PyTorch的风格
- 准备数据集
- 使用类设计模型
- 计算损失函数和优化器
- 训练【前向、反向和更新】
线性回归
import torch
# 准备数据集
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
#LinearModel类继承torch的Module模块
class LinearModel(torch.nn.Module):
#需要事先__init__和forward两个函数
def __init__(self):
#父类初始化
super(LinearModel, self).__init__()
# (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
#linear相当于一个类
def forward(self, x):
y_pred = self.linear(x)
return y_pred
#构造模型
model = LinearModel()
# 构造损失函数和优化器
#损失函数
criterion = torch.nn.MSELoss(size_average = False)
#size_average=false表示不将最后结果求平均值
#优化器SGD
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# model.parameters()自动完成参数的初始化操作 lr学习率
# training cycle forward, backward, update
#每一次的epoch过程总结就是
#1、前向传播计算y_pred值【预测值】
#2、根据预测值和测试值计算损失
#3、反向传播backward【计算梯度】
#4、根据梯度更新参数
for epoch in range(100):
y_pred = model(x_data) # forward:predict
loss = criterion(y_pred, y_data) # forward: loss
#loss.item()表示直接输出数值
print(epoch, loss.item())
optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zero
loss.backward() # backward: autograd,自动计算梯度
optimizer.step() # update 参数,即更新w和b的值
#输出偏置值和权重
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
#测试预测
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
Logistic回归模型
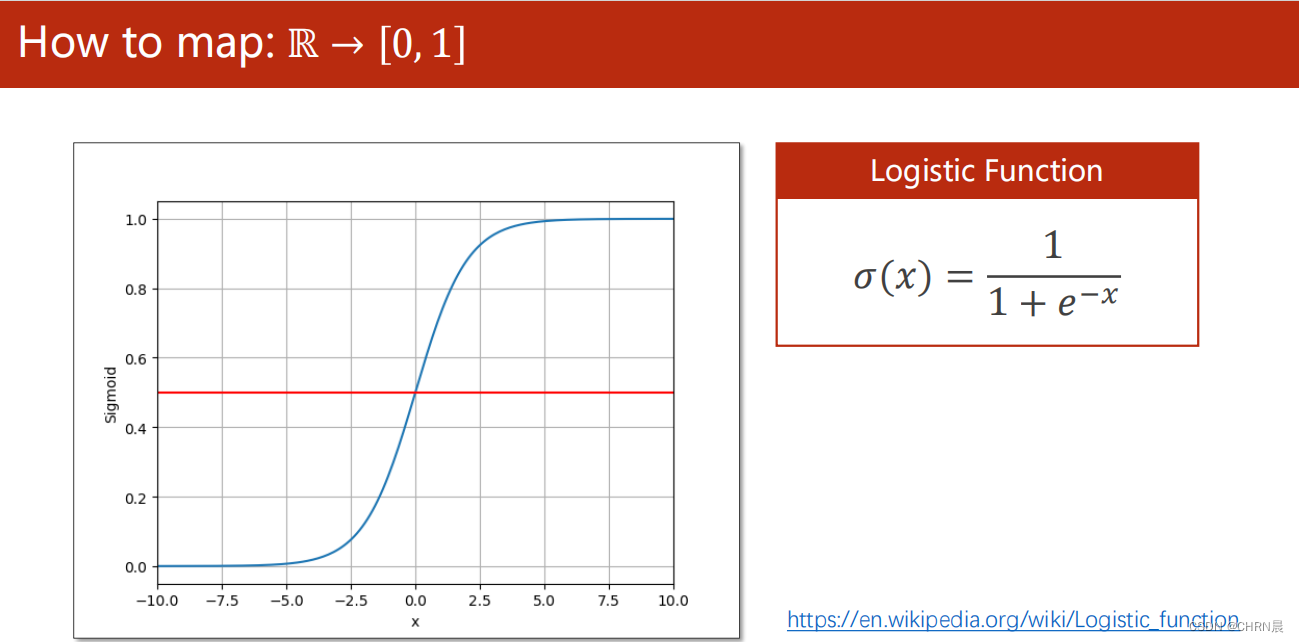
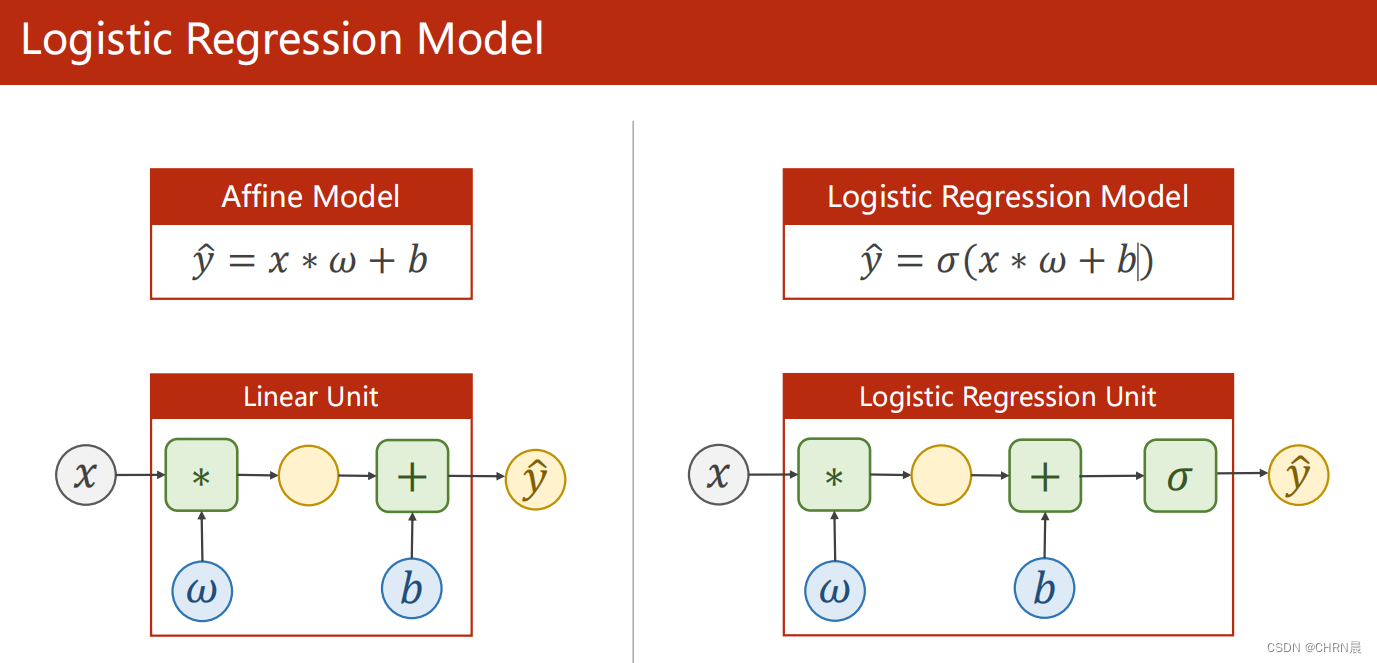
如下图所示,与线性回归模型不同的是,Logistic回归是对线性回归计算的值使用sigmoid函数对其进行变换,映射在0-1之间
Logistic回归损失函数计算公式

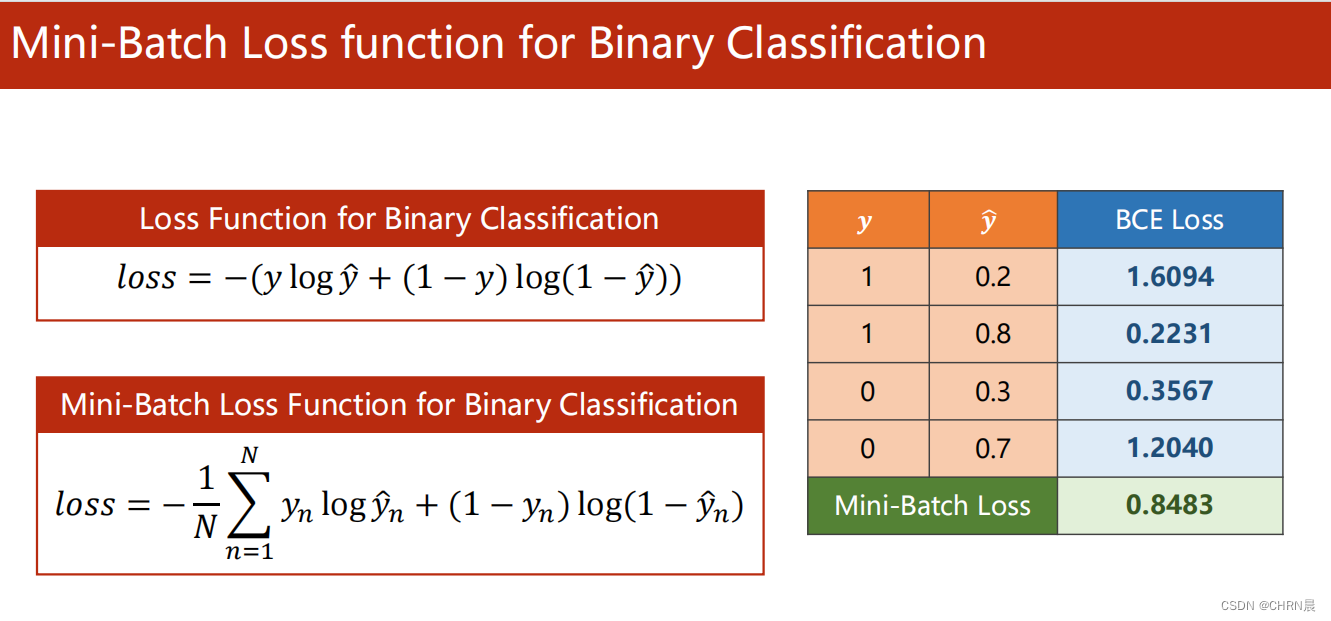
说明:预测与标签越接近,BCE损失越小。
对比线性回归和Logistic回归构造的类,Logistic回归是使用torch.nn.functional模块中的sigmoid函数
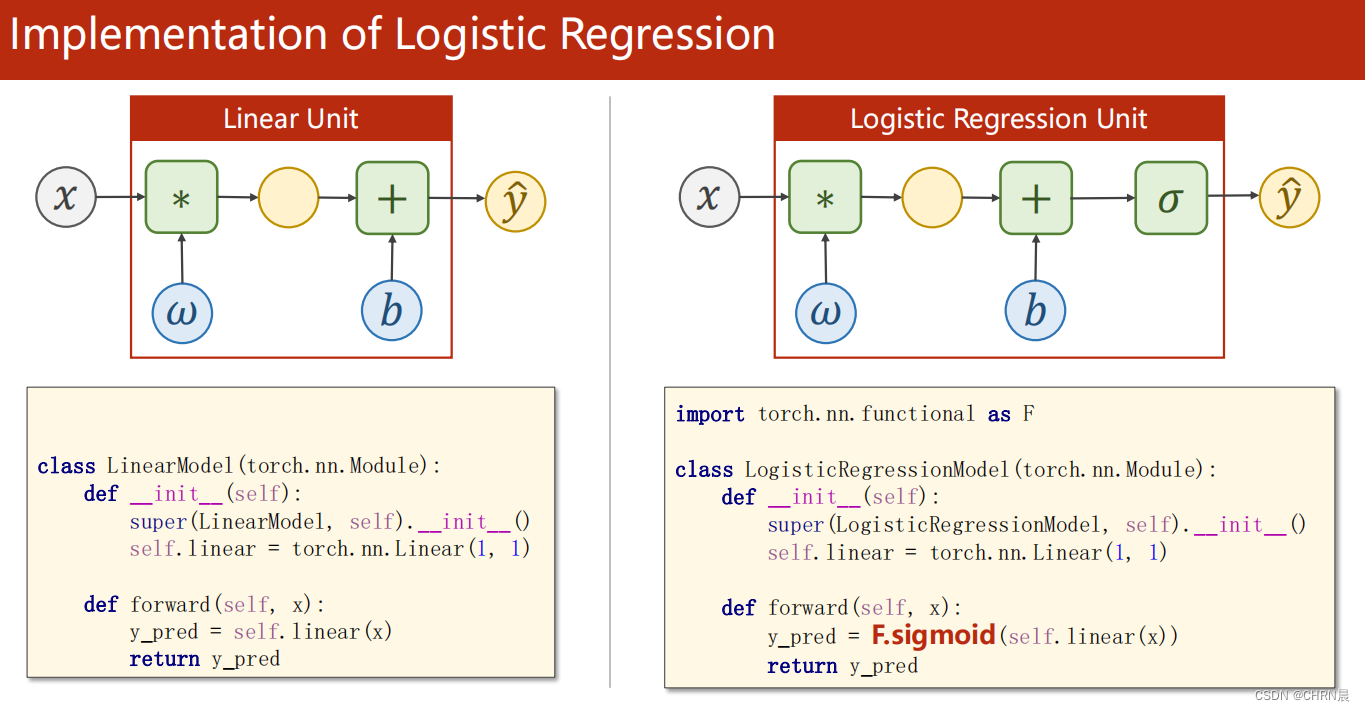
Logistic回归的损失函数为BCELoss

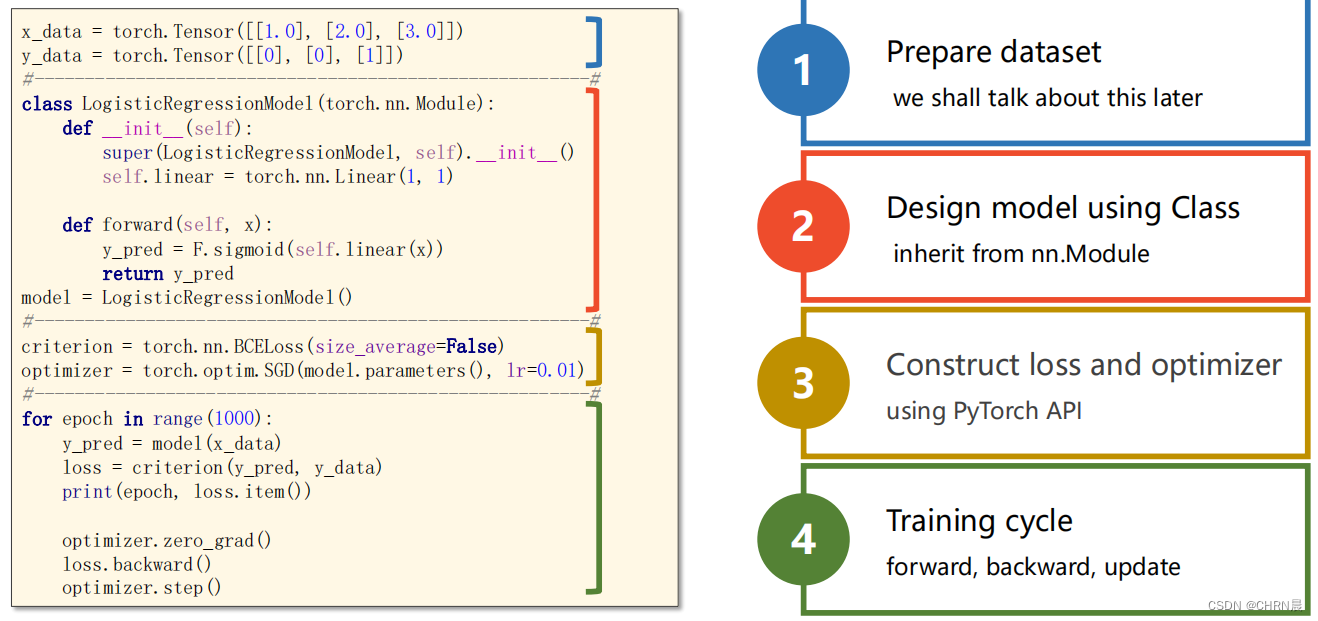
构建Logistic回归模型
第一步:准备数据

第二步:设计类模型

第三步:设置损失函数和优化器

第四步:训练

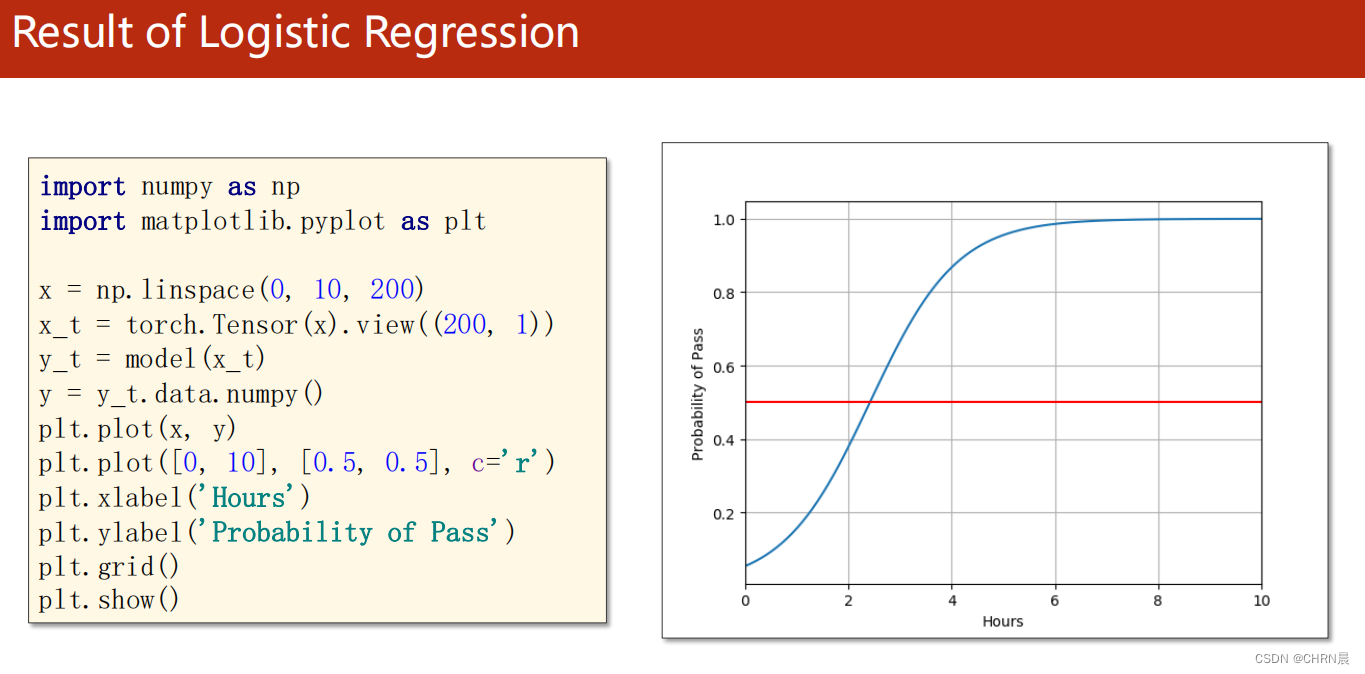
可视化
import torch
# import torch.nn.functional as F
# prepare dataset
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
#design model using class
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
# y_pred = F.sigmoid(self.linear(x))
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# construct loss and optimizer
# 默认情况下,loss会基于element平均,如果size_average=False的话,loss会被累加。
criterion = torch.nn.BCELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# training cycle forward, backward, update
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)











![学习 [Spring MVC] 的JSR 303和拦截器,提高开发效率](https://img-blog.csdnimg.cn/88b554277b194ed0ad2ec987a29e8ac5.gif)