在页中定义了一个叫Page Header的部分,它是页结构的第二部分,这个部分占用固定的56个字节,专门存储各种状态信息,具体如下:
| 名称 | 占用空间大小 | 描述 |
| PAGE_N_DIR_SLOTS | 2 字节 | 在页目录中的槽数量 |
| PAGE_HEAP_TOP | 2 字节 | 还未使用的空间最小地址,也就是说从该地址之后就是 Free Space |
| PAGE_N_HEAP | 2 字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE | 2 字节 | 第一个已经标记为删除的记录地址(各个已删除的记录通过 next_record 也会组成一个单链表,这个单链表中的记录可以被重新利用) |
| PAGE_GARBAGE | 2 字节 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2 字节 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 字节 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2 字节 | 一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2 字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8 字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2 字节 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8 字节 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10 字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10 字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
PAGE_DIRECTION
假如新插入的一条记录的主键值比上一条记录的主键值大,我们说这条记录的插入方向是右边,反之则是左边。用来表示最后一条记录插入方向的状态就是 PAGE_DIRECTION 。
PAGE_N_DIRECTION
假设连续几次插入新记录的方向都是一致的, InnoDB 会把沿着同一个方向插入记录的条数记下来,这个条数就用 PAGE_N_DIRECTION 这个状态表示。当然,如果最后一条记录的插入方向改变了的话,这个状态的值会被清零重新统计。
5.6 File Header(文件头部)
上边说的 Page Header 是专门针对 数据页 记录的各种状态信息,比方说页里头有多少个记录了,有多少个槽。现在描述的 File Header 针对各种类型的页都通用,也就是说不同类型的页都会以 File Header 作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁。这部分占用固定的38个字节,是由下边这些内容组成的:
| 名称 | 占用空间大小 | 描述 |
| FIL_PAGE_SPACE_OR_CHKSUM | 4 字节 | 页的校验和(checksum值) |
| FIL_PAGE_OFFSET | 4 字节 | 页号 |
| FIL_PAGE_PREV | 4 字节 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4 字节 | 下一个页的页号 |
| FIL_PAGE_LSN | 8 字节 | 页面被最后修改时对应的日志序列位置(英文名是:Log SequenceNumber) |
| FIL_PAGE_TYPE | 2 字节 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 字节 | 页属于哪个表空间 |
对照着这个表格,我们看几个目前比较重要的部分:
FIL_PAGE_SPACE_OR_CHKSUM
这个代表当前页面的校验和(checksum)。啥是个校验和?就是对于一个很长很长的字节串来说,我们会通过某种算法来计算一个比较短的值来代表这个很长的字节串,这个比较短的值就称为 校验和 。这样在比较两个很长的字节串之前先比较这两个长字节串的校验和,如果校验和都不一样两个长字节串肯定是不同的,所以省去了直接比较两个比较长的字节串的时间损耗。
FIL_PAGE_OFFSET
每一个 页 都有一个单独的页号,就跟你的身份证号码一样, InnoDB 通过页号来可以唯一定位一个 页 。
FIL_PAGE_TYPE
这个代表当前 页 的类型,我们前边说过, InnoDB 为了不同的目的而把页分为不同的类型,我们上边介绍的其实都是存储记录的 数据页 ,其实还有很多别的类型的页,具体如下表: |类型名称|十六进制|描述| |:--:|:--:|:--:| | FIL_PAGE_TYPE_ALLOCATED |0x0000|最新分配,还没使用| | FIL_PAGE_UNDO_LOG |0x0002|Undo日志页|| FIL_PAGE_INODE |0x0003|段信息节点| | FIL_PAGE_IBUF_FREE_LIST |0x0004|Insert Buffer空闲列表|| FIL_PAGE_IBUF_BITMAP |0x0005|Insert Buffer位图| | FIL_PAGE_TYPE_SYS |0x0006|系统页|| FIL_PAGE_TYPE_TRX_SYS |0x0007|事务系统数据| | FIL_PAGE_TYPE_FSP_HDR |0x0008|表空间头部信息|| FIL_PAGE_TYPE_XDES |0x0009|扩展描述页| | FIL_PAGE_TYPE_BLOB |0x000A|BLOB页|| FIL_PAGE_INDEX |0x45BF|索引页,也就是我们所说的 数据页 |
我们存放记录的数据页的类型其实是 FIL_PAGE_INDEX ,也就是所谓的 索引页 。
FIL_PAGE_PREV 和 FIL_PAGE_NEXT
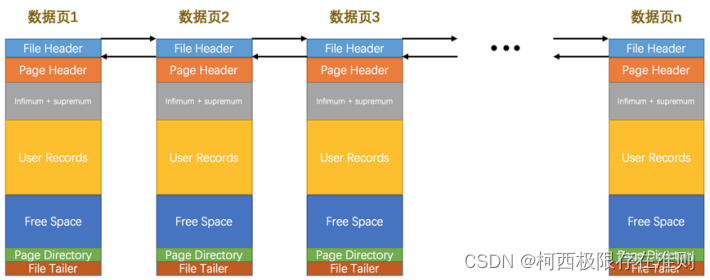
InnoDB 都是以页为单位存放数据的,有时候我们存放某种类型的数据占用的空间非常大(比方说一张表中可以有成千上万条记录), InnoDB 可能不可以一次性为这么多数据分配一个非常大的存储空间,如果分散到多个不连续的页中存储的话需要把这些页关联起来, FIL_PAGE_PREV 和 FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了,而无需这些页在物理上真正连着。需要注意的是,并不是所有类型的页都有上一个和下一个页的属性,不过我们本集中唠叨的 数据页 (也就是类型为 FIL_PAGE_INDEX 的页)是有这两个属性的,所以所有的数据页其实是一个双链表,就像这样:
5.7 File Trailer
我们知道 InnoDB 存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以 页 为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),设计 InnoDB 的大叔们在每个页的尾部都加了一个 File Trailer 部分,这个部分由 8 个字节组成,可以分成2个小部分:
前4个字节代表页的校验和
后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
5.8 总结
1. InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做 数据页 。
2. 一个数据页可以被大致划分为7个部分,分别是
File Header ,表示页的一些通用信息,占固定的38字节。
Page Header ,表示数据页专有的一些信息,占固定的56个字节。
Infimum + Supremum ,两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的 26 个字节。
User Records :真实存储我们插入的记录的部分,大小不固定。
Free Space :页中尚未使用的部分,大小不确定。
Page Directory :页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。
File Trailer :用于检验页是否完整的部分,占用固定的8个字节。
3. 每个记录的头信息中都有一个 next_record 属性,从而使页中的所有记录串联成一个 单链表 。
4. InnoDB 会为把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个 槽 ,存放在Page Directory 中,所以在一个页中根据主键查找记录是非常快的,分为两步:
通过二分法确定该记录所在的槽。
通过记录的next_record属性遍历该槽所在的组中的各个记录。
5. 每个数据页的 File Header 部分都有上一个和下一个页的编号,所以所有的数据页会组成一个 双链表 。
6. 为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的 LSN 值,如果首部和尾部的校验和和 LSN 值校验不成功的话,就说明同步过程出现了问题。