文章目录
- 0. 前言
- 本文技术组件版本
- 基本介绍
- 2. 使用和配置:
- 步骤1 引入依赖
- 步骤2 配置数据源和分片策略
- 步骤3 核心代码
- MybatisPlusConfig 核心配置
- OrderService
- OrderServiceImpl
- OrderInfo
- OrderMapper
- OrderController
- BaseMapper
- 3. 数据库分片配置
- 在我的demo工程中大家可以看到如下的配置
- 3.1 表的分片策略
- 3.2 分片算法
- 3.3. 自定义分片算法
- 3.3.1. 自定义算法类实现
- 3.3.2. 自定义表达式实现
- 4. 数据路由
- 具体的执行过程
- 通常复杂查询Sharding-jdbc的处理方式
- 1. 分页查询
- 2. 聚合查询
- 3. 子查询和关联查询
- 4. 跨库事务
- 5. 数据库连接池
- 使用druid连接池
- 6. SQL执行引擎
- 7. 参考文档

0. 前言
Sharding-JDBC 是一款开源的分布式数据库中间件,主要目标是充分利用数据库的水平扩展能力,尽可能地避免改变已有的应用程序代码,简化分布式系统的开发难度。本文主要是使用sharding-jdbc 实现分库分表 以及各种分库分表策略实战验证。
在学习本文之前建议 先看下我之前写的两篇文章
《MySQL从入门到精通【进阶篇】MySQL分库分表详解》
《MySQL从入门到精通【进阶篇】MySQL的读写分离详解》
本文技术组件版本
> spring-boot 2.7.15
> jdk 1.8
> mybatis-plus-boot-starter 3.5.3.2 最新版
> mysql 8.0
> sharding-jdbc 4.0.1
基本介绍
分库分表是一种常见的数据库扩展策略,它通过将数据分散到多个数据库或表中,来提高系统的性能和可扩展性。然而,实现分库分表并不简单,它涉及到数据的路由、SQL的改写、结果的合并等一系列复杂的问题。其实我们也不需要自己造轮子,因为已经有一批优秀的开源组件满足了我们的基本需求。
最著名的组件MyCAT大家肯定若有耳闻。MyCAT 它提供了包括分库分表、读写分离、高可用等在内的一系列功能。MyCAT是基于Java开发的,可以透明地将多个MySQL数据库合并为一个逻辑数据库。而本章节我们要讲的是国内比较牛逼的ShardingSphere团队开发的Sharding-JDBC。后来加入了Apache 项目。
目前Sharding-JDBC是Apache ShardingSphere项目的一部分,它是一个在Java的JDBC层提供额外服务的轻量级框架,可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。使用Sharding-JDBC,我们可以轻松地实现MySQL的分库分表,而无需修改业务代码。
本文,我们将深入探讨如何使用Sharding-JDBC实现MySQL的分库分表。我们将从Sharding-JDBC的基本概念和原理开始,然后通过实际的示例和代码,详细介绍如何配置和使用Sharding-JDBC。无论你是菜鸟,还是有一定数据库经验的开发者,我相信你都能从这篇文章中也能get到一些有用的知识。
2. 使用和配置:
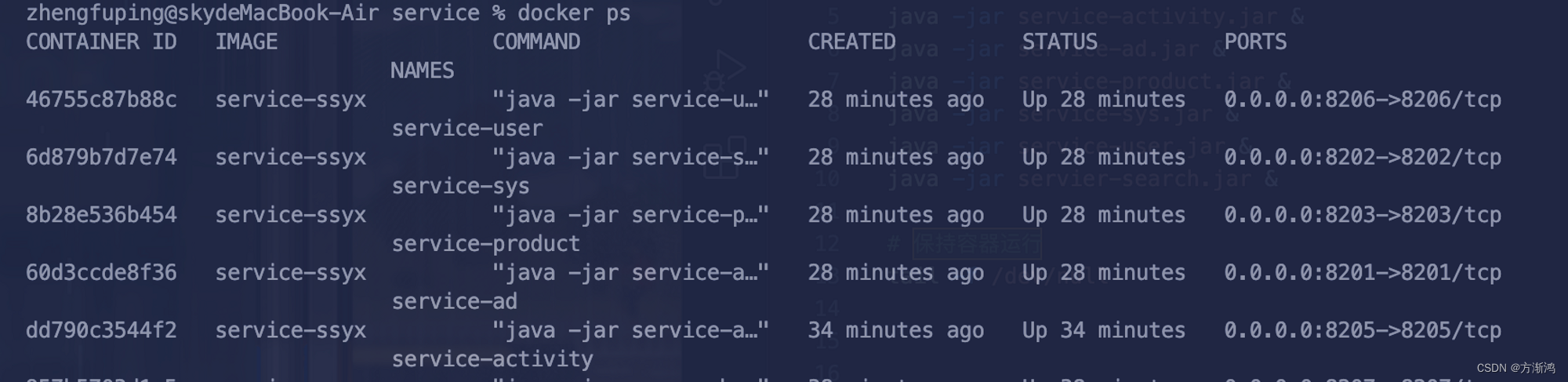
demo工程的目录结构如下
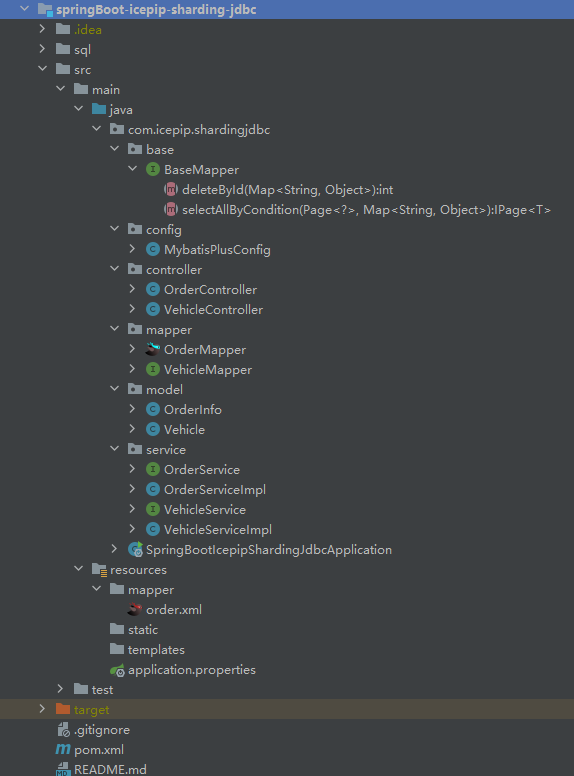
步骤1 引入依赖
在pom.xml中添加Sharding-JDBC的依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.15</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.icepip</groupId>
<artifactId>springBoot-icepip-sharding-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springBoot-icepip-sharding-jdbc</name>
<description>springBoot-icepip-sharding-jdbc</description>
<properties>
<java.version>1.8</java.version>
<mysql.version>8.0.13</mysql.version>
<sharding-sphere.version>4.0.1</sharding-sphere.version>
<mybatis-plus-boot-starter.version>3.5.3.2</mybatis-plus-boot-starter.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus-boot-starter.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
步骤2 配置数据源和分片策略
在application.properties中配置数据源和分片规则。
server.port=8098
management.health.db.enabled=false
spring.shardingsphere.datasource.names=ds0,ds1,ds2
logging.level.root=trace # 专门搞成trace 我们可以看到 SQL 解析、路由计算、SQL 改写和 SQL 执行
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://172.20.6.xx:3306/icepip_demo0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&characterSetResults=utf8&useSSL=false&verifyServerCertificate=false&autoReconnct=true&autoReconnectForPools=true&allowMultiQueries=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=password
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://172.20.6.xx:3306/icepip_demo1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&characterSetResults=utf8&useSSL=false&verifyServerCertificate=false&autoReconnct=true&autoReconnectForPools=true&allowMultiQueries=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=password
spring.shardingsphere.datasource.ds2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.jdbc-url=jdbc:mysql://172.20.6.xx:3306/icepip_demo2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&characterSetResults=utf8&useSSL=false&verifyServerCertificate=false&autoReconnct=true&autoReconnectForPools=true&allowMultiQueries=true
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=password
# 设置分库策略为内联分片策略,分片列为user_id
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
# 设置分库策略算法表达式,根据user_id的值取模3得到分库后缀,拼接到ds前面作为数据源名 因为我上面是3个库所以与3取模,实际根据分片库的数量配置
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 3}
# 设置t_order表的实际数据节点,实际数据节点由数据源名和表名组成
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..2}.t_order$->{0..1}
# 设置t_order表的内联分片策略,分片列为order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
# 设置t_order表的主键生成器列为order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
# 设置t_order表的主键生成器类型为雪花算法
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
# 设置t_order表的内联分片策略算法表达式,根据order_id的值取模2得到分片后缀,拼接到t_order前面作为表名
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
# 设置默认数据源名称为ds0
spring.shardingsphere.sharding.default-data-source-name=ds0
# 设置显示SQL语句
spring.shardingsphere.props.sql.show=true
# 允许覆盖Bean定义
spring.main.allow-bean-definition-overriding=true
# mybatis-plus
mybatis-plus.mapper-locations=classpath:/mapper/*.xml
mybatis-plus.configuration.jdbc-type-for-null='null'
步骤3 核心代码
在项目中使用JdbcTemplate或者JPA等方式进行数据库操作,Sharding-JDBC会自动进行分片。
MybatisPlusConfig 核心配置
package com.icepip.shardingjdbc.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.BlockAttackInnerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.actuate.jdbc.DataSourceHealthIndicator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
/**
* Mybatis-plus 全局拦截器
* 可通过开关选择启用不同作用的全局拦截器 {@see MybatisPlusConfig}
*
* @author 冰点
* @date 2022-06-23 2:13 PM
*/
@Configuration
@Slf4j
public class MybatisPlusConfig {
@Value("${icepip.mybatis-plus-ext.db-key.enable:false}")
private boolean dbKeyEnable;
@Value("${icepip.datasource.dynamic.primary:ds0}")
private String primaryCode;
@Value("${icepip.mybatis-plus-ext.db-key:ds0}")
private String dbKey;
@Value("${icepip.mybatis-plus-ext.pagination-interceptor.enable:true}")
private boolean paginationInterceptorEnable;
@Value("${icepip.mybatis-plus-ext.optimistic-Locker.enable:true}")
private boolean optimisticLockerEnable;
@Value("${icepip.mybatis-plus-ext.sql-attack-interceptor.enable:false}")
private boolean sqlAttackInterceptorEnable;
@Value("${icepip.mybatis-plus-ext.tenant-interceptor.enable:true}")
private boolean tenantEnable;
@Bean
public DataSourceHealthIndicator dataSourceHealthIndicator(DataSource dataSource) {
return new DataSourceHealthIndicator(dataSource, "select 1");
}
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
if (optimisticLockerEnable) {
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
log.info("已开启乐观锁校验[当要更新一条记录的时候,希望这条记录没有被别人更新],被@version字段修饰的字段为乐观锁字段,此必须要有默认值或初始值");
}
if (sqlAttackInterceptorEnable) {
interceptor.addInnerInterceptor(new BlockAttackInnerInterceptor());
log.info("已开启危险SQL拦截[由于开启了直接输入sql操作数据库,防止误操作],危险SQL拦截判断规则详见@see BlockAttackInnerInterceptor");
}
if (tenantEnable) {
// 已简化
log.info("已开启多租户模式,默认项目id为租户id");
}
if (paginationInterceptorEnable) {
PaginationInnerInterceptor innerInterceptor = new PaginationInnerInterceptor();
innerInterceptor.setOptimizeJoin(false);
interceptor.addInnerInterceptor(innerInterceptor);
log.info("已开启自动分页插件,如果返回类型是 IPage 则入参的 IPage 不能为null,因为 返回的IPage == 入参的IPage,如果返回类型是 List 则入参的 IPage 可以为 null(为 null 则不分页),但需要你手动入参的IPage.setRecords(返回的 List)");
}
return interceptor;
}
}
OrderService
package com.icepip.shardingjdbc.service;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.IService;
import com.icepip.shardingjdbc.model.OrderInfo;
import java.io.Serializable;
public interface OrderService extends IService<OrderInfo> {
@Override
boolean save(OrderInfo entity);
@Override
boolean removeById(Serializable id);
@Override
boolean updateById(OrderInfo entity);
IPage<OrderInfo> page(Page<?> page, OrderInfo orderInfo);
}
OrderServiceImpl
package com.icepip.shardingjdbc.service;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.icepip.shardingjdbc.mapper.OrderMapper;
import com.icepip.shardingjdbc.model.OrderInfo;
import org.springframework.stereotype.Service;
import java.io.Serializable;
import java.util.HashMap;
import java.util.Map;
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, OrderInfo> implements OrderService {
@Override
public boolean save(OrderInfo entity) {
return super.save(entity);
}
@Override
public boolean removeById(Serializable id) {
return super.removeById(id);
}
@Override
public boolean updateById(OrderInfo entity) {
return super.updateById(entity);
}
@Override
public IPage<OrderInfo> page(Page<?> page, OrderInfo orderInfo) {
Map<String, Object> map = new HashMap<>();
map.put("userId", orderInfo.getUserId());
map.put("orderId", orderInfo.getOrderId());
map.put("orderName", orderInfo.getOrderName());
map.put("orderStatus", orderInfo.getOrderStatus());
page.addOrder(new OrderItem("order_id",false));
return super.baseMapper.selectAllByCondition(page, map);
}
}
OrderInfo
package com.icepip.shardingjdbc.model;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("t_order")
public class OrderInfo {
@TableId(value = "order_id")
private Long orderId;
@TableField(value = "order_name")
private String orderName;
@TableField(value = "order_status")
private Integer orderStatus;
@TableField(value = "user_id")
private Long userId;
}
OrderMapper
package com.icepip.shardingjdbc.mapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.icepip.shardingjdbc.base.BaseMapper;
import com.icepip.shardingjdbc.model.OrderInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import java.util.Map;
@Mapper
public interface OrderMapper extends BaseMapper<OrderInfo> {
IPage<OrderInfo> selectAllByCondition(Page<?> page, @Param("condition") Map<String, Object> condition);
int deleteById(@Param("condition")Map<String, Object> condition);
}
OrderController
package com.icepip.shardingjdbc.controller;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.icepip.shardingjdbc.model.OrderInfo;
import com.icepip.shardingjdbc.service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/v1/order")
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping("add")
public boolean save(@RequestBody OrderInfo orderInfo) {
return orderService.save(orderInfo);
}
@DeleteMapping("/{orderId}")
public boolean deleteById(
@PathVariable("orderId")
Long id) {
return orderService.removeById(id);
}
@PutMapping("/{orderId}")
public boolean updateById(
@PathVariable("orderId")
Long orderId,
@RequestBody OrderInfo orderInfo) {
orderInfo.setOrderId(orderId);
return orderService.updateById(orderInfo);
}
@GetMapping("/page")
public IPage page(
@RequestParam(name = "pageNum", required = false, defaultValue = "1")
Integer pageNum,
@RequestParam(name = "pageSize", required = false, defaultValue = "10")
Integer pageSize,
@RequestParam(name = "orderId", required = false)
Long orderId,
@RequestParam(name = "orderStatus", required = false)
Integer orderStatus,
@RequestParam(name = "orderName", required = false)
String orderName) {
Page<OrderInfo> page = new Page<>(pageNum,pageSize);
OrderInfo orderInfo = new OrderInfo();
orderInfo.setOrderId(orderId);
orderInfo.setOrderName(orderName);
orderInfo.setOrderStatus(orderStatus);
return orderService.page(page, orderInfo);
}
}
BaseMapper
package com.icepip.shardingjdbc.base;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.apache.ibatis.annotations.Param;
import java.util.Map;
public interface BaseMapper<T> extends com.baomidou.mybatisplus.core.mapper.BaseMapper<T> {
IPage<T> selectAllByCondition(Page<?> page, @Param("condition")Map<String, Object> condition);
int deleteById(@Param("condition")Map<String, Object> condition);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.icepip.shardingjdbc.mapper.OrderMapper">
<sql id="Base_Column_List">
order_id, order_name, order_status, user_id
</sql>
<select id="selectAllByCondition" resultType="com.icepip.shardingjdbc.model.OrderInfo">
select
<include refid="Base_Column_List"/>
from
t_order
<where>
<if test="condition.userId != null">
and user_id = #{condition.userId, jdbcType=BIGINT}
</if>
<if test="condition.orderId != null">
and order_id = #{condition.orderId, jdbcType=BIGINT}
</if>
<if test="condition.orderName != null and condition.orderName != ''">
and order_name like concat('%',#{condition.orderName,jdbcType=VARCHAR} ,'%')
</if>
<if test="condition.orderStatus != null">
and order_status = #{condition.orderStatus, jdbcType=INTEGER}
</if>
</where>
</select>
<delete id="deleteById">
delete from t_order where order_id = #{condition.orderId, jdbcType=BIGINT} and user_id = #{condition.userId, jdbcType=BIGINT}
</delete>
</mapper>
3. 数据库分片配置
Sharding-JDBC 提供了强大的数据分片能力,可以根据业务规则将数据分散到多个数据库或表中,提高数据处理能力。
- 分片策略:如根据某字段的值进行取模分片等
- 分片算法:如内置的基于取模的分片算法、基于范围的分片算法等
Sharding-JDBC的数据分片功能使得对海量数据的管理和查询更加高效。通过将数据分散到多个数据库或表中,可以避免数据量过大导致的系统性能下降,提高系统的查询和处理速度。
例如,如果业务数据主要根据用户ID进行查询,那么可以选择用户ID作为分片键,然后根据用户ID的值进行取模操作,将数据均匀分散到不同的数据库或表中。
在我的demo工程中大家可以看到如下的配置
设置分库策略为内联分片策略,分片列为user_id.设置分库策略算法表达式,根据user_id的值取模3得到分库后缀,拼接到ds前面作为数据源名 因为我上面是3个库所以与3取模,实际根据分片库的数量配置
我是三个库。


3.1 表的分片策略
Sharding-JDBC支持各种分片策略,比如单键分片、复合键分片等。开发者可以根据业务需求选择合适的分片策略。
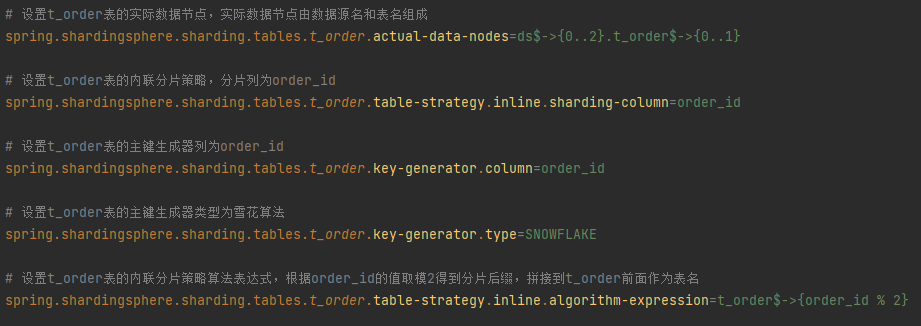
这是对Apache ShardingSphere的配置进行解析:
-
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..2}.t_order$->{0..1}
设置数据分片的逻辑表和实际数据节点。逻辑表是t_order,实际数据节点是ds0.t_order0、ds0.t_order1、ds1.t_order0、ds1.t_order1、ds2.t_order0、ds2.t_order1,其中ds表示数据源。 -
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
设置分片策略的列,这里order_id列作为分片依据。 -
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id和spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
设置主键生成策略,这里使用的是雪花算法(Snowflake)生成order_id字段的主键。 -
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
设置分片策略的算法表达式,这里通过order_id的值取模2的结果作为分片后缀,拼接到t_order前面作为表名。
3.2 分片算法
其实Sharding-JDBC内置了多种分片算法,比如基于取模的分片算法、基于范围的分片算法、基于哈希的分片算法等。取模分片算法是一种简单而常用的分片算法,适用于数据量大并且分布比较均匀的场景;范围分片算法适用于数据在分片键上的分布不均匀的场景,可以通过指定分片键的范围来进行分片;哈希分片算法则适用于数据量特别大的场景,通过对分片键进行哈希运算,可以将数据均匀地分散到各个数据库或表中。
ShardingSphere提供了多种内置的分片策略,
-
标准分片策略(StandardShardingStrategy):适用于分片键的值具有明确的分片逻辑,例如:偶数分到一个分片,奇数分到另一个分片。 -
复合分片策略(ComplexShardingStrategy):适用于多个分片键之间存在复杂关系的场景。 -
Hint分片策略(HintShardingStrategy):适用于分片键的值无法从SQL中直接获取,需要应用通过Hint API提供。 -
类型分片策略(ClassBasedShardingStrategy):适用于分片键的值需要通过自定义算法进行分片。 -
范围分片策略(RangeShardingStrategy):适用于分片键的值具有范围关系的场景。
对我们上面的需求 也可以使用范围分片策略。 我们定义了一个名为range_order_id的范围分片算法,它将order_id字段的值除以1024,然后将结果用于确定分片。
sharding.jdbc.config.sharding.tables.t_order.table-strategy.range.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.range.sharding-algorithm-name=range_order_id
sharding.jdbc.config.sharding.sharding-algorithms.range_order_id.type=RANGE
sharding.jdbc.config.sharding.sharding-algorithms.range_order_id.props.algorithm-expression=ds${order_id / 1024}
3.3. 自定义分片算法
3.3.1. 自定义算法类实现
假设我们想根据订单的创建时间进行分片。我们可以选择按照年份进行分片,即每年的数据存储在一个分片中。这样,我们可以创建一个自定义的分片算法, 其实也可以用表达式处理。
package com.icepip.shardingjdbc.config;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import java.util.Calendar;
import java.util.Collection;
import java.util.Date;
/**
* 自定义分片策略
* @author 冰点
* @version 1.0.0
* @date 2023/9/5 14:52
*/
public class OrderTableShardingAlgorithm implements PreciseShardingAlgorithm<Date> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {
Date orderCreateTime = shardingValue.getValue();
int year = getYear(orderCreateTime);
for (String each : availableTargetNames) {
if (each.endsWith(year + "")) {
return each;
}
}
throw new IllegalArgumentException();
}
private int getYear(Date date) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
return calendar.get(Calendar.YEAR);
}
}
sharding:
tables:
t_order:
actual-data-nodes: ds${0..1}.t_order_${0..9}
table-strategy:
standard:
sharding-column: create_time
precise-algorithm-class-name: com.yourpackage.OrderTableShardingAlgorithm
t_order是逻辑表名,ds${0..1}.t_order_${0..9}表示实际的数据节点,create_time是分片列,com.yourpackage.OrderTableShardingAlgorithm是你自定义的分片算法类。
3.3.2. 自定义表达式实现
如果我们不使用自定义算法类 也是可以实现的。需要配置表达式去解析。这种方式需要数据库支持在SQL中直接使用Java的日期时间函数,否则可能会出现错误。如果数据库不支持,那么还是需要写自定义的分片策略。
我们首先获取订单的创建时间,然后提取出年份。然后,我们遍历所有的可用的目标表名,如果表名的后缀与年份匹配,那么我们就选择这个表作为目标表。
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds${0..1}.t_order_${2018..2023}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.standard.sharding-column=create_time
sharding.jdbc.config.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=orderTableShardingAlgorithm
sharding.jdbc.config.sharding.sharding-algorithms.orderTableShardingAlgorithm.type=INLINE
sharding.jdbc.config.sharding.sharding-algorithms.orderTableShardingAlgorithm.props.algorithm-expression=t_order_${create_time.toInstant().atZone(ZoneId.systemDefault()).toLocalDate().getYear()}

sharding.jdbc.config.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name定义了分片算法的名称。
sharding.jdbc.config.sharding.sharding-algorithms.orderTableShardingAlgorithm.type定义了分片算法的类型,sharding.jdbc.config.sharding.sharding-algorithms.orderTableShardingAlgorithm.props.algorithm-expression定义了分片的表达式。
当你插入一个新的订单时,ShardingSphere会根据订单的创建时间来选择一个分片进行存储。
4. 数据路由
Sharding-JDBC 在处理业务请求时,能够根据分片规则自动路由到对应的数据库或表,无需开发者关注底层数据存储细节。
数据路由的过程主要分为四个步骤:SQL 解析、路由计算、SQL 改写和 SQL 执行。
-
SQL 解析:Sharding-JDBC 首先对 SQL 语句进行解析,得到抽象语法树(AST),并提取出路由条件。
-
路由计算:通过使用分片键和分片算法,结合解析出的路由条件,计算出 SQL 语句需要访问的目标数据库和表。
-
SQL 改写:根据路由结果,对原始 SQL 语句进行改写,将全局表和分片表替换为真实的物理表。
-
SQL 执行:最后,将改写后的 SQL 语句发送到目标数据库执行。
这四个步骤完全由 Sharding-JDBC 自动完成,开发者只需配置好分片规则,即可做到数据的水平切分和分布式访问,大大简化了开发工作。
我们可以通过日志 看到SQL改写。我故意加了一些order by 排序想看下
sharding-jdbc改写后的结果,发现它是在每个库和每个表都执行了此sql 然后在内存中在做排序。
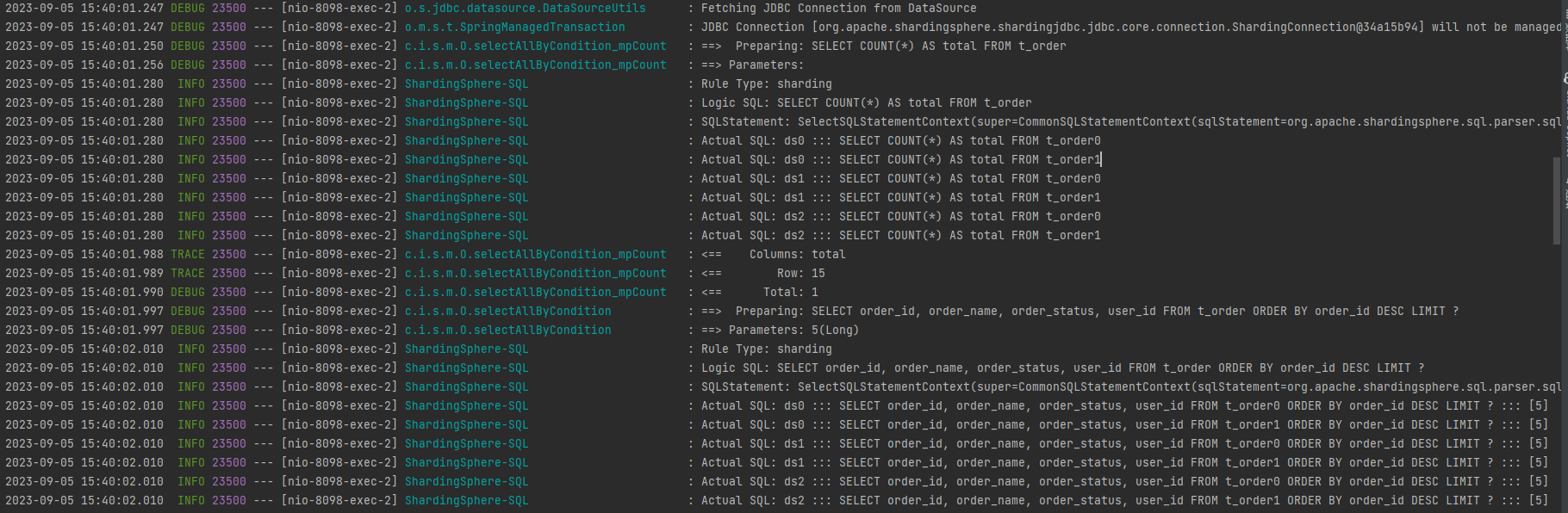
具体的执行过程
首先,Sharding-JDBC会解析SQL,提取出表名、列名、条件、排序字段等关键信息。
Sharding-JDBC会进行SQL路由。根据分片策略,它会计算出SQL语句需要执行的具体的数据库和数据表。
然后,Sharding-JDBC会对原始的SQL语句进行改写。这一步中,它会将逻辑表名替换为实际的物理表名,并根据分片键将查询条件拆分为多个子查询。同时,它还会在每个子查询中添加相应的排序和分页条件。
并行查询:改写后的SQL语句会被并行发送到对应的数据库执行。每个数据库会返回一个结果集。
结果合并:在内存中,Sharding-JDBC会将来自不同数据库的结果集进行合并。首先,它会按照排序字段对所有结果进行排序。然后,它会根据分页条件,取出需要的部分数据返回给客户端。
例如,原始的SQL
SELECT * FROM t_order ORDER BY order_id DESC LIMIT 10 OFFSET 20
如果t_order表按照order_id字段分片,存储在两个数据库的t_order_0和t_order_1两个表中,那么改写后的SQL可能会是:
SELECT * FROM t_order_0 ORDER BY order_id DESC LIMIT 30
SELECT * FROM t_order_1 ORDER BY order_id DESC LIMIT 30
这两条SQL会并行在各自的数据库中执行,然后Sharding-JDBC会将两个结果集合并,按照order_id进行排序,取出第21到30条记录返回给客户端。
大家有没有思考过在上述分库分表的例子中,我们的原始查询是希望取出排序后的第21到30条记录,也就是希望取出10条记录,但在改写后的SQL中我们却对每个子查询使用了LIMIT 30,这是为什么呢?
这是因为在分库分表的情况下,数据是分散在不同的数据库和表中的。当我们需要对数据进行排序并取出一部分数据时,我们不能保证每个子查询都能贡献出足够的数据。
比如在我们的例子中,我们希望取出排序后的第21到30条记录。如果我们直接对每个子查询使用LIMIT 10 OFFSET 20,那么有可能某个子查询返回的数据不足10条(比如只返回了5条),这样合并后的结果集就不足10条了。为了避免这种情况,我们需要让每个子查询返回更多的数据,比如返回前30条数据,这样即使某个子查询的数据不足,我们也有可能从其他子查询中获取到足够的数据。
我只是做了一个示例,这只是一种简化的做法,实际上Sharding-JDBC在处理这种情况时会更加复杂和智能。
通常复杂查询Sharding-jdbc的处理方式
1. 分页查询
如上面我们举的例子。在分库分表的环境中,处理分页查询和排序查询会相对比较复杂。因为数据分散在不同的库和表中,我们不能直接使用LIMIT和OFFSET关键词进行分页。Sharding-JDBC更新的方法是对每个子查询使用改写后的LIMIT和OFFSET值,然后在内存中对所有的结果进行合并和排序。
2. 聚合查询
类似的,对于COUNT()、SUM()、AVG()等聚合函数,Sharding-JDBC也会对每个子查询进行聚合操作,然后在内存中对所有的结果进行二次聚合。比如,对于COUNT()函数,Sharding-JDBC会将各个子查询的结果加起来;对于AVG()函数,Sharding-JDBC会将所有子查询的SUM()结果相加,然后除以所有子查询的COUNT()结果相加得到的数。
3. 子查询和关联查询
如果SQL中涉及到子查询或者关联查询,比如JOIN、IN等,相对来说也是很复杂的。但是Sharding-JDBC也能正确地处理。它会将包含子查询或关联查询的复杂SQL,逐步拆解成单表查询,然后逐一进行执行,最后在内存中对所有的结果进行合并。 我们举一个简单的实力 理解一下。
假设我们在一个电商系统中有两张分表,users(用户表)和orders(订单表),并且它们根据用户ID(user_id)进行了分片。
例如,下面是一个包含子查询的SQL语句。我们的需求是查询希望找到所有订单总金额大于1000的用户。 Sharding-JDBC会按以下方式处理:
原始SQL
SELECT * FROM users WHERE user_id IN (SELECT user_id FROM orders WHERE total_amount > 1000);
Sharding-JDBC会解析这个SQL,找到主查询和子查询,然后分别进行路由。因为
orders表按照user_id进行了分片,所以子查询可能要在多个表中进行。主查询中的users表也是根据user_id分片的,因此路由结果可能会涉及多个表。对于主查询和子查询,Sharding-JDBC会逐一改写并执行。 对于子查询,Sharding-JDBC会在每个
orders表中执行该查询,找到所有订单总金额大于1000的用户。
得到的user_id将用于主查询。在每个改写过的users表中执行主查询,找出对应的用户记录。结果合并 Sharding-JDBC会将来自不同表的查询结果进行合并,组成一个统一的结果集返回。
所以我们再开发过程尽量避免子查询和join 查询。
4. 跨库事务
在分库分表的环境中,实现横跨多个数据库的事务是一件挑战性的工作。通常的做法是借助某种分布式事务协议,如XA或者TCC。Sharding-JDBC通过整合开源分布式事务框架Seata,提供了对XA事务的支持。这个我们后续再专门来讲一下,如何集成实现。
5. 数据库连接池
Sharding-JDBC 支持多种流行的数据库连接池,如 HikariCP、Druid 等。可以对每个物理数据库设置独立的连接池。
如果你想使用Druid作为连接池,你可以按照以下方式进行配置:
我的示例里面使用的是hikari连接池 ,此处不做详解,下面是使用Druid 的示例。
使用druid连接池
spring.shardingsphere.datasource.names=ds0,ds1
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
在项目中使用了Spring Boot的starter for Druid(spring-boot-starter-data-druid),也可以额外配置Druid的一些属性,例如初始连接数、最小空闲连接数、最大活动连接数等。这些配置可以通过spring.shardingsphere.datasource.ds0.druid.*进行。
6. SQL执行引擎
Sharding-JDBC 对 SQL 语句进行解析、改写和执行,能够支持绝大部分的 SQL 语法,包括对联表查询、子查询、分页查询等复杂 SQL 的支持。这个我们已经在数据路由中已经详细讲解,此处就不做详解,大家只需要知道Sharding-jdbc的组成核心部分有SQL执行引擎,以及他的主要作用。
7. 参考文档
本文参考了以下文档
-
Sharding-JDBC GitHub:https://github.com/apache/shardingsphere
-
Sharding-JDBC官方文档包括了Sharding-JDBC的安装、配置和使用方法,以及一些高级话题,比如分片策略、SQL支持等。
-
Sharding-JDBC API文档 对于开发者来说是一个非常有用的参考资源。
-
Sharding-JDBC示例项目:https://github.com/apache/shardingsphere-example