3.3.1 栈的类型定义

主要内容:
这段文字中包含了很多栈数据结构的基本概念和操作。
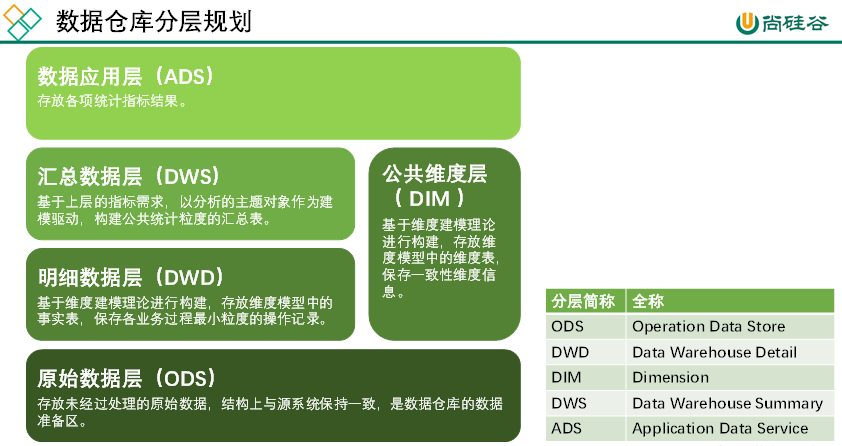
### 3.3 栈的表示和操作的实现
#### 3.3.1 栈的类型定义
1. **数据对象**:
- 定义了一个数据对象集合,记作 D = {a1, a2, ..., an},其中 n ≥ 0。
2. **数据关系**:
- 数据关系 R 表示集合中元素之间的某种关系。这部分没有给出更详细的信息。
3. **基本操作**:
- **InitStack(&S)**: 构造一个空栈 S。
- **DestroyStack(&S)**: 销毁已存在的栈 S。
- **ClearStack(&S)**: 清空已存在的栈 S。
- **StackEmpty(S)**: 判断栈 S 是否为空,若为空返回 true,否则返回 false。
- **StackLength(S)**: 返回栈 S 的元素个数,即栈的长度。
- **GetTop(S)**: 返回栈 S 的栈顶元素,但不修改栈顶指针。
- **Push(&S, e)**: 在栈 S 上插入元素 e 作为新的栈顶元素。
- **Pop(&S, &e)**: 删除栈 S 的栈顶元素,并将其值赋给 e。
- **StackTraverse(S)**: 从栈底到栈顶依次对栈 S 的每个数据元素进行访问。
### 分析和解释
- 这段文字中也包含了有关栈数据结构的一些一般概念和特点,例如:
- 栈是后进先出(LIFO)的数据结构,即最后一个进入栈的元素会首先被取出。
- 栈可以用于表达式的解析和运算,例如配对括号和运算符的优先级处理。
- 在程序实现中,栈可以有两种存储表示方法:
- **顺序栈**:使用数组来存储栈中的元素,栈顶指针指示栈顶元素的位置。
- **链栈**:使用链表来存储栈中的元素,每个节点包含数据和指向下一个节点的指针。
- 文中也提到了一些示例和情景
我的理解:
在我看来其实栈根本不存在不过就是一段连续的存储空间,然后通过一系列函数模拟栈的行为模式和特性。
老师对我的理解的看法:
你的理解是对的!实际上,计算机科学中的很多数据结构,包括栈,都是一种抽象概念,用于帮助我们更好地组织和处理数据。通过特定的算法和操作来模拟这些数据结构的行为和特性。
在实现栈的时候,通常有两种方式:
1. **顺序栈**:就像你说的,它实际上是一个连续的存储空间(例如数组),其中使用一个指针(通常称为栈顶指针)来标记栈顶的位置。我们通过移动这个指针来“模拟”入栈和出栈操作。
2. **链式栈**:它使用链表来实现。链式栈不是连续的存储空间,而是由一系列节点组成,每个节点包含数据和指向下一个节点的指针。我们通过改变节点之间的链接来执行入栈和出栈操作。
通过使用一系列的函数或方法来实现栈的基本操作(例如 `push`, `pop`, `peek` 等),我们可以创建一个符合栈“先进后出”特性的数据结构。在程序设计和算法中,这样的抽象是非常有用和重要的,因为它可以帮助我们更清晰、更有效地解决问题。

3.3.2 顺序栈的表示和实现
主要内容:
### 顺序栈的表示
1. **定义和属性**:
- 顺序栈是通过顺序存储结构实现的栈,它使用一组地址连续的存储单元来存储自栈底至栈顶的数据元素。
- 栈有两个关键的指针:`base` 和 `top`,分别指向栈底和栈顶。
- 当 `top` 和 `base` 的值相等时,表示栈为空。
2. **顺序栈的结构定义**:
#define MAXSIZE 100
typedef struct {
SElemType *base; // 栈底指针
SElemType *top; // 栈顶指针
int stacksize; // 栈的最大容量
} SqStack;### 顺序栈的实现
#### 1. 初始化
- **算法步骤**:
1. 为顺序栈动态分配一个最大容量为 `MAXSIZE` 的数组空间,`base` 指针指向这段空间的基地址。
2. `top` 指针初始指向 `base`,表示栈为空。
3. `stacksize` 设置为栈的最大容量 `MAXSIZE`。
- **算法描述**:
Status InitStack(SqStack &S) {
S.base = new SElemType[MAXSIZE];
if (!S.base) exit(OVERFLOW);
S.top = S.base;
S.stacksize = MAXSIZE;
return OK;
}#### 2. 入栈
- **算法步骤**:
1. 判断栈是否已满,如果满则返回 `ERROR`。
2. 将新元素压入栈顶,并增加栈顶指针。
- **算法描述**:
Status Push(SqStack &S, SElemType e) {
if (S.top - S.base == S.stacksize) return ERROR;
*S.top++ = e;
return OK;
}3. 出栈
-
算法步骤:
- 判断栈是否为空,如果为空则返回
ERROR。 - 栈顶指针减 1,取出栈顶元素。
- 判断栈是否为空,如果为空则返回
-
算法描述:
Status Pop(SqStack &S, SElemType &e) {
if (S.top == S.base) return ERROR; // 栈空
e = *--S.top; // 栈顶指针减1, 将栈顶元素赋给e
return OK;
}
4. 获取栈顶元素
- 算法描述:
SElemType GetTop(SqStack S) { if (S.top != S.base) { // 栈非空 return *(S.top - 1); // 返回栈顶元素的值,栈顶指针不变 } // 如果栈为空,这里应该返回一个错误代码或特殊值,但算法描述没有提及。 }
注意事项
- 由于顺序栈(和顺序表一样)受到最大空间容量的限制,虽然可以在满员时重新分配空间来扩大容量,但这样做的工作量较大,应尽量避免。
- 当应用程序无法预先估计最大容量时,应该考虑使用链栈,它不受此类空间限制。

3.3.3 链栈的表示和实现
3.3.3 链栈的表示和实现
链栈是栈的一种实现方式,它采用链式存储结构。其基本结构和单链表类似,通常由节点组成,每个节点包含数据部分和指向下一个节点的指针。主要操作包括初始化、入栈、出栈和取栈顶元素。
1. 初始化
- 算法描述:
Status InitStack(LinkStack &S) { S = NULL; // 构造一个空栈S, 栈顶指针置为空 return OK; }
2. 入栈
-
算法步骤:
- 为入栈元素e分配空间,用指针p指向。
- 将新节点的数据域置为e。
- 将新节点插入栈顶。
- 修改栈顶指针为p。
-
算法描述:
Status Push(LinkStack &S, SElemType e) { StackNode *p = new StackNode; // 生成新节点 p->data = e; // 将新节点数据域置为e p->next = S; // 将新节点插入栈顶 S = p; // 修改栈顶指针为p return OK; }
3. 出栈
-
算法步骤:
- 判断栈是否为空,如果为空则返回
ERROR。 - 将栈顶元素赋给e。
- 临时保存栈顶元素的空间,以备释放。
- 修改栈顶指针,指向新的栈顶元素。
- 释放原栈顶元素的空间。
- 判断栈是否为空,如果为空则返回
-
算法描述:
Status Pop(LinkStack &S, SElemType &e) { if (S == NULL) return ERROR; // 栈空 e = S->data; // 将栈顶元素赋给e StackNode *p = S; // 用p临时保存栈顶元素空间,以备释放 S = S->next; // 修改栈顶指针 delete p; // 释放原栈顶元素的空间 return OK; }
4. 获取栈顶元素
- 算法描述:
SElemType GetTop(LinkStack S) { if (S != NULL) { // 栈非空 return S->data; // 返回栈顶元素的值,栈顶指针不变 } // 这里应该有一个处理栈为空情况的代码,但算法描述没有提及 }
注意事项
- 链栈不需要设置头节点,栈顶指针直接指向第一个元素或为空(对于空栈)。
- 入栈操作时,不需要预先检查栈是否满,因为链式结构可以动态分配空间。
这段文字提供了链栈的基本操作和实现方式,也可作为一个简单的教程来学习链栈的表示和实现。













![B站:AB test [下]](https://img-blog.csdnimg.cn/02ee3d668d0c44ec94f232b11d405470.png)