,所以并没有模块的概念,但随着程序越来越复杂,代码的模块化开发变得越来越重要。
- 由于函数具有独立作用域的特点,最原始的写法是使用函数来作为模块,几个函数作为一个模块,但是这种方式容易造成全局变量的污染,并且模块间没有联系。
- 后面提出了对象写法,通过将函数作为一个对象的方法来实现,这样解决了直接使用函数作为模块的一些缺点,但是这种办法会暴露所有的所有的模块成员,外部代码可以修改内部属性的值。
- 现在最常用的是立即执行函数的写法,通过利用闭包来实现模块私有作用域的建立,同时不会对全局作用域造成污染。
TCP粘包是怎么回事,如何处理?
默认情况下, TCP 连接会启⽤延迟传送算法 (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到⼀起作⼀次发送 (缓冲⼤⼩⻅ socket.bufferSize ), 这样可以减少 IO 消耗提⾼性能.
如果是传输⽂件的话, 那么根本不⽤处理粘包的问题, 来⼀个包拼⼀个包就好了。但是如果是多条消息, 或者是别的⽤途的数据那么就需要处理粘包.
下面看⼀个例⼦, 连续调⽤两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下⼏种常⻅的情况:
A. 先接收到 data1, 然后接收到 data2 .
B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部.
C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据.
D. ⼀次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常⻅的粘包的情况. ⽽对于处理粘包的问题, 常⻅的解决⽅案有:
- 多次发送之前间隔⼀个等待时间:只需要等上⼀段时间再进⾏下⼀次 send 就好, 适⽤于交互频率特别低的场景. 缺点也很明显, 对于⽐较频繁的场景⽽⾔传输效率实在太低,不过⼏乎不⽤做什么处理.
- 关闭 Nagle 算法:关闭 Nagle 算法, 在 Node.js 中你可以通过 socket.setNoDelay() ⽅法来关闭 Nagle 算法, 让每⼀次 send 都不缓冲直接发送。该⽅法⽐较适⽤于每次发送的数据都⽐较⼤ (但不是⽂件那么⼤), 并且频率不是特别⾼的场景。如果是每次发送的数据量⽐较⼩, 并且频率特别⾼的, 关闭 Nagle 纯属⾃废武功。另外, 该⽅法不适⽤于⽹络较差的情况, 因为 Nagle 算法是在服务端进⾏的包合并情况, 但是如果短时间内客户端的⽹络情况不好, 或者应⽤层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从⽽粘包的情况。 (如果是在稳定的机房内部通信那么这个概率是⽐较⼩可以选择忽略的)
- 进⾏封包/拆包: 封包/拆包是⽬前业内常⻅的解决⽅案了。即给每个数据包在发送之前, 于其前/后放⼀些有特征的数据, 然后收到数据的时 候根据特征数据分割出来各个数据包。
Proxy代理
proxy在目标对象的外层搭建了一层拦截,外界对目标对象的某些操作,必须通过这层拦截
var proxy = new Proxy(target, handler);
new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为
var target = {
name: 'poetries'
};
var logHandler = {
get: function(target, key) {
console.log(`${key} 被读取`);
return target[key];
},
set: function(target, key, value) {
console.log(`${key} 被设置为 ${value}`);
target[key] = value;
}
}
var targetWithLog = new Proxy(target, logHandler);
targetWithLog.name; // 控制台输出:name 被读取
targetWithLog.name = 'others'; // 控制台输出:name 被设置为 others
console.log(target.name); // 控制台输出: others
targetWithLog读取属性的值时,实际上执行的是logHandler.get:在控制台输出信息,并且读取被代理对象target的属性。- 在
targetWithLog设置属性值时,实际上执行的是logHandler.set:在控制台输出信息,并且设置被代理对象target的属性的值
// 由于拦截函数总是返回35,所以访问任何属性都得到35
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35
Proxy 实例也可以作为其他对象的原型对象
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
let obj = Object.create(proxy);
obj.time // 35
proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截
Proxy的作用
对于代理模式
Proxy的作用主要体现在三个方面
- 拦截和监视外部对对象的访问
- 降低函数或类的复杂度
- 在复杂操作前对操作进行校验或对所需资源进行管理
Proxy所能代理的范围–handler
实际上 handler 本身就是ES6所新设计的一个对象.它的作用就是用来 自定义代理对象的各种可代理操作 。它本身一共有13中方法,每种方法都可以代理一种操作.其13种方法如下
// 在读取代理对象的原型时触发该操作,比如在执行 Object.getPrototypeOf(proxy) 时。
handler.getPrototypeOf()
// 在设置代理对象的原型时触发该操作,比如在执行 Object.setPrototypeOf(proxy, null) 时。
handler.setPrototypeOf()
// 在判断一个代理对象是否是可扩展时触发该操作,比如在执行 Object.isExtensible(proxy) 时。
handler.isExtensible()
// 在让一个代理对象不可扩展时触发该操作,比如在执行 Object.preventExtensions(proxy) 时。
handler.preventExtensions()
// 在获取代理对象某个属性的属性描述时触发该操作,比如在执行 Object.getOwnPropertyDescriptor(proxy, "foo") 时。
handler.getOwnPropertyDescriptor()
// 在定义代理对象某个属性时的属性描述时触发该操作,比如在执行 Object.defineProperty(proxy, "foo", {}) 时。
andler.defineProperty()
// 在判断代理对象是否拥有某个属性时触发该操作,比如在执行 "foo" in proxy 时。
handler.has()
// 在读取代理对象的某个属性时触发该操作,比如在执行 proxy.foo 时。
handler.get()
// 在给代理对象的某个属性赋值时触发该操作,比如在执行 proxy.foo = 1 时。
handler.set()
// 在删除代理对象的某个属性时触发该操作,比如在执行 delete proxy.foo 时。
handler.deleteProperty()
// 在获取代理对象的所有属性键时触发该操作,比如在执行 Object.getOwnPropertyNames(proxy) 时。
handler.ownKeys()
// 在调用一个目标对象为函数的代理对象时触发该操作,比如在执行 proxy() 时。
handler.apply()
// 在给一个目标对象为构造函数的代理对象构造实例时触发该操作,比如在执行new proxy() 时。
handler.construct()
为何Proxy不能被Polyfill
- 如class可以用
function模拟;promise可以用callback模拟 - 但是proxy不能用
Object.defineProperty模拟
目前谷歌的polyfill只能实现部分的功能,如get、set https://github.com/GoogleChrome/proxy-polyfill
// commonJS require
const proxyPolyfill = require('proxy-polyfill/src/proxy')();
// Your environment may also support transparent rewriting of commonJS to ES6:
import ProxyPolyfillBuilder from 'proxy-polyfill/src/proxy';
const proxyPolyfill = ProxyPolyfillBuilder();
// Then use...
const myProxy = new proxyPolyfill(...);
从输入URL到页面展示过程

1. DNS域名解析

- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
DNS的域名查找,在客户端和浏览器,本地DNS之间的查询方式是递归查询;在本地DNS服务器与根域及其子域之间的查询方式是迭代查询;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jssOTrgb-1671415246034)(null)]
在客户端输入 URL 后,会有一个递归查找的过程,从浏览器缓存中查找->本地的hosts文件查找->找本地DNS解析器缓存查找->本地DNS服务器查找,这个过程中任何一步找到了都会结束查找流程。
如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程如下图:

结合起来的过程,可以用一个图表示:

在查找过程中,有以下优化点:
- DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种:
浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。 - 在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
2. 建立TCP连接
首先,判断是不是https的,如果是,则HTTPS其实是HTTP + SSL / TLS 两部分组成,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据
进行三次握手,建立TCP连接。
- 第一次握手:建立连接。客户端发送连接请求报文段
- 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认
- 第三次握手:客户端收到服务器的SYN+ACK报文段,向服务器发送ACK报文段
SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
完成了之后,客户端和服务器端就可以开始传送数据
发送HTTP请求,服务器处理请求,返回响应结果
TCP连接建立后,浏览器就可以利用
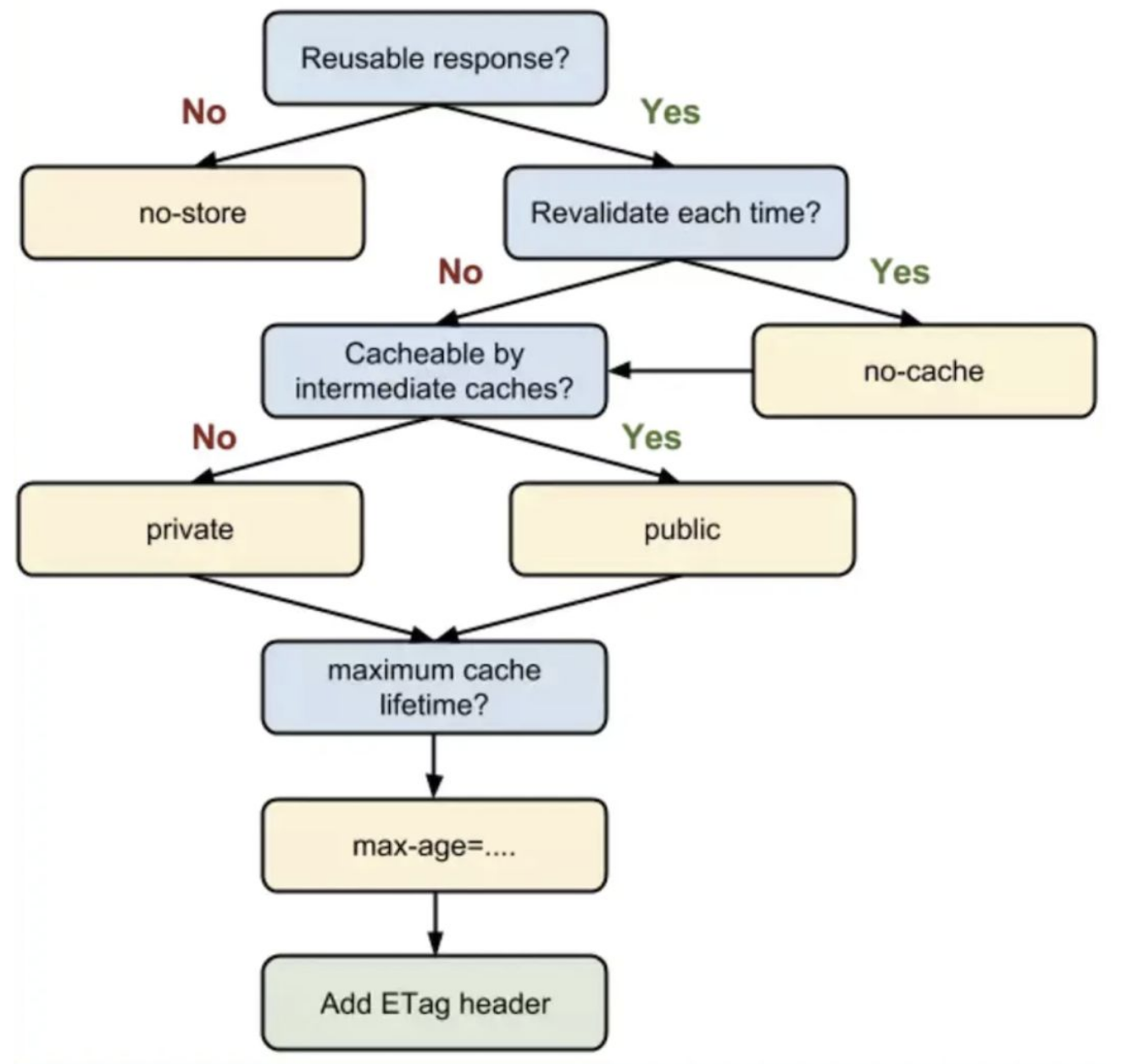
HTTP/HTTPS协议向服务器发送请求了。服务器接受到请求,就解析请求头,如果头部有缓存相关信息如if-none-match与if-modified-since,则验证缓存是否有效,若有效则返回状态码为304,若无效则重新返回资源,状态码为200
这里有发生的一个过程是HTTP缓存,是一个常考的考点,大致过程如图:
3. 关闭TCP连接
4. 浏览器渲染
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、栅格化和显示。如图:
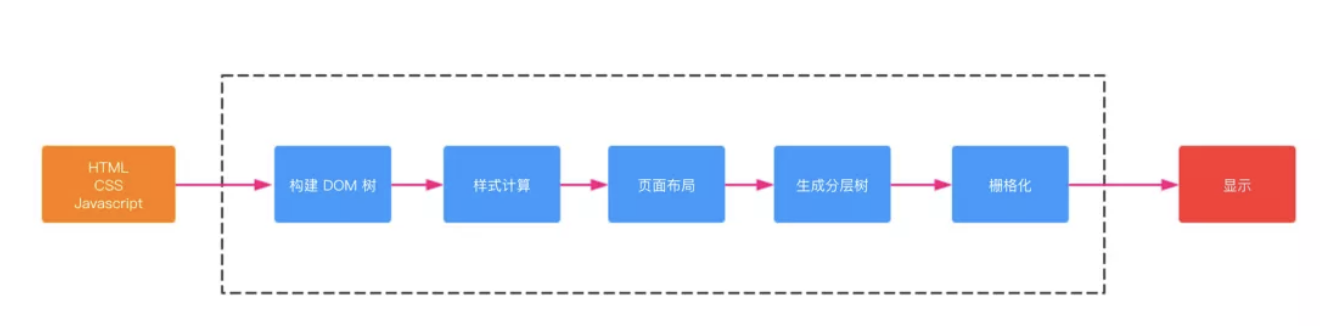
- 渲染进程将 HTML 内容转换为能够读懂DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的
styleSheets,计算出DOM节点的样式。 - 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
构建 DOM 树

- 转码(Bytes -> Characters)—— 读取接收到的 HTML 二进制数据,按指定编码格式将字节转换为 HTML 字符串
- Tokens 化(Characters -> Tokens)—— 解析 HTML,将 HTML 字符串转换为结构清晰的 Tokens,每个 Token 都有特殊的含义同时有自己的一套规则
- 构建 Nodes(Tokens -> Nodes)—— 每个 Node 都添加特定的属性(或属性访问器),通过指针能够确定 Node 的父、子、兄弟关系和所属 treeScope(例如:iframe 的 treeScope 与外层页面的 treeScope 不同)
- 构建 DOM 树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系
样式计算
渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
CSS 样式来源主要有 3 种,分别是通过 link 引用的外部 CSS 文件、style标签内的 CSS、元素的 style 属性内嵌的 CSS。
页面布局
布局过程,即
排除 script、meta 等功能化、非视觉节点,排除display: none的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XPEAM1L1-1671415246222)(null)]
其中,这个过程需要注意的是回流和重绘
生成分层树
页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图
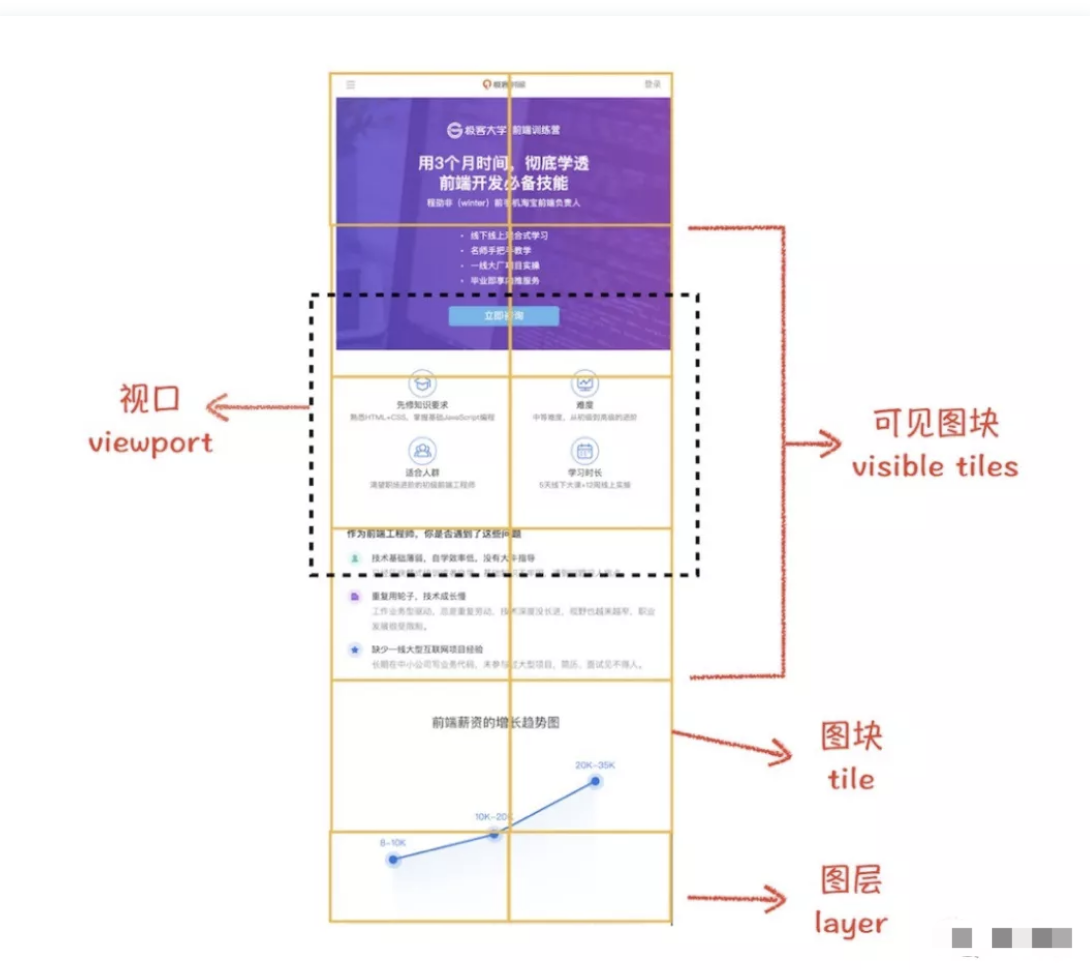
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
显示
最后,合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上,渲染过程完成。
左边定宽,右边自适应方案
float + margin,float + calc
/* 方案1 */
.left {
width: 120px;
float: left;
}
.right {
margin-left: 120px;
}
/* 方案2 */
.left {
width: 120px;
float: left;
}
.right {
width: calc(100% - 120px);
float: left;
}
浏览器存储
我们经常需要对业务中的一些数据进行存储,通常可以分为 短暂性存储 和 持久性储存。
- 短暂性的时候,我们只需要将数据存在内存中,只在运行时可用
- 持久性存储,可以分为 浏览器端 与 服务器端
- 浏览器:
cookie: 通常用于存储用户身份,登录状态等http中自动携带, 体积上限为4K, 可自行设置过期时间
localStorage / sessionStorage: 长久储存/窗口关闭删除, 体积限制为4~5MindexDB
- 服务器:
- 分布式缓存
redis - 数据库
- 分布式缓存
- 浏览器:
cookie和localSrorage、session、indexDB 的区别
| 特性 | cookie | localStorage | sessionStorage | indexDB |
|---|---|---|---|---|
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在 header 中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,
cookie已经不建议用于存储。如果没有大量数据存储需求的话,可以使用localStorage和sessionStorage。对于不怎么改变的数据尽量使用localStorage存储,否则可以用sessionStorage存储。
对于 cookie,我们还需要注意安全性
| 属性 | 作用 |
|---|---|
value | 如果用于保存用户登录态,应该将该值加密,不能使用明文的用户标识 |
http-only | 不能通过 JS访问 Cookie,减少 XSS攻击 |
secure | 只能在协议为 HTTPS 的请求中携带 |
same-site | 规定浏览器不能在跨域请求中携带 Cookie,减少 CSRF 攻击 |
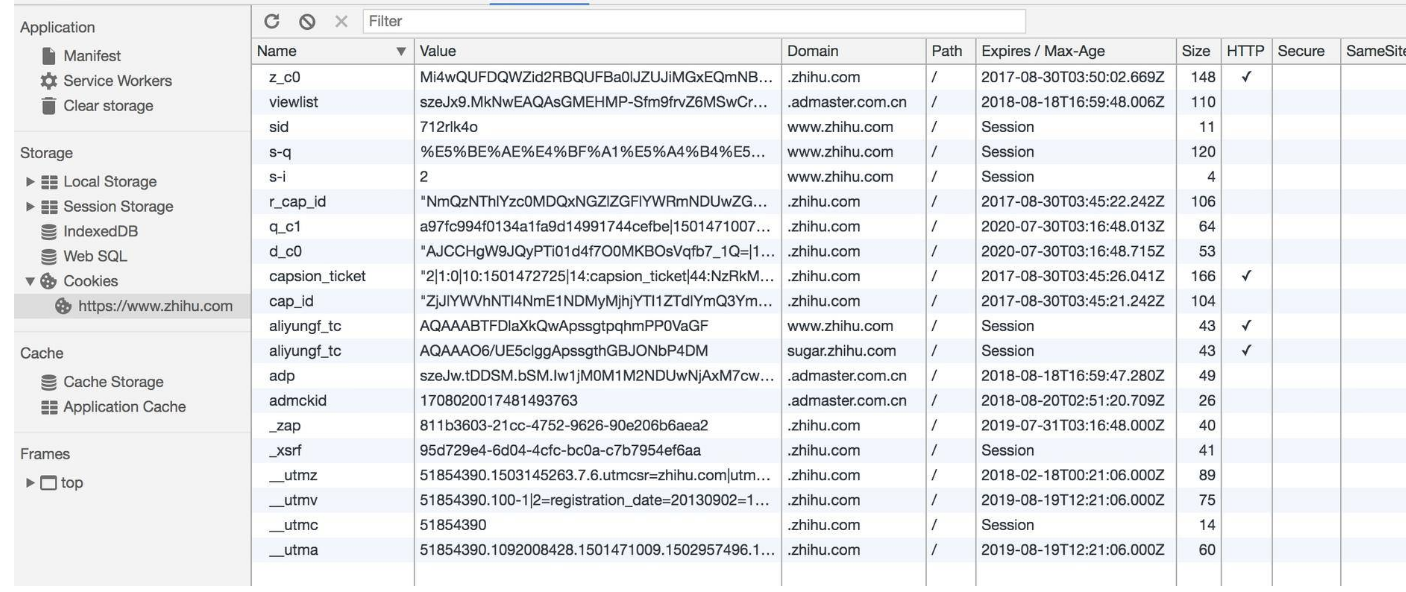
Name,即该Cookie的名称。Cookie一旦创建,名称便不可更改。Value,即该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。Max Age,即该Cookie失效的时间,单位秒,也常和Expires一起使用,通过它可以计算出其有效时间。Max Age如果为正数,则该Cookie在Max Age秒之后失效。如果为负数,则关闭浏览器时Cookie即失效,浏览器也不会以任何形式保存该Cookie。Path,即该Cookie的使用路径。如果设置为/path/,则只有路径为/path/的页面可以访问该Cookie。如果设置为/,则本域名下的所有页面都可以访问该Cookie。Domain,即可以访问该Cookie的域名。例如如果设置为.zhihu.com,则所有以zhihu.com,结尾的域名都可以访问该Cookie。Size字段,即此Cookie的大小。Http字段,即Cookie的httponly属性。若此属性为true,则只有在HTTP Headers中会带有此 Cookie 的信息,而不能通过document.cookie来访问此 Cookie。Secure,即该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS、SSL等,在网络上传输数据之前先将数据加密。默认为false。
为什么udp不会粘包?
- TCP协议是⾯向流的协议,UDP是⾯向消息的协议。UDP段都是⼀条消息,应⽤程序必须以消息为单位提取数据,不能⼀次提取任意字节的数据
- UDP具有保护消息边界,在每个UDP包中就有了消息头(消息来源地址,端⼝等信息),这样对于接收端来说就容易进⾏区分处理了。传输协议把数据当作⼀条独⽴的消息在⽹上传输,接收端只能接收独⽴的消息。接收端⼀次只能接收发送端发出的⼀个数据包,如果⼀次接受数据的⼤⼩⼩于发送端⼀次发送的数据⼤⼩,就会丢失⼀部分数据,即使丢失,接受端也不会分两次去接收。
如何高效操作DOM
1. 为什么说 DOM 操作耗时
1.1 线程切换
- 浏览器为了避免两个引擎同时修改页面而造成渲染结果不一致的情况,增加了另外一个机制,这
两个引擎具有互斥性,也就是说在某个时刻只有一个引擎在运行,另一个引擎会被阻塞。操作系统在进行线程切换的时候需要保存上一个线程执行时的状态信息并读取下一个线程的状态信息,俗称上下文切换。而这个操作相对而言是比较耗时的 - 每次 DOM 操作就会引发线程的上下文切换——从 JavaScript 引擎切换到渲染引擎执行对应操作,然后再切换回 JavaScript 引擎继续执行,这就带来了性能损耗。单次切换消耗的时间是非常少的,但是如果频繁地大量切换,那么就会产生性能问题
比如下面的测试代码,循环读取一百万次 DOM 中的 body 元素的耗时是读取 JSON 对象耗时的 10 倍。
// 测试次数:一百万次
const times = 1000000
// 缓存body元素
console.time('object')
let body = document.body
// 循环赋值对象作为对照参考
for(let i=0;i<times;i++) {
let tmp = body
}
console.timeEnd('object')// object: 1.77197265625ms
console.time('dom')
// 循环读取body元素引发线程切换
for(let i=0;i<times;i++) {
let tmp = document.body
}
console.timeEnd('dom')// dom: 18.302001953125ms
1.2 重新渲染
另一个更加耗时的因素是元素及样式变化引起的再次渲染,在渲染过程中最耗时的两个步骤为重排(Reflow)与重绘(Repaint)。
浏览器在渲染页面时会将 HTML 和 CSS 分别解析成 DOM 树和 CSSOM 树,然后合并进行排布,再绘制成我们可见的页面。如果在操作 DOM 时涉及到元素、样式的修改,就会引起渲染引擎重新计算样式生成 CSSOM 树,同时还有可能触发对元素的重新排布和重新绘制
- 可能会影响到其他元素排布的操作就会引起重排,继而引发重绘
- 修改元素边距、大小
- 添加、删除元素
- 改变窗口大小
- 引起重绘
- 设置背景图片
- 修改字体颜色
- 改变
visibility属性值
了解更多关于重绘和重排的样式属性,可以参看这个网址:https://csstriggers.com/ (opens new window)。
2. 如何高效操作 DOM
明白了 DOM 操作耗时之后,要提升性能就变得很简单了,反其道而行之,减少这些操作即可
2.1 在循环外操作元素
比如下面两段测试代码对比了读取 1000 次 JSON 对象以及访问 1000 次 body 元素的耗时差异,相差一个数量级
const times = 10000;
console.time('switch')
for (let i = 0; i < times; i++) {
document.body === 1 ? console.log(1) : void 0;
}
console.timeEnd('switch') // 1.873046875ms
var body = JSON.stringify(document.body)
console.time('batch')
for (let i = 0; i < times; i++) {
body === 1 ? console.log(1) : void 0;
}
console.timeEnd('batch') // 0.846923828125ms
2.2 批量操作元素
比如说要创建 1 万个 div 元素,在循环中直接创建再添加到父元素上耗时会非常多。如果采用字符串拼接的形式,先将 1 万个 div 元素的 html 字符串拼接成一个完整字符串,然后赋值给 body 元素的 innerHTML 属性就可以明显减少耗时
const times = 10000;
console.time('createElement')
for (let i = 0; i < times; i++) {
const div = document.createElement('div')
document.body.appendChild(div)
}
console.timeEnd('createElement')// 54.964111328125ms
console.time('innerHTML')
let html=''
for (let i = 0; i < times; i++) {
html+='<div></div>'
}
document.body.innerHTML += html // 31.919921875ms
console.timeEnd('innerHTML')
ES6 之前使用 prototype 实现继承
Object.create() 会创建一个 “新” 对象,然后将此对象内部的 [[Prototype]] 关联到你指定的对象(Foo.prototype)。Object.create(null) 创建一个空 [[Prototype]] 链接的对象,这个对象无法进行委托。
function Foo(name) {
this.name = name;
}
Foo.prototype.myName = function () {
return this.name;
}
// 继承属性,通过借用构造函数调用
function Bar(name, label) {
Foo.call(this, name);
this.label = label;
}
// 继承方法,创建备份
Bar.prototype = Object.create(Foo.prototype);
// 必须设置回正确的构造函数,要不然在会发生判断类型出错
Bar.prototype.constructor = Bar;
// 必须在上一步之后
Bar.prototype.myLabel = function () {
return this.label;
}
var a = new Bar("a", "obj a");
a.myName(); // "a"
a.myLabel(); // "obj a"